本文主要是介绍《论文阅读》CAE-LO: LiDAR Odometry Leveraging Fully Unsupervised Convolutional Auto-Encoder Based Interes,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
留个笔记自用
CAE-LO: LiDAR Odometry Leveraging Fully Unsupervised Convolutional Auto-Encoder Based Interest Point Detection and Feature Description
做什么
Lidar Odometry激光雷达里程计,里程计作为移动机器人相对定位的有效传感器,为机器人提供了实时的位姿信息。移动机器人里程计模型决定于移动机器人结构和运动方式,即移动机器人运动学模型。
简单来说,里程计是一种利用从移动传感器获得的数据来估计物体位置随时间的变化而改变的方法

用建图的方式来理解,要实现机器人的定位与导航,就需要知道机器人走了多远,往哪走,也就是初始位姿和终点位姿,只有知道了里程计,才能准确将机器人扫描出来的数据进行构建。
做了什么

这里提出的方法是2D和3D结合的,使用3D点云投影到的2D平面来检测物体兴趣点,再通过3D体素中提取兴趣点特征,辅以实现激光雷达里程计
怎么做
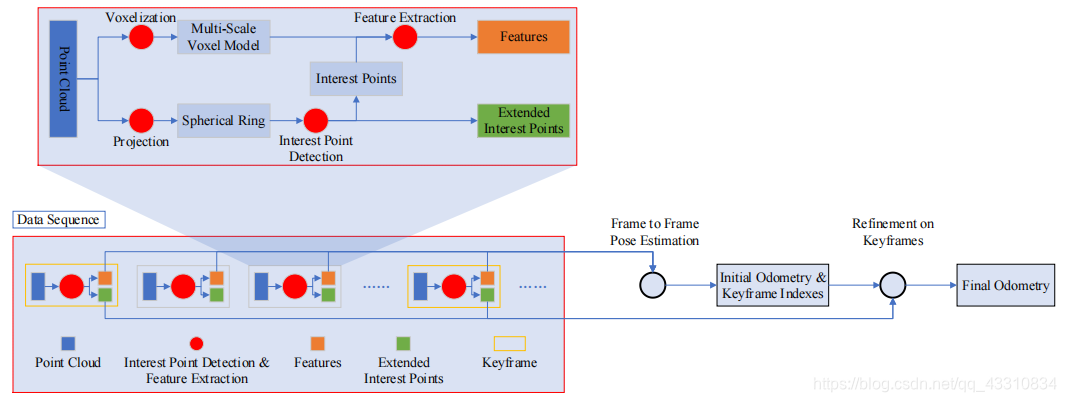
整体过程分为两步,也就是上面所提到的,第一步是根据输入点云进行帧序列的姿态估计,生成兴趣点和初始里程计结果,这一部分称为2D初始化部分。第二步是根据兴趣点和ICP(Iterative Closest Point迭代最近点)方法进行的里程计结果细化。这一部分称为3D细化部分。
首先是2D初始化部分,这里的方法是无监督的兴趣点检测
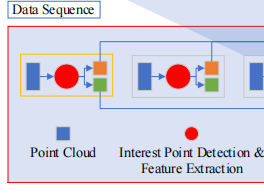
也像其他激光雷达里程计的论文一样,要对输入的3D点云数据进行一个2D投影
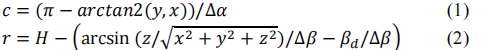
这里的(x,y,z)就是该点p的三维坐标, ∆α和 ∆β分别是点p的横纵角,得到的c和r就是投影的2D平面的横纵索引,H是图片纵向长度,βd是最低的激光角,这里的作用就是为了防止得到的值为负数。
最终由3D点云输入投影得到一个2D平面∈RH×W×C
处理完了输入,然后就是利用2D图像提取兴趣点,这里将这个问题视为挑选出与相邻像素点差异较大的像素点为对应的兴趣点
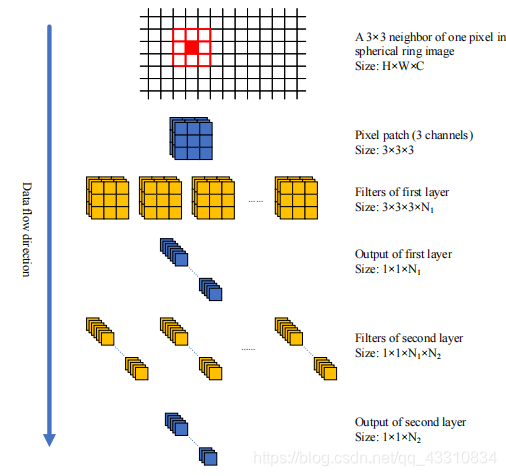
采用的方法便是用卷积来进行局部滤波,将每一点得到的卷积结果作为局部视野, 然后将特征间的差值去计算前面所述的差异较大的特征点情况
有了这种设计基础,只需要在网络中融入卷积就能进行模拟,这里采用的方法叫CAE也就是论文的名字(Convolutional Auto-Encoder)其实就是带了卷积的Auto-Encoder
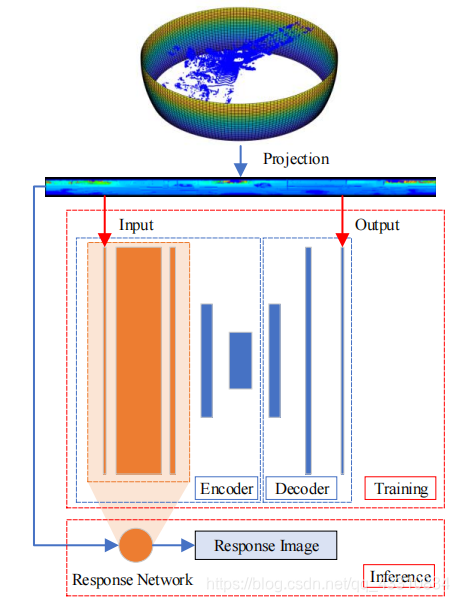
上图展示了大致流程,输入便是3D点云投影得到的2D平面∈RH×W×C,首先先看traning部分,由于为了使用无监督的方法实现它,采用了Auto-Encoder的结构,也就是希望通过encoder来对平面进行特征压缩,然后再通过输入输出完全相同的方式来进行训练,然后是下面的inference部分,这里的response Network用的是前面CAE的C部分,也就是前面的几层橙色的卷积层,目标就是为了把图片进行一个特征的提取,得到Response Image∈RH×W×N,这就是H×W中每个点的单独特征,用来计算后面的邻域差,也就是兴趣点
定义局部区域大小为
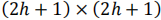
对于每个点来说,它拥有这样大小的一个局部区域,第一步先是通过前面得到的特征向量去直接计算一个差值,第二步根据投影过程产生的掩码与得到的差值矩阵相乘,最后进行一个排序
用式子展示如下,第一步
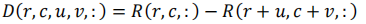
D就是特征差值图∈RH×W×h×h×N,简单来说就是对于每个点,都会跟h×h个邻域进行特征差值对比,这里的R就是特征图,(r,c)就是某一点的坐标索引,(u,v)是偏置
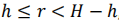
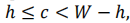
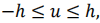
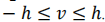
然后是第二步
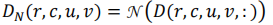
这里的N是计算向量norm的函数,这里的目的是记录每个像素和相邻像素的所有差值,在D的数值基础上做归一化,为了后面的mask做准备
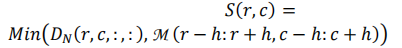
然后是第三步

这里的m是整张图的mask∈RH×W×1,是平面中有效像素的掩码,是由投影过程产生的,最后对这个乘积结果进行最小值排序
最终,得到的S(r,c)就是表示的平面(r,c)这个位置的点,与其邻域中其他点特征差的最小值,S∈RH×W×1就是整张图,这就是需求的兴趣点矩阵
然后是整体框架的第二步,3D细化部分,这里采用的方法是基于体素的多尺度特征提取
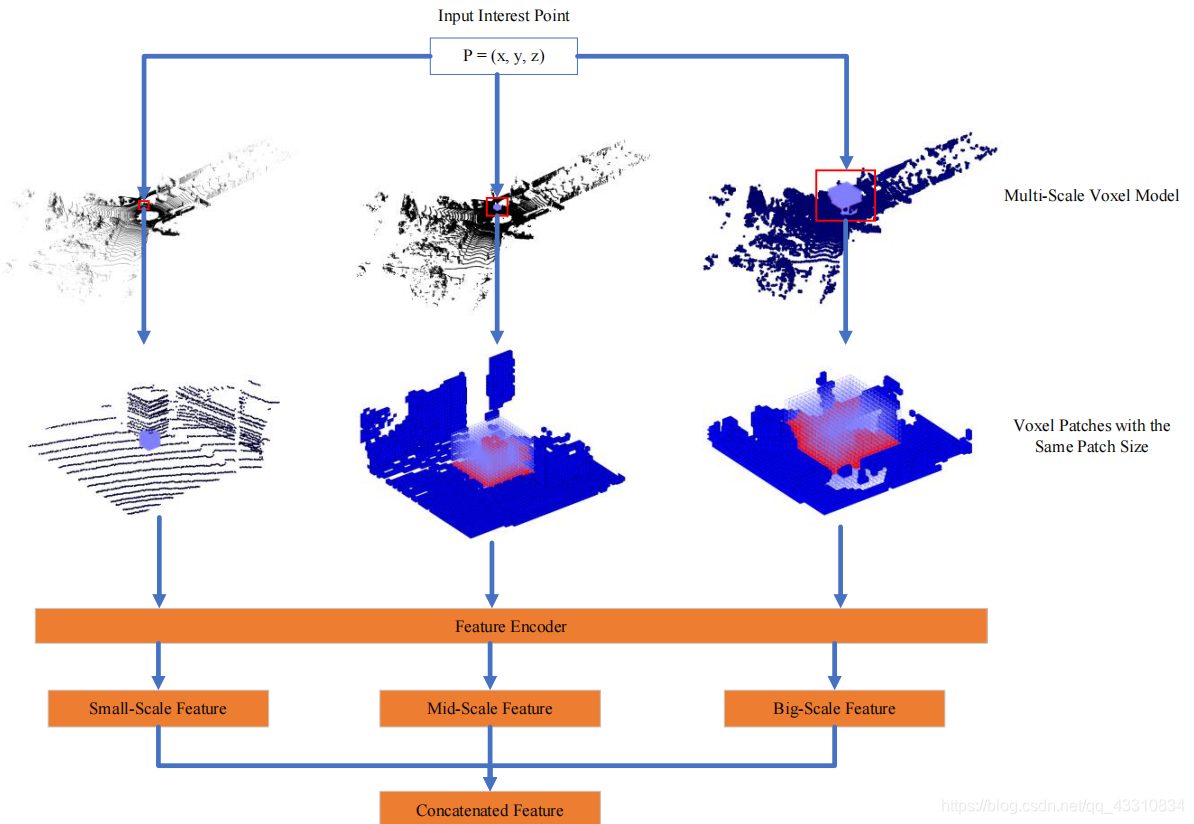
这里的输入是前面得到的兴趣点,将其索引至3D环境下的原位置后,为每个点设立一个多尺度结构,各自构造一个Patch大小为Sp,也就是构造了一个grid,这个grid里的格子数量一定是Sp^3,Voxel就是体素大小为{S1,S2,S3}
简单来说这里构造的多尺度的意思是,在固定网格数量的情况下,用不同大小的voxel去进行多尺度特征提取
然后是上图的Feature Encoder部分,这里采用的方法就是前面的CAE,构造方式也相似,不过到了3D领域中罢了
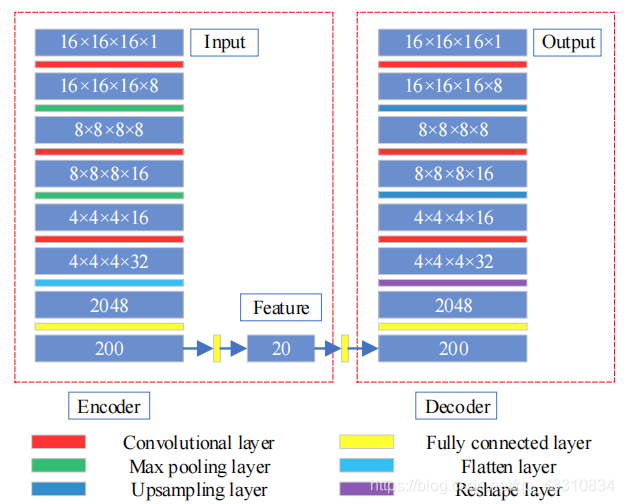
这里的200->20->就是一个AE的过程,无监督的,训练完后剪掉,主要目的就是通过这里的16×16×16的patch,聚合一个20维的特征向量,当然由于是多尺度的,可以将它们concat起来,就是60维的聚合特征
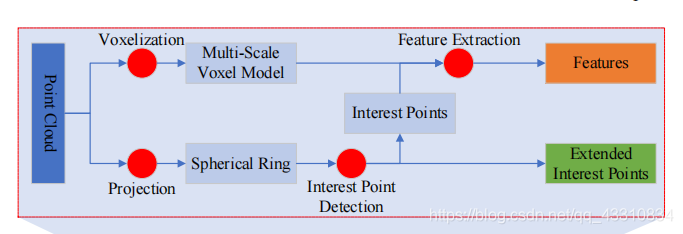
这就是上图中的面向兴趣点的Multi-Scale模块
至此,得到了两个点云中,所有兴趣点的聚合特征,然后就可以做里程计的初始和细化了,基础想法是通过Ransac来进行初始化,但显然这种方法太过粗
假设对于mth帧的点云有nIm的兴趣点,Im作为兴趣点的索引
定义两帧匹配对为
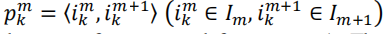
也就是两帧点云中的某些兴趣点匹配,将这一对对匹配对再建立一个索引
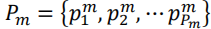
然后就可以定义目标函数
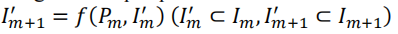
也就是这里的f,通过m帧点云的兴趣点找到m+1帧里的兴趣点,如果得到的目标兴趣点为空,则意味着对于m帧来说这个转换是失败的,所以对于关键帧的选择就是把前一帧作为第一个关键点,第一个转换失败的帧作为第二个关键点,然后用这个第二个关键帧继续寻找。
这里说实话,没懂什么意思。。。只知道总归通过某些设计方法,知道了帧序列中的关键帧位置,然后就用ICP去进行姿态细化了,注意的是这里面向的对象是关键点
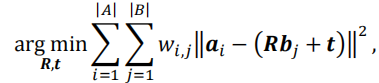
这里的a是某一帧关键帧点云中的点,b是后一个关键帧点云中的点,R是旋转矩阵,t是平移向量,wi,j是判断A点云的ai点和B点云中的bj点是否对应。这个最小化式子的意思就是,我们前一步获得了点云帧序列中的关键帧,任取两个前后帧,希望它们做到的是它们点云中任意对应的两个点都尽量能满足一个转换,也就是激光雷达里程计要求的,帧之间点的相对姿态转换
这样就存在了一个问题,由于合理只针对关键帧,对于帧序列中的部分普通帧没有做任何操作,所以这时候就需要根据关键帧的转换来对普通帧进行一个反向优化,其实就是一个简单的平均撒网
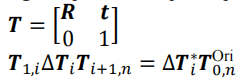
T就是位姿转换矩阵
下面式子中∆Ti是对第i帧点相对于原始位姿的转换更新(在初始化位姿转换的基础上根据关键帧反向来进行一个优化),T1,i是第0帧到第i帧的位姿转换,Ti+1,n是第i帧到第n帧的位姿转换,这里假设0帧和n帧分别是关键帧,然后是后面的式子
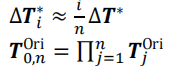
最后
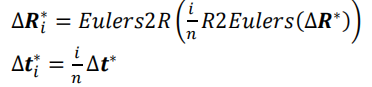
简单来说,也就是根据第一个式子来根据关键帧对序列中的普通帧的初始化位姿转换进行一个细化
总结
1.用Auto-Encoder的方式实现无监督,刚看上去觉得确实很厉害,但文中没提及loss部分,感觉这样训练特征提取效果不会好
2.多尺度体素的提取方式值得效仿,这样的patch可以很好的结合各种论文的卷积结构,同样关键帧的提取可能也能很好的识别场景中的动态物体
这篇关于《论文阅读》CAE-LO: LiDAR Odometry Leveraging Fully Unsupervised Convolutional Auto-Encoder Based Interes的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









