本文主要是介绍Unity SRP 管线【第二讲:Draw Call】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考:
https://edu.uwa4d.com/lesson-detail/282/1309/0?isPreview=0
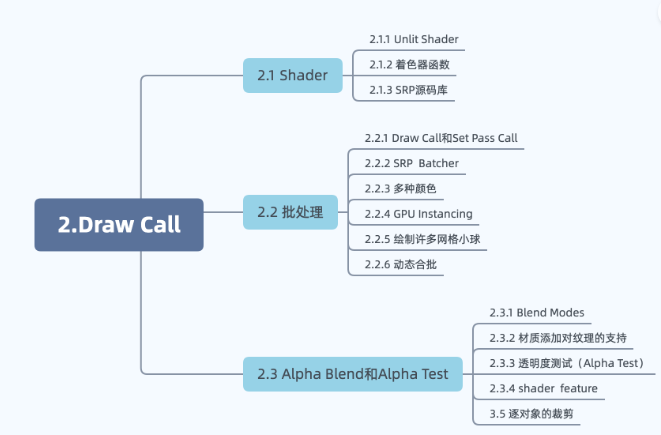
文章目录
- 参考:
- 一、Shader
- 1.HLSL引入
- 2.获取Unity提供的标准输入
- 3.Unity提供的运算库
- SpaceTransform库的宏对应
- 补充:
- 4.标准库Common.hlsl
- 5.SpaceTransforms库引入Common.hlsl
- 6.Shader文件
- 二、批处理
- 1.SRP batch
- SRP batcher的工作原理:
- SRP batcher的使用
- (1)声明常量缓冲区
- (2)启动SRP Batcher
- 注意:
- 其他
- 2. GPU Instancing
- GPU Instancing工作原理
- GPU Instancing的使用
- (1) 使当前Shader支持实例化
- (2)引入SRP源码,UnityInstancing.hlsl,使用里面的宏和方法
- 宏定义
- 使用
- (3)创建实例化常量缓存区
- (4)在片元函数中提供对象索引
- (5) 运行GPU Instancing
- (6) 填充材质的数组元素
- (7) 渲染结果
- 3. 动态合批
- 三、Alpha混合与Alpha测试
一、Shader
在SRP管线中使用HLSL语言,虽然CG语言是完全跨平台的语言,但是已经很久没有更新了。所有SRP使用HLSL替代CG语言。
1.HLSL引入
使用如下代码包裹hlsl内容。并定义vertex,fragment函数入口名称。
HLSLPROGRAM
#progma vertex vertexName
#progma fragment fragmentNameENDHLSL
可以使用#include引入hlsl文件
HLSLPROGRAM
#progma vertex vertexName
#progma fragment fragmentName
#include “UnlitPass.hlsl”
ENDHLSL
使用#include指令会将其他文件的所有内容插入#include处,如果有多个文件需要嵌套包含,则有可能造成同一文件被多次包含,造成重复代码、重复声明和编译错误。使用#define指令保证同一文件只能包含一次。
#ifndef DEFINE_FILE_INCLUDED
#define DEFINE_FILE_INCLUDED
#endif
2.获取Unity提供的标准输入
unity会在每次绘制时,将物体的参数,摄像机的参数,保存到特定名称的变量中供HLSL着色器文件使用。
类似于OpenGL中将特定变量传入GPU的Uniform变量中。
只有当着色器中声明了该变量,我们才能获取到它的值。
标准输入包含但不限于如下变量:
//存放unity标准输入库
#ifndef CUSTOM_UNITY_INPUT_INCLUDED
#define CUSTOM_UNITY_INPUT_INCLUDEDfloat4x4 unity_ObjectToWorld;
float4x4 unity_WorldToObject;
float4x4 unity_MatrixVP;
float4x4 unity_MatrixV;
real4 unity_WorldTransformParams;
float4x4 glstate_matrix_projection;
float4x4 unity_MatrixPreviousMI;
float4x4 unity_MatrixPreviousM;#endif
3.Unity提供的运算库
#include "Package/com.unity.render-pipelines.core/ShaderLibrary/SpaceTransform"
使用如上库进行空间转换,包含的函数有:
float4x4 GetObjectToWorldMatrix()
float4x4 GetWorldToObjectMatrix()
float4x4 GetPrevObjectToWorldMatrix()
float4x4 GetPrevWorldToObjectMatrix()
float4x4 GetWorldToViewMatrix()
float4x4 GetWorldToHClipMatrix()// Transform to homogenous clip space
float4x4 GetViewToHClipMatrix()// Transform to homogenous clip space// This function always return the absolute position in WS
float3 GetAbsolutePositionWS(float3 positionRWS)
// This function return the camera relative position in WS
float3 GetCameraRelativePositionWS(float3 positionWS)
float3 TransformObjectToWorld(float3 positionOS)
float3 TransformWorldToObject(float3 positionWS)
float3 TransformWorldToView(float3 positionWS)
// Transforms position from object space to homogenous space
float4 TransformObjectToHClip(float3 positionOS)
// Tranforms position from world space to homogenous space
float4 TransformWorldToHClip(float3 positionWS)
// Tranforms position from view space to homogenous space
float4 TransformWViewToHClip(float3 positionVS)
// Normalize to support uniform scaling
float3 TransformObjectToWorldDir(float3 dirOS, bool doNormalize = true)
// Normalize to support uniform scaling
float3 TransformWorldToObjectDir(float3 dirWS, bool doNormalize = true)
// Tranforms vector from world space to view space
real3 TransformWorldToViewDir(real3 dirWS, bool doNormalize = false)
// Tranforms vector from world space to homogenous space
real3 TransformWorldToHClipDir(real3 directionWS, bool doNormalize = false)
// Transforms normal from object to world space
float3 TransformObjectToWorldNormal(float3 normalOS, bool doNormalize = true)
// Transforms normal from world to object space
float3 TransformWorldToObjectNormal(float3 normalWS, bool doNormalize = true)
real3x3 CreateTangentToWorld(real3 normal, real3 tangent, real flipSign)
real3 TransformTangentToWorld(float3 dirTS, real3x3 tangentToWorld)
real3 TransformWorldToTangent(real3 dirWS, real3x3 tangentToWorld)
real3 TransformTangentToObject(real3 dirTS, real3x3 tangentToWorld)
real3 TransformObjectToTangent(real3 dirOS, real3x3 tangentToWorld)
该函数内包含宏,但没有宏定义,需要自己将Uniform变量与SpaceTransform库中的宏对应起来。
SpaceTransform库的宏对应
- 首先
#includeUnity标准输入 - 其次定义宏(包含如下宏,但不限于)
#define UNITY_MATRIX_M unity_ObjectToWorld
#define UNITY_MATRIX_I_M unity_WorldToObject
#define UNITY_MATRIX_V unity_MatrixV
#define UNITY_MATRIX_VP unity_MatrixVP
#define UNITY_MATRIX_P glstate_matrix_projection
#define UNITY_PREV_MATRIX_I_M unity_MatrixPreviousMI
#define UNITY_PREV_MATRIX_M unity_MatrixPreviousM
参照URP中标准库的定义
//URP Input.hlsl 定义
#define UNITY_MATRIX_M unity_ObjectToWorld
#define UNITY_MATRIX_I_M unity_WorldToObject
#define UNITY_MATRIX_V unity_MatrixV
#define UNITY_MATRIX_I_V unity_MatrixInvV
#define UNITY_MATRIX_P OptimizeProjectionMatrix(glstate_matrix_projection)
#define UNITY_MATRIX_I_P unity_MatrixInvP
#define UNITY_MATRIX_VP unity_MatrixVP
#define UNITY_MATRIX_I_VP unity_MatrixInvVP
#define UNITY_MATRIX_MV mul(UNITY_MATRIX_V, UNITY_MATRIX_M)
#define UNITY_MATRIX_T_MV transpose(UNITY_MATRIX_MV)
#define UNITY_MATRIX_IT_MV transpose(mul(UNITY_MATRIX_I_M, UNITY_MATRIX_I_V))
#define UNITY_MATRIX_MVP mul(UNITY_MATRIX_VP, UNITY_MATRIX_M)
#define UNITY_PREV_MATRIX_M unity_MatrixPreviousM
#define UNITY_PREV_MATRIX_I_M unity_MatrixPreviousMI
- 最后,引入
SpaceTransforms库
#include "Packages/com.unity.render-pipelines.core/ShaderLibrary/SpaceTransforms.hlsl"
补充:
空间名称缩写
- WS: world space
- RWS: Camera-Relative world space. A space where the translation of the camera have already been substract in order to improve precision(与相机相关的世界空间。为了提高精度,相机的平移量已经被减去的空间)
- VS: view space
- OS: object space
- CS: Homogenous clip spaces(齐次裁剪空间)
- TS: tangent space
- TXS: texture space
4.标准库Common.hlsl
ShaderLibrary中的头文件不包含“common.hlsl”,这应该包含在.shader文件中使用它(或Material.hlsl)。
所有Uniform都应该在内容缓冲区中,而不是在全局缓冲区中。原因是对于计算着色器,我们需要保证CBs的布局在内核之间是一致的。一些我们不能控制全局命名空间(优化的Uniforms如果不使用,修改每个内核全局CBuffer布局)
Common库中的内容(包含但不限于)
- 定义了real类型
- 定义了跨平台Shader库(D3D11,Metal,Vulkan,Switch,GLCore,GLES)
- 一般回退路径
- 一些库函数(位运算,Quad函数,内置NaN函数,Math函数,Texture程序【LOD】)
- CubeMap宏和库函数
- 结构体定义(纹理格式采样)
- sampler1D/2D/3D
- samplerCube
- tex[1D/2D/3D/CUBE]bias
- tex[1D/2D/3D/CUBE]lod
- tex[1D/2D/3D/CUBE]grad
- tex[1D/2D/3D/CUBE]
- tex[1D/2D/3D/CUBE]proj
- 深度编码/解码[Unity对深度进行的编码,如果需要得到确定的深度,需要解码计算]【
Common.hlsl P968】 - 空间变换函数【
Common.hlsl P1085】 PositionInputs结构体【Common.hlsl P1176】- 地形/刷高度图编码/解码【
Common.hlsl P1278】 - 其他函数
5.SpaceTransforms库引入Common.hlsl
因为 SpaceTransform库中使用了real,已经Common库中的函数(real3 SafeNormalize(float3 inVec)),所以#include “SpaceTransforms”之前,需要提前包含Common库。
故框架库的整体代码架构为:
//./ShaderLibrary/Common.hlsl
//对应于URP的input.hlsl文件#ifndef CUSTOM_COMMON_INCLUDED
#define CUSTOM_COMMON_INCLUDED#include "Packages/com.unity.render-pipelines.core/ShaderLibrary/Common.hlsl"
#include "UnityInput.hlsl"#define UNITY_MATRIX_M unity_ObjectToWorld
#define UNITY_MATRIX_I_M unity_WorldToObject
#define UNITY_MATRIX_V unity_MatrixV
#define UNITY_MATRIX_VP unity_MatrixVP
#define UNITY_MATRIX_P glstate_matrix_projection
#define UNITY_PREV_MATRIX_I_M unity_MatrixPreviousMI
#define UNITY_PREV_MATRIX_M unity_MatrixPreviousM#include "Packages/com.unity.render-pipelines.core/ShaderLibrary/SpaceTransforms.hlsl"#endif
6.Shader文件
Shader文件编写,只需引入库文件即可#include "../ShaderLibrary/Common.hlsl"
#ifndef CUSTOM_UNLIT_PASS_INCLUDED
#define CUSTOM_UNLIT_PASS_INCLUDED
#include "../ShaderLibrary/Common.hlsl"// vertex
float4 UnlitPassVertex(float3 positionOS : POSITION) : SV_POSITION
{float3 positionWS = TransformObjectToWorld(positionOS.xyz);return TransformWorldToHClip(positionWS);
}// fragment
float4 _BaseColor;
float4 UnlitPassFragment(): SV_TARGET
{return _BaseColor;
}#endif
二、批处理
首先我们思考,一次DrawCall前,需要进行哪些事情:
- 绑定VAO:将当前要渲染的物体数据绑定
- 绑定Shader着色器:设置当前使用的Shader
- 设置Uniform参数:参数包括数据和纹理图片
- 调用DrawCall。
可以看出:在CPU和GPU通信中,最占用通信时间的是 设置Uniform参数 ,因为每次DrawCall时,都需要在CPU段将数据上传到GPU段。而物体顶点信息(VAO)则不需要上传只需要绑定。
Uniform参数可大致分为如下几类:
- 物体的Model矩阵(每次调用DrawCall时都需要输入)
- 摄像机的VM矩阵(每帧渲染只用修改一次)
- 材质属性(材质参数、材质贴图)
如果使用通用的渲染流程:每一个物体都需要 DrawCall 时设置 Model矩阵 和 所有的材质属性 。但这对于CPU与GPU的通信消耗很大。
如果我们可以减少材质属性的通信,例如:
- 只修改那些改变的材质属性,这样就可以大大加快渲染状态的切换;
- 或者一次性传入所有的材质属性,只在GPU中切换。
批处理方法主要包含:
- SRP batch: 通过一次性将多种材质属性(材质数据和贴图)存入GPU,每次修改材质时,只需要修改绑定点,不需要CPU传入数据【要求:多个材质使用同一Shader,存入的材质属性不可再变(1次batch中)】
- GPU Instancing 实例化: 一次对具有相同网格的多个对象发出一次DrawCall指令,CPU收集所有实例对象的Transform和材质属性,将其放入数组中,发送给GPU;GPU遍历所有条目,并按提供顺序对其进行渲染。
- 动态合批: 将共享相同材质的多个小网格合并成一个较大的网络【将多个VBO(世界空间)合并成一个,只支持小网格】
三种批处理方法的区别:
- SRP batch: 不同网格,同一Shader变种,不同材质,一次Batch发送多个材质属性(不修改的话不发送),切换时修改绑定点,多次DrawCall。
- GPU Instancing 实例化: 同一网络,同一Shader变种,不同材质,一次性发送每个对象对应的材质属性,一次DrawCall。
- 动态合批: 不同网络(有网络顶点限制),同一Shader,同一材质,需要CPU每次调用时合并模型世界坐标下数据,一次DrawCall。

1.SRP batch
参考:https://docs.unity3d.com/cn/current/Manual/SRPBatcher.html
SRP batcher的工作原理:
SRP批处理程序减少了绘制调用之间的渲染状态更改。SRP Batcher结合了一系列bind和drawGPU的命令。每一个一系列的命令叫做一个SRP batch。
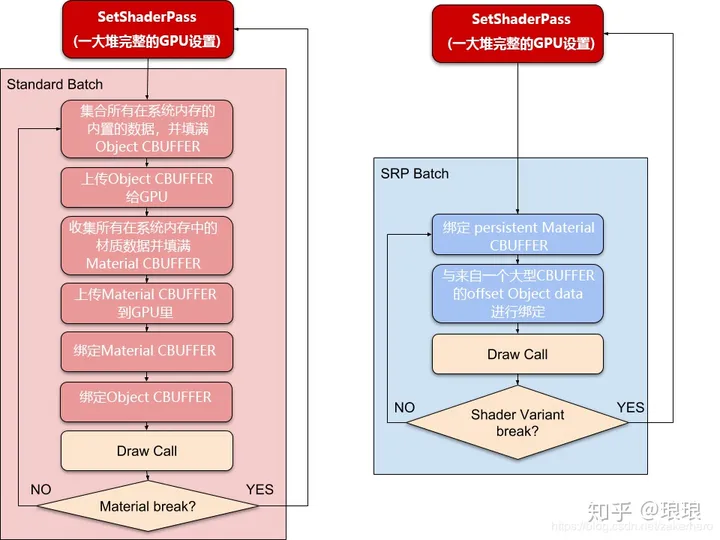
为了实现渲染的最佳性能,每个SRP批处理应该包含尽可能多的绑定和绘制命令。为了实现这一点,使用尽可能少的着色器变体。你仍然可以使用许多不同的材质和你想要的相同的着色器。
当Unity在渲染循环中检测到新材质时,CPU会收集所有属性并将它们绑定到GPU的constant buffers中。GPU缓冲区的个数取决于着色器如何声明它的constant buffers。
SRP Batcher是一个低级渲染循环,它使材料数据在GPU内存中持久化。如果材质内容没有改变,这个srp批处理程序不会改变任何渲染状态。相反,SRP批处理程序使用专用代码路径来更新大型GPU缓冲区中的Unity引擎属性,如下所示:

在这里,CPU只处理Unity引擎属性,在上图中标记为Per Object large buffer。所有材料都有位于GPU内存中的持久不变的缓冲区,可以随时使用。这加快了渲染速度,因为:
- 所有材质内容现在都保存在GPU内存中。
- 专用代码管理一个大的 per-Object GPU
constant buffers(常量缓冲区)的所有 per-Object 属性。
部分情况下,使用实例化会比SRP更有效,关闭SRP才能使用实例化程序。请使用Profiler分析器确保那种方式更有效。
SRP batcher的使用
SRP Batcher会在主存中将模型的坐标信息、材质信息、主光源阴影参数、非主光源阴影参数分别保存到不同的CBUFFER(常量缓冲区)中,只有CBUFFER发送变化时才会重新提交到GPU并保存。(与OpenGL的Uniform块同理)
附加知识点:常量缓冲区


(1)声明常量缓冲区
在unityInput.hlsl文件中定义物体矩阵全局变量块(UnityPerDraw)
如下四个定义缺一不可,否则无法使用SRP。如果我们要使用一组特定值的其中一个值,我们必须把这组特定值全部定义出来
CBUFFER_START(UnityPerDraw)float4x4 unity_ObjectToWorld;float4x4 unity_WorldToObject;float4 unity_LODFade;real4 unity_WorldTransformParams;
CBUFFER_END
在当前Shader文件中定义材质属性的全局变量块(UnityPerMaterial)
CBUFFER_START(UnityPerMaterial)float4 _BaseColor;
CBUFFER_END
(2)启动SRP Batcher
在C#脚本中添加
GraphicsSettings.useScriptableRenderPipelineBatching = true;
即可开启SRP Batcher
注意:
合批操作只能合并相邻渲染顺序中的多个物体,如果合批操作的多个物体渲染中,有其他类型的物体渲染,则会打断合批操作。
例如:如下因为Draw Mesh Cube(2)的操作打断了上下两个SRP Batch,所以有两次合批处理




修改物体位置,使得 蓝色圆柱 的渲染顺序在 浅蓝立方体 之前。


三个物体在同一批次被渲染。
其他
SRP开启SRP batcher,但是Statistics面板仍显示【Saved by batching = 0】,这是Statistics面板的错误,我们需要其他方法来分析SRP batcher带来的性能优化。

链接:https://zhuanlan.zhihu.com/p/432223843
2. GPU Instancing
GPU Instancing工作原理
GPU Instancing能够在一个绘制调用中渲染多个相同网格的物体,CPU收集材质属性和变换,放入GPU中,GPU遍历数组按顺序渲染。
一次渲染中,CPU将每个实例的不同信息存储在一块缓冲区(可以是顶点缓冲区,也可以是Uniform常量缓冲区)中,将模型信息存储在另一块缓冲区中。
GPU Instancing的使用
(1) 使当前Shader支持实例化
要支持GPU Instancing,首先需要添加#pragma multi_compile_instancing,然后在材质球界面上就可以看到 Enable GPU Instancing 按钮切换开关。
Shader "CustomRP/UnlitShader"
{...SubShader{Pass{HLSLPROGRAM#pragma vertex UnlitPassVertex#pragma fragment UnlitPassFragment#pragma multi_compile_instancing#include "./UnlitPass.hlsl"ENDHLSL}}
}
(2)引入SRP源码,UnityInstancing.hlsl,使用里面的宏和方法
//common.hlsl
#include "Packages/com.unity.render-pipelines.core/ShaderLibrary/UnityInstancing.hlsl"
宏定义
UnityInstancing.hlsl中重新定义了一些宏去访问数据数组,例如:
UNITY_VERTEX_INPUT_INSTANCE_ID—>uint instanceID : SV_InstanceID;//简化定义
// basic instancing setups
// - UNITY_VERTEX_INPUT_INSTANCE_ID Declare instance ID field in vertex shader input / output struct.
// - UNITY_GET_INSTANCE_ID (Internal) Get the instance ID from input struct.
#define DEFAULT_UNITY_VERTEX_INPUT_INSTANCE_ID uint instanceID : SV_InstanceID;
#define UNITY_VERTEX_INPUT_INSTANCE_ID DEFAULT_UNITY_VERTEX_INPUT_INSTANCE_ID#define UNITY_GET_INSTANCE_ID(input) input.instanceID
UNITY_SETUP_INSTANCE_ID(input)
必须在顶点着色器/片段着色器的最开始使用,以便后续代码可以访问全局unity_InstanceID。用来提取顶点输入结构体中的渲染对象的索引,并将其存储到其他实例宏所依赖的全局静态变量中。
// - UNITY_SETUP_INSTANCE_ID Should be used at the very beginning of the vertex shader / fragment shader,
// so that succeeding code can have access to the global unity_InstanceID.
// Also procedural function is called to setup instance data.
// - UNITY_TRANSFER_INSTANCE_ID Copy instance ID from input struct to output struct. Used in vertex shader.void UnitySetupInstanceID(uint inputInstanceID){//GLES3下定义unity_StereoEyeIndex = round(fmod(inputInstanceID, 2.0));unity_InstanceID = unity_BaseInstanceID + (inputInstanceID >> 1);
}
#define DEFAULT_UNITY_SETUP_INSTANCE_ID(input)//其中之一的定义
{ UnitySetupInstanceID(UNITY_GET_INSTANCE_ID(input));
}
#define UNITY_SETUP_INSTANCE_ID(input) DEFAULT_UNITY_SETUP_INSTANCE_ID(input)
input是顶点函数(vertex)的输入变量,input.instanceID即为当前顶点的实例ID
使用
- 定义结构体
- 结构体内包含UNITY_VERTEX_INPUT_INSTANCE_ID
- Vertex着色器中通过UNITY_SETUP_INSTANCE_ID(input);将索引储存起来,用于其他宏内的使用。
struct Attributes
{float3 positionOS : POSITION;UNITY_VERTEX_INPUT_INSTANCE_ID
}// vertex
float4 UnlitPassVertex(Attributes input) : SV_POSITION
{UNITY_SETUP_INSTANCE_ID(input);float3 positionWS = TransformObjectToWorld(input.positionOS);return TransformWorldToHClip(positionWS);
}
如上代码和近似为
struct Attributes
{float3 positionOS : POSITION;uint instanceID : SV_InstanceID;
};//注意:这里要有分号// vertex
float4 UnlitPassVertex(Attributes input) : SV_POSITION
{UnitySetupInstanceID(input.instanceID);//将instanceID保存到UnityInstancing.hlsl中其他宏内会使用的全局变量unity_InstanceID float3 positionWS = TransformObjectToWorld(input.positionOS);return TransformWorldToHClip(positionWS);
}
(3)创建实例化常量缓存区
现在的问题有两个
- GPU Instancing的优先级低于SRP Batcher,所以需要关闭或打断SRP Batcher。
- 现在只实现了实例化不同的空间坐标,但未实现实例化不同的材质数据。
我们需要用一个数据BUFFER保存不同实例的材质数据
UNITY_INSTANCING_BUFFER_START(UnityPerMaterial)UNITY_DEFINE_INSTANCED_PROP(float4, _BaseColor);
UNITY_INSTANCING_BUFFER_END(UnityPerMaterial)
宏定义源码UNITY_INSTANCING_BUFFER_START,UNITY_INSTANCING_BUFFER_END,UNITY_DEFINE_INSTANCED_PROP
如果没有定义UNITY_DOTS_INSTANCING_ENABLED则为:
#define UNITY_INSTANCING_BUFFER_START(buf) UNITY_INSTANCING_CBUFFER_SCOPE_BEGIN(UnityInstancing_##buf) struct {
#define UNITY_INSTANCING_BUFFER_END(arr) } arr##Array[UNITY_INSTANCED_ARRAY_SIZE]; UNITY_INSTANCING_CBUFFER_SCOPE_END
#define UNITY_DEFINE_INSTANCED_PROP(type, var) type var;
#define UNITY_ACCESS_INSTANCED_PROP(arr, var) arr##Array[unity_InstanceID].var
继续还原
#define UNITY_INSTANCING_CBUFFER_SCOPE_BEGIN(name) CBUFFER_START(name)
#define UNITY_INSTANCING_CBUFFER_SCOPE_END CBUFFER_END
展开宏,则为
CBUFFER_START(UnityInstancing_UnityPerMaterial)
struct{float4 _BaseColor;
}UnityPerMaterialArray[UNITY_INSTANCED_ARRAY_SIZE];
CBUFFER_END
(4)在片元函数中提供对象索引
#ifndef CUSTOM_UNLIT_PASS_INCLUDED
#define CUSTOM_UNLIT_PASS_INCLUDED
#include "../ShaderLibrary/Common.hlsl"//CBUFFER_START(UnityPerMaterial)
// float4 _BaseColor;
//CBUFFER_ENDUNITY_INSTANCING_BUFFER_START(UnityPerMaterial)UNITY_DEFINE_INSTANCED_PROP(float4, _BaseColor)
UNITY_INSTANCING_BUFFER_END(UnityPerMaterial)struct Attributes
{float3 positionOS : POSITION;UNITY_VERTEX_INPUT_INSTANCE_ID
};struct Varyings{float4 positionCS : SV_POSITION;float2 baseUV : VAR_BASE_UV;UNITY_VERTEX_INPUT_INSTANCE_ID
};Varyings UnlitPassVertex(Attributes input)
{Varyings output;UNITY_SETUP_INSTANCE_ID(input);UNITY_TRANSFER_INSTANCE_ID(input,output);float3 positionWS = TransformObjectToWorld(input.positionOS);output.positionCS = TransformWorldToHClip(positionWS);return output;
}
float4 UnlitPassFragment(Varyings input): SV_TARGET
{UNITY_SETUP_INSTANCE_ID(input)//在vertex中使用,在fragment中也不可忽略return UNITY_ACCESS_INSTANCED_PROP(UnityPerMaterial,_BaseColor);
}
#endif
源码分析: UNITY_TRANSFER_INSTANCE_ID(input,output);
#define UNITY_TRANSFER_INSTANCE_ID(input, output) output.instanceID = UNITY_GET_INSTANCE_ID(input)
如上代码展开变为(因为平台和图形API的不同,所以这种展开只是其中好理解的一种,并不能保证可以运行)
#ifndef CUSTOM_UNLIT_PASS_INCLUDED
#define CUSTOM_UNLIT_PASS_INCLUDED
#include "../ShaderLibrary/Common.hlsl"CBUFFER_START(UnityInstancing_UnityPerMaterial)struct{float4 _BaseColor;} UnityPerMaterialArray[UNITY_INSTANCED_ARRAY_SIZE];
CBUFFER_ENDstruct Attributes
{float3 positionOS : POSITION;uint instanceID : SV_InstanceID;
};struct Varyings{float4 positionCS : SV_POSITION;float2 baseUV : VAR_BASE_UV;uint instanceID;
};Varyings UnlitPassVertex(Attributes input)
{Varyings output;unity_InstanceID = input.instanceID ;output.instanceID = input.instanceID ;float3 positionWS = TransformObjectToWorld(input.positionOS);output.positionCS = TransformWorldToHClip(positionWS);return output;
}
float4 UnlitPassFragment(Varyings input): SV_TARGET
{unity_InstanceID = input.instanceID ;return UnityPerMaterialArray[unity_InstanceID]._BaseColor;
}
#endif
(5) 运行GPU Instancing
- 取消BRP Batcher
//GraphicsSettings.useScriptableRenderPipelineBatching = true;
-
开启Shader的GPU Instancing(将Render Queue设置为同一批次,否则可能会被其他物体渲染打断),同时将三个物体的Material设置为同一个。

-
测试


结果分析:GPU Instancing运行成功,但是使用相同材质只有一个BaseColor。
(6) 填充材质的数组元素
使用脚本添加属性
调用实例化DrawCall函数需要如下几个参数(有多个重写函数,按照需要填写)
// 数据定义
[SerializeField] Mesh mesh = default;
[SerializeField] Material material = default;
Matrix4x4[] matrices = new Matrix4x4[1023];
Vector4[] baseColors = new Vector4[1023];
// MaterialPropertyBlock 块定义 以及 填充
static int baseColorId = Shader.PropertyToID("_BaseColor");
MaterialPropertyBlock block;
block = new MaterialPropertyBlock();
block.SetVectorArray(baseColorId, baseColors);Graphics.DrawMeshInstanced(mesh, 0, material, matrices, 1023, block);
Graphics.DrawMeshInstanced(mesh, 0, material, matrices, 1023, block,...);
- mesh:
[SerializeField] Mesh mesh = default; - submeshIndex:绘制网格的哪个子集。这只适用于由几种材料组成的网格。
- material:
[SerializeField] Material material = default; - matrices:对象变换矩阵的数组。
Matrix4x4[] matrices = new Matrix4x4[1023]; - count:要绘制的实例数。【最大为1023】
- properties:适用的其他材料属性。详见MaterialPropertyBlock。
- castShadows:确定网格是否应该投射阴影。
- receiveShadows:确定网格是否应该接收阴影。
- layer: to use.
- camera:If null (default), the mesh will be drawn in all cameras. Otherwise it will be drawn in the given Camera only.
- lightProbeUsage:LightProbeUsage for the instances.
(7) 渲染结果
2023 个实例被分成 3 个 DrawCall 调用,分别为 511、511、1(这不是确定的,根据机器不同,平台不同会有不同的结果),单个网络的绘制顺序,与我们提供的数组数据的顺序相同。




3. 动态合批
在DrawingSettings中设置,是否开启动态合批和GPU实例化
// 设置渲染的 Shader Pass 和排序模式
var drawingSettings = new DrawingSettings(unlitShaderTagID, sortingSettings)//使用哪个ShaderID,以什么一定顺序渲染的设定
{//动态合批enableDynamicBatching = useDynamicBatching,//实例化enableInstancing = useGPUInstancing,
};
如果动态合批开启,Unity自动判断是否可以动态合批。
若未开启动态合批:



若开启动态合批,Vertices和Indices的数量为合批网络的总和


三、Alpha混合与Alpha测试
暂时跳过
知识点:
- 设置混合模式
- Pass是否写入深度
- 材质对纹理的支持
- Shader Feature:让Unity根据不同定义条件或关键字编译多次,生成多个着色器变体。
这篇关于Unity SRP 管线【第二讲:Draw Call】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!