本文主要是介绍树叶识别系统python+Django网页界面+TensorFlow+算法模型+数据集+图像识别分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、介绍
树叶识别系统。使用Python作为主要编程语言开发,通过收集常见的6中树叶(‘广玉兰’, ‘杜鹃’, ‘梧桐’, ‘樟叶’, ‘芭蕉’, ‘银杏’)图片作为数据集,然后使用TensorFlow搭建ResNet50算法网络模型,通过对数据集进行处理后进行模型迭代训练,得到一个识别精度较高的H5模型文件。并基于Django框架开发网页端平台,实现用户在网页上上传一张树叶图片识别其名称。
二、系统效果图片展示

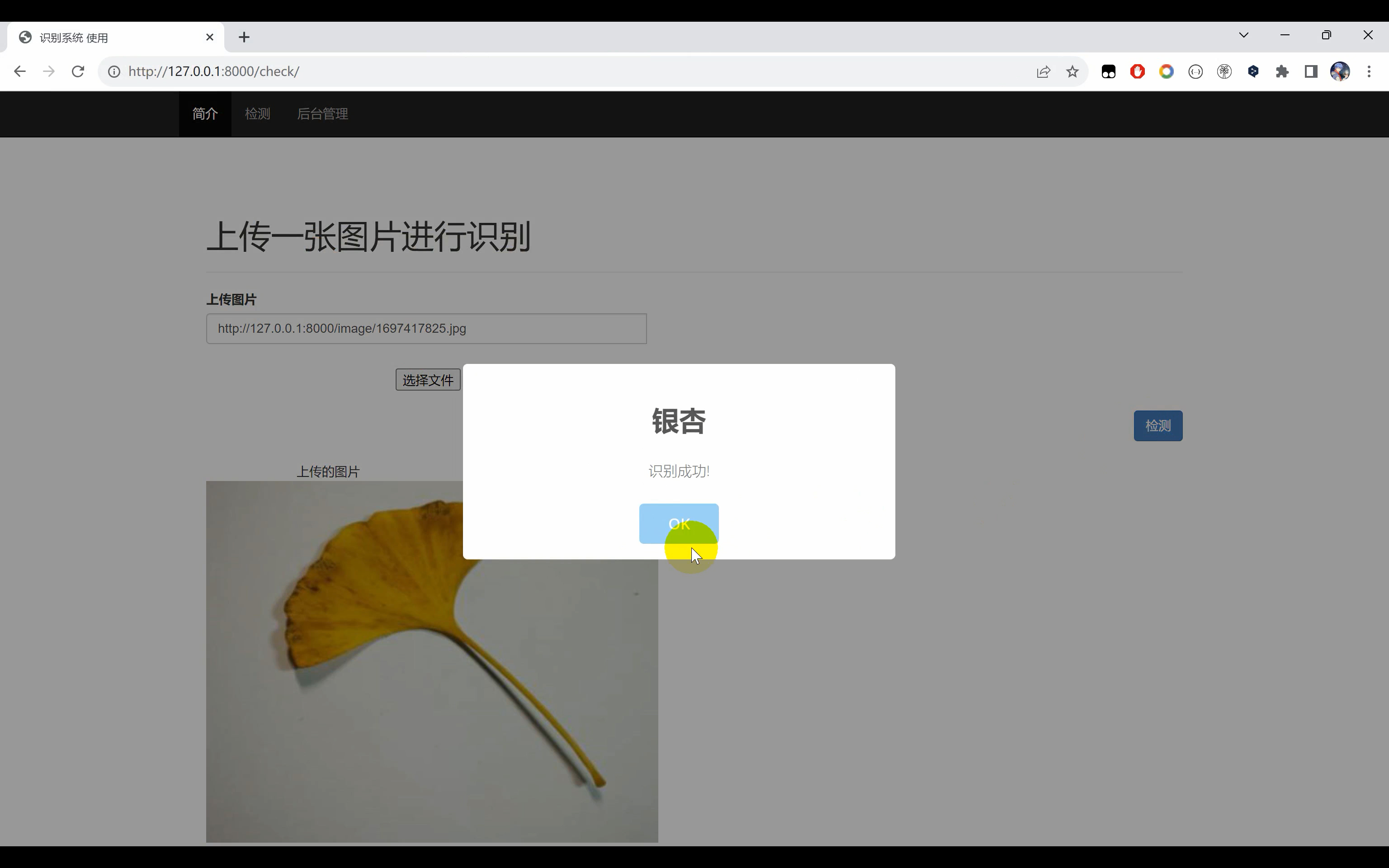
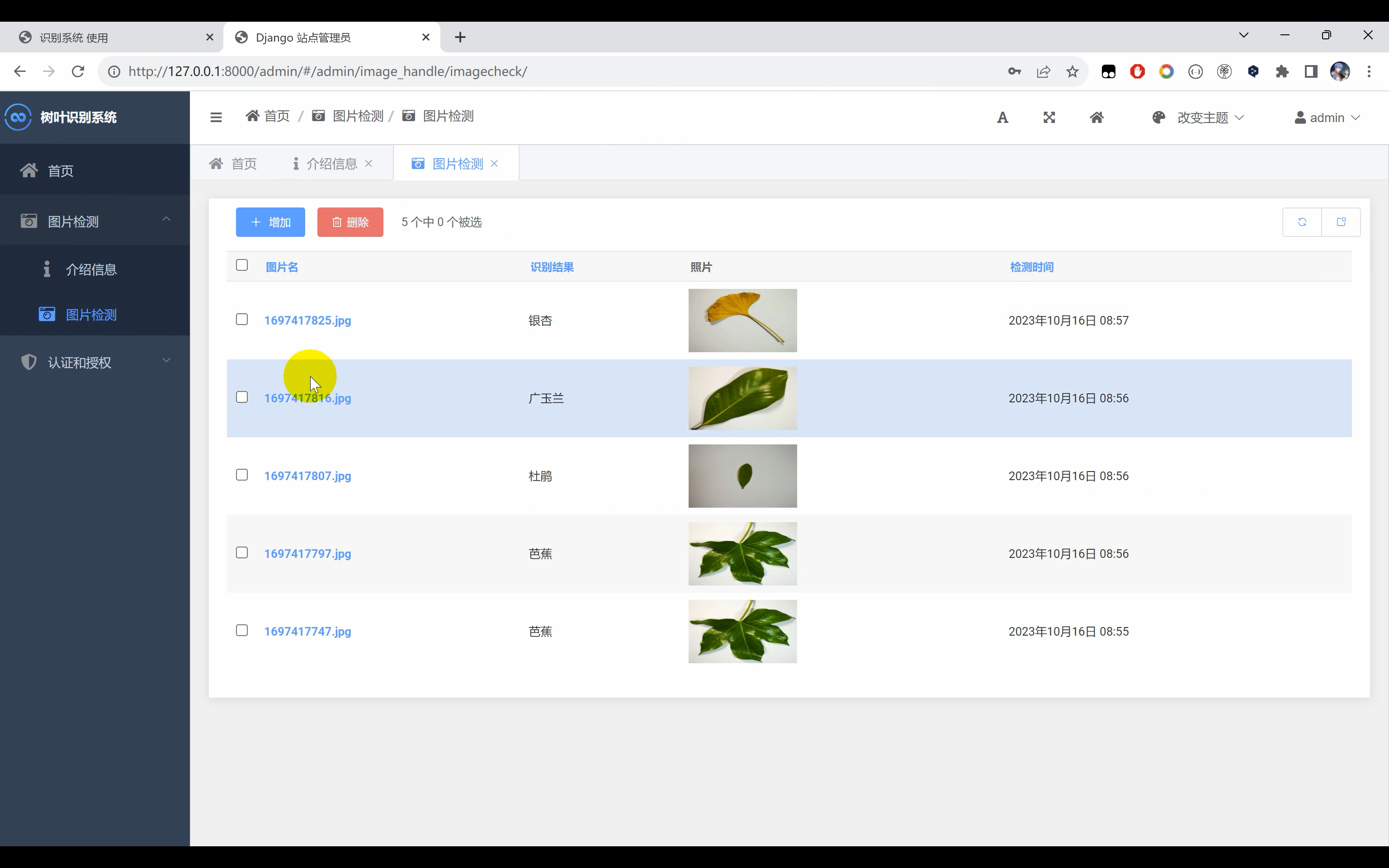
三、演示视频 and 代码 and 介绍
视频+代码+介绍:yuque.com/ziwu/yygu3z/yt0dsez3zk2dxs66
四、卷积神经网络介绍
卷积神经网络(Convolutional Neural Network, CNN)是一种专门用来处理具有类似网格结构数据的神经网络,如图像(2D网格的像素点)或声音信号(1D网格的音频振幅)。
卷积神经网络的特点:
- 局部感受野:CNN通过使用小的、局部的滤波器(称为卷积核)来扫描输入数据,从而捕捉局部的特征,如边缘、纹理等。
- 权重共享:同一个卷积核在整个输入数据上滑动,共享参数,这大大减少了模型的参数数量。
- 多层卷积层:通过堆叠多个卷积层,CNN可以学习到从简单到复杂的特征。
- 池化层:用于降维和减少计算量,同时增强了特征的不变性。
- 全连接层:在卷积层和池化层提取特征后,使用全连接层进行最终的分类。
使用TensorFlow搭建一个简单的卷积神经网络:
首先,假设我们要对CIFAR-10数据集进行分类。这是一个包含10个类别的60,000张32x32彩色图像的数据集。
以下是一个简单的CNN模型实例:
import tensorflow as tf
from tensorflow.keras import layers, models, datasets# 1. 数据加载和预处理
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()# 将像素值缩放到0到1之间
train_images, test_images = train_images / 255.0, test_images / 255.0# 2. 模型构建
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10))# 3. 编译模型
model.compile(optimizer='adam',loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=['accuracy'])# 4. 训练模型
history = model.fit(train_images, train_labels, epochs=10, validation_data=(test_images, test_labels))# 5. 评估模型
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)
这个模型非常简单,只包含3个卷积层、2个最大池化层和2个全连接层。您可以根据需要调整网络结构和参数。
这篇关于树叶识别系统python+Django网页界面+TensorFlow+算法模型+数据集+图像识别分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




