网页专题

使用Python实现获取网页指定内容
《使用Python实现获取网页指定内容》在当今互联网时代,网页数据抓取是一项非常重要的技能,本文将带你从零开始学习如何使用Python获取网页中的指定内容,希望对大家有所帮助... 目录引言1. 网页抓取的基本概念2. python中的网页抓取库3. 安装必要的库4. 发送HTTP请求并获取网页内容5. 解
Python使用DrissionPage中ChromiumPage进行自动化网页操作
《Python使用DrissionPage中ChromiumPage进行自动化网页操作》DrissionPage作为一款轻量级且功能强大的浏览器自动化库,为开发者提供了丰富的功能支持,本文将使用Dri... 目录前言一、ChromiumPage基础操作1.初始化Drission 和 ChromiumPage

网页解析 lxml 库--实战
lxml库使用流程 lxml 是 Python 的第三方解析库,完全使用 Python 语言编写,它对 XPath表达式提供了良好的支 持,因此能够了高效地解析 HTML/XML 文档。本节讲解如何通过 lxml 库解析 HTML 文档。 pip install lxml lxm| 库提供了一个 etree 模块,该模块专门用来解析 HTML/XML 文档,下面来介绍一下 lxml 库
EasyPlayer.js网页H5 Web js播放器能力合集
最近遇到一个需求,要求做一款播放器,发现能力上跟EasyPlayer.js基本一致,满足要求: 需求 功性能 分类 需求描述 功能 预览 分屏模式 单分屏(单屏/全屏) 多分屏(2*2) 多分屏(3*3) 多分屏(4*4) 播放控制 播放(单个或全部) 暂停(暂停时展示最后一帧画面) 停止(单个或全部) 声音控制(开关/音量调节) 主辅码流切换 辅助功能 屏

禁止复制的网页怎么复制
禁止复制的网页怎么复制 文章目录 禁止复制的网页怎么复制前言准备工作操作步骤一、在浏览器菜单中找到“开发者工具”二、点击“检查元素(inspect element)”按钮三、在网页中选取需要的片段,锁定对应的元素四、复制被选中的元素五、粘贴到记事本,以`.html`为后缀命名六、打开`xxx.html`,优雅地复制 前言 在浏览网页的时候,有的网页内容无法复制。比如「360
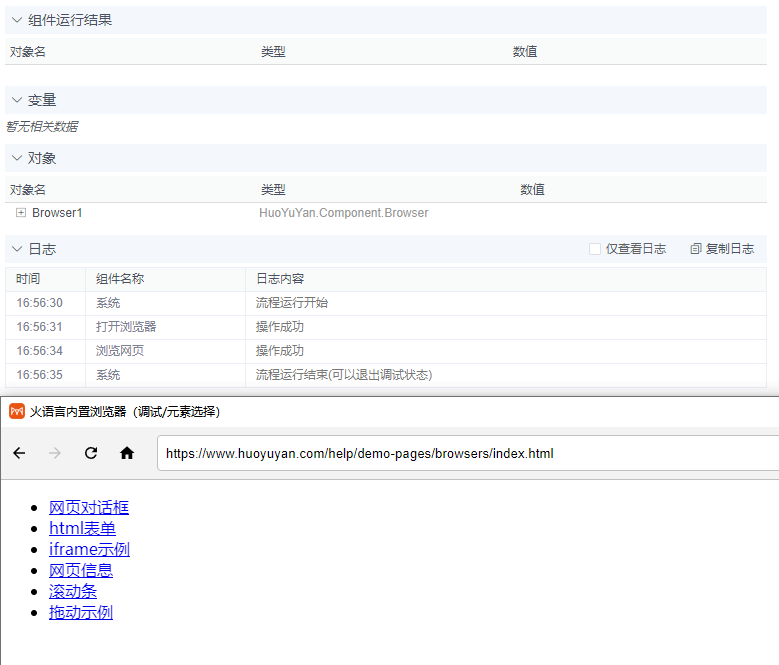
火语言RPA流程组件介绍--浏览网页
🚩【组件功能】:浏览器打开指定网址或本地html文件 配置预览 配置说明 网址URL 支持T或# 默认FLOW输入项 输入需要打开的网址URL 超时时间 支持T或# 打开网页超时时间 执行后后等待时间(ms) 支持T或# 当前组件执行完成后继续等待的时间 UserAgent 支持T或# User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器

起点中文网防止网页调试的代码展示
起点中文网对爬虫非常敏感。如图,想在页面启用调试后会显示“已在调试程序中暂停”。 选择停用断点并继续运行后会造成cpu占用率升高电脑卡顿。 经简单分析网站使用了js代码用于防止调试并在强制继续运行后造成电脑卡顿,代码如下: function A(A, B) {if (null != B && "undefined" != typeof Symbol && B[Symbol.hasInstan

(入门篇)JavaScript 网页设计案例浅析-简单的交互式图片轮播
网页设计已经成为了每个前端开发者的必备技能,而 JavaScript 作为前端三大基础之一,更是为网页赋予了互动性和动态效果。本篇文章将通过一个简单的 JavaScript 案例,带你了解网页设计中的一些常见技巧和技术原理。今天就说一说一个常见的图片轮播效果。相信大家在各类电商网站、个人博客或者展示页面中,都看到过这种轮播图。它的核心功能是展示多张图片,并且用户可以通过点击按钮,左右切换图片。

【IPV6从入门到起飞】4-RTMP推流,ffmpeg拉流,纯HTML网页HLS实时直播
【IPV6从入门到起飞】4-RTMP推流,ffmpeg拉流,纯HTML网页HLS实时直播 1 背景2 搭建rtmp服务器2.1 nginx方案搭建2.1.1 windows 配置2.1.2 linux 配置 2.2 Docker方案搭建2.2.1 docker 下载2.2.2 宝塔软件商店下载 3 rtmp推流3.1 EV录屏推流3.2 OBS Studio推流 4 ffmpeg拉流转格式
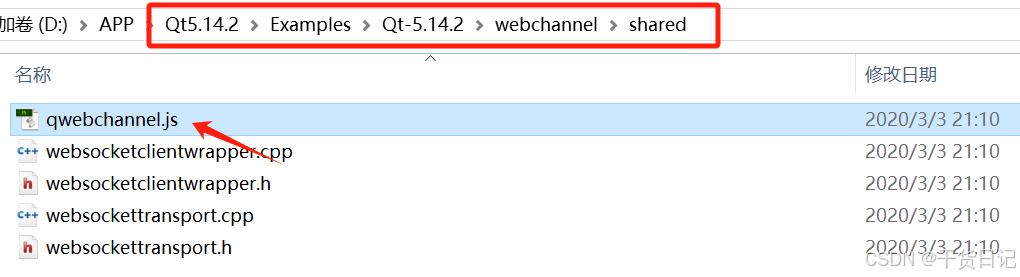
【Qt】Qt与Html网页进行数据交互
前言:此项目使用达梦数据库,以Qt制作服务器,Html制作网页客户端界面,可以通过任意浏览器访问。 1、Qt与网页进行数据交互 1.1、第一步:准备qwebchannel.js文件 直接在qt的安装路径里复制即可 1.2、第二步:在Qt的.pro文件加载webchannel组件 在.pro文件添加如下组件: QT += core gui sql webchannel wi
浅析网页不安装插件播放RTSP/FLV视频的方法
早期很多摄像头视频流使用的是RTSP、RTMP协议,播放这类协议的视频通常是在网页上安装插件。但现在越来越多的用户,对于网页安装插件比较反感,且随着移动设备的普及,用户更多的希望使用手机、平板等移动设备,直接可以查看这些协议的视频。那是否有什么方案可以直接网页打开RTSP、RTMP协议的视频,直接观看不用安装插件呢?而且对于摄像头的数据,尽可能低延迟的获取实时画面。 其实很多摄像头厂家也注意到

运用WPS快速整理中英混排的网页文字的方法
朋友从网上下载了一篇技术文档,发现文档中每一行的行末都有一个段落符号,而真正要分段的段首则有4个半角空格,还有许多空段。 想重新编排一下,由于文档比较长,手工操作肯定不行,我向他推荐用WPS文字的“智能格式整理”功能。在该文档处于打开状态时,用鼠标点开“工具”菜单下的“文字工具→智能格式整理”,几秒钟后,所有的段首空格全部消失,段与段之间的空段也全部消除,但每一行行末的段落标记却依然

计应3-01-静态网页
JDK标准配置 第一个静态网页 <!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>Document</title></head><body>我的
网页中经常见到的,点击菜单栏,跳转到执行元素的位置
* 点击滑动制定位置* @param scrolldom 点击的制定元素* @param scrollTime 滑动的时间*/$.scrollto = function (scrolldom,scrollTime) {//dom点击事件$(scrolldom).click(function () {//查找点击dom里的属性,要在dom元素里添加var scrolldom = $(t

网页时装购物系统:Spring Boot框架的创新设计
第1章 绪论 1.1背景及意义 随着社会的快速发展,计算机的影响是全面且深入的。人们生活水平的不断提高,日常生活中人们对时装购物系统方面的要求也在不断提高,喜欢购物的人数更是不断增加,使得时装购物系统的开发成为必需而且紧迫的事情。时装购物系统主要是借助计算机,通过对时装购物系统所需的信息管理,增加用户的选择,同时也方便对广大时装购物系统的及时查询、修改以及对时装购物系统的及时了解。时装购物系统对用

时尚购物革命:Spring Boot技术在网页时装系统中的应用
第1章 绪论 1.1背景及意义 随着社会的快速发展,计算机的影响是全面且深入的。人们生活水平的不断提高,日常生活中人们对时装购物系统方面的要求也在不断提高,喜欢购物的人数更是不断增加,使得时装购物系统的开发成为必需而且紧迫的事情。时装购物系统主要是借助计算机,通过对时装购物系统所需的信息管理,增加用户的选择,同时也方便对广大时装购物系统的及时查询、修改以及对时装购物系统的及时了解。时装购物系统对用

html css网页制作成品
前言 在HTML和CSS中创建一个网页是一个简单的过程,但是要创建一个成品级的网页,你需要考虑更多的因素,例如: 响应式设计:确保你的网页在不同的设备和屏幕尺寸上都能良好显示。 访问性:确保你的网页对于大多数的用户都很友好。 标准的遵从性:遵循HTML和CSS的最佳实践,以便更容易维护和更新。 以下是一个简单的HTML和CSS结合的成品级网页示例: 一、html代码 <div c

html+css网页设计 我的家乡5个页面
html+css网页设计 我的家乡5个页面 网页作品代码简单,可使用任意HTML辑软件(如:Dreamweaver、HBuilder、Vscode 、Sublime 、Webstorm、Text 、Notepad++ 等任意html编辑软件进行运行及修改编辑等操作)。 获取源码 1,访问该网站 https://download.csdn.net/download/qq_42431718/89
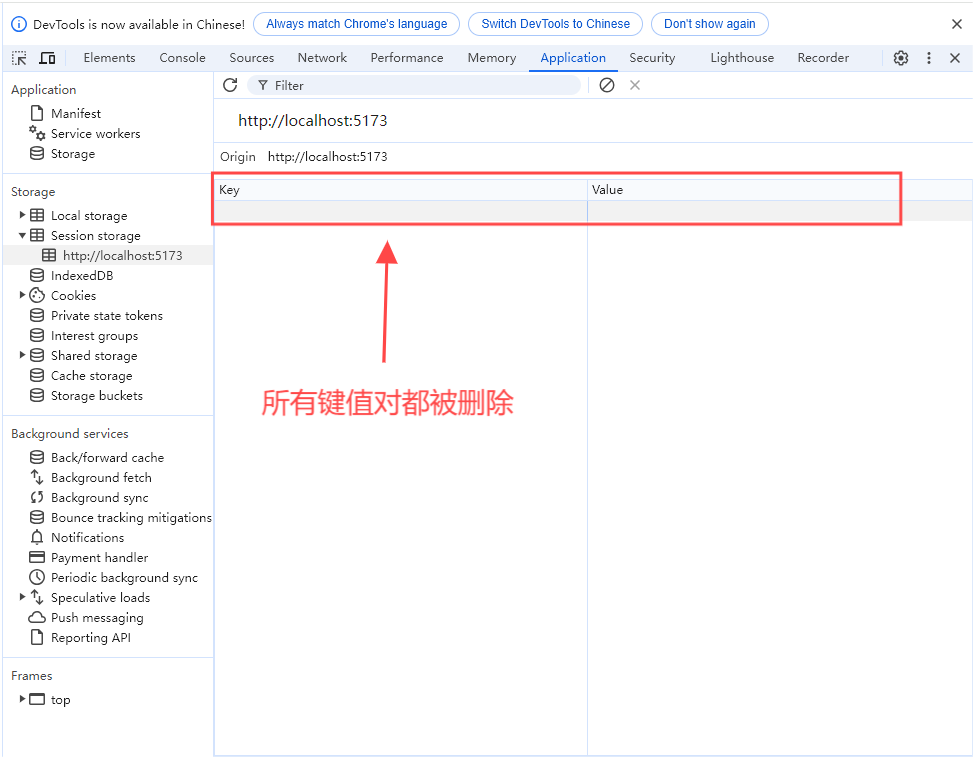
浏览器百科:网页存储篇-Session storage应用实例(九)
1.引言 在前面的文章中,我们详细介绍了如何在 Chrome 浏览器中打开并使用 Session storage 窗格,进行数据的查看、编辑和管理。作为网页存储技术的重要组成部分,sessionStorage在提升用户体验和数据管理能力方面发挥了重要作用。在本篇《浏览器百科:网页存储篇-Session storage应用实例(九)》中,我们将深入探讨sessionStorage的实际应用场景,通

物联网之ESP32控制舵机、通过网页设置舵机角度、Web服务、舵机原理、接线、Arduino、WiFi、Http
MENU 前言原理硬件电路设计软件程序设计LEDC输出PWM信号使用第三方库控制舵机网页控制舵机 前言 舵机在电子产品中非常常见,比如四足机器人、固定翼航模等都有应用,因此学习舵机对电子制作非常有意义。本文章使用Arguino的PWM对SG90舵机旋转角度控制。 原理 舵机是一种位置(角度)伺服的驱动器,适用于那些需要角度不断变化并可以保持的控制系统。舵机只
JavaScript 实现网页菜单延迟加载效果》
目录 一、整体代码结构 二、代码注解 1. HTML 结构部分 2. CSS 样式部分 3. JavaScript 部分 一、整体代码结构 <!DOCTYPE html><html lang="en"><head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial
【Python获取网页元素的值】
Python 高效获取网页元素值全攻略 在当今数字化的时代,从网页中提取特定元素的值已成为许多数据处理和分析任务的关键步骤。无论是进行网页数据挖掘、自动化信息收集,还是构建个性化的网页应用,准确获取网页元素值都是至关重要的。本文将深入探讨如何使用 Python 实现网页元素值的获取,并通过一个具体的问题场景进行详细说明。 一、问题背景与重要性 在日常的网页操作和数据分析中,我们常常需要从网页

Qt放Element网页滑动菜单栏
基于QTabWidget实现菜单 tabwidget.h #ifndef TAB_WIDGET_H#define TAB_WIDGET_H#include <QTabWidget>#include <QVariantAnimation>#include "customcomponent_global.h"class TabBarAnimation;class TabWidget : pu
微信公众号h5网页-调用录音评测
一、全局引入jweixin-1.6.0.js微信能力插件; 二、初始化微信配置,开启音频相关能力; initWxConfig() {let url = window.location.href.split('#')[0]let data = { url: url }this.$http.get(this.$api.getTicket, { params: data }).then((res)
将网页保存为PDF---不分页
将网页保存为PDF---不分页 1.要下载的内容 <div ref="reportContent">写入要下载的内容</div> 2.下载的方法 downloadPDF() {html2canvas(this.$refs.reportContent, {scale: 1.5, // 降低缩放比例来减少图像大小(从2降到1.5)useCORS: true,width: this.$