本文主要是介绍论文阅读:Offboard 3D Object Detection from Point Cloud Sequences,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
概要
Motivation
整体架构流程
技术细节
3D Auto Labeling Pipeline
The static object auto labeling model
The dynamic object auto labeling model
小结
论文地址:[2103.05073] Offboard 3D Object Detection from Point Cloud Sequences (arxiv.org)
概要
该论文提出了一种利用点云序列数据进行离线三维物体检测的方法,称为3D Auto Labeling。相比现有的三维物体检测方法,该方法能够更好地满足离线场景下高质量的要求。该方法利用点云序列中不同帧所捕获的物体的互补视角信息,通过多帧物体检测和新颖的物体中心优化模型来利用时间点云。在Waymo公开数据集上的评估结果表明,该方法相比于现有的三维物体检测方法和离线基准有显著提升,甚至可以与人工标签的效果媲美。该方法还具有半监督学习和应用自动标签的能力。
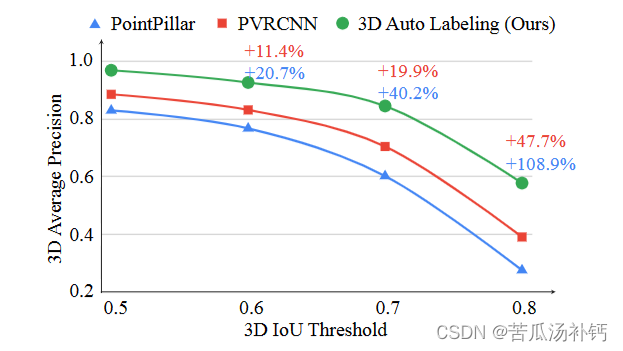
关键是使用点云序列数据来进行物体检测,并设计了一个新的离线物体检测管道,利用多帧物体检测和新的物体中心检测模型来提高检测准确性。同时,还利用了物体轨迹数据来对物体的运动状态进行分类,并引入了一个动态物体自动标注模型和一个静态物体自动标注模型来生成高质量的自动标注数据。这些自动标注数据可以用于半监督学习,以提高检测性能。
Motivation
- 由于有限的输入和速度限制,现有的3D目标检测器无法满足机外使用的高质量要求。大多数3D预测研究都集中在实时车载用例上,只考虑来自当前帧或少数历史帧的传感器输入。
- 4D标注数据内含物体动态行为信息,为高等级自动驾驶的必要输入;
- 4D人工标注极为耗时,据统计,人工标注25秒10Hz的点云序列中物体4D框,平均需要10小时,成本高,可扩展性差。
整体架构流程
该方法主要运用coarse-to-fine的思想使得检测结果更为准确:
技术细节
为了充分利用时态点云,摒弃了基于帧的通用输入结构,其中点云的整个帧被合并。转向以目标为中心的设计。首先利用性能最佳的多帧检测器来提供初始目标定位。然后,通过多目标跟踪链接在不同帧中检测到的目标。基于检测box和原始点云序列,可以提取物体的整个跟踪数据,包括其所有传感器数据(点云)和检测box,即4D:3D空间+1D时间。然后,提出了新的深度网络模型来处理这样的4D目标跟踪数据,并输出时间已知且高质量的目标box。
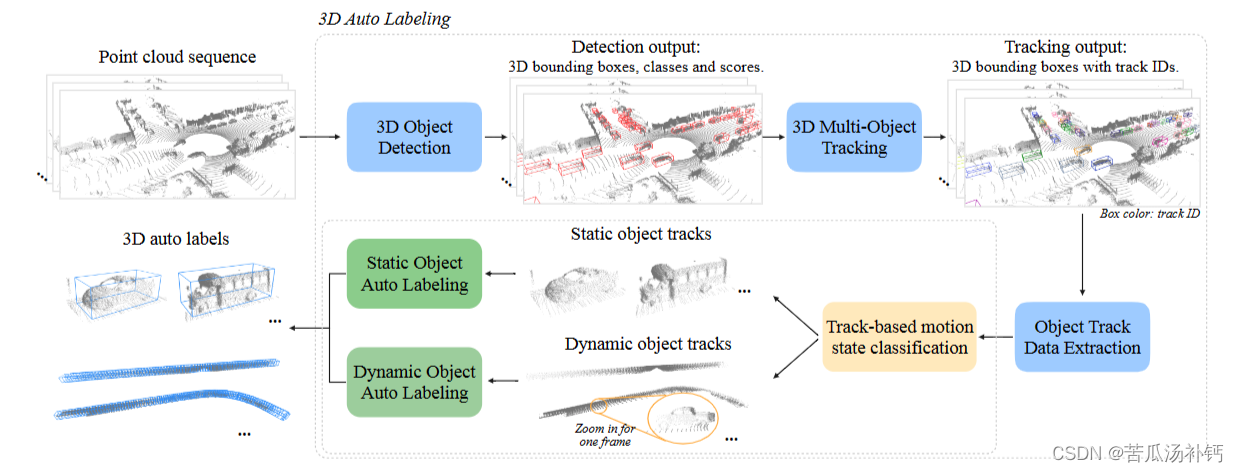
3D Auto Labeling Pipeline
3D Auto Labeling管道。给定一个点云序列作为输入,管道首先利用3D对象检测器来定位每一帧中的对象。然后跨帧的对象框通过多目标跟踪器链接。为每个对象提取对象跟踪数据(其每帧的点云及其 3D 边界框),然后通过以对象为中心的自动标记(静态和动态轨迹的分而治之)生成最终的“自动标签”,即细化的 3D 边界框。
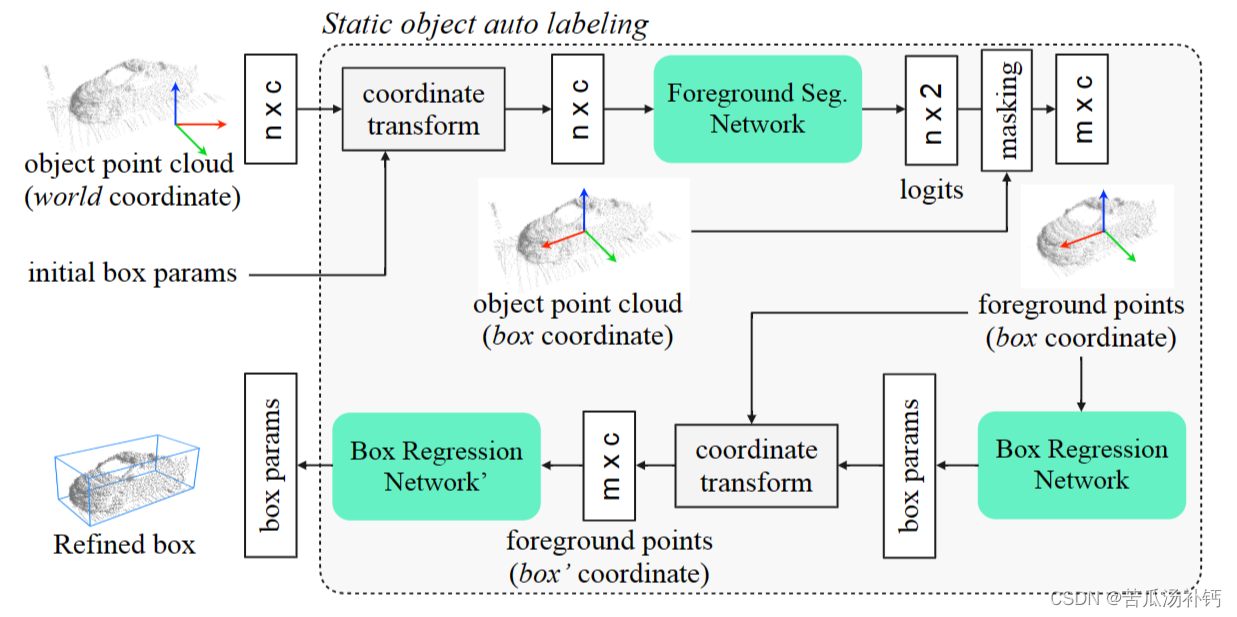
The static object auto labeling model
静态对象自动标记模型。将世界坐标中合并的对象点作为输入,模型输出静态对象的单个框。
先做前景分割,分割出前景背景点.然后用提取前景点,回归物体的目标框.
1)前景分割的网络:PointNet分割网络,MLPx5 -> 1024->maxpool -> concat to 1088(1024 + 64)->预测出2维
2)目标框回归网络:PointNet的变体,输出(3 dim,heading,size,cls)
3)进行级联微调,再让transform过的前景点经过一次目标框回归网络.
两个回归网络共享参数的效果更好。
The dynamic object auto labeling model
动态对象自动标记模型。以一系列对象点和一系列对象框,模型以滑动窗口方式运行,并为中心帧输出细化的 3D 框。输入点和框颜色表示帧。
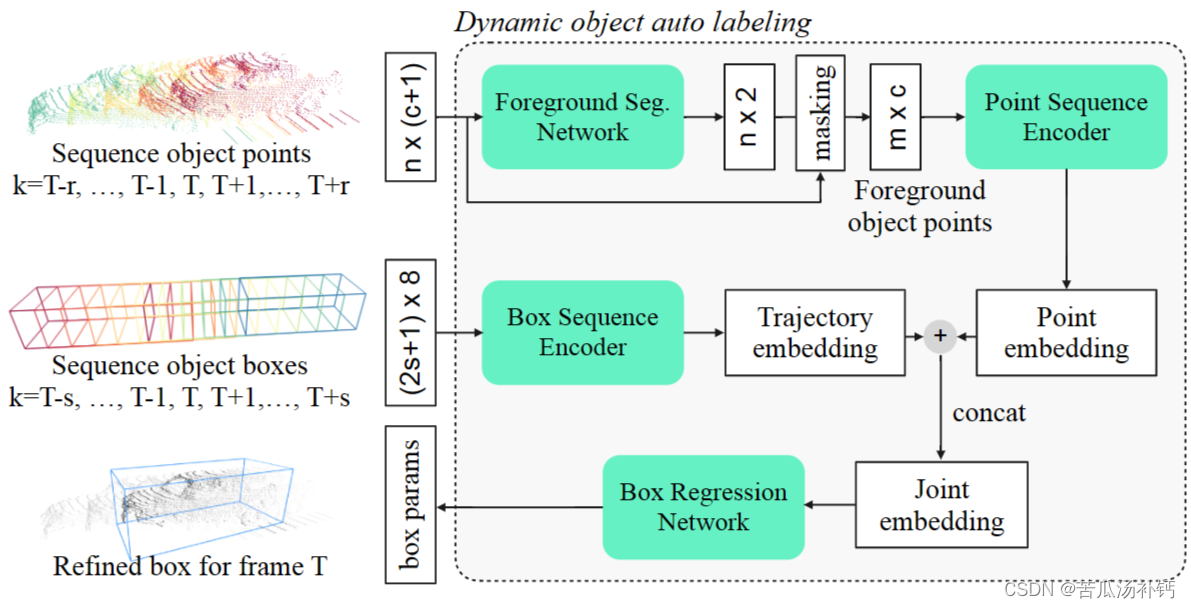
对于点云分支,模型采用目标点云的子序列。向每个点添加时间编码通道后,子序列点通过并集合并,并在中心帧处为检测器box的box坐标。接着有一个基于PointNet的分割网络来对前景点进行分类,然后通过另一个点编码网络将目标点编码为一个embedding。对于长方体序列分支,长方体序列帧将转换为长方体框架处探测器box的坐标。长方体子序列可以比点子序列长,以捕获长的轨迹嵌入,其中每个box是一个具有7维几何和1维时间编码的点。然后,将计算出的目标嵌入和轨迹嵌入连接起来,形成联合嵌入,然后通过一个box回归网络预测帧处的目标box。(参考:Offboard 3D Object Detection From Point Cloud Sequences-CSDN博客)
小结
- 制定车载 3D 目标检测问题和特定管道 (3D Auto Labeling) 的提议,该管道利用了我们的多帧检测器和新颖的以对象为中心的自动标记模型;
- 在具有挑战性的Waymo开放数据集上实现最先进的3D目标检测性能;
- 3D目标检测的人体标签研究,以及人体标签和自动标签之间的比较;
- 证明了自动标签对半监督学习的有效性。
这篇关于论文阅读:Offboard 3D Object Detection from Point Cloud Sequences的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








