本文主要是介绍基于轻量级yolov5模型摔倒行文检测识别系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关于行文检测的项目之前也有一些实践,比如:不文明行文检测识别、课堂行为识别、步态识别等等,今天这里正好有点时间,就像基于更加强大轻量级的模型来开发构建摔倒检测识别模型,之前其实关于摔倒检测已经做过了,但是主要是基于Darknet框架实现的。
首先看下效果图:

接下来看下数据情况:

标注文件如下:

实例标注数据内容如下所示:
0 0.482176 0.4 0.829268 0.593333
考虑到实时运行精度和速度的需求,这里选择的是yolov5s模型,如下:
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license# Parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32#Backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]#Head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]
默认100次的迭代训练,结果详情如下:
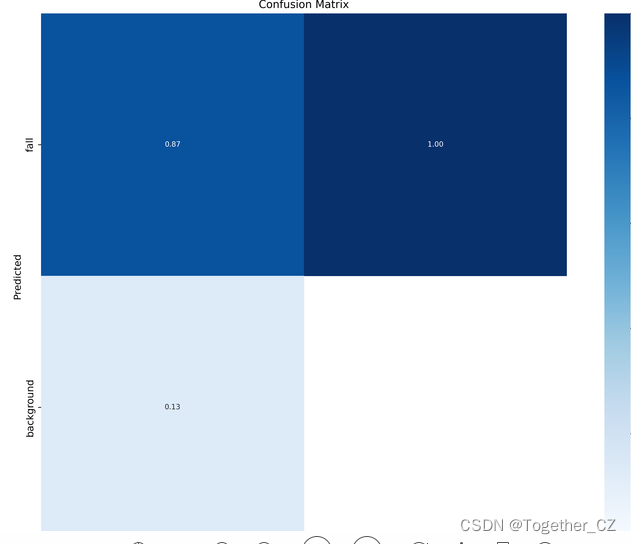
【混淆矩阵】
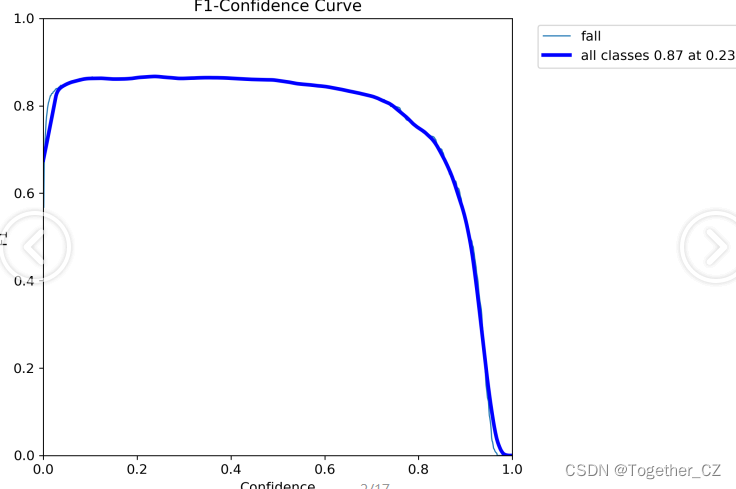
【F1值曲线】
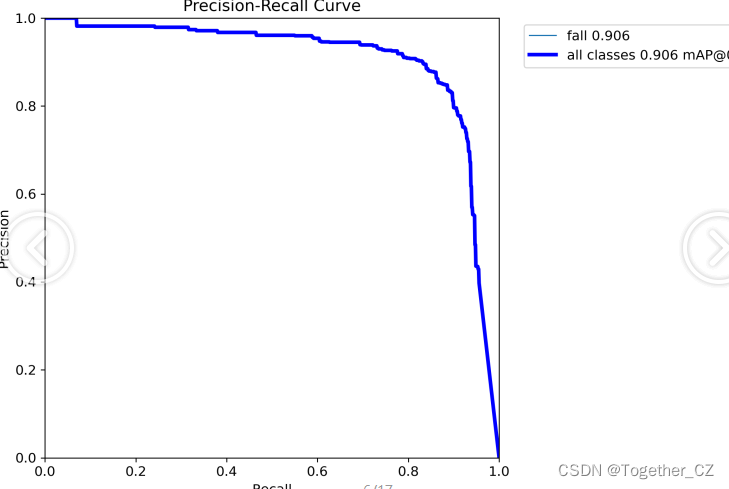
【PR曲线】
Batch计算实例:

从检测评估指标上直观来看。最终模型的效果还不错,但是还是有一定优化空间的。
在之前的一些项目中,看到也有一些人是基于连续的视频帧数据来实现的摔倒检测,相比她们的方法,本文的方法就比较简单了,是直接基于静态图片实现的检测,但是如何是想要对摔倒这个行为过程进行识别判断的话还是得基于连续帧或者是视频数据才行的,这里我们只是简单的基于目标检测的方式来探索式地开发实践了。
这篇关于基于轻量级yolov5模型摔倒行文检测识别系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








