本文主要是介绍爬虫 | 【实践】Best Computer Science Scientists数据爬取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 📚数据需求
- 📚数据爬取
- 🐇排行榜页数据爬取
- 🐇获取详情页
- 🐇目标信息提取
- 📚完整代码与结果
📚数据需求
-
姓名,国家,学校

-
最有名研究领域
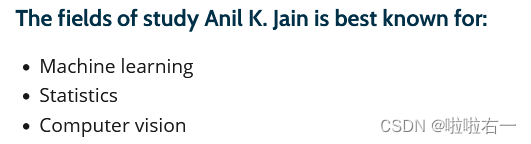
-
目前研究领域

-
共同作者

-
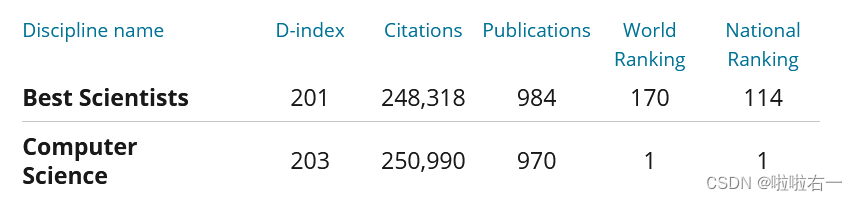
D-index、引用、出版物、世界排名、国家排名
📚数据爬取
🐇排行榜页数据爬取
# 以for循环实现翻页,总共20页
for page in range(1, 21):# 前缀f表示该字符串是一个格式化字符串,允许我们在字符串中嵌入变量或表达式的值。# 这里嵌入变量page,实现翻页后的url对应url = f"https://research.com/scientists-rankings/computer-science?page={page}"# 获得响应response = requests.get(url=url, headers=headers)# 智能解码response.encoding = response.apparent_encoding# 使用etree.HTML函数将HTML文本转换为可进行XPath操作的树结构对象tree。tree = etree.HTML(response.text)# 提取id为"rankingItems"元素下的所有div子元素的列表div_list = tree.xpath('//*[@id="rankingItems"]/div')
- 定位到
id="rankingItems
- 每一个
div是每一条排行记录
🐇获取详情页
# 循环取出div_list内容for i in div_list:# 获取当前科学家的详情页地址href = 'https://research.com' + i.xpath('.//div//h4/a/@href')[0]print(href)# 调用等待时间函数,防止宕机random_wait()# 获得详情页响应response_detail = requests.get(url=href, headers=headers)# 智能解码response.encoding = response.apparent_encoding# 使用etree.HTML函数将HTML文本转换为可进行XPath操作的树结构对象tree。tree_detail = etree.HTML(response_detail.text)
.//div//h4/a/@href获取对应科学家详情页相关信息,通过href = 'https://research.com' + i.xpath('.//div//h4/a/@href')[0]得到详情页url
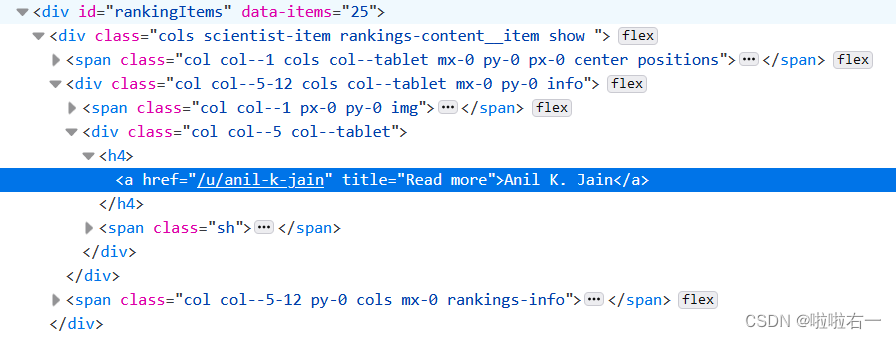
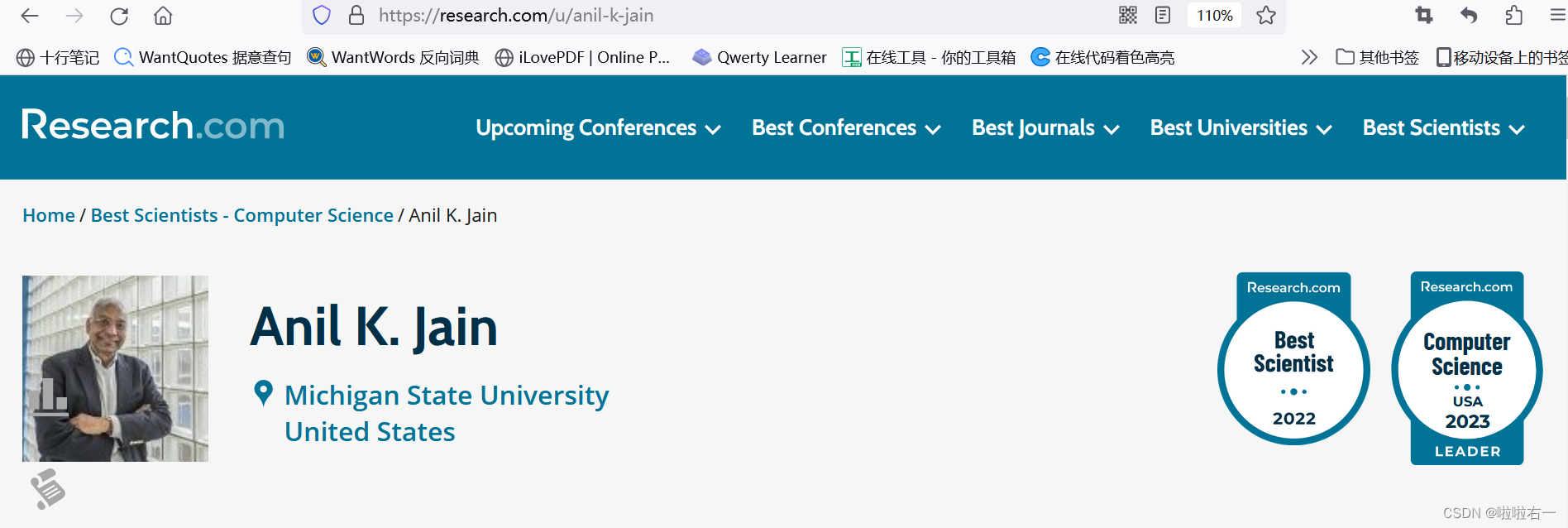
- 对应详情页url如下所示
🐇目标信息提取
- 姓名
# 名字,依次找到htm → body → 第1个div → 第2个div → 第1个div → div → h1元素,匹配文本内容 # .strip()用于去除文本内容两端的空白字符,包括空格、制表符和换行符。 name = tree_detail.xpath('/html/body/div[1]/div[2]/div[1]/div/h1/text()')[0].strip()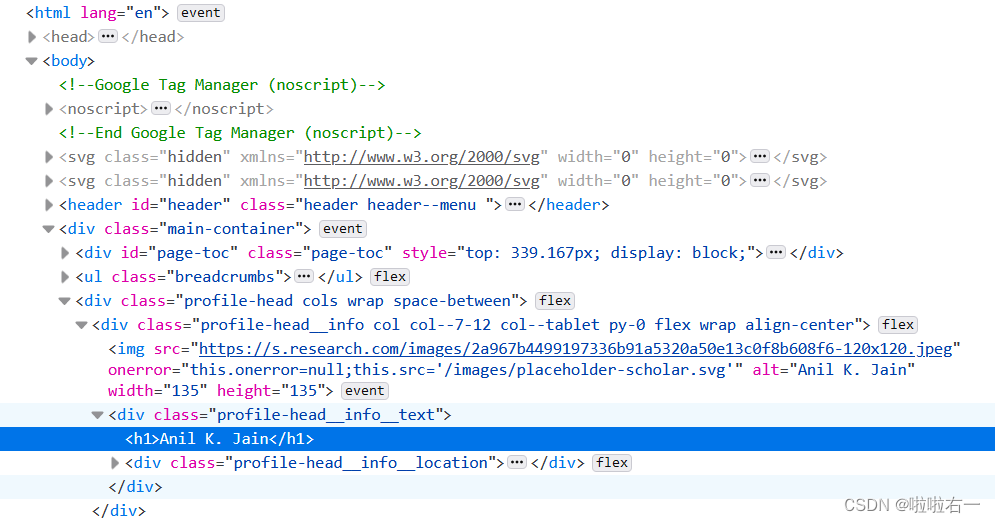
-
国家
country = tree_detail.xpath('/html/body/div[1]/div[2]/div[1]/div/div/p/a[2]/text()')[0].strip()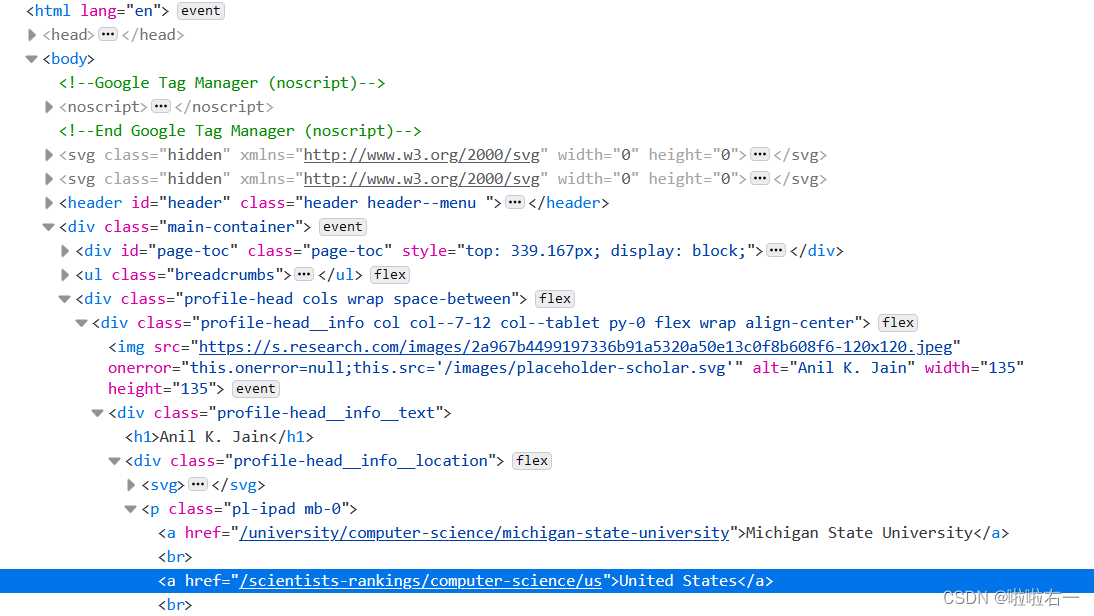
-
学校
university = tree_detail.xpath('/html/body/div[1]/div[2]/div[1]/div/div/p/a[1]/text()')[0].strip()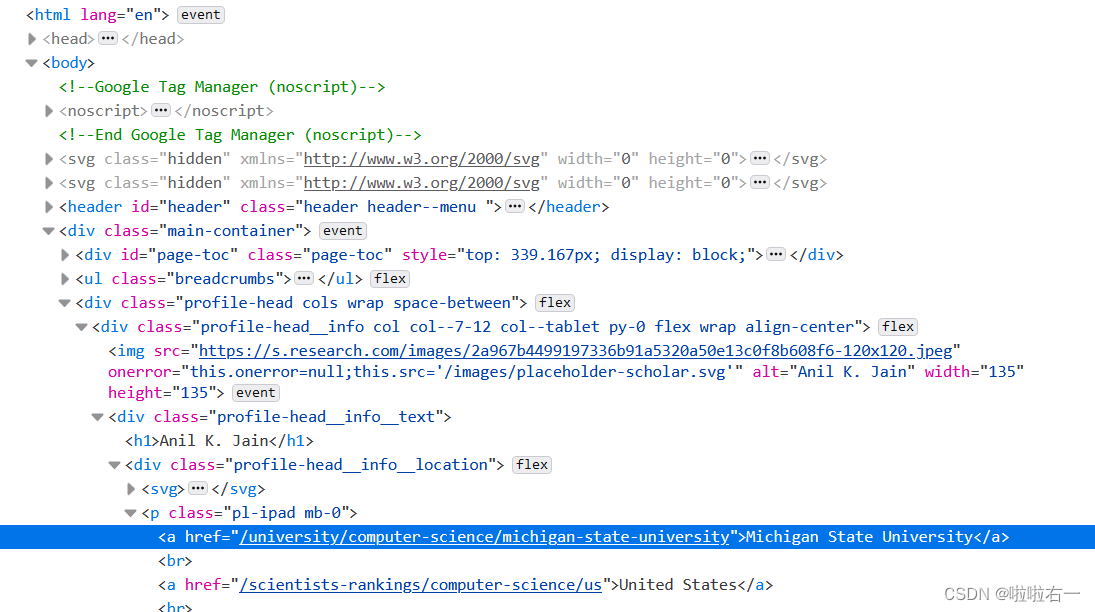
-
最有名研究领域
try:research_field1 = tree_detail.xpath('//*[@class="tab bg-white shadow"]//ul[1]/li/text()')[0].strip()research_field2 = tree_detail.xpath('//*[@class="tab bg-white shadow"]//ul[1]/li/text()')[1].strip()research_field3 = tree_detail.xpath('//*[@class="tab bg-white shadow"]//ul[1]/li/text()')[2].strip() except:# 异常处理,有些详情页无对应数据research_field1="无研究领域"research_field2="无研究领域"research_field3 ="无研究领域"
-
目前研究领域
try: # 目前研究领域# 将匹配正则表达式pattern的内容替换为空字符串。删除括号及其内部的内容。now_research_field1 = re.sub(pattern, '', tree_detail.xpath('//*[@class="tab bg-white shadow"]//ul[4]/li/text()')[0].strip())now_research_field2 = re.sub(pattern, '', tree_detail.xpath('//*[@class="tab bg-white shadow"]//ul[4]/li/text()')[1].strip())now_research_field3 = re.sub(pattern, '', tree_detail.xpath('//*[@class="tab bg-white shadow"]//ul[4]/li/text()')[2].strip()) except:now_research_field1="无研究领域"now_research_field2="无研究领域"now_research_field3 ="无研究领域"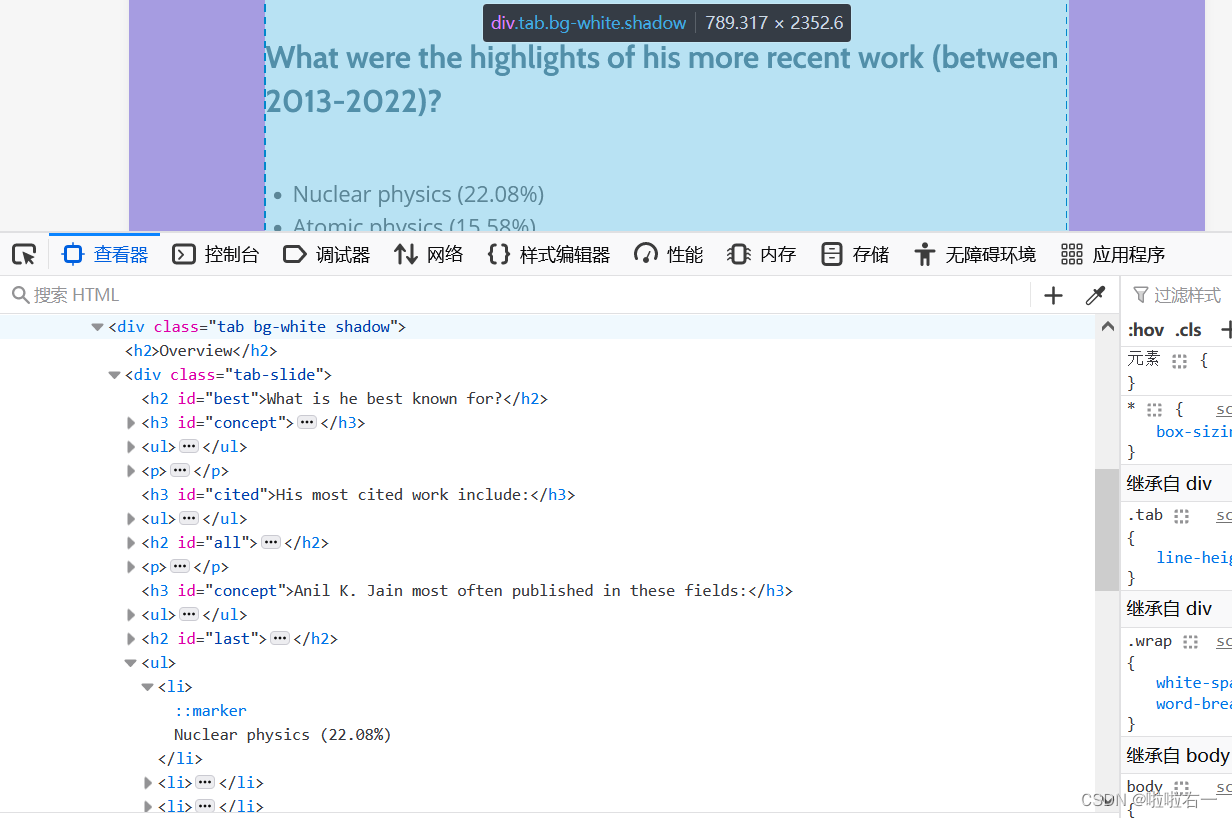
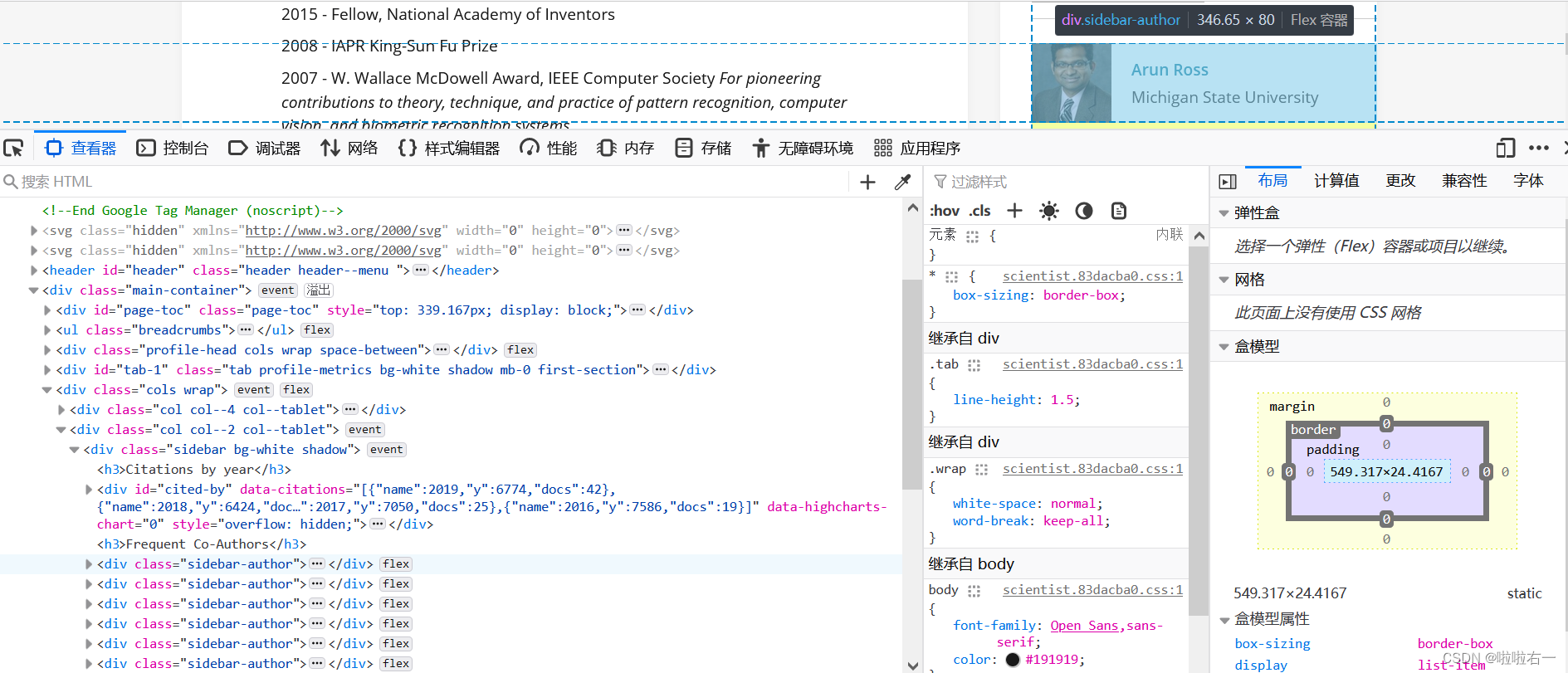
- 共同作者
# 共同作者,定位后源码里的第一个div不要 Frequent_CoAuthors = tree_detail.xpath('/html/body/div[1]/div[4]/div[2]/div/div')[1:] # 共同关系的人 for i in Frequent_CoAuthors:common_name = i.xpath('.//h4/a/text()')[0].strip().replace('\n', '')friend_list.append(common_name) # 将共同关系的人拼成一个字符串 result = ', '.join(friend_list)tree_detail.xpath('/html/body/div[1]/div[4]/div[2]/div/div')[1:]——定位到列表框
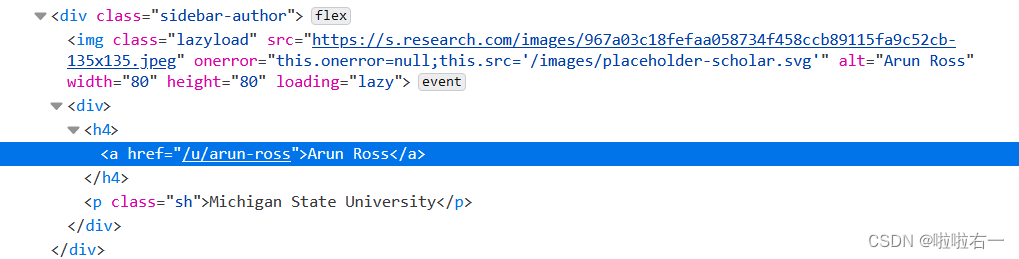
i.xpath('.//h4/a/text()')[0].strip().replace('\n', '')——定位到每个人
-
各项数据、排名等
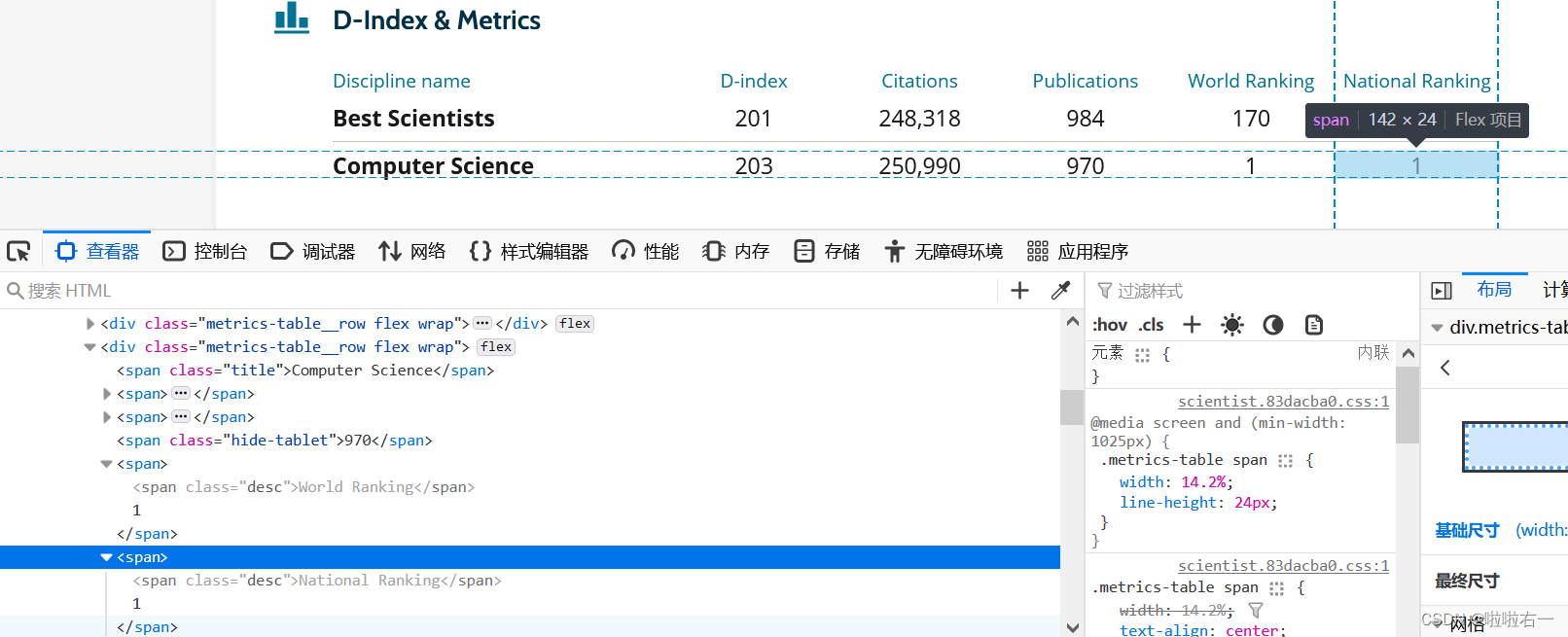
# 各项数据,排名等等,[-1:]返回匹配结果列表中的最后一个元素 data_list = tree_detail.xpath('//*[@id="tab-1"]/div/div')[-1:] for a in data_list:# D-indexD_index = a.xpath('.//span[2]//text()')[-1].replace(' ', '').replace('\n', '')# 引用Citations = a.xpath('.//span[3]//text()')[-1].replace(' ', '').replace('\n', '').replace(',', '')# 出版物publication = a.xpath('.//span[4]//text()')[-1].replace(' ', '').replace('\n', '').replace(',', '')# 世界排名world_rank = a.xpath('.//span[5]//text()')[-1].replace(' ', '').replace('\n', '')# 国家排名national_rank = a.xpath('.//span[6]//text()')[-1].replace(' ', '').replace('\n', '')-
//*[@id="tab-1"]/div/div——定位到数据表格
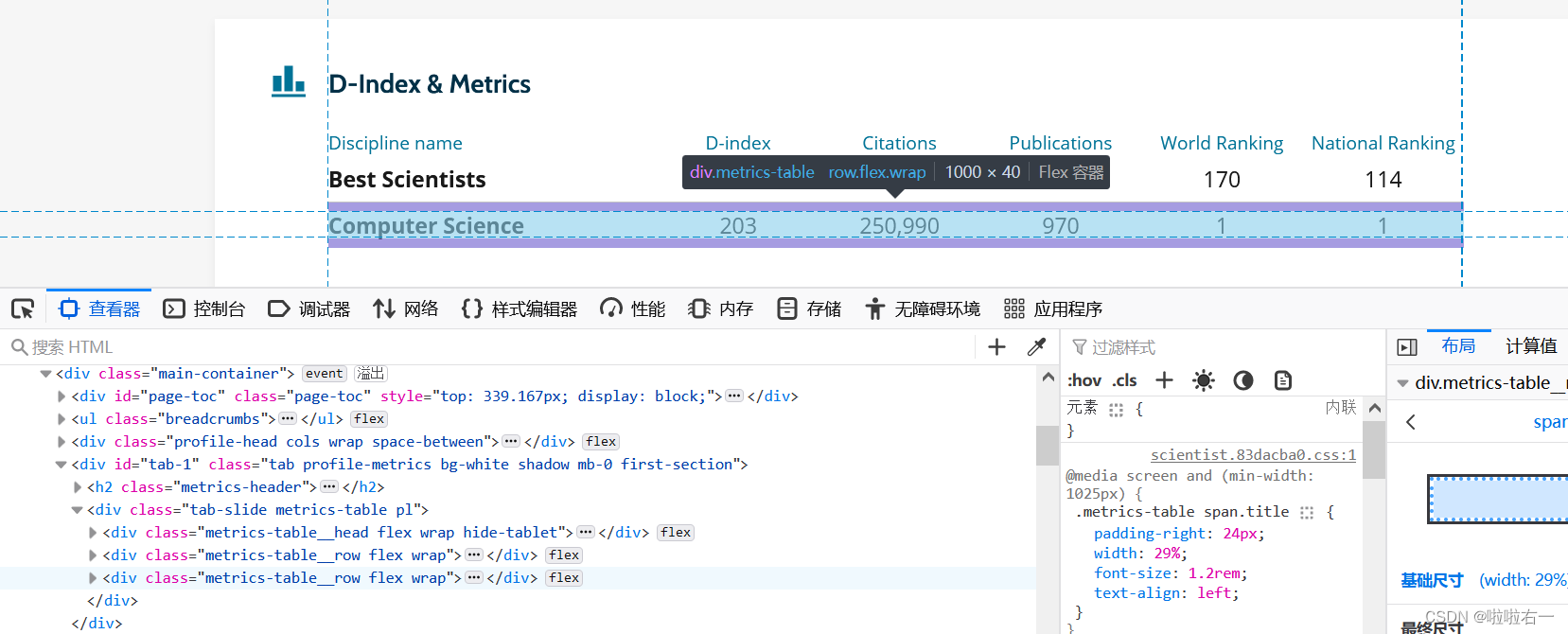
-
a.xpath('.//span[2]//text()')[-1]——D-index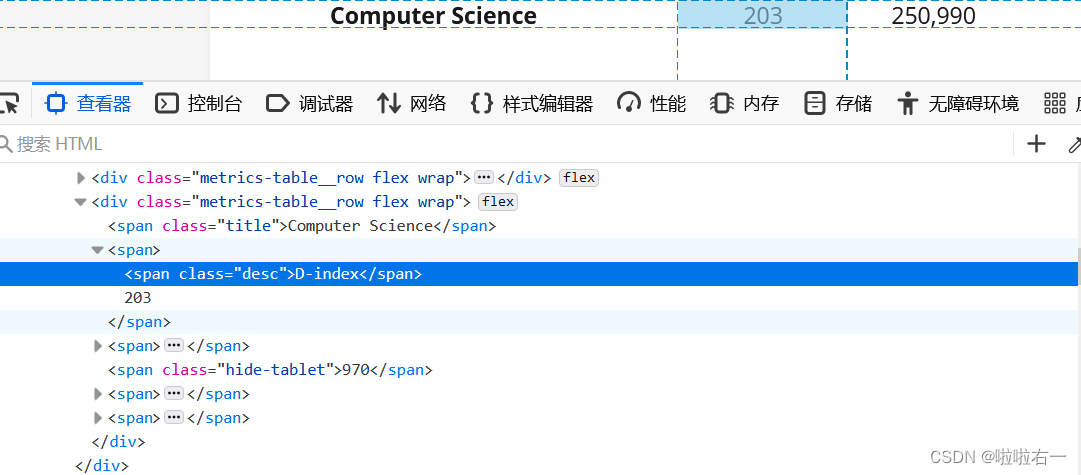
-
a.xpath('.//span[3]//text()')[-1]——引用
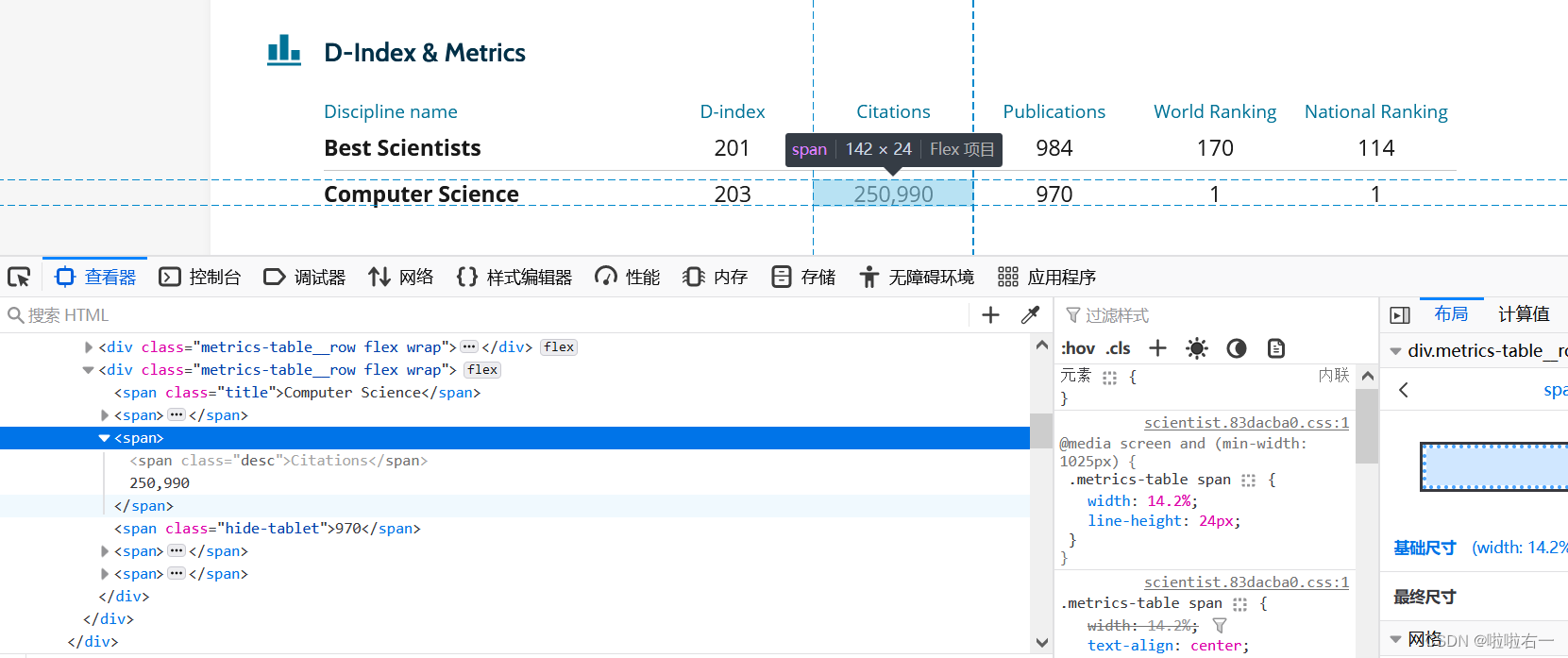
-
a.xpath('.//span[4]//text()')[-1]——出版物
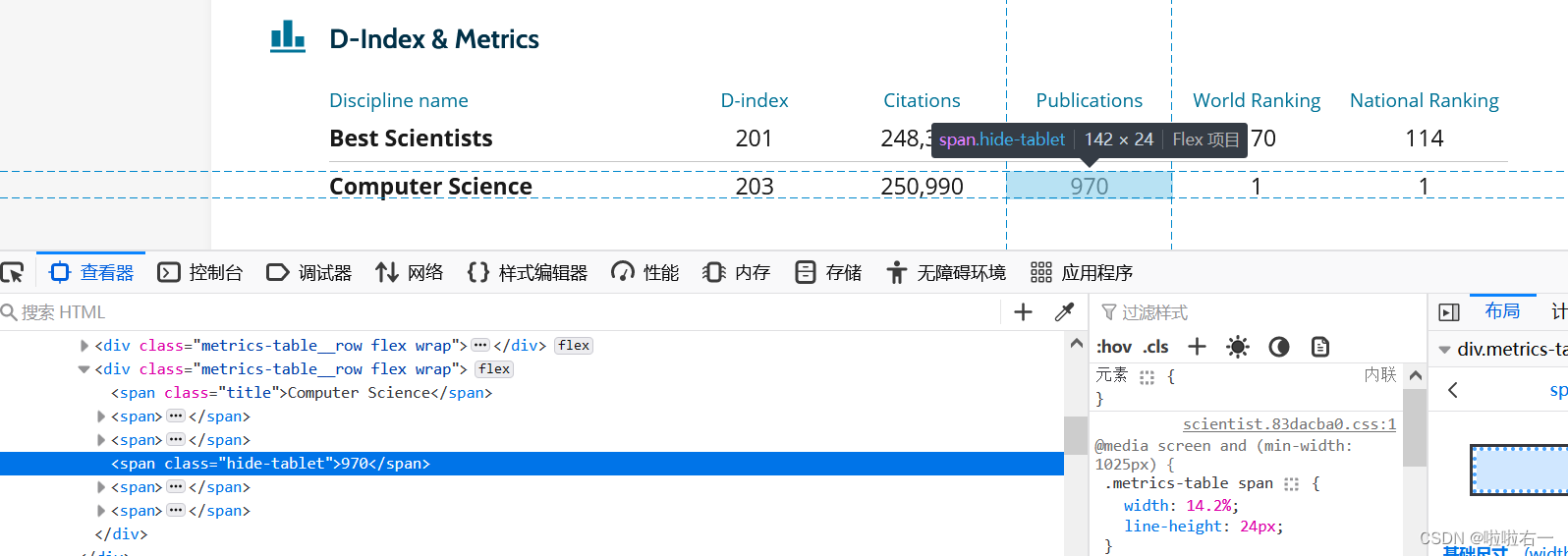
-
世界排名和国家排名
# 世界排名world_rank = a.xpath('.//span[5]//text()')[-1].replace(' ', '').replace('\n', '')# 国家排名national_rank = a.xpath('.//span[6]//text()')[-1].replace(' ', '').replace('\n', '')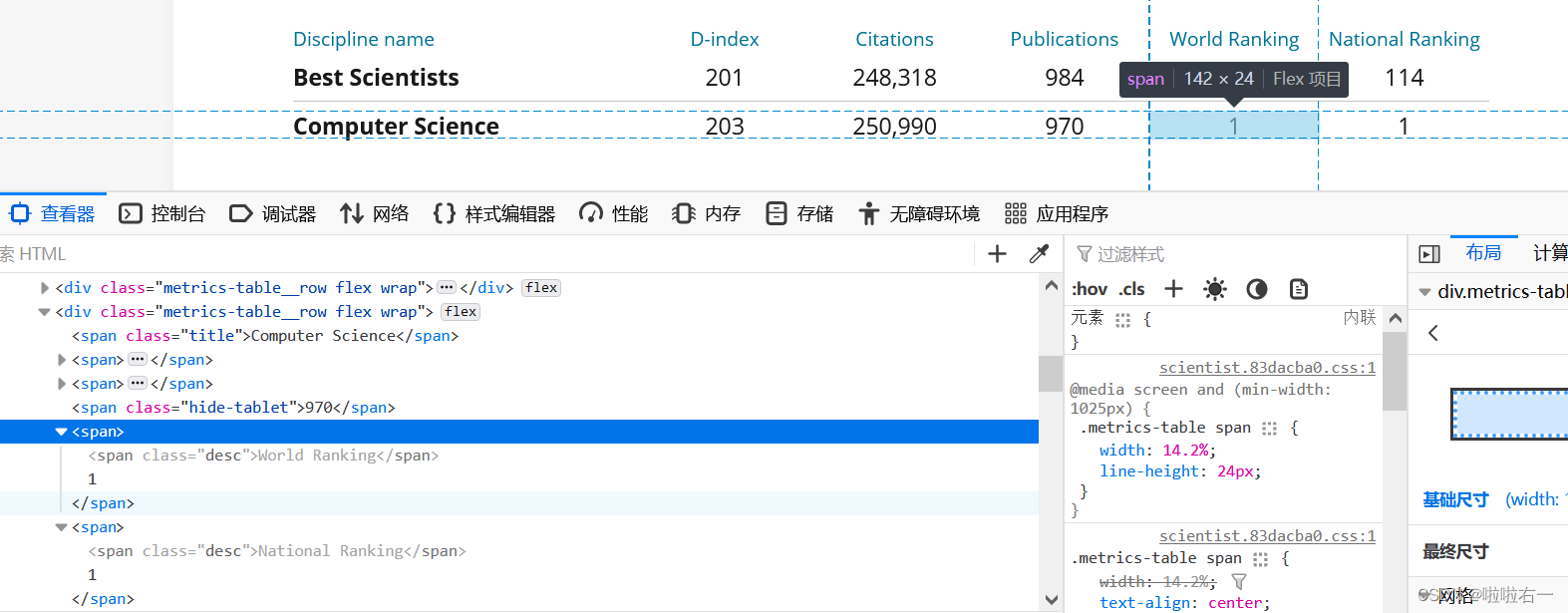
-
📚完整代码与结果
import requests
from lxml import etree
import openpyxl
import re
import random
import time# 随机等待时间的函数
# 避免以高频率向服务器发送请求造成宕机
def random_wait():# 生成一个随机的等待时间,范围为1到5秒wait_time = random.uniform(1, 5)time.sleep(wait_time)# openpyxl用于操作Excel文件。它允许我们读取、写入和修改Excel文件中的数据。
# 创建一个新的Excel工作簿对象
workbook = openpyxl.Workbook()
# 返回工作簿中的活动工作表对象,表明之后的代码对这个工作表进行操作
worksheet = workbook.active
# 添加标题
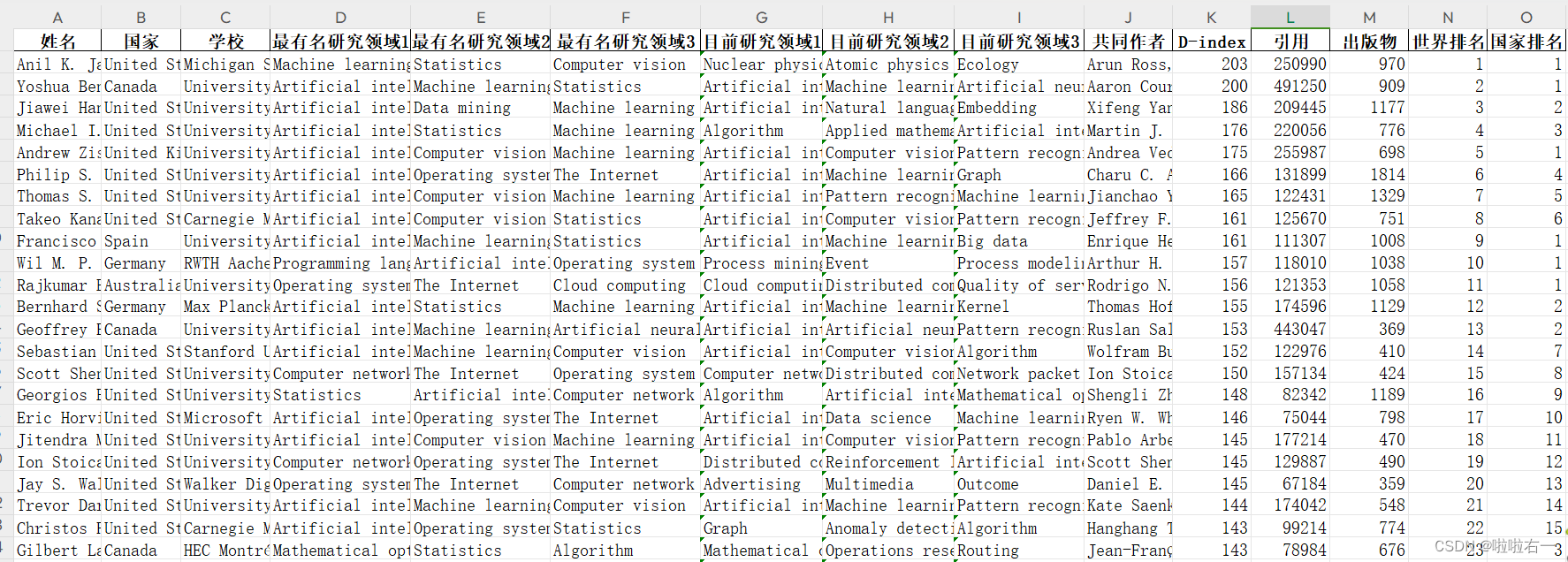
worksheet.append(['姓名', '国家', '学校', '最有名研究领域1', '最有名研究领域2', '最有名研究领域3', '目前研究领域1', '目前研究领域2','目前研究领域3', '共同作者', 'D-index', '引用', '出版物', '世界排名', '国家排名'])# 伪装请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/118.0'
}# 以for循环实现翻页,总共20页
for page in range(1, 21):# 前缀f表示该字符串是一个格式化字符串,允许我们在字符串中嵌入变量或表达式的值。# 这里嵌入变量page,实现翻页后的url对应url = f"https://research.com/scientists-rankings/computer-science?page={page}"# 获得响应response = requests.get(url=url, headers=headers)# 智能解码response.encoding = response.apparent_encoding# 使用etree.HTML函数将HTML文本转换为可进行XPath操作的树结构对象tree。tree = etree.HTML(response.text)# 提取id为"rankingItems"元素下的所有div子元素的列表div_list = tree.xpath('//*[@id="rankingItems"]/div')# 循环取出div_list内容for i in div_list:# 获取当前科学家的详情页地址href = 'https://research.com' + i.xpath('.//div//h4/a/@href')[0]print(href)# 调用等待时间函数,防止宕机random_wait()# 获得详情页响应response_detail = requests.get(url=href, headers=headers)# 智能解码response.encoding = response.apparent_encoding# 使用etree.HTML函数将HTML文本转换为可进行XPath操作的树结构对象tree。tree_detail = etree.HTML(response_detail.text)# 用于删除括号及其内部的内容,主要是对后边最近研究领域后续括号内的百分比进行删除pattern = r'\([^()]*\)'# 存取共同作者的列表friend_list = []try:# 名字,依次找到htm → body → 第1个div → 第2个div → 第1个div → div → h1元素,匹配文本内容# .strip()用于去除文本内容两端的空白字符,包括空格、制表符和换行符。name = tree_detail.xpath('/html/body/div[1]/div[2]/div[1]/div/h1/text()')[0].strip()# 国家country = tree_detail.xpath('/html/body/div[1]/div[2]/div[1]/div/div/p/a[2]/text()')[0].strip()# 学校university = tree_detail.xpath('/html/body/div[1]/div[2]/div[1]/div/div/p/a[1]/text()')[0].strip()# 最有名研究领域try:research_field1 = tree_detail.xpath('//*[@class="tab bg-white shadow"]//ul[1]/li/text()')[0].strip()research_field2 = tree_detail.xpath('//*[@class="tab bg-white shadow"]//ul[1]/li/text()')[1].strip()research_field3 = tree_detail.xpath('//*[@class="tab bg-white shadow"]//ul[1]/li/text()')[2].strip()except:# 异常处理,有些详情页无对应数据research_field1="无研究领域"research_field2="无研究领域"research_field3 ="无研究领域"try:# 目前研究领域# 将匹配正则表达式pattern的内容替换为空字符串。删除括号及其内部的内容。now_research_field1 = re.sub(pattern, '', tree_detail.xpath('//*[@class="tab bg-white shadow"]//ul[4]/li/text()')[0].strip())now_research_field2 = re.sub(pattern, '', tree_detail.xpath('//*[@class="tab bg-white shadow"]//ul[4]/li/text()')[1].strip())now_research_field3 = re.sub(pattern, '', tree_detail.xpath('//*[@class="tab bg-white shadow"]//ul[4]/li/text()')[2].strip())except:now_research_field1="无研究领域"now_research_field2="无研究领域"now_research_field3 ="无研究领域"# 共同作者,定位后源码里的第一个div不要Frequent_CoAuthors = tree_detail.xpath('/html/body/div[1]/div[4]/div[2]/div/div')[1:]# 共同关系的人for i in Frequent_CoAuthors:common_name = i.xpath('.//h4/a/text()')[0].strip().replace('\n', '')friend_list.append(common_name)# 将共同关系的人拼成一个字符串result = ', '.join(friend_list)# 各项数据,排名等等,[-1:]返回匹配结果列表中的最后一个元素data_list = tree_detail.xpath('//*[@id="tab-1"]/div/div')[-1:]for a in data_list:# D-indexD_index = a.xpath('.//span[2]//text()')[-1].replace(' ', '').replace('\n', '')# 引用Citations = a.xpath('.//span[3]//text()')[-1].replace(' ', '').replace('\n', '').replace(',', '')# 出版物publication = a.xpath('.//span[4]//text()')[-1].replace(' ', '').replace('\n', '').replace(',', '')# 世界排名world_rank = a.xpath('.//span[5]//text()')[-1].replace(' ', '').replace('\n', '')# 国家排名national_rank = a.xpath('.//span[6]//text()')[-1].replace(' ', '').replace('\n', '')print(name, country, university, research_field1, research_field2, research_field3, now_research_field1,now_research_field2, now_research_field3, result, D_index, Citations, publication, world_rank, national_rank)# 清空列表friend_list.clear()# 将数据添加到excel表格内worksheet.append([name, country, university, research_field1, research_field2, research_field3, now_research_field1,now_research_field2, now_research_field3, result, D_index, Citations, publication, world_rank, national_rank])# 保存workbook.save('world_data.csv')except:worksheet.append(['无数据', '无数据', '无数据', '无数据', '无数据', '无数据', '无数据', '无数据', '无数据', '无数据', '无数据', '无数据', '无数据', '无数据', '无数据'])# 保存workbook.save('world_data.csv')
这篇关于爬虫 | 【实践】Best Computer Science Scientists数据爬取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


