本文主要是介绍Kaggle竞赛 Real or Not? NLP with Disaster Tweets 文本分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 前言
- 一、比赛介绍
- 二、解决方案(探索式资料分析&清洗数据)
- 2-1、介绍和引言
- 2-2、对于特征keyword(关键字)和location(地点)的处理
- 2-3、组成新特征
- 2-4、target分布
- 2-5、文本清理
- 2-6、错误标签样本处理
- 三、训练模型
- 3-1、加载所需包
- 3-2、数据的进一步处理
- 3-3、添加特征并绘图
- 3-4、训练模型
- 总结
前言
在这场竞赛中,你面临的挑战是建立一个机器学习模型,预测哪些推文是关于真实灾难的,哪些不是。你将有权访问由 10,000 条手动分类的推文组成的数据集。一、比赛介绍
来源:kaggle竞赛- Natural Language Processing with Disaster Tweets
任务:我们需要根据文章的location、keyword以及文本text来判断这篇推文是否和灾难有关,相关部门可以据此来第一时间发现可能存在的灾难并且迅速做出反应,将损失降低到最低。
二、解决方案(探索式资料分析&清洗数据)
2-1、介绍和引言
导入库、读取数据、分析:
import re
import string
import operator
from collections import defaultdictimport matplotlib.pyplot as plt
import seaborn as snsfrom sklearn.model_selection import StratifiedKFold, StratifiedShuffleSplit
from sklearn.metrics import precision_score, recall_score, f1_scoredf_train = pd.read_csv('/kaggle/input/nlp-getting-started/train.csv')
df_test = pd.read_csv('/kaggle/input/nlp-getting-started/test.csv')print(f'Training Set Shape: {df_train.shape}')
print(f'Test Set Shape: {df_test.shape}')
数据规模:Training Set Shape: (7613, 5); Test Set Shape: (3263, 4)
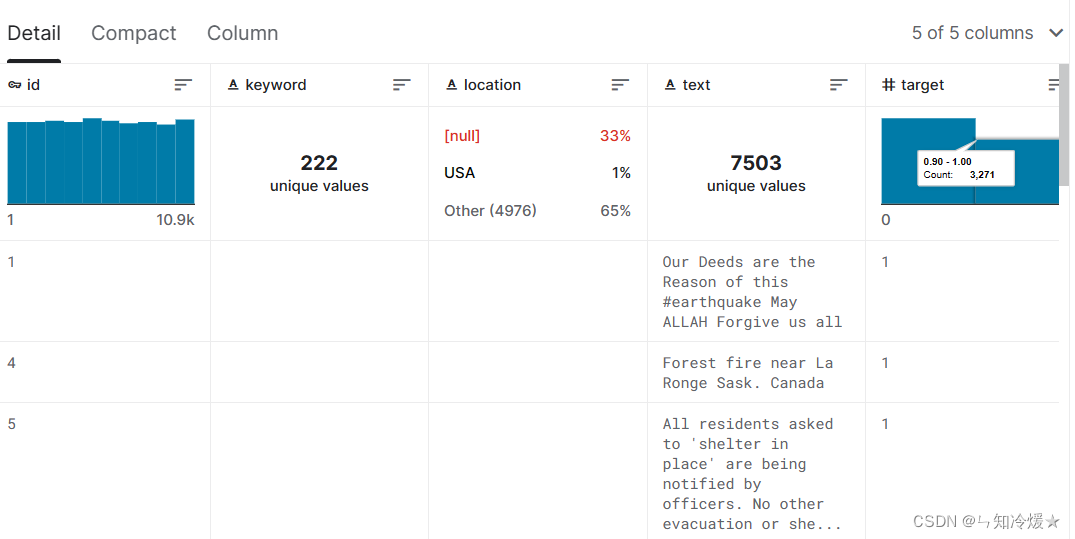
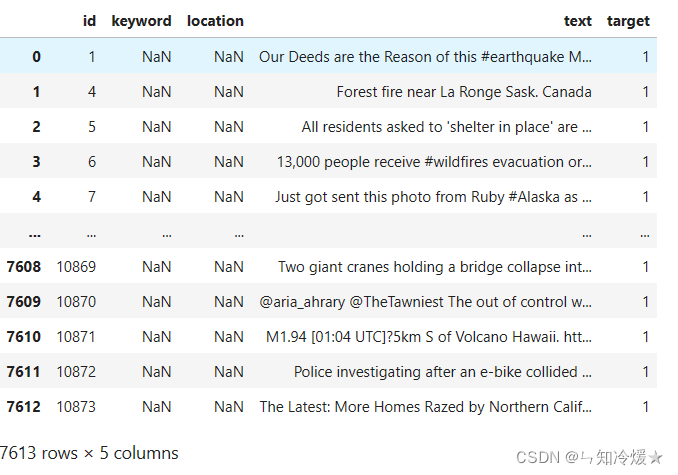
训练集:
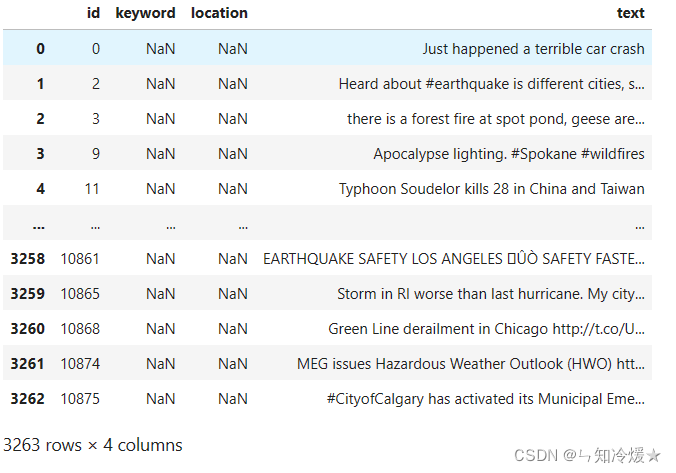
验证集:
2-2、对于特征keyword(关键字)和location(地点)的处理
一、探索空值的数量:
print(df_train['location'].isnull().sum())
print(df_train['keyword'].isnull().sum())
输出:
2533 61
二、缺失值的处理: 使用空字符串 ‘’ 来替代缺失值,将缺失值用空字符串填充。
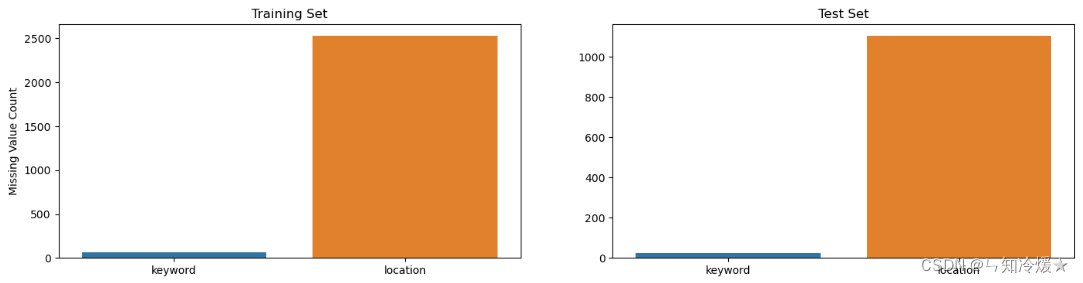
missing_cols = ['keyword', 'location']fig, axes = plt.subplots(ncols=2, figsize=(17, 4), dpi=100)sns.barplot(x=df_train[missing_cols].isnull().sum().index, y=df_train[missing_cols].isnull().sum().values, ax=axes[0])
sns.barplot(x=df_test[missing_cols].isnull().sum().index, y=df_test[missing_cols].isnull().sum().values, ax=axes[1])axes[0].set_ylabel('Missing Value Count')
axes[0].set_title('Training Set')
axes[1].set_title('Test Set')plt.show()for df in [df_train, df_test]:for col in ['keyword', 'location']:# df[col] = df[col].fillna(f'no_{col}')# 在该方法中,使用空字符串 '' 来替代缺失值,将缺失值用空字符串填充。df[col] = df[col].fillna('')
输出:如图输出所示,训练集和测试集的loaction字段缺失较多。
三、分布探索: 输出其唯一的值的数量;
print(f"Number of unique values in keyword = {df_train['keyword'].nunique()} (Training) - {df_test['keyword'].nunique()} (Test)")
print(f"Number of unique values in location = {df_train['location'].nunique()} (Training) - {df_test['location'].nunique()} (Test)")
输出:
Number of unique values in keyword = 221 (Training) - 221 (Test)
Number of unique values in location = 3341 (Training) - 1602 (Test)
四、关键字分布探索
# 以keyword来分组抽取target的平均值
df_train['target_mean'] = df_train.groupby('keyword')['target'].transform('mean')fig = plt.figure(figsize=(8,72), dpi=100)# 绘制图形,根据关键字keyword,并且根据target_mean降序排列
sns.countplot(y=df_train.sort_values(by='target_mean', ascending=False)['keyword'], hue=df_train.sort_values(by='target_mean', ascending=False)['target'])plt.legend(loc=1)
plt.title('Target Distribution in Keywords')plt.show()# 删除掉列
df_train.drop(columns=['target_mean'], inplace=True)
部分输出:从图中我们可以得知,keyword与label之间有可见的相关性,有些词只在灾难推文中出现,而有些词只在非灾难推文中出现。
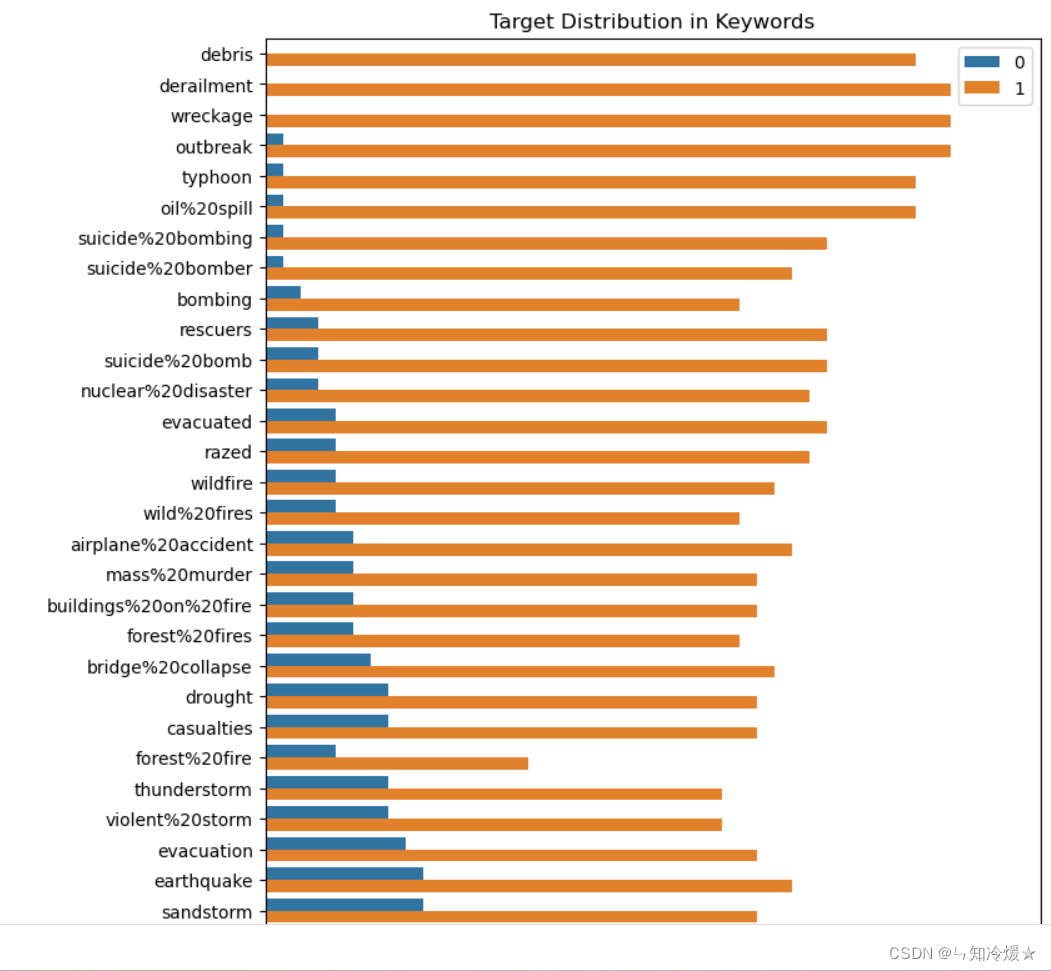
看一下上边输出添加了target_mean的df是什么样子: df_train.sort_values(by=‘target_mean’, ascending=False)

2-3、组成新特征
一、组成新特征:单词数量、唯一的单词数量、停用词数量、url数量、单词平均长度、字符串长度、标点符号数量、#数量、@数量。(#开头的一般是标签,即考虑标签数量,@一般是提及什么朋友,即提到的人数量。)
# word_count
df_train['word_count'] = df_train['text'].apply(lambda x:len(str(x).split()))
df_test['word_count'] = df_test['text'].apply(lambda x:len(str(x).split()))# unique_word_count
df_train['unique_word_count'] = df_train['text'].apply(lambda x:len(set(str(x).split())))
df_test['unique_word_count'] = df_test['text'].apply(lambda x:len(set(str(x).split())))# stop_word_count
from wordcloud import STOPWORDS
df_train['stop_word_count'] = df_train['text'].apply(lambda x: len([w for w in str(x).lower().split() if w in STOPWORDS]))
df_test['stop_word_count'] = df_test['text'].apply(lambda x: len([w for w in str(x).lower().split() if w in STOPWORDS]))# url_count
df_train['url_count'] = df_train['text'].apply(lambda x: len([w for w in str(x).lower().split() if 'http' in w or 'https' in w]))
df_test['url_count'] = df_test['text'].apply(lambda x: len([w for w in str(x).lower().split() if 'http' in w or 'https' in w]))# mean_word_length
df_train['mean_word_length'] = df_train['text'].apply(lambda x: np.mean([len(w) for w in str(x).split()]))
df_test['mean_word_length'] = df_test['text'].apply(lambda x: np.mean([len(w) for w in str(x).split()]))# char_count
df_train['char_count'] = df_train['text'].apply(lambda x: len(str(x)))
df_test['char_count'] = df_test['text'].apply(lambda x: len(str(x)))# punctuation_count
df_train['punctuation_count'] = df_train['text'].apply(lambda x:len([c for c in str(x) if c in string.punctuation]))
df_test['punctuation_count'] = df_test['text'].apply(lambda x:len([c for c in str(x) if c in string.punctuation]))# hashtag_count
df_train['hashtag_count'] = df_train['text'].apply(lambda x: len([c for c in str(x) if c == '#']))
df_test['hashtag_count'] = df_test['text'].apply(lambda x: len([c for c in str(x) if c == '#']))# mention_count
df_train['mention_count'] = df_train['text'].apply(lambda x: len([c for c in str(x) if c == '@']))
df_test['mention_count'] = df_test['text'].apply(lambda x: len([c for c in str(x) if c == '@']))
# 输出df_train
输出:看看添加了新特征的df_train什么样子。
二、观察新特征上灾难和不是灾难的分布情况、每个特征训练集和验证集上的分布情况
meta_features = ['word_count', 'unique_word_count', 'stop_word_count', 'url_count', 'mean_word_length', 'char_count', 'punctuation_count']
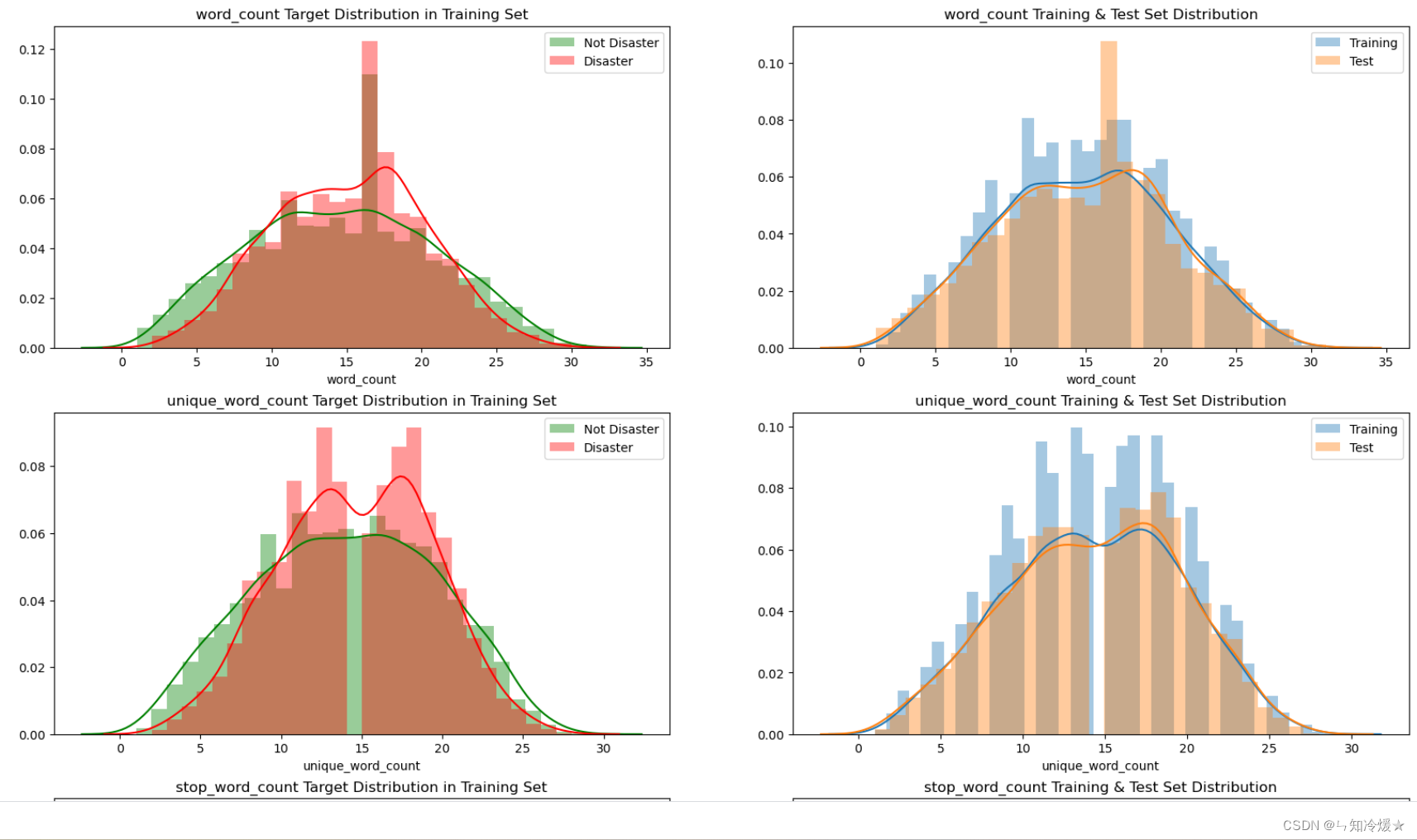
disaster_tweets = df_train['target'] == 1fig, axes = plt.subplots(ncols=2, nrows=len(meta_features), figsize=(20,40), dpi=100)for i, feature in enumerate(meta_features):sns.distplot(df_train.loc[~disaster_tweets][feature], label='Not Disaster', ax=axes[i][0], color='green')sns.distplot(df_train.loc[disaster_tweets][feature], label='Disaster', ax=axes[i][0], color='red')sns.distplot(df_train[feature], label='Training', ax=axes[i][1])sns.distplot(df_test[feature], label='Test', ax=axes[i][1])for j in range(2):axes[i][j].legend()axes[i][0].set_title(f'{feature} Target Distribution in Training Set')axes[i][1].set_title(f'{feature} Training & Test Set Distribution')plt.show()
输出:这里只展示部分图片,根据图片显示,分布大概一致,可以使用,如果出现一些偏差比较大的分布,可以考虑直接砍掉特征,如果是训练集和验证集分布不一致,可以考虑重新整理一下验证集,使得分布大概相同。
2-4、target分布
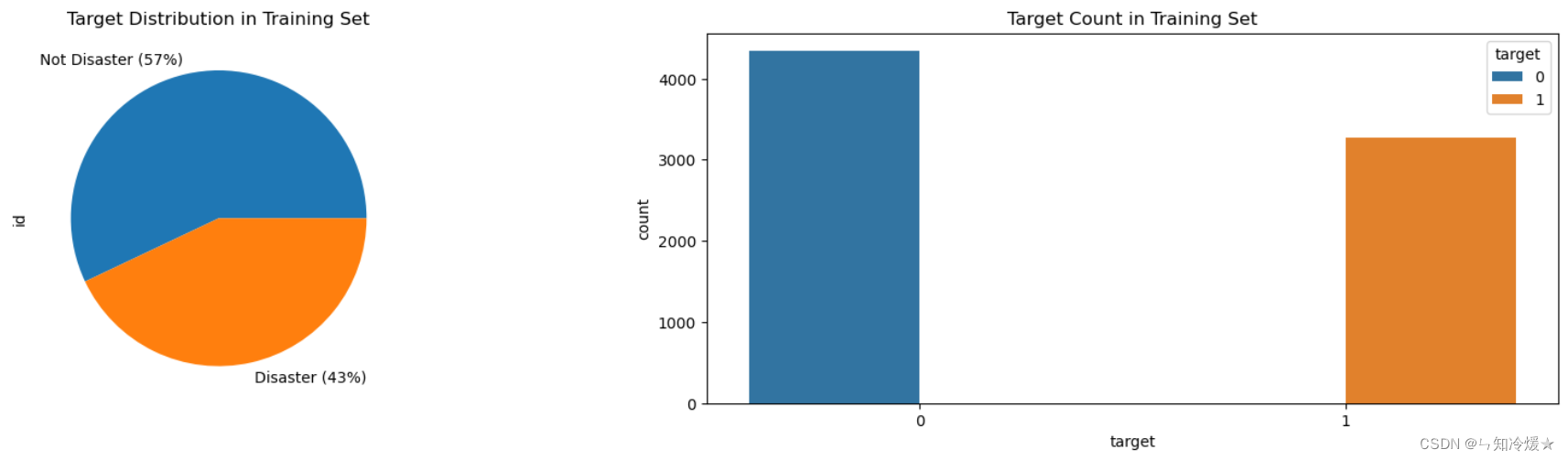
target: 画出图表观测一下分布情况。
fig, axes = plt.subplots(ncols=2, figsize=(17, 4), dpi=100)
plt.tight_layout()df_train.groupby('target').count()['id'].plot(kind='pie', ax=axes[0], labels=['Not Disaster (57%)', 'Disaster (43%)'])
sns.countplot(x=df_train['target'], hue=df_train['target'], ax=axes[1])axes[0].set_title('Target Distribution in Training Set')
axes[1].set_title('Target Count in Training Set')plt.show()
输出:根据图表可知,0、1标签的数量大致持平,没有相差太大。
2-5、文本清理
文本清理: 把一些奇奇怪怪的符号都去掉,适用于tweet评论。
2-6、错误标签样本处理
错误标签样本处理: 某些样本的标签是错误的,剔除掉。
df_mislabeled = df_train.groupby(['text_cleaned']).nunique().sort_values(by='target', ascending=False)
df_mislabeled = df_mislabeled[df_mislabeled['target'] > 1]['target']
df_mislabeled.index.tolist()
输出:各位爷,来瞅瞅标错的文本都是什么德行,让我们的标注人员迷失了自己。
把标记错误的老六都剔除掉。
df_train = df_train[~df_train['text_cleaned'].isin(df_mislabeled.index.tolist())]
三、训练模型
3-1、加载所需包
import random
import torch
from torch.utils.data import TensorDataset, DataLoader, random_split
from transformers import BertTokenizer
from transformers import BertForSequenceClassification, AdamW
from transformers import get_linear_schedule_with_warmup# 加载huggingface的transformers,编辑词向量。
# 设定随机种子,使得每次得到的结果一致。
seed = 42
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = Truedevice = torch.device('cuda')
3-2、数据的进一步处理
数据的进一步处理: 添加字段,加载预训练分词模型。
# 添加一个字段,final_text,由keyword和text_cleaned组成
df_train['final_text'] = df_train['keyword'] + ' ' + df_train['text_cleaned']
df_test['final_text'] = df_test['keyword'] + ' ' + df_test['text_cleaned']# Get text values and labels
text_values = df_train['final_text'].values
labels = df_train['target'].values# Load the pretrained Tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True)# 查看编码后的text以及转换为ID的text
text = '[CLS]'
print('Original Text : ', text)
print('Tokenized Text: ', tokenizer.tokenize(text))
print('Token IDs : ', tokenizer.convert_tokens_to_ids(tokenizer.tokenize(text)))
print('\n')text = '[SEP]'
print('Original Text : ', text)
print('Tokenized Text: ', tokenizer.tokenize(text))
print('Token IDs : ', tokenizer.convert_tokens_to_ids(tokenizer.tokenize(text)))
print('\n')text = '[PAD]'
print('Original Text : ', text)
print('Tokenized Text: ', tokenizer.tokenize(text))
print('Token IDs : ', tokenizer.convert_tokens_to_ids(tokenizer.tokenize(text)))# tokenizer的编码(encode)是两个操作步骤的合体
print(f'Adding Special Tokens Using Encode Func: {tokenizer.encode(text_values[1])}')
输出:

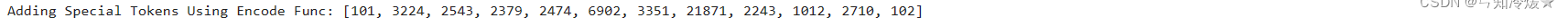
3-3、添加特征并绘图
添加final_text这一列的长度特征并绘图
# Add a length column which contains the length of the tweet
# 添加final_text这一列的长度。
df_train['length'] = df_train['final_text'].apply(len)
df_test['length'] = df_test['final_text'].apply(len)# Plot
sns.set_style('whitegrid', {'axes.grid' : False})
fig, ax = plt.subplots(1, 2)
fig.set_size_inches(18, 6)sns.distplot(df_train['length'], color='#20A387',ax=ax[0])
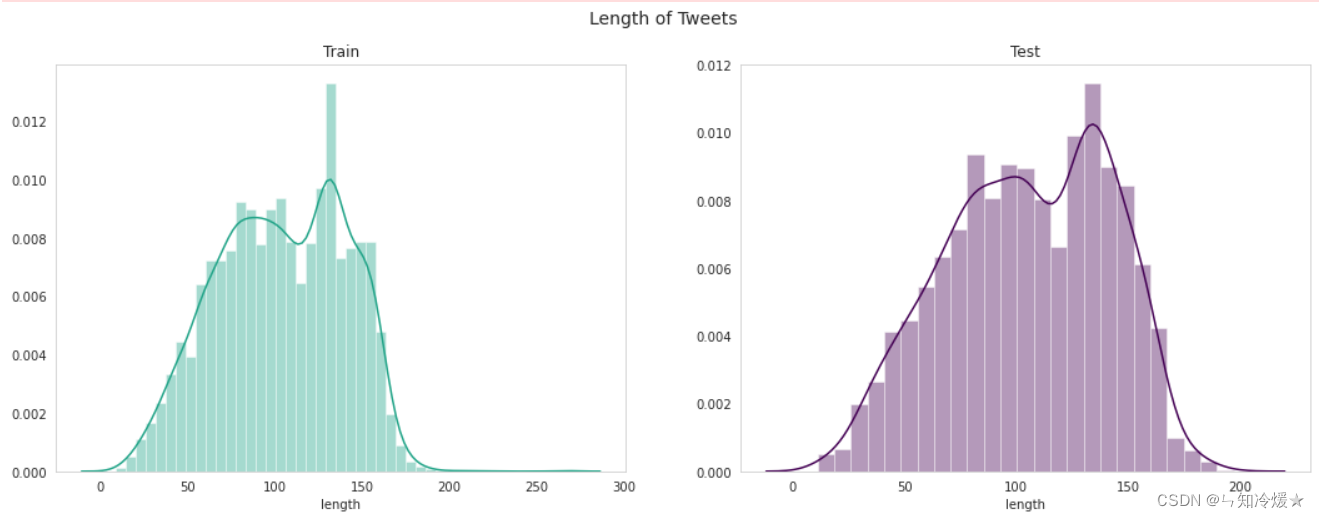
sns.distplot(df_test['length'], color='#440154',ax=ax[1])fig.suptitle("Length of Tweets", fontsize=14)
ax[0].set_title('Train')
ax[1].set_title('Test')plt.show()
添加final_text这一列的单词数量并绘图
# Add column for number of words
df_train['num_of_words'] = df_train['final_text'].apply(lambda x:len(str(x).split()))
df_test['num_of_words'] = df_test['final_text'].apply(lambda x:len(str(x).split())) # Plot
sns.set_style('whitegrid', {'axes.grid' : False})
fig, ax = plt.subplots(1, 2)
fig.set_size_inches(18, 6)sns.distplot(df_train['num_of_words'], color='#20A387',ax=ax[0])
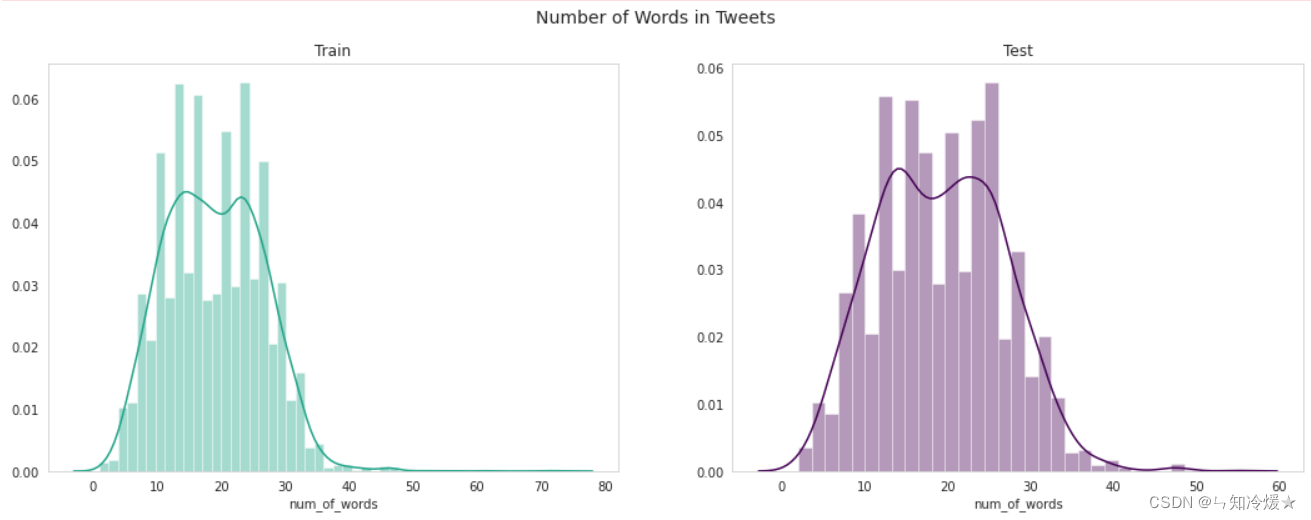
sns.distplot(df_test['num_of_words'], color='#440154',ax=ax[1])fig.suptitle("Number of Words in Tweets", fontsize=14)
ax[0].set_title('Train')
ax[1].set_title('Test')plt.show()
3-4、训练模型
处理final_text,返回编码后的ID串。
def encode_fn(text_list):all_input_ids = []for text in text_values:input_ids = tokenizer.encode(text, add_special_tokens=True, max_length=180, pad_to_max_length=True, return_tensors='pt')all_input_ids.append(input_ids)all_input_ids = torch.cat(all_input_ids, dim=0)return all_input_ids
划分数据为训练集和验证集
epochs = 4
batch_size = 32# Split data into train and validation
# 将数据转化为输入模型需要的数据类型
all_input_ids = encode_fn(text_values)
labels = torch.tensor(labels)# TensorDataset是pytorch中的一个类,用于将多个张量打包成一个数据集,将输入数据张量和标签张量进行一一对应组合。
# 划分训练集和验证集
dataset = TensorDataset(all_input_ids, labels)
train_size = int(0.90 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])# Create train and validation dataloaders
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
加载bert模型
# Load the pretrained BERT model
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2, output_attentions=False, output_hidden_states=False)
model.cuda()# create optimizer and learning rate schedule
optimizer = AdamW(model.parameters(), lr=2e-5)
# len(train_dataloader),数据被分为N个批次,每个批次的数据长度是32
# total_steps
total_steps = len(train_dataloader) * epochs
# get_linear_schedule_with_warmup: 创建学习率调度器函数,
# get_linear_schedule_with_warmup函数在训练初期使用一种称为"warm-up"的策略,即在初始几个epoch中逐步增加学习率,以帮助模型更快地收敛到一个相对合适的参数范围。然后,在warm-up之后,学习率线性地减少或保持恒定。
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=total_steps)
准确率计算

from sklearn.metrics import f1_score, accuracy_scoredef flat_accuracy(preds, labels):"""A function for calculating accuracy scores"""pred_flat = np.argmax(preds, axis=1).flatten()# 将真实标签数组labels进行展平,得到一维的真实标签数组。labels_flat = labels.flatten()# 计算展平后的真实标签数组与预测结果数组之间的准确率return accuracy_score(labels_flat, pred_flat)
训练和验证
for epoch in range(epochs):# 将模型设置为训练模式model.train()total_loss, total_val_loss = 0, 0total_eval_accuracy = 0# step:步数# batch : 每一个批次的数据for step, batch in enumerate(train_dataloader):model.zero_grad() loss, logits = model(batch[0].to(device), token_type_ids=None, attention_mask=(batch[0]>0).to(device), labels=batch[1].to(device))total_loss += loss.item()loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)optimizer.step() scheduler.step()# model.eval()是PyTorch中用于将模型设置为评估模式(evaluation mode)的方法。在深度学习中,模型通常有两种模式:训练模式(training mode)和评估模式(evaluation mode)。model.eval()for i, batch in enumerate(val_dataloader):with torch.no_grad():loss, logits = model(batch[0].to(device), token_type_ids=None, attention_mask=(batch[0]>0).to(device), labels=batch[1].to(device))total_val_loss += loss.item()logits = logits.detach().cpu().numpy()label_ids = batch[1].to('cpu').numpy()total_eval_accuracy += flat_accuracy(logits, label_ids)avg_train_loss = total_loss / len(train_dataloader)avg_val_loss = total_val_loss / len(val_dataloader)avg_val_accuracy = total_eval_accuracy / len(val_dataloader)print(f'Train loss : {avg_train_loss}')print(f'Validation loss: {avg_val_loss}')print(f'Accuracy: {avg_val_accuracy:.2f}')print('\n')
Train loss : 0.441781023875452
Validation loss: 0.34831519580135745
Accuracy: 0.86
Train loss : 0.3275374324204257
Validation loss: 0.3286557973672946
Accuracy: 0.88
Train loss : 0.2503694619696874
Validation loss: 0.355623895690466
Accuracy: 0.86
Train loss : 0.19663514375973207
Validation loss: 0.3806843503067891
Accuracy: 0.86
预测
# Create the test data loader
text_values = df_test['final_text'].values
# 将数据转化为输入模型需要的数据类型
all_input_ids = encode_fn(text_values)
pred_data = TensorDataset(all_input_ids)
#
pred_dataloader = DataLoader(pred_data, batch_size=batch_size, shuffle=False)
# 设置模型为评估模式。
model.eval()
preds = []
for i, (batch,) in enumerate(pred_dataloader):with torch.no_grad():outputs = model(batch.to(device), token_type_ids=None, attention_mask=(batch>0).to(device))logits = outputs[0]logits = logits.detach().cpu().numpy()preds.append(logits)final_preds = np.concatenate(preds, axis=0)
final_preds = np.argmax(final_preds, axis=1)# Create submission file
submission = pd.DataFrame()
submission['id'] = df_test['id']
submission['target'] = final_preds
submission.to_csv('submission.csv', index=False)
参考:
NLP with Disaster Tweets EDA
总结
🎵~ 出卖我的爱,你背了良心债,最后知道真相的我眼泪掉下来。
这篇关于Kaggle竞赛 Real or Not? NLP with Disaster Tweets 文本分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





