本文主要是介绍优化过后的基于采样的路径规划算法(RRT Star),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Original RRT的一些缺陷
- 所得到的的路径并不是最短/最优
- 由线段连接成的路径不光滑,不太适合机器人去执行,如下图所示。

RRT Star
是针对性地去解决RRT当中路径不是最优的情况
伪代码
RRT Star大体上与RRT是一致的

- 采样得到空间中的点X_rand。
- 通过在X_rand周围进行搜索,找到其最近的领域节点X_near,搜索过程中可以用KT-Tree进行加速。
- 通过X_near往X_rand移动一定距离,可以得到一个新的点X_new。
- 此时就与RRT当中有些不同了,在RRT当中,找到X_new之后是与X_near直接相连的,但是在RRT*当中,找到了X_new之后,就会在X_new之间找到一个范围,在这个范围内,画一个以R为半径的圆,继续搜索其他的点, 如下图所示,找到了X_new,X1,X2这三个节点。

伪代码中的NearC就代表了找附近节点的这么个过程,在RRT当中,找到X_new后,其父节点就是X_near,但在这就不同了,这时把三个节点都通过直线连接起来,下一步做一个操作,就是当前的终点是X_new,从X1,X2,X_near都可以到达X_new,现在就看这三个点中的哪个点到这个最初的大红色起点的Cost是最小的。(动态规划思想)。
显然是从X_near到达红色起点路径最短。

这时候X_near就被选为X_new的父节点。
综上,就完成了一次ChooseParent,AddNodEdge的过程。
rewire()
RRT Star更为突出的特色,就是结尾处的这个rewire()函数,帮助其修改连接过程,使得路径更优化。
举个例子:

在图中,X1到起始节点有两条路径可以选择,一条是红色的一条是蓝色的,当选红色的路径时,X1的父节点是X_near;当选蓝色的路径时,X1的父节点是X_new。通过计算两条路的Cost可知,红色的Cost<蓝色的Cost,此时就不进行Rewire操作,继续保持原有的红色路径行进。

在图中,X2到起始节点有两条路径可以选择,一条是红色的一条是蓝色的,当选红色的路径时,X2的父节点是X1;当选蓝色的路径时,X2的父节点是X_new。通过计算两条路的Cost可知,红色的Cost>蓝色的Cost,此时就进行Rewire操作,更改X2的父节点为X_new,走蓝色的路径,如下图所示。

rewire过程不断迭代,从而使得路径不断优化。
RRT Star在找到一条路径的时候并不会停止,而是会继续进行寻找,直到找到最优的路径为止。
这也是为什么RRT Star可以找到最优化路径的原因。
Kinodynamic-RRT*
之前说过了未优化的RRT,由线段连接成的路径不光滑,在运动学上是接受的,但是现实当中不太适合机器人去执行,之前的RRT也没解决这个问题,有的研究者就提出了Kinodynamic-RRT来解决这个问题。
Kinodynamic
之前的步骤与RRT Star都是一样,最主要的是如何连接X_near与X_new,在RRT以及RRT Star当中,直接用直线进行连接;而Kinodynamic是找符合机器人约束的曲线作为路径,下图是两algorithm的效果图。


上图左边,RRT* 类的算法,找到了X_new,下意识的进行直线连接,但是直线穿过了障碍物,只能舍去,但是运用了Kinodynamic-RRT* ,就会有一条平滑的路径,绕过了障碍物。
Kinodynamic-RRT* 演示
Kinodynamic-RRT* 相关资料
Anytime-RRT*
当通过树找到了路径,机器人就会沿着树往前走,当机器人往前走的过程中,这个树还是实时的在构建,实时的在更新,在寻找路径,做了一个实时更新的过程。
Anytime-RRT Star的要义就是,将自己的起始点进行实时更新,最初的起始点就是起始点,每走一步起始点就变成了当前点。
相比于之前的RRT,就是先规划出一条,很死板,固定死了,Anytime-RRT* 能更好的去适应环境变化大的情况。
Anytime-RRT* 相关资料
其他的Sampling-Based Algorithm
Informed RRT*
前面也说了,RRT是在一个Space当中均匀的进行撒点,然后不断优化路径,但是这样工作量很大,而且浪费也高,这下研究者就提出了Informed RRT Star,将采样的范围限定成了椭圆。只需要在有用的区域进行撒点。

以路径的常数来作为椭圆方程中的常数,这就是为什么椭圆越来越扁的原因。
这样采样的范围就会快速收缩,越来越快得到最优的路径。
Informed RRT* 相关资料
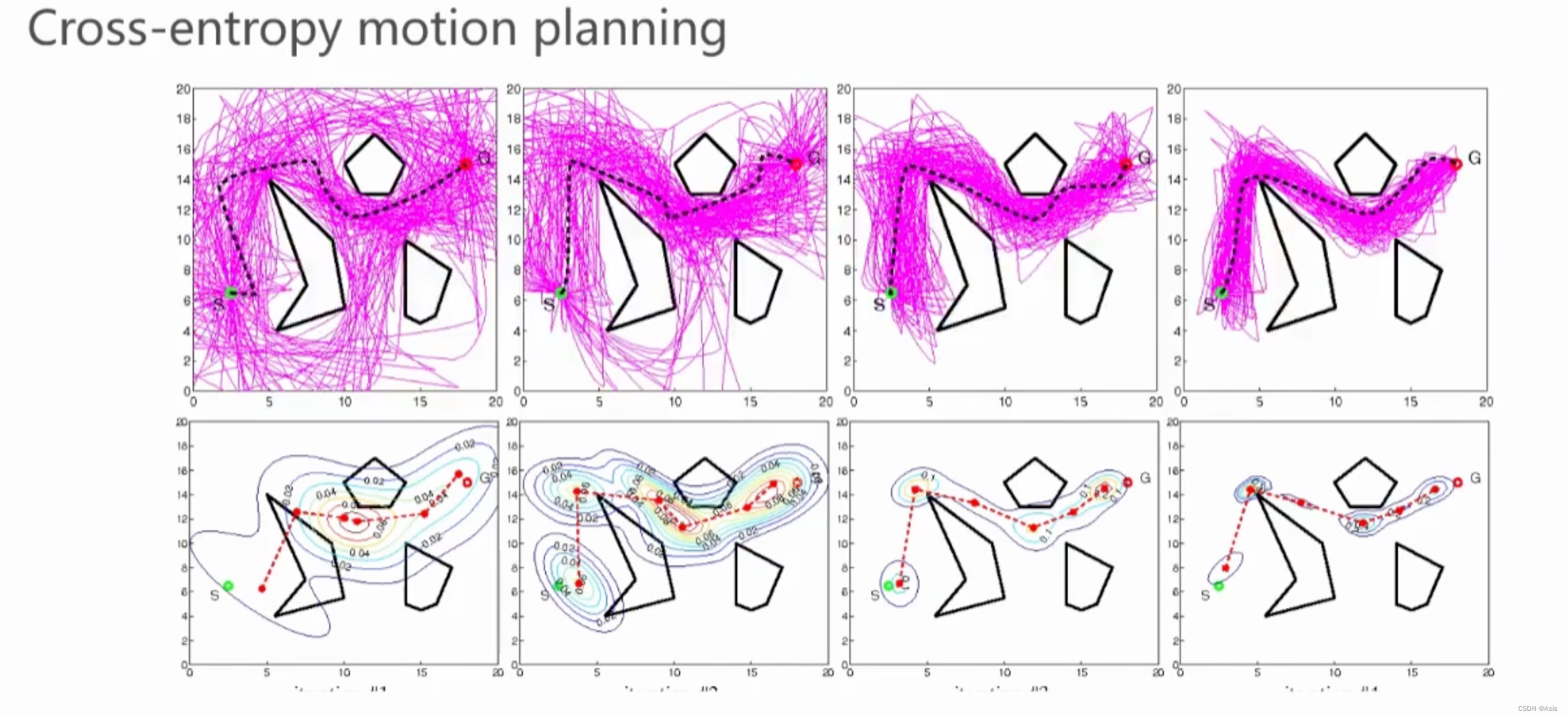
Cross-Entropy motion planning

轨迹生成后,就在各个节点周围进行采样,每个圈都是一个高斯采样,不断进行路径优化,就会得到后面的几条路径。
CEMP流程
Conclusion
除此之外,还有很多Advanced Sampling Based Algorithm,欢迎评论区交流👏🏻。
这篇关于优化过后的基于采样的路径规划算法(RRT Star)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


