本文主要是介绍Arxiv 2106 | Vision Transformers with Hierarchical Attention,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Arxiv 2106 | Vision Transformers with Hierarchical Attention

- 论文:https://arxiv.org/abs/2106.03180
- 代码:https://github.com/yun-liu/HAT-Net
- 本文地址:https://www.yuque.com/lart/papers/cbsx8x
关注的问题
本文重新设计了视觉Transformer中的多头自注意力(MHSA),以实现更高效的全局关系建模过程,同时又不牺牲细粒度信息。
具体过程可以简单概述为将原始细粒度的全局交互拆解为细粒度的局部交互和粗粒度的全局交互的多步处理的形式。
现有问题及方案
Transformer在NLP领域中以成为了处理长距离依赖关系的事实标准(the de-facto standard)。Transformer依赖于自注意力机制来建模序列数据的全局关系。
随着视觉Transformer的代表性工作ViT的出现,基于像素patch构建Transformer模型的方式已经成为了视觉Transformer的主流范式,但是由于视觉数据中patch序列长度依然较长,其所依赖的Self-Attention操作在实际应用中仍然面临着较高的计算量和空间复杂度的问题。
最近的一些工作主要在尝试通过各种手段来压缩序列长度从而提升视觉Transformer的计算效率。
- Local Attention:Swin Transformer中使用固定大小的窗口,并搭配Shift Window并多层堆叠从而模拟全局建模。这种手段仍然次优,因为其仍然延续着CNN的堆叠模拟长距离依赖的思路。
- Pooling Attention:PVT对特征图下采样,从而缩小了序列长度。但是因为下采样了key和value,也因此丢失了局部细节。而且使用了固定尺寸的下采样比例,这使用的是具有与卷积核大小相同的步长的跨步卷积实现的。如果需要调整配置,就得需要重新训练。
- Channel Attention:CoaT计算了通道形式的注意力,这可能没有模拟全局特征依赖那么有效。
本文方法
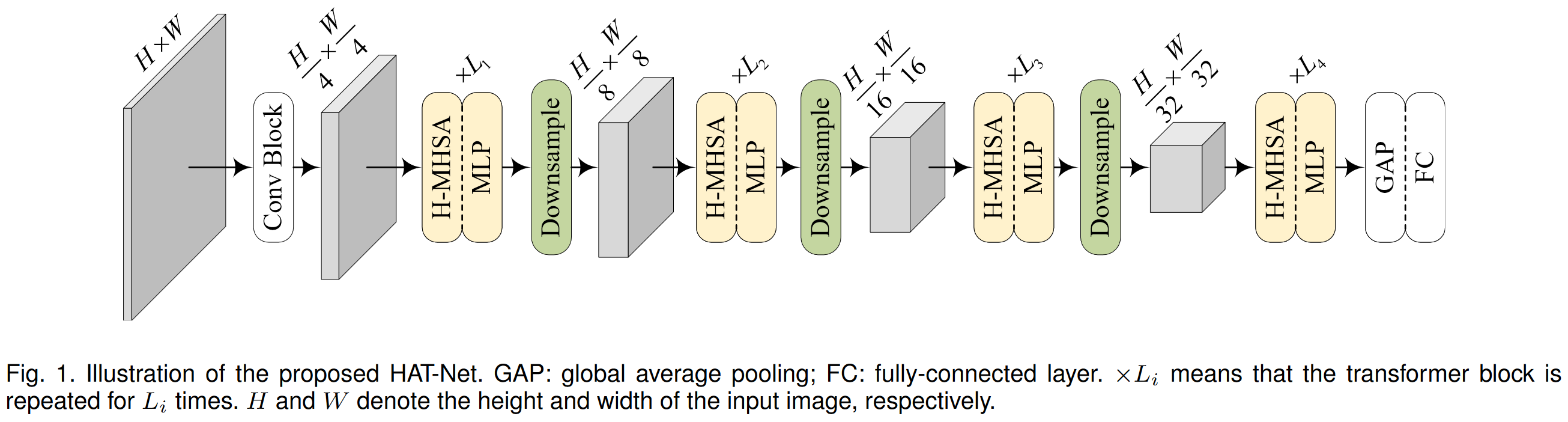
提出模块
针对MHSA提出了一种更加有效和灵活的变体——分层多头自注意力(Hierarchical Multi-Head Self-Attention,H-MHSA)。其通过将直接计算全局相似关系的MHSA拆解成了多个步骤,每步中具有不同粒度的短序列之间的相似性建模,从而既保留了细粒度信息,又保留了短序列计算的高效。
而且H-MHSA涉及到缩短序列的操作都是无参数的,所以对于下游任务更加灵活,不需要因为调整而重新预训练。
具体而言,H-MHSA中包含一下几个步骤:
- 对于输入的query、key以及value对应的patch token,首先将它们进行分组,分成不重叠的数个grid。
B, C, H, W = x.shape
qkv = self.qkv(self.norm(x))grid_h, grid_w = H // self.grid_size, W // self.grid_size
qkv = qkv.reshape(B, 3, self.num_heads, self.head_dim, grid_h,self.grid_size, grid_w, self.grid_size)
qkv = qkv.permute(1, 0, 2, 4, 6, 5, 7, 3)
qkv = qkv.reshape(3, -1, self.grid_size * self.grid_size, self.head_dim)
q, k, v = qkv[0], qkv[1], qkv[2]
- 在grid内的patch之间计算attention,从而捕获局部关系,产生更具判别性的局部表征。这里是基于残差形式。
attn = (q * self.scale) @ k.transpose(-2, -1)
attn = attn.softmax(dim=-1)
grid_x = (attn @ v).reshape(B, self.num_heads, grid_h, grid_w,self.grid_size, self.grid_size, self.head_dim)
grid_x = grid_x.permute(0, 1, 6, 2, 4, 3, 5).reshape(B, C, H, W)
grid_x = self.grid_norm(x + grid_x)
- 将这些小patch合并,获得更大层级的patch token。这允许我们直接基于这些数量较少的粗粒度的token来模拟全局依赖关系。这里计算时,对k、v使用平均池化进行进行压缩处理。
q = self.q(grid_x).reshape(B, self.num_heads, self.head_dim, -1)
q = q.transpose(-2, -1)
kv = self.kv(self.ds_norm(self.avg_pool(grid_x)))
kv = kv.reshape(B, 2, self.num_heads, self.head_dim, -1)
kv = kv.permute(1, 0, 2, 4, 3)
k, v = kv[0], kv[1]
- 最后来自局部和全局层级的特征被集成,从而获得具有更加丰富粒度的特征。
attn = (q * self.scale) @ k.transpose(-2, -1)
attn = attn.softmax(dim=-1)
global_x = (attn @ v).transpose(-2, -1).reshape(B, C, H, W)
if self.grid_size > 1:global_x = global_x + grid_x
基于提出的H-MHSA,文章构建了Hierarchical-Attention-based Transformer Networks (HAT-Net)的多个变体。在多个基础视觉任务上获得了良好的效果。
整体代码如下:
# https://github.com/yun-liu/HAT-Net/blob/3240bc014d51cb3f4215e6c086dfb02496b48215/HAT-Net.py#L42-L101
class Attention(nn.Module):def __init__(self, dim, head_dim, grid_size=1, ds_ratio=1, drop=0.):super().__init__()assert dim % head_dim == 0self.num_heads = dim // head_dimself.head_dim = head_dimself.scale = self.head_dim ** -0.5self.grid_size = grid_sizeself.norm = nn.GroupNorm(1, dim, eps=1e-6)self.qkv = nn.Conv2d(dim, dim * 3, 1)self.proj = nn.Conv2d(dim, dim, 1)self.proj_norm = nn.GroupNorm(1, dim, eps=1e-6)self.drop = nn.Dropout2d(drop, inplace=True)if grid_size > 1:self.grid_norm = nn.GroupNorm(1, dim, eps=1e-6)self.avg_pool = nn.AvgPool2d(ds_ratio, stride=ds_ratio)self.ds_norm = nn.GroupNorm(1, dim, eps=1e-6)self.q = nn.Conv2d(dim, dim, 1)self.kv = nn.Conv2d(dim, dim * 2, 1)def forward(self, x):B, C, H, W = x.shapeqkv = self.qkv(self.norm(x))if self.grid_size > 1:grid_h, grid_w = H // self.grid_size, W // self.grid_sizeqkv = qkv.reshape(B, 3, self.num_heads, self.head_dim, grid_h,self.grid_size, grid_w, self.grid_size)qkv = qkv.permute(1, 0, 2, 4, 6, 5, 7, 3)qkv = qkv.reshape(3, -1, self.grid_size * self.grid_size, self.head_dim)q, k, v = qkv[0], qkv[1], qkv[2]attn = (q * self.scale) @ k.transpose(-2, -1)attn = attn.softmax(dim=-1)grid_x = (attn @ v).reshape(B, self.num_heads, grid_h, grid_w,self.grid_size, self.grid_size, self.head_dim)grid_x = grid_x.permute(0, 1, 6, 2, 4, 3, 5).reshape(B, C, H, W)grid_x = self.grid_norm(x + grid_x)q = self.q(grid_x).reshape(B, self.num_heads, self.head_dim, -1)q = q.transpose(-2, -1)kv = self.kv(self.ds_norm(self.avg_pool(grid_x)))kv = kv.reshape(B, 2, self.num_heads, self.head_dim, -1)kv = kv.permute(1, 0, 2, 4, 3)k, v = kv[0], kv[1]else:qkv = qkv.reshape(B, 3, self.num_heads, self.head_dim, -1)qkv = qkv.permute(1, 0, 2, 4, 3)q, k, v = qkv[0], qkv[1], qkv[2]attn = (q * self.scale) @ k.transpose(-2, -1)attn = attn.softmax(dim=-1)global_x = (attn @ v).transpose(-2, -1).reshape(B, C, H, W)if self.grid_size > 1:global_x = global_x + grid_xx = self.drop(self.proj(global_x))return x
构建模型

- 使用全局平均池化和全连接层作为分类结构。
- 使用SiLU替换常用的GELU,因为后者训练期间更占内存。
- 在MLP中使用深度分离卷积。
- 模型开始使用两个步长为2的3x3卷积实现4倍下采样。
- 后续分别堆叠多个H-MHSA和MLP的集成单元构成四个不同尺度的阶段。
- 每个阶段为了下采样特征,在结尾会使用步长为2的3x3卷积操作。
- 这里的多头设定中,使用的是固定大小的头,对于Tiny版本中设置为48,其他版本中为64。
实验结果
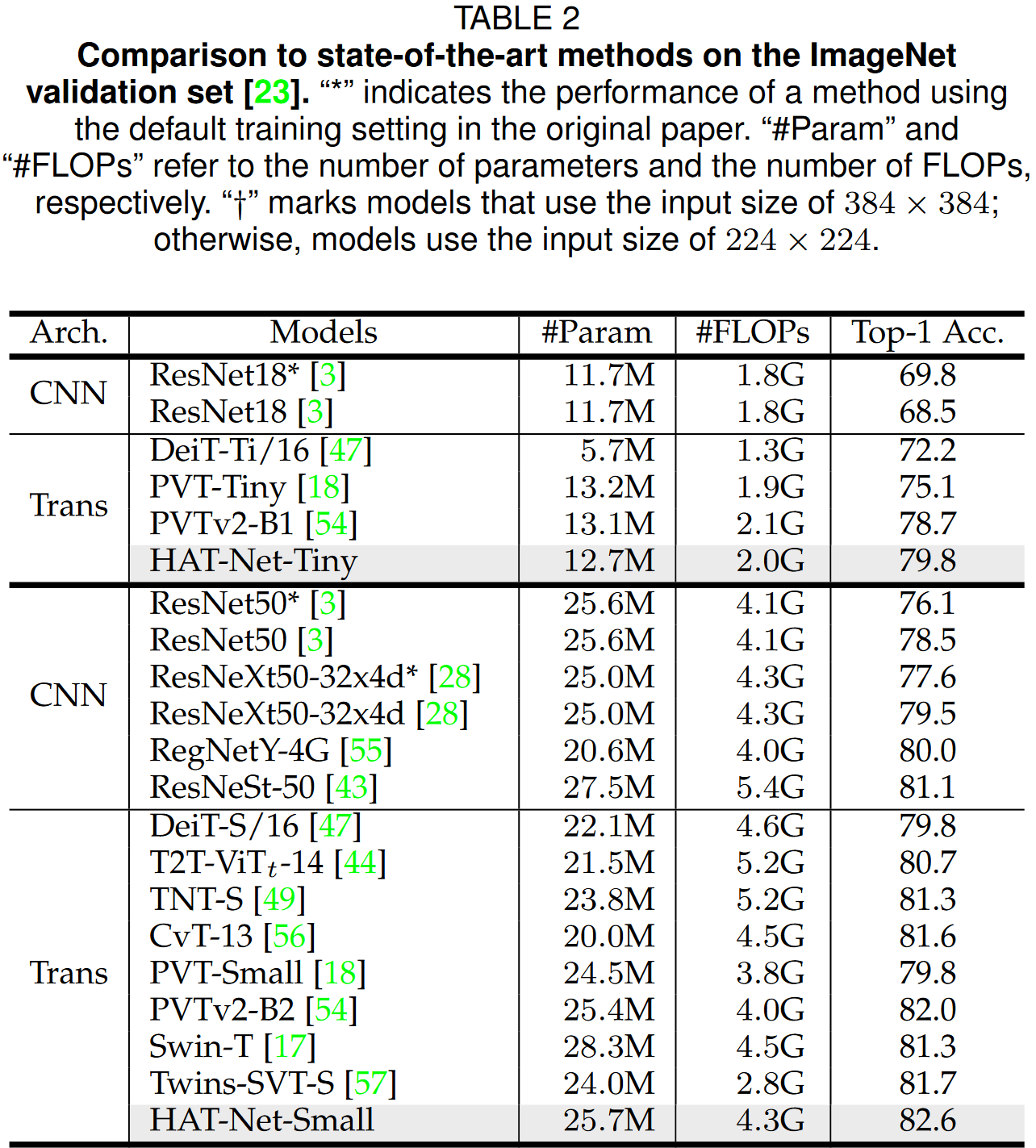
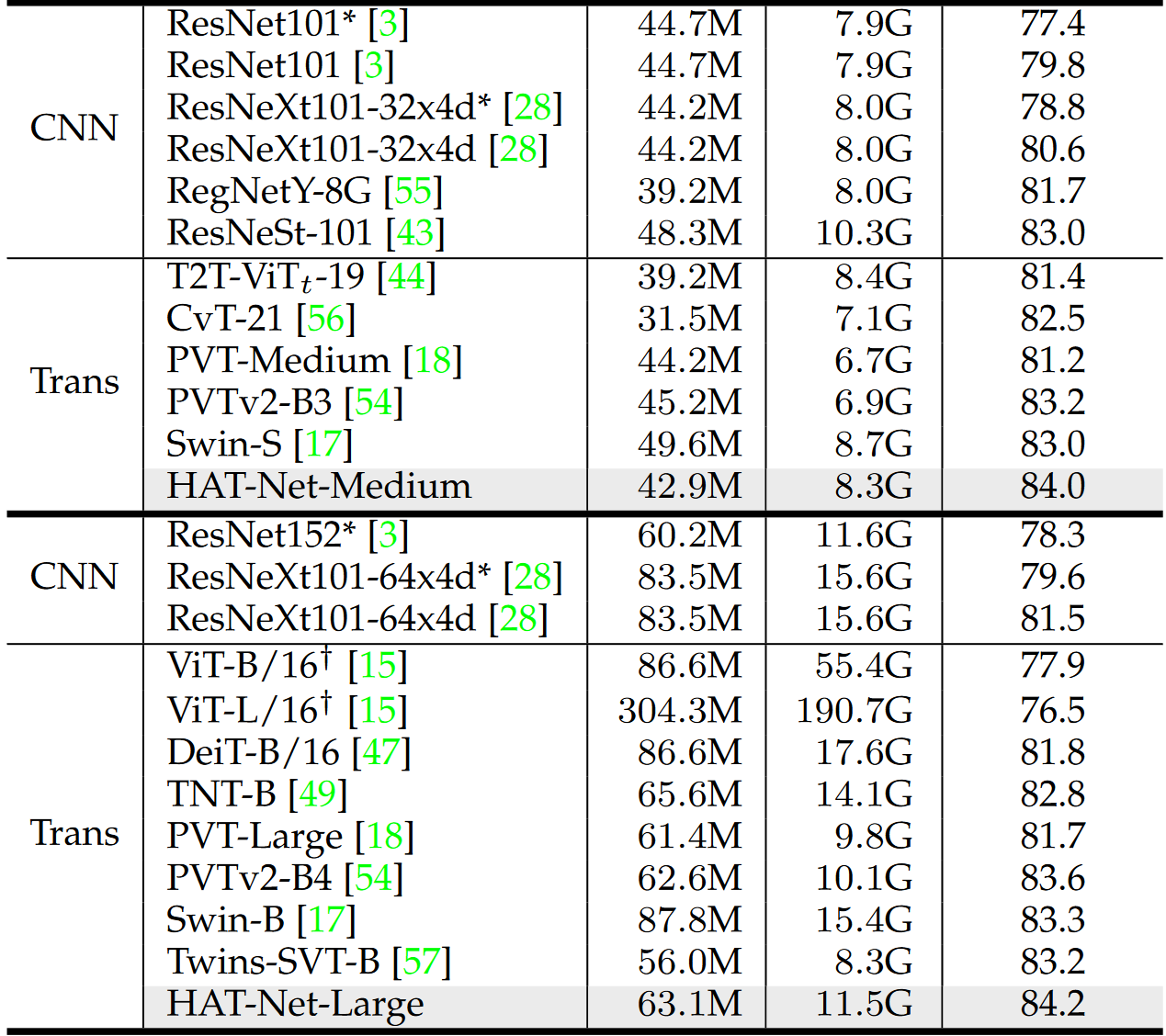
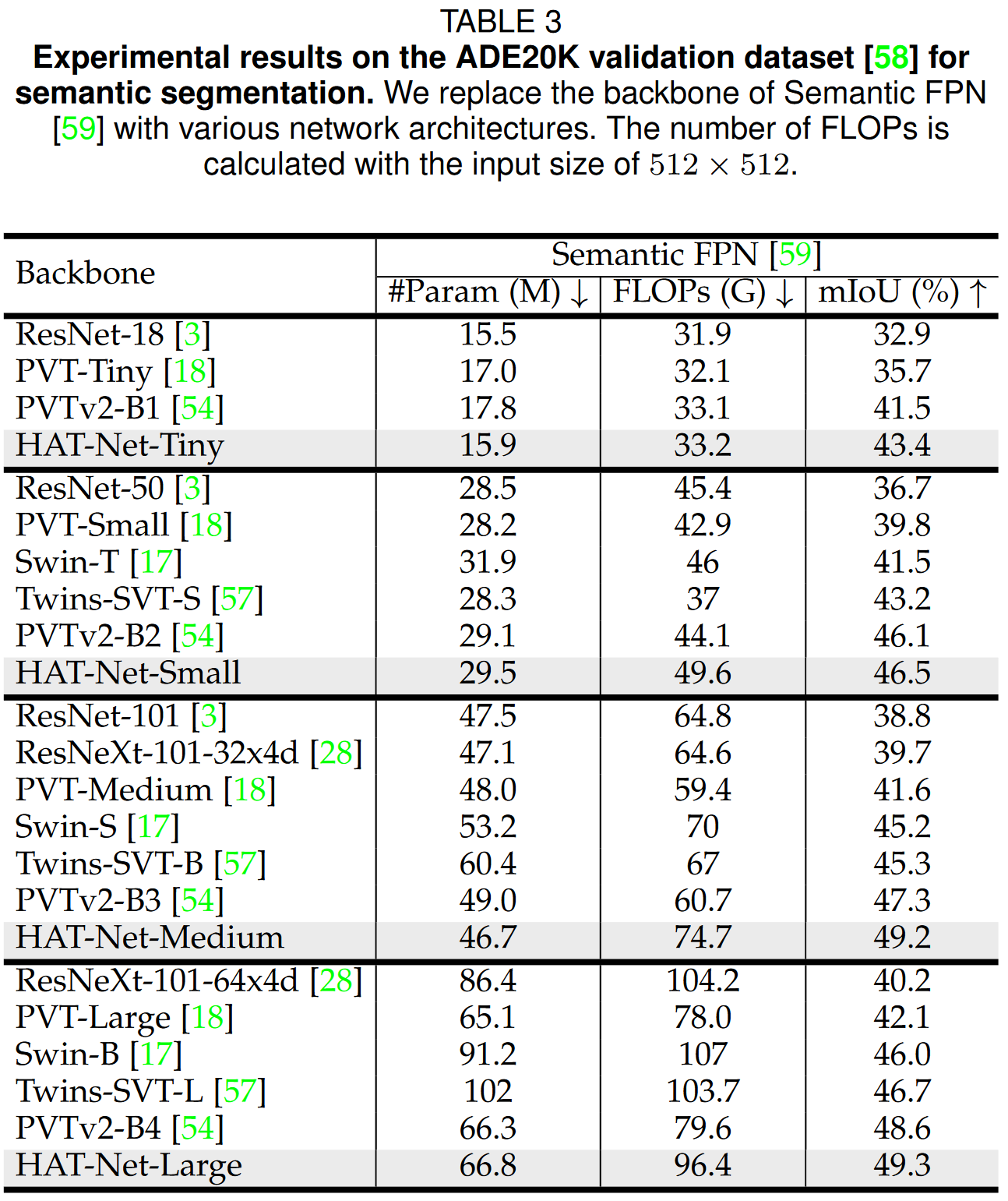
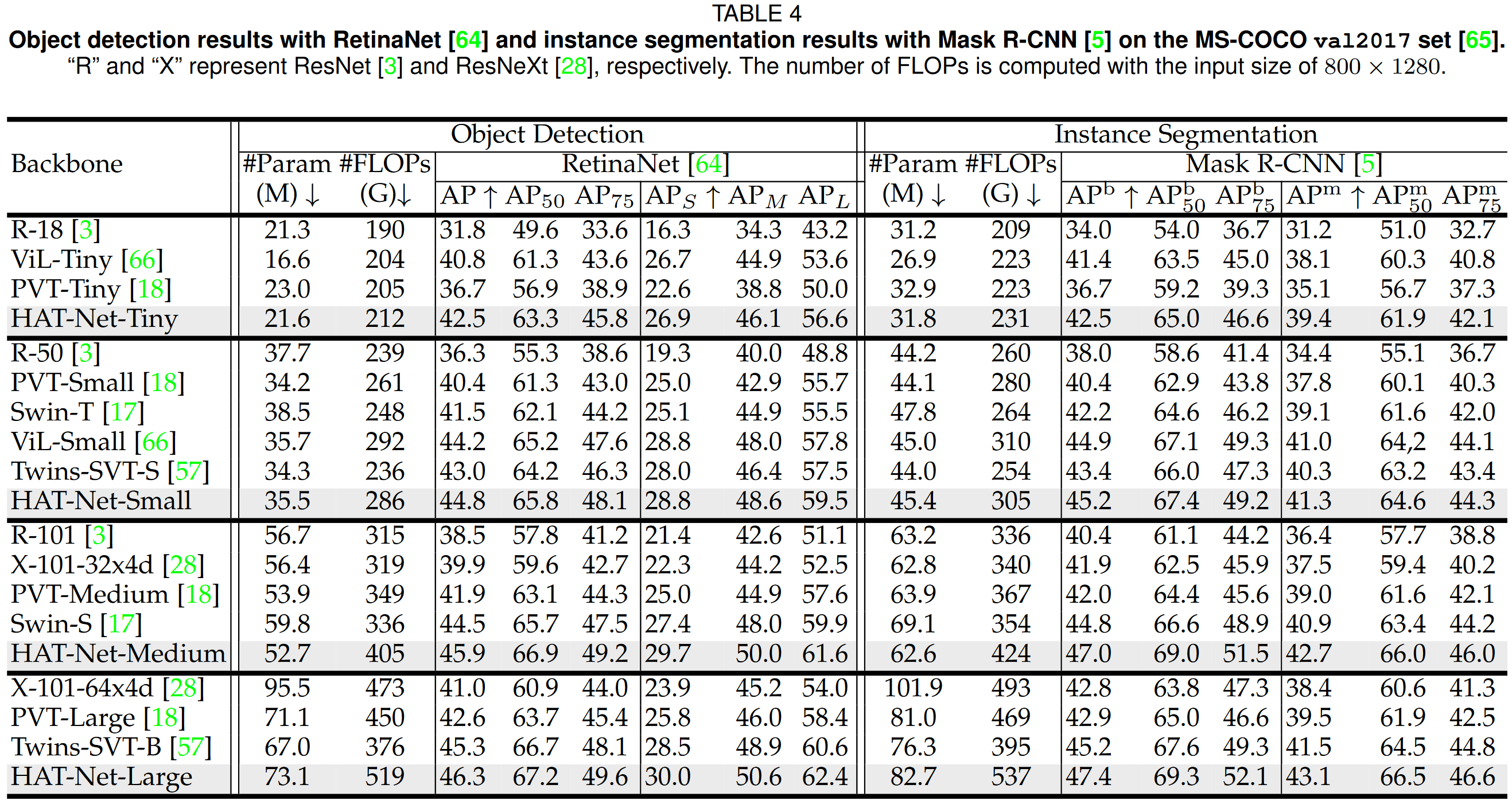
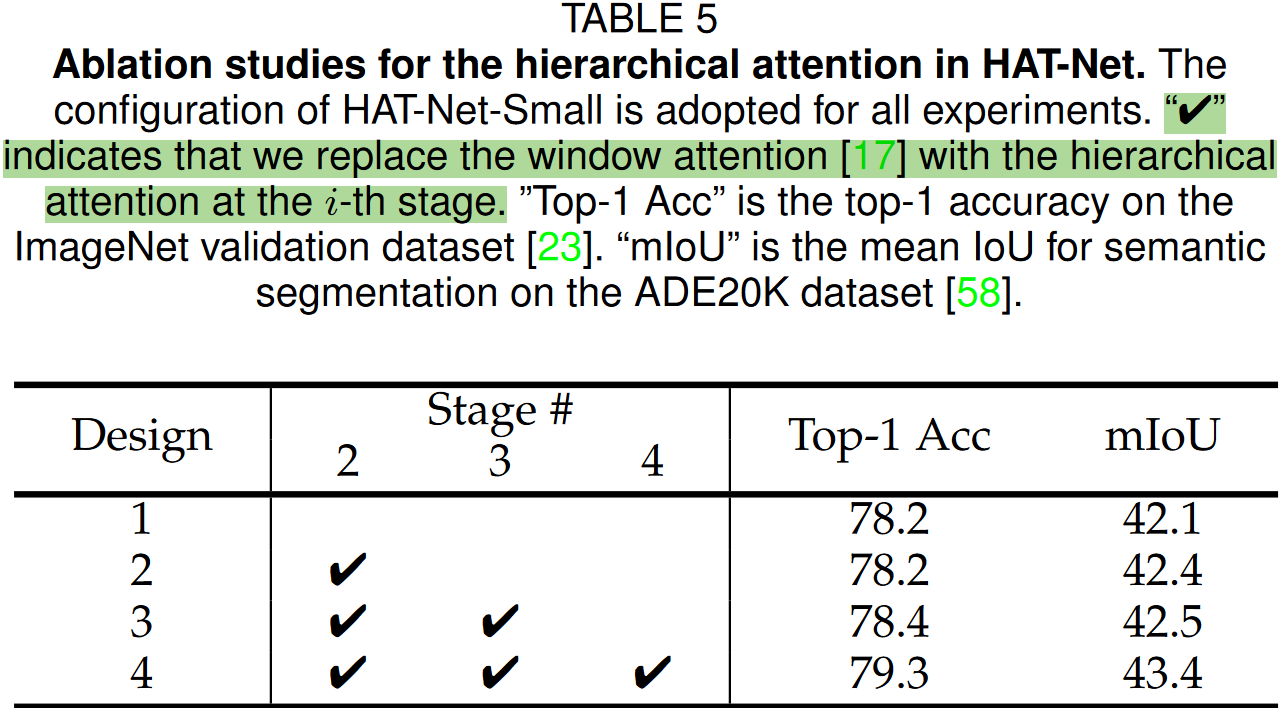
这篇关于Arxiv 2106 | Vision Transformers with Hierarchical Attention的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)




