本文主要是介绍第64步 深度学习图像识别:多分类建模误判病例分析(Pytorch),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于WIN10的64位系统演示
一、写在前面
上期我们基于TensorFlow环境介绍了多分类建模的误判病例分析。
本期以健康组、肺结核组、COVID-19组、细菌性(病毒性)肺炎组为数据集,基于Pytorch环境,构建SqueezeNet多分类模型,分析误判病例,因为它建模速度快。
同样,基于GPT-4辅助编程。
二、误判病例分析实战
使用胸片的数据集:肺结核病人和健康人的胸片的识别。其中,健康人900张,肺结核病人700张,COVID-19病人549张、细菌性(病毒性)肺炎组900张,分别存入单独的文件夹中。
直接分享代码:
######################################导入包###################################
import copy
import torch
import torchvision
import torchvision.transforms as transforms
from torchvision import models
from torch.utils.data import DataLoader
from torch import optim, nn
from torch.optim import lr_scheduler
import os
import matplotlib.pyplot as plt
import warnings
import numpy as npwarnings.filterwarnings("ignore")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 设置GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")################################导入数据集#####################################
from torchvision import datasets, transforms
from torch.nn.functional import softmax
from PIL import Image
import pandas as pd
import torch.nn as nn
import timm
from torch.optim import lr_scheduler# 自定义的数据集类
class ImageFolderWithPaths(datasets.ImageFolder):def __getitem__(self, index):original_tuple = super(ImageFolderWithPaths, self).__getitem__(index)path = self.imgs[index][0]tuple_with_path = (original_tuple + (path,))return tuple_with_path# 数据集路径
data_dir = "./MTB-1"# 图像的大小
img_height = 256
img_width = 256# 数据预处理
data_transforms = {'train': transforms.Compose([transforms.RandomResizedCrop(img_height),transforms.RandomHorizontalFlip(),transforms.RandomVerticalFlip(),transforms.RandomRotation(0.2),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),'val': transforms.Compose([transforms.Resize((img_height, img_width)),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
}# 加载数据集
full_dataset = ImageFolderWithPaths(data_dir, transform=data_transforms['train'])# 获取数据集的大小
full_size = len(full_dataset)
train_size = int(0.8 * full_size) # 假设训练集占70%
val_size = full_size - train_size # 验证集的大小# 随机分割数据集
torch.manual_seed(0) # 设置随机种子以确保结果可重复
train_dataset, val_dataset = torch.utils.data.random_split(full_dataset, [train_size, val_size])# 应用数据增强到训练集和验证集
train_dataset.dataset.transform = data_transforms['train']
val_dataset.dataset.transform = data_transforms['val']# 创建数据加载器
batch_size = 8
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=True, num_workers=0)dataloaders = {'train': train_dataloader, 'val': val_dataloader}
dataset_sizes = {'train': len(train_dataset), 'val': len(val_dataset)}
class_names = full_dataset.classes# 获取数据集的类别
class_names = full_dataset.classes# 保存预测结果的列表
results = []###############################定义SqueezeNet模型################################
# 定义SqueezeNet模型
model = models.squeezenet1_1(pretrained=True) # 这里以SqueezeNet 1.1版本为例
num_ftrs = model.classifier[1].in_channels# 根据分类任务修改最后一层
# 这里我们改变模型的输出层为4,因为我们做的是四分类
model.classifier[1] = nn.Conv2d(num_ftrs, 4, kernel_size=(1,1))# 修改模型最后的输出层为我们需要的类别数
model.num_classes = 4model = model.to(device)# 打印模型摘要
print(model)#############################编译模型#########################################
# 定义损失函数
criterion = nn.CrossEntropyLoss()# 定义优化器
optimizer = torch.optim.Adam(model.parameters())# 定义学习率调度器
exp_lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)# 开始训练模型
num_epochs = 20# 初始化记录器
train_loss_history = []
train_acc_history = []
val_loss_history = []
val_acc_history = []for epoch in range(num_epochs):print('Epoch {}/{}'.format(epoch, num_epochs - 1))print('-' * 10)# 每个epoch都有一个训练和验证阶段for phase in ['train', 'val']:if phase == 'train':model.train() # 设置模型为训练模式else:model.eval() # 设置模型为评估模式running_loss = 0.0running_corrects = 0# 遍历数据for inputs, labels, paths in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# 零参数梯度optimizer.zero_grad()# 前向with torch.set_grad_enabled(phase == 'train'):outputs = model(inputs)_, preds = torch.max(outputs, 1)loss = criterion(outputs, labels)# 只在训练模式下进行反向和优化if phase == 'train':loss.backward()optimizer.step()# 统计running_loss += loss.item() * inputs.size(0)running_corrects += torch.sum(preds == labels.data)epoch_loss = running_loss / dataset_sizes[phase]epoch_acc = (running_corrects.double() / dataset_sizes[phase]).item()# 记录每个epoch的loss和accuracyif phase == 'train':train_loss_history.append(epoch_loss)train_acc_history.append(epoch_acc)else:val_loss_history.append(epoch_loss)val_acc_history.append(epoch_acc)print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))print()# 保存模型
torch.save(model.state_dict(), 'SqueezeNet_model-m-s.pth')# 加载最佳模型权重
#model.load_state_dict(best_model_wts)
#torch.save(model, 'shufflenet_best_model.pth')
#print("The trained model has been saved.")
###########################误判病例分析#################################
import os
import pandas as pd
from collections import defaultdict# 判定组别的字典
group_dict = {("COVID-19", "Normal"): "B",("COVID-19", "Pneumonia"): "C",("COVID-19", "Tuberculosis"): "D",("Normal", "COVID-19"): "E",("Normal", "Pneumonia"): "F",("Normal", "Tuberculosis"): "G",("Pneumonia", "COVID-19"): "H",("Pneumonia", "Normal"): "I",("Pneumonia", "Tuberculosis"): "J",("Tuberculosis", "COVID-19"): "K",("Tuberculosis", "Normal"): "L",("Tuberculosis", "Pneumonia"): "M",
}# 创建一个字典来保存所有的图片信息
image_predictions = {}# 循环遍历所有数据集(训练集和验证集)
for phase in ['train', 'val']:# 设置模型的状态model.eval()# 遍历数据for inputs, labels, paths in dataloaders[phase]:inputs = inputs.to(device)labels = labels.to(device)# 计算模型的输出with torch.no_grad():outputs = model(inputs)_, preds = torch.max(outputs, 1)# 循环遍历每一个批次的结果for path, pred in zip(paths, preds):# 提取图片的类别actual_class = os.path.split(os.path.dirname(path))[-1] # 提取图片的名称image_name = os.path.basename(path)# 获取预测的类别predicted_class = class_names[pred]# 判断预测的分组类型if actual_class == predicted_class:group_type = 'A'elif (actual_class, predicted_class) in group_dict:group_type = group_dict[(actual_class, predicted_class)]else:group_type = 'Other' # 如果没有匹配的条件,可以归类为其他# 保存到字典中image_predictions[image_name] = [phase, actual_class, predicted_class, group_type]# 将字典转换为DataFrame
df = pd.DataFrame.from_dict(image_predictions, orient='index', columns=['Dataset Type', 'Actual Class', 'Predicted Class', 'Group Type'])# 保存到CSV文件中
df.to_csv('result-m-s.csv')四、改写过程
先说策略:首先,先把二分类的误判病例分析代码改成四分类的;其次,用咒语让GPT-4帮我们续写代码已达到误判病例分析。
提供咒语如下:
①改写{代码1},改变成4分类的建模。代码1为:{XXX};
②在{代码1}的基础上改写代码,达到下面要求:
(1)首先,提取出所有图片的“原始图片的名称”、“属于训练集还是验证集”、“预测为分组类型”;文件的路劲格式为:例如,“MTB-1\Normal\XXX.png”属于Normal,“MTB-1\COVID-19\XXX.jpg”属于COVID-19,“MTB-1\Pneumonia\XXX.jpeg”属于Pneumonia,“MTB-1\Tuberculosis\XXX.png”属于Tuberculosis;
(2)其次,根据样本预测结果,把样本分为以下若干组:(a)预测正确的图片,全部判定为A组;(b)本来就是COVID-19的图片,预测为Normal,判定为B组;(c)本来就是COVID-19的图片,预测为Pneumonia,判定为C组;(d)本来就是COVID-19的图片,预测为Tuberculosis,判定为D组;(e)本来就是Normal的图片,预测为COVID-19,判定为E组;(f)本来就是Normal的图片,预测为Pneumonia,判定为F组;(g)本来就是Normal的图片,预测为Tuberculosis,判定为G组;(h)本来就是Pneumonia的图片,预测为COVID-19,判定为H组;(i)本来就是Pneumonia的图片,预测为Normal,判定为I组;(j)本来就是Pneumonia的图片,预测为Tuberculosis,判定为J组;(k)本来就是Tuberculosis的图片,预测为COVID-19,判定为H组;(l)本来就是Tuberculosis的图片,预测为Normal,判定为I组;(m)本来就是Tuberculosis的图片,预测为Pneumonia,判定为J组;
(3)居于以上计算的结果,生成一个名为result-m.csv表格文件。列名分别为:“原始图片的名称”、“属于训练集还是验证集”、“预测为分组类型”、“判定的组别”。其中,“原始图片的名称”为所有图片的图片名称;“属于训练集还是验证集”为这个图片属于训练集还是验证集;“预测为分组类型”为模型预测该样本是哪一个分组;“判定的组别”为根据步骤(2)判定的组别,从A到J一共十组选择一个。
(4)需要把所有的图片都进行上面操作,注意是所有图片,而不只是一个批次的图片。
代码1为:{XXX}
③还需要根据报错做一些调整即可,自行调整。
最后,看看结果:
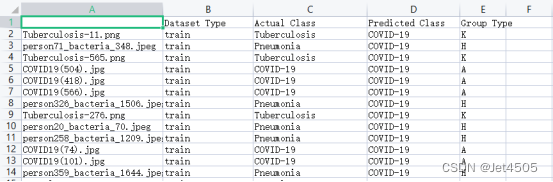
模型只运行了2次,所以效果很差哈,全部是预测成了COVID-19。
四、数据
链接:https://pan.baidu.com/s/1rqu15KAUxjNBaWYfEmPwgQ?pwd=xfyn
提取码:xfyn
五、结语
深度学习图像分类的教程到此结束,洋洋洒洒29篇,涉及到的算法和技巧也够发一篇SCI了。当然,图像识别还有图像分割和目标识别两块内容,就放到最后再说了。下一趴,我们来介绍时间序列建模!!!
这篇关于第64步 深度学习图像识别:多分类建模误判病例分析(Pytorch)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





