rlaif专题
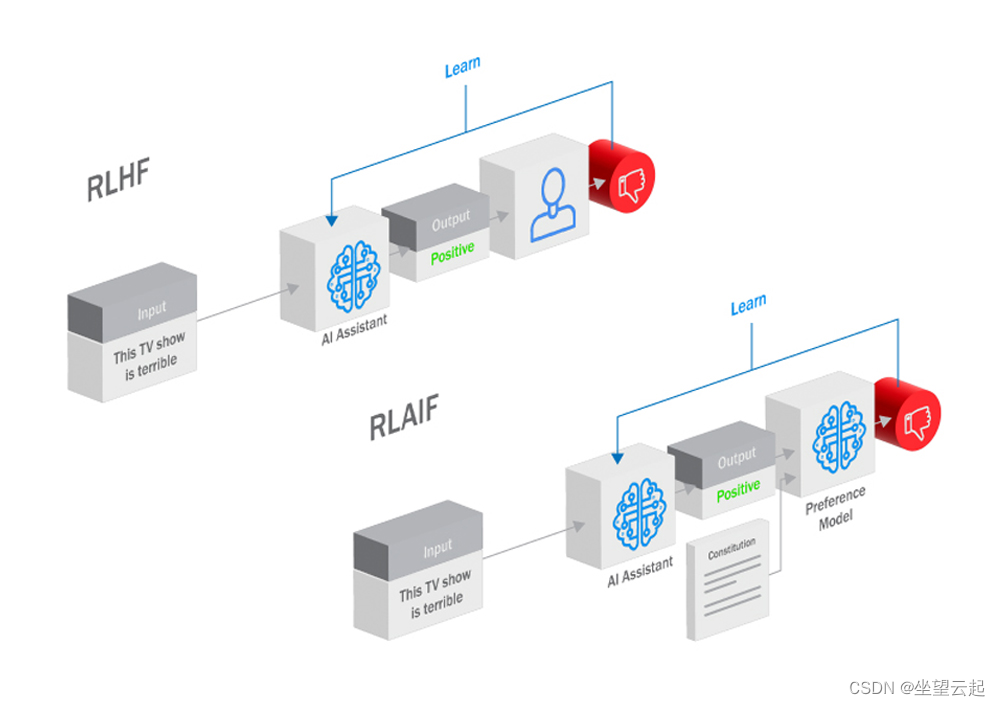
大语言模型微调过程中的 RLHF 和 RLAIF 有什么区别?
目前想要深入挖掘大型语言模型(LLM)的全部潜力需要模型与我们人类的目标和偏好保持一致。从而出现了两种方法:来自人类反馈的人力强化学习(RLHF)和来自人工智能反馈的人工智能驱动的强化学习(RLAIF)。两者都利用强化学习(RL)中的反馈循环来引导大语言模型接近并实现人类意图,但这两种方法的机制和含义却截然不同。 什么是 RLHF? RLHF是一个弥合人工智能模
RLAIF(0)—— DPO(Direct Preference Optimization) 原理与代码解读
之前的系列文章:介绍了 RLHF 里用到 Reward Model、PPO 算法。 但是这种传统的 RLHF 算法存在以下问题:流程复杂,需要多个中间模型对超参数很敏感,导致模型训练的结果不稳定。 斯坦福大学提出了 DPO 算法,尝试解决上面的问题,DPO 算法的思想也被后面 RLAIF(AI反馈强化学习)的算法借鉴,这个系列会从 DPO 开始,介绍 SPIN、self-reward model

RLAIF在提升大型语言模型训练中的应用
RLAIF在提升大型语言模型训练中的应用 大型语言模型(LLMs)在理解和生成自然语言方面展示了巨大能力,但仍面临输出不可靠、推理能力有限、缺乏一致性个性或价值观对齐等挑战。为解决这些问题,研究者开发了一种名为“来自AI反馈的强化学习”(RLAIF)的技术。RLAIF允许AI系统对自身行为和输出提供反馈,通过强化学习过程进行自我优化。这一方法为赋予LLMs有益行为、增加模型安全性和可靠性提供了新

大规模语言模型人类反馈对齐--RLAIF
RLHF 中是需要大量的人力参与的, 如果 RLHF 中的「人类」被取代, 可行吗? 谷歌团队 2023 年 8 月的 最新研究提出了, 用大模型替代人类, 进行偏好标注, 也就是AI 反馈强化学习(RLAIF:Scaling Reinforcement Learning from Human Feedbak with AI Feadback),实验结果发现 RLAIF 可以在不依赖人类标注员的情