本文主要是介绍大规模语言模型人类反馈对齐--RLAIF,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
RLHF 中是需要大量的人力参与的, 如果 RLHF 中的「人类」被取代, 可行吗? 谷歌团队 2023 年 8 月的 最新研究提出了, 用大模型替代人类, 进行偏好标注, 也就是AI 反馈强化学习(RLAIF:Scaling Reinforcement Learning from Human Feedbak with AI Feadback),实验结果发现 RLAIF 可以在不依赖人类标注员的情况下, 产生 与 RLHF 相当的改进效果, 胜率 50%;而且, 证明了 RLAIF 和 RLHF,比起监督微调(SFT) 胜率都超过了 70%。
如今,大型语言模型训练中一个关键部分便是 RLHF。人类通过对 AI 输出的质量进行评级,让回复更加有 用。但是, 这需要付出很多的努力, 包括让许多标注人员暴露在 AI 输出的有害内容中。既然 RLAIF 能够与 RLHF 相媲美,未来模型不需要人类反馈,也可以通过自循环来改进。
我们通过前面章节知道 RLHF 分为三步:预训练一个监督微调 LLM;收集数据训练一个奖励模型;用 RL 微 调模型。有了 RLHF,大模型可以针对复杂的序列级目标进行优化, 而传统的 SFT 很难区分这些目标。然而, 一 个非常现实的问题是, RLHF 需要大规模高质量的人类标注数据,另外这些数据能否可以取得一个优胜的结果。
在谷歌这项研究之前, Anthropic 研究人员是第一个探索使用 AI 偏好来训练 RL 微调的奖励模型。他们首次 在 Constitutional AI(Constitutional AI: Harmlessness from AI Feadback) 中提出了 RLAIF,发现 LLM 与人类判断表 现出高度一致, 甚至在某些任务上, 表现优于人类。但是, 这篇研究没有将人类与人工智能反馈做对比, 因此, RLAIF 是否可以替代 RLHF 尚未得到终极答案。

RLAIF 和 RLHF 对比示意图
谷歌提出的 RLAIF 主要就是探讨是否能替代 RLHF,他们在模型摘要任务中, 直接比较了 RLAIF 和 RLHF, 如上图所示,具体的模型训练方面:
-
首先, 研究人员使用 PaLM 2 Extra-Small (XS) 作为初始模型权重, 在 OpenAI 过滤后的 TL;DR 数据集上训 练 SFT 模型。
-
然后, 给定 1 个文本和 2 个候选答案, 使用现成的 LLM 给出一个偏好标注, 根据 LLM 偏好和对比损失训 练奖励模型(RM)。研究人员从 SFT 模型初始化 RM,并在 OpenAI 的 TL;DR 人类偏好数据集上训练它们。 这个 AI 标注的偏好是研究人员使用PaLM 2L 生成的, 然后在完整的偏好上训练 RM 数据集, 训练reward 模型 rϕ 的损失如下所示, yw 和 yl 分别代表人类偏好的和非偏好的回复。
![]()
-
最后, 通过强化学习微调策略模型, 利用奖励模型给出奖励。研究人员使用 Advantage Actor Critic (A2C) 来训练策略。策略 πθRL 和价值模型都是从 SFT 模型初始化的。研究人员使用过滤后的 Reddit TL;DR 数据 集作为初始状态来推出他们的策略,优化目标函数如下所示。
![]()
在 LLM 的 prompt 的改进方面, 研究者还尝试了使用思维链(CoT) 推理和 self-consistency 等方法促进 LLM 的评估。下图中展示了 AI 标注器中引出思维链 (COT) 推理, 以提高 LLM 与人类偏好的一致性。研究人员替 换标准的结尾提示(例如将”Preferred Summary=” 替换为”Consider the coherence, accuracy, coverage, and over-all quality of each summary and explain which one is better. Rationale :”), 然后解码一个 LLM 的回复。最后, 研究人 员将原始提示、响应和原始结尾字符串“Preferred Summary=”连接在一起,之后再获得偏好分布。
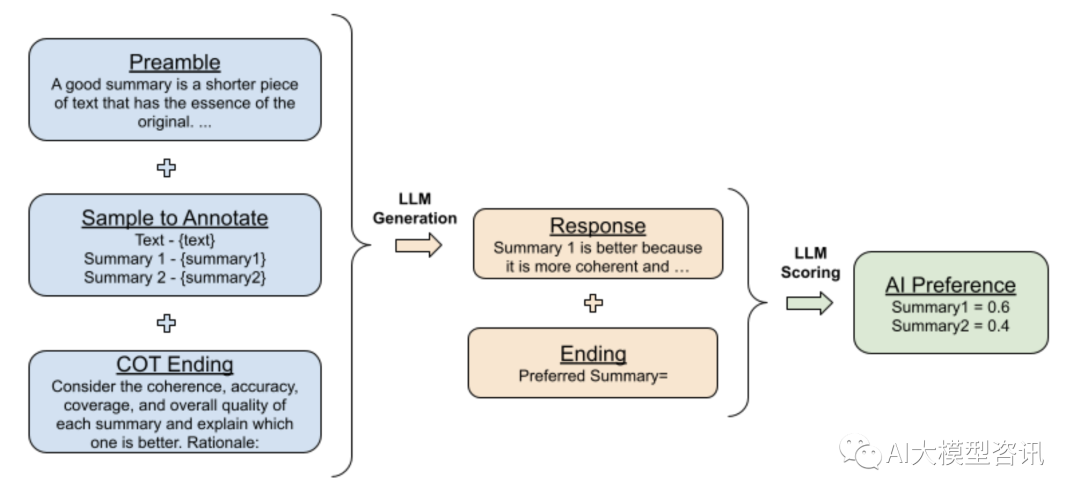
思维链推理方法提高 LLM 与人类偏好的一致性示意图
研究人员证明了 RLAIF 可以在不依赖人类标注者的情况下产生与 RLHF 相当的改进。虽然这项工作凸显了 RLAIF 的潜力,但依然有一些局限性。
-
首先,这项研究仅探讨了摘要总结任务,关于其他任务的泛化性还需要进一步研究。
-
其次,研究人员没有评估 LLM 推理在经济成本上是否比人工标注更有优势。
-
此外, 还有一些有趣的问题值得研究, 例如 RLHF 与 RLAIF 相结合是否可以优于单一的一种方法, 使用 LLM 直接分配奖励的效果如何, 改进 AI 标注器对齐是否会转化为改进的最终策略, 以及是否使用 LLM 与策略模型大小相同的标注器可以进一步改进策略(即模型是否可以“自我改进”)。
ps: 欢迎扫码关注公众号^_^.

这篇关于大规模语言模型人类反馈对齐--RLAIF的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







