本文主要是介绍跨模态检索:基于OpenAI的Clip预训练模型构建以文搜图系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1 项目背景
2 关键技术
2.1 Clip模型
2.2 Milvus向量数据库
3 系统代码实现
3.1 运行环境构建
3.2 数据集下载
3.3 预训练模型下载
3.4 代码实现
3.4.1 创建向量表和索引
3.4.2 构建向量编码模型
3.4.3 数据向量化与加载
3.4.4 构建检索web
4 总结
1 项目背景
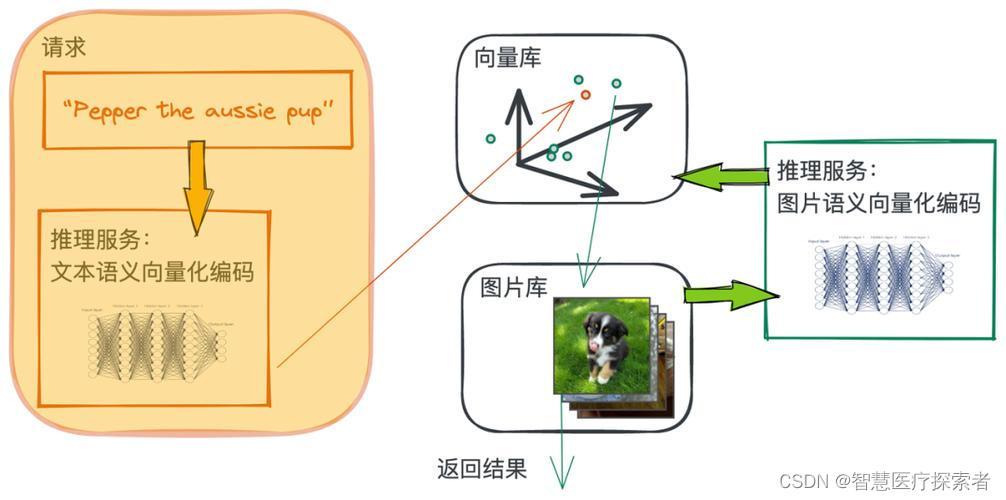
以文搜图是一种跨模态检索技术,即通过输入文字描述来搜索图片,它不仅应用于辅助搜索与信息检索,尤其在难以用关键词准确描述情况下发挥作用,提供了一种高效的信息检索方式。这种技术应用场景和价值非常广泛,它在辅助信息搜索、艺术、广告等领域均有重要的应用价值,为用户提供更个性化的搜索体验。以文搜图涉及到的技术点如下:
- 如何对文本数据进行向量编码
- 如何对海量图片数据进行向量化和存储
- 如何映射文本向量与图片向量的关系
- 如何快速对海量的向量数据进行检索
本项目基于OpenAI的Clip预训练模型结合Milvus向量数据库,在水果数据集上实现了以文搜图系统,读者可以将数据集扩展到其它领域,构建满足自身业务的以文搜图系统。
2 关键技术
2.1 Clip模型
CLIP全称Constrastive Language-Image Pre-training,是OpenAI推出的采用对比学习的文本-图像预训练模型。CLIP惊艳之处在于架构非常简洁且效果好到难以置信,在zero-shot文本-图像检索,zero-shot图像分类,文本→图像生成任务guidance,open-domain 检测分割等任务上均有非常惊艳的表现。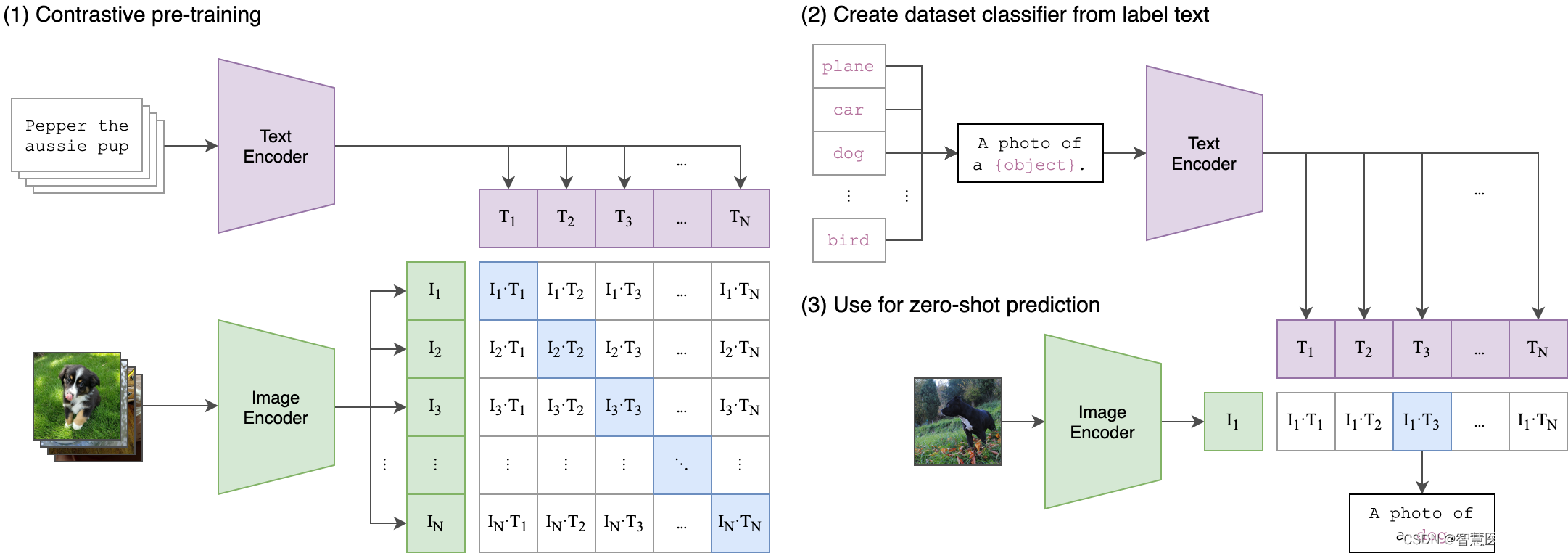
CLIP的创新之处在于,它能够将图像和文本映射到一个共享的向量空间中,从而使得模型能够理解图像和文本之间的语义关系。这种共享的向量空间使得CLIP在图像和文本之间实现了无监督的联合学习,从而可以用于各种视觉和语言任务。
CLIP的设计灵感源于一个简单的思想:让模型理解图像和文本之间的关系,不仅仅是通过监督训练,而是通过自监督的方式。CLIP通过大量的图像和文本对来训练,使得模型在向量空间中将相应的图像和文本嵌入彼此相近。
CLIP模型的特点
- 统一的向量空间: CLIP的一个关键创新是将图像和文本都映射到同一个向量空间中。这使得模型能够直接在向量空间中计算图像和文本之间的相似性,而无需额外的中间表示。
- 对比学习: CLIP使用对比学习的方式进行预训练。模型被要求将来自同一个样本的图像和文本嵌入映射到相近的位置,而将来自不同样本的嵌入映射到较远的位置。这使得模型能够学习到图像和文本之间的共同特征。
- 多语言支持: CLIP的预训练模型是多语言的,这意味着它可以处理多种语言的文本,并将它们嵌入到共享的向量空间中。
- 无监督学习: CLIP的预训练是无监督的,这意味着它不需要大量标注数据来指导训练。它从互联网上的文本和图像数据中学习,使得它在各种领域的任务上都能够表现出色。
Clip模型详细介绍:Clip模型详解
2.2 Milvus向量数据库
Milvus 是一款云原生向量数据库,它具备高可用、高性能、易拓展的特点,用于海量向量数据的实时召回。
Milvus 基于FAISS、Annoy、HNSW 等向量搜索库构建,核心是解决稠密向量相似度检索的问题。在向量检索库的基础上,Milvus 支持数据分区分片、数据持久化、增量数据摄取、标量向量混合查询、time travel 等功能,同时大幅优化了向量检索的性能,可满足任何向量检索场景的应用需求。通常,建议用户使用 Kubernetes 部署 Milvus,以获得最佳可用性和弹性。
Milvus 采用共享存储架构,存储计算完全分离,计算节点支持横向扩展。从架构上来看,Milvus 遵循数据流和控制流分离,整体分为了四个层次,分别为接入层(access layer)、协调服务(coordinator service)、执行节点(worker node)和存储层(storage)。各个层次相互独立,独立扩展和容灾。

Milvus 向量数据库能够帮助用户轻松应对海量非结构化数据(图片/视频/语音/文本)检索。单节点 Milvus 可以在秒内完成十亿级的向量搜索,分布式架构亦能满足用户的水平扩展需求。
milvus特点总结如下:
- 高性能:性能高超,可对海量数据集进行向量相似度检索。
- 高可用、高可靠:Milvus 支持在云上扩展,其容灾能力能够保证服务高可用。
- 混合查询:Milvus 支持在向量相似度检索过程中进行标量字段过滤,实现混合查询。
- 开发者友好:支持多语言、多工具的 Milvus 生态系统。
Milvus详细介绍:Miluvs详解
3 系统代码实现
3.1 运行环境构建
conda环境准备详见:annoconda
git clone https://gitcode.net/ai-medical/text_image_search.git
cd text_image_searchpip install -r requirements.txt
pip install git+https://ghproxy.com/https://github.com/openai/CLIP.git3.2 数据集下载
下载地址:
第一个数据包:package01
第二个数据包:package01
在数据集目录下,存放着10个文件夹,文件夹名称为水果类型,每个文件夹包含几百到几千张此类水果的图片,如下图所示:

以apple文件夹为例,内容如下:

下载后进行解压,保存到D:/dataset/fruit目录下,查看显示如下
# ll fruit/
总用量 508
drwxr-xr-x 2 root root 36864 8月 2 16:35 apple
drwxr-xr-x 2 root root 24576 8月 2 16:36 apricot
drwxr-xr-x 2 root root 40960 8月 2 16:36 banana
drwxr-xr-x 2 root root 20480 8月 2 16:36 blueberry
drwxr-xr-x 2 root root 45056 8月 2 16:37 cherry
drwxr-xr-x 2 root root 12288 8月 2 16:37 citrus
drwxr-xr-x 2 root root 49152 8月 2 16:38 grape
drwxr-xr-x 2 root root 16384 8月 2 16:38 lemon
drwxr-xr-x 2 root root 36864 8月 2 16:39 litchi
drwxr-xr-x 2 root root 49152 8月 2 16:39 mango3.3 预训练模型下载
预训练模型包含5个resnet和4个VIT,其中ViT-L/14@336px效果最好。
"RN50": "https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt",
"RN101": "https://openaipublic.azureedge.net/clip/models/8fa8567bab74a42d41c5915025a8e4538c3bdbe8804a470a72f30b0d94fab599/RN101.pt",
"RN50x4": "https://openaipublic.azureedge.net/clip/models/7e526bd135e493cef0776de27d5f42653e6b4c8bf9e0f653bb11773263205fdd/RN50x4.pt",
"RN50x16": "https://openaipublic.azureedge.net/clip/models/52378b407f34354e150460fe41077663dd5b39c54cd0bfd2b27167a4a06ec9aa/RN50x16.pt",
"RN50x64": "https://openaipublic.azureedge.net/clip/models/be1cfb55d75a9666199fb2206c106743da0f6468c9d327f3e0d0a543a9919d9c/RN50x64.pt",
"ViT-B/32": "https://openaipublic.azureedge.net/clip/models/40d365715913c9da98579312b702a82c18be219cc2a73407c4526f58eba950af/ViT-B-32.pt",
"ViT-B/16": "https://openaipublic.azureedge.net/clip/models/5806e77cd80f8b59890b7e101eabd078d9fb84e6937f9e85e4ecb61988df416f/ViT-B-16.pt",
"ViT-L/14": "https://openaipublic.azureedge.net/clip/models/b8cca3fd41ae0c99ba7e8951adf17d267cdb84cd88be6f7c2e0eca1737a03836/ViT-L-14.pt",
"ViT-L/14@336px": "https://openaipublic.azureedge.net/clip/models/3035c92b350959924f9f00213499208652fc7ea050643e8b385c2dac08641f02/ViT-L-14-336px.pt",
下载ViT-L/14@336px的预训练模型:ViT-L-14-336px.pt,存放到D:/models目录下
3.4 代码实现
3.4.1 创建向量表和索引
from pymilvus import connections, dbconn = connections.connect(host="192.168.1.156", port=19530)
database = db.create_database("text_image_db")db.using_database("text_image_db")
print(db.list_database())
创建collection
from pymilvus import CollectionSchema, FieldSchema, DataType
from pymilvus import Collection, db, connectionsconn = connections.connect(host="192.168.1.156", port=19530)
db.using_database("text_image_db")m_id = FieldSchema(name="m_id", dtype=DataType.INT64, is_primary=True,)
embeding = FieldSchema(name="embeding", dtype=DataType.FLOAT_VECTOR, dim=768,)
path = FieldSchema(name="path", dtype=DataType.VARCHAR, max_length=256,)
schema = CollectionSchema(fields=[m_id, embeding, path],description="text to image embeding search",enable_dynamic_field=True
)collection_name = "text_image_vector"
collection = Collection(name=collection_name, schema=schema, using='default', shards_num=2)
创建index
from pymilvus import Collection, utility, connections, dbconn = connections.connect(host="192.168.1.156", port=19530)
db.using_database("text_image_db")index_params = {"metric_type": "IP","index_type": "IVF_FLAT","params": {"nlist": 1024}
}collection = Collection("text_image_vector")
collection.create_index(field_name="embeding",index_params=index_params
)utility.index_building_progress("text_image_vector")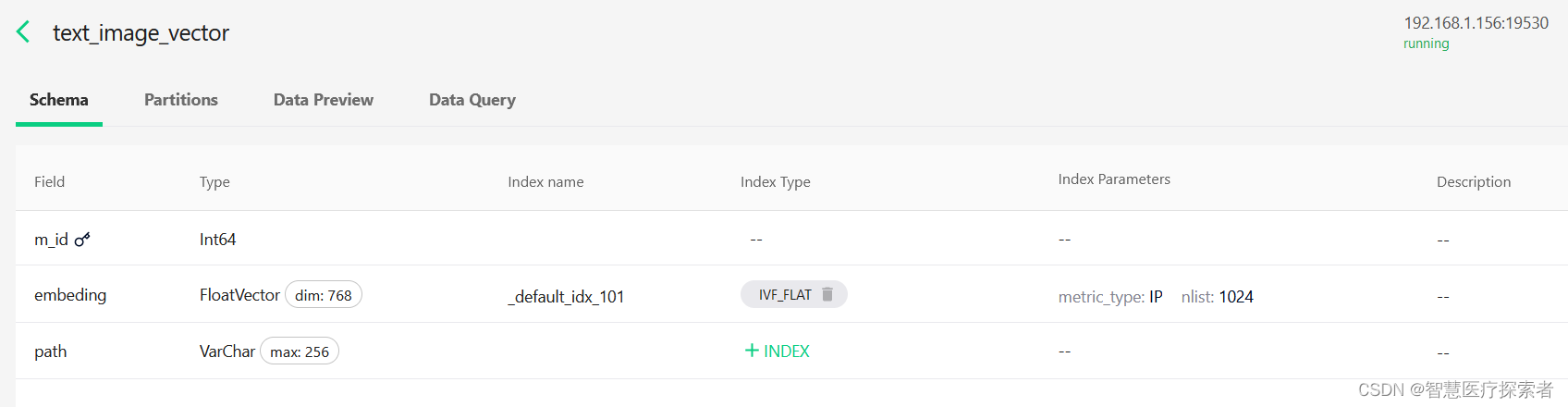
3.4.2 构建向量编码模型
加载预训练模型,通过Clip模型对图片进行编码,编码后输出特征维度为768
from torchvision.models import resnet50
import torch
from torchvision import transforms
from torch import nnclass RestnetEmbeding:pretrained_model = 'D:/models/resnet50-0676ba61.pth'def __init__(self):self.model = resnet50()self.model.load_state_dict(torch.load(self.pretrained_model))# delete fc layerself.model.fc = nn.Sequential()self.transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.48145466, 0.4578275, 0.40821073],std=[0.26862954, 0.26130258, 0.27577711])])def embeding(self, image):trans_image = self.transform(image)trans_image = trans_image.unsqueeze_(0)return self.model(trans_image)restnet_embeding = RestnetEmbeding()3.4.3 数据向量化与加载
from clip_embeding import clip_embeding
from milvus_operator import text_image_vector, MilvusOperator
from PIL import Image
import osdef update_image_vector(data_path, operator: MilvusOperator):idxs, embedings, paths = [], [], []total_count = 0for dir_name in os.listdir(data_path):sub_dir = os.path.join(data_path, dir_name)for file in os.listdir(sub_dir):image = Image.open(os.path.join(sub_dir, file)).convert('RGB')embeding = clip_embeding.embeding_image(image)idxs.append(total_count)embedings.append(embeding[0].detach().numpy().tolist())paths.append(os.path.join(sub_dir, file))total_count += 1if total_count % 50 == 0:data = [idxs, embedings, paths]operator.insert_data(data)print(f'success insert {operator.coll_name} items:{len(idxs)}')idxs, embedings, paths = [], [], []if len(idxs):data = [idxs, embedings, paths]operator.insert_data(data)print(f'success insert {operator.coll_name} items:{len(idxs)}')print(f'finish update {operator.coll_name} items: {total_count}')if __name__ == '__main__':data_dir = 'D:/dataset/fruit'update_image_vector(data_dir, text_image_vector)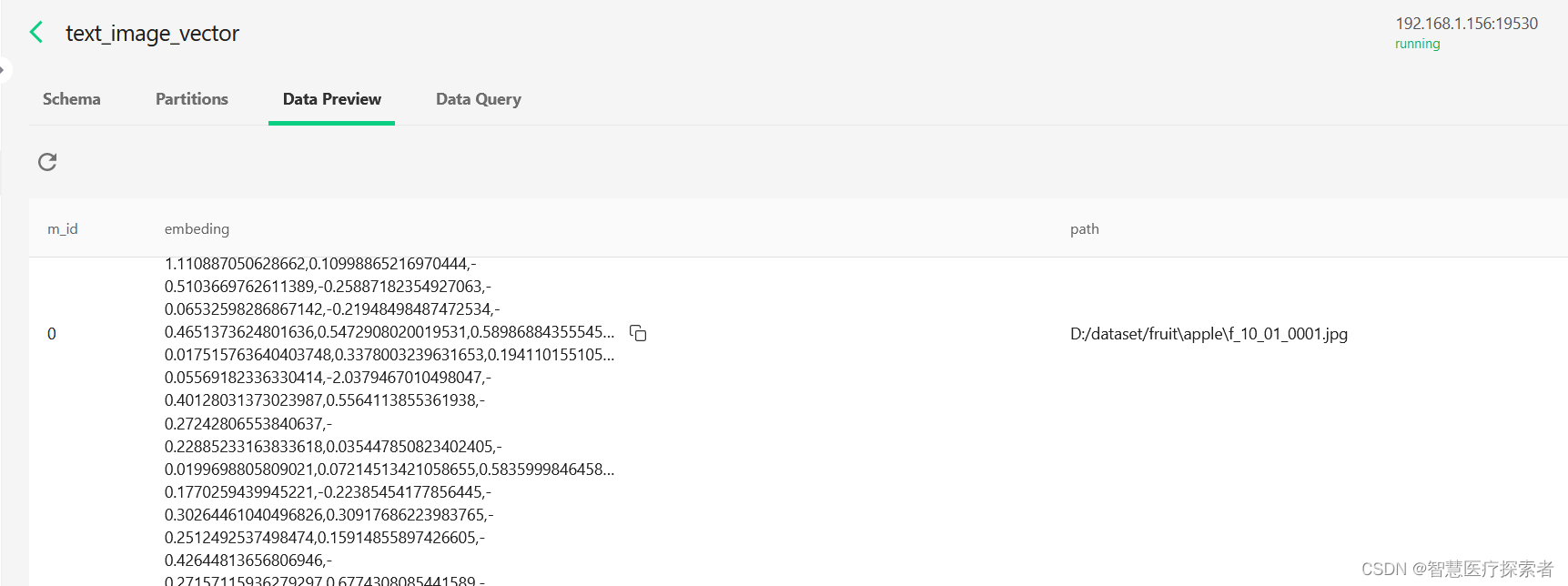
3.4.4 构建检索web
import gradio as gr
import torch
import argparse
from net_helper import net_helper
from PIL import Image
from clip_embeding import clip_embeding
from milvus_operator import text_image_vectordef image_search(text):if text is None:return None# clip编码imput_embeding = clip_embeding.embeding_text(text)imput_embeding = imput_embeding[0].detach().cpu().numpy()results = text_image_vector.search_data(imput_embeding)pil_images = [Image.open(result['path']) for result in results]return pil_imagesif __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument("--share", action="store_true",default=False, help="share gradio app")args = parser.parse_args()device = torch.device("cuda" if torch.cuda.is_available() else "cpu")app = gr.Blocks(theme='default', title="image",css=".gradio-container, .gradio-container button {background-color: #009FCC} ""footer {visibility: hidden}")with app:with gr.Tabs():with gr.TabItem("image search"):with gr.Row():with gr.Column():text = gr.TextArea(label="Text",placeholder="description",value="",)btn = gr.Button(label="search")with gr.Column():with gr.Row():output_images = [gr.outputs.Image(type="pil", label=None) for _ in range(16)]btn.click(image_search, inputs=[text], outputs=output_images, show_progress=True)ip_addr = net_helper.get_host_ip()app.queue(concurrency_count=3).launch(show_api=False, share=True, server_name=ip_addr, server_port=9099)


4 总结
本项目基于OpenAI的Clip预训练模型及milvus向量数据库两个关键技术,构建了以文搜图的跨模态检索系统;经过Clip模型编码后每个图片输出向量维度为768,存入milvus向量数据库;为保证图像检索的效率,通过脚本在milvus向量数据库中构建了向量索引。此项目可作为参考,在实际开发类似的信息检索项目中使用。
项目完整代码地址:code
这篇关于跨模态检索:基于OpenAI的Clip预训练模型构建以文搜图系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






