本文主要是介绍GCANet(Gated Context Aggregation Network for Image Dehazing and Deraining)图像去雾去雨,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
雾化处理可以由以下模型表示(corruption model):
![]()
I ( x ) :有雾的图片
J ( x ) :去雾的图片
A : 全球大气光
t ( x ) :中间的转换映射,取决于未知的深度信息,介质透射图
以往的去雾方法是用回归方法加上人为设计的先验条件来估计A或t(x),但问题是现实中这两项很难得到。该论文中使用的方式是直接学习原图和雾图之间的残差。
由于空洞卷积被广泛用于聚集上下文信息以提高其有效性而又不牺牲空间分辨率,因此我们也采用它来通过覆盖更多相邻像素来帮助获得更准确的恢复结果。 但是,原始的扩张卷积会产生所谓的“网格伪影”,因为当扩张率大于1时,输出中的相邻单元是根据输入中完全独立的集合计算出来的。因此以合成的方式分析了膨胀卷积,并提出使膨胀的卷积平滑,这可以大大减少这种网格化伪影。 因此,我们也将这种想法纳入了我们的上下文聚合网络。因为融合不同级别的功能通常对低级和高级任务都是有益的。所以,文章进一步提出了门控子网,以确定不同级别的重要性,并根据其相应的重要性权重对其进行融合。
模型
论文提出的encoder-decoder模型主要包含以下三个部分:
- auto-encoder,最后一层进行下采样
- 插入到encoder和decoder之间的Smooth Dilated Resblock
- 加入了Gated Fusion网络的decoder,与encoder对称地,第一层进行上采样
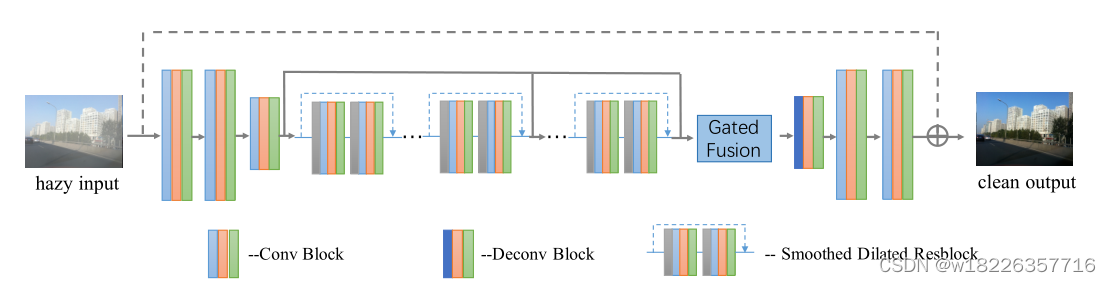
该模型由三个卷积块作为编码器部分,一个反卷积块和两个卷积块作为解码器部分组成。在它们之间插入几个平滑的空洞残差块来聚合上下文信息,而不会造成网格化假象。为了融合不同级别的功能,需要使用一个额外的门融合子网络。在运行时,GCANet将端到端预测目标干净图像与模糊输入图像之间的残差。
给定一个模糊的输入图像,我们首先通过编码器部分将其编码为特征图,然后通过聚合更多上下文信息并融合不同级别的特征而无需下采样来增强它们。 具体而言,利用了平滑的扩张卷积和额外的门子网。 最终将增强后的特征图解码回原始图像空间,以获取目标雾度残留物。 通过将其添加到输入的模糊图像上,我们将获得最终的无雾图像。
去雾的流程:
- 编码图片特征
- 加入context信息,融合不同层次的特征
- 解码特征映射,得到残差
- 将残差加到雾图上,得到去雾的图片
论文最重要的两个贡献:
- smooth dilated convolution,用于代替原始的dilated convolution,消除了gridding artifacts(网格伪影)
- gated fusion sub-network,用于融合不同层级的特征,对low-level任务和high-level任务都有好处
smooth dilated convolution(平滑的空洞卷积)
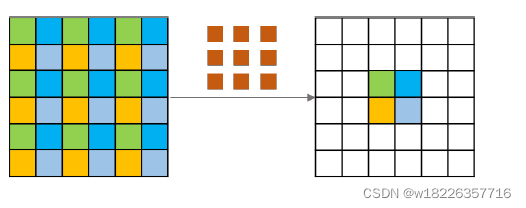
下一层的四个相邻像素,它们及其上一层中的从属单元分别用四种不同的颜色标记。 我们可以很容易地发现这四个邻居像素与上一层中完全不同的一组先前单元有关。 换句话说,在扩展的卷积中,输入单元或输出单元之间没有依赖性。 这就是为什么它将潜在地引起不一致的原因,即网格伪影。
剖析空洞卷积过程,可以看到卷积之后输出的四个相邻像素在上一层中依赖的像素之间是独立的(即相同颜色的像素之间不存在相邻等依赖关系)
因此在空洞卷积之前,增加一个核为(2r-1)的分离卷积的操作,同时卷积的参数由所有通道共享。可分离”是可分离的卷积思想,而“共享”是指所有通道均共享卷积权重,经过这些操作之后,每一个特征点都融合了周围(2r-1)大小的特征。(r = 膨胀率)
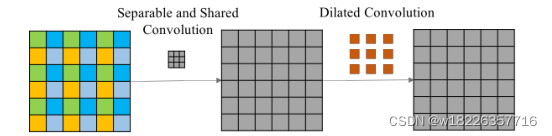
图中下一层的四个不同点用不同的颜色表示,可以看出它们与完全不同的单元集有关 ,我们知道,图像是具有局部相关性的,同理,特征层也应该保留这个特性,否则会导致网格化伪影。 相比之下,平滑的扩张卷积在扩张卷积之前在输入单元之间增加了额外的可分离和共享卷积层 。在卷积之前在输入单元之间或卷积之后在输出单元之间添加交互,同时所有通道均共享卷积权重。
gated fusion sub-network(门控融合子网)
学到了特征信息后,采用恰当的方式对其进行融合才能有效训练,论文的做法是,从高、中、低不同层次提取特征映射F l , F m , F h 输入gated fusion网络,根据学习的权重Ml,Mm,Mh将特征进行线性组合,将加权和送入decoder得到残差。
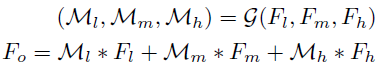
原文链接:https://blog.csdn.net/weixin_37625243/article/details/102874243
GCANet.py
import torch
import torch.nn as nn
import torch.nn.functional as F# SS convolution 分割和共享卷积(separate and shared convolution)
class ShareSepConv(nn.Module):def __init__(self, kernel_size):super(ShareSepConv, self).__init__()assert kernel_size % 2 == 1, 'kernel size should be odd' # assert条件为假时,报错(卷积核大小必须为奇数)self.padding = (kernel_size - 1)//2# 手动定义卷积核(weight),weight矩阵正中间的元素是1,其余为0weight_tensor = torch.zeros(1, 1, kernel_size, kernel_size)weight_tensor[0, 0, (kernel_size-1)//2, (kernel_size-1)//2] = 1# nn.Parameter:类型转换函数,将一个不可训练的类型Tensor转换成可以训练的类型parameter并将这个parameter绑定到module里self.weight = nn.Parameter(weight_tensor)self.kernel_size = kernel_sizedef forward(self, x):inc = x.size(1) # 获取输入图片的通道数# 根据Share and Separable convolution的定义,复制weights,x的每个通道对应相同的weight,contiguous()函数使得复制后并在内存空间上对齐# .expand自动将原来的张量所有长度为1的维度扩展成所需要的长度,将卷积核转换成(in_c) batch_sizeexpand_weight = self.weight.expand(inc, 1, self.kernel_size, self.kernel_size).contiguous()# 调用F.conv2d进行卷积操作# 可以这样理解:nn.Conv2d是[2D卷积层],而F.conv2d是[2D卷积操作]return F.conv2d(x, expand_weight,None, 1, self.padding, 1, inc) # group : inc# 改进的空洞卷积
class SmoothDilatedResidualBlock(nn.Module):def __init__(self, channel_num, dilation=1, group=1):super(SmoothDilatedResidualBlock, self).__init__()# 在空洞卷积之前先使用SS convolution进行局部信息融合self.pre_conv1 = ShareSepConv(dilation*2-1)# 空洞卷积self.conv1 = nn.Conv2d(channel_num, channel_num, 3, 1, padding=dilation, dilation=dilation, groups=group, bias=False) # output:(64,im_h/2, im_w/2)# 归一化层 num_features:来自期望输入的特征数 affine:布尔值,当设为true,给该层添加可学习的仿射变换参数self.norm1 = nn.InstanceNorm2d(channel_num, affine=True) # 归一化层self.pre_conv2 = ShareSepConv(dilation*2-1) # 在空洞卷积之前先使用SS convolution进行局部信息融合self.conv2 = nn.Conv2d(channel_num, channel_num, 3, 1, padding=dilation, dilation=dilation, groups=group, bias=False) # output:(64,im_h/2, im_w/2)self.norm2 = nn.InstanceNorm2d(channel_num, affine=True) # 归一化层def forward(self, x):# 残差连接y = F.relu(self.norm1(self.conv1(self.pre_conv1(x))))y = self.norm2(self.conv2(self.pre_conv2(y)))return F.relu(x+y)# 残差网络
# 基于这种使用直接映射来连接网络不同层直接的思想,残差网络应运而生
# 每两层增加一个捷径,构成一个残差块,此结构图有7个残差块
class ResidualBlock(nn.Module):def __init__(self, channel_num, dilation=1, group=1):super(ResidualBlock, self).__init__()self.conv1 = nn.Conv2d(channel_num, channel_num, 3, 1, padding=dilation, dilation=dilation, groups=group, bias=False)self.norm1 = nn.InstanceNorm2d(channel_num, affine=True) # 归一化层self.conv2 = nn.Conv2d(channel_num, channel_num, 3, 1, padding=dilation, dilation=dilation, groups=group, bias=False)self.norm2 = nn.InstanceNorm2d(channel_num, affine=True) # 归一化层def forward(self, x):y = F.relu(self.norm1(self.conv1(x)))y = self.norm2(self.conv2(y))return F.relu(x+y)class GCANet(nn.Module):def __init__(self, in_c=4, out_c=3, only_residual=True):super(GCANet, self).__init__()# Encoder:三层卷积,通道数64,卷积核大小3*3,stride=1,padding=1self.conv1 = nn.Conv2d(in_c, 64, 3, 1, 1, bias=False) # output:(64,im_h,im_w)self.norm1 = nn.InstanceNorm2d(64, affine=True) # Instance Normalizationself.conv2 = nn.Conv2d(64, 64, 3, 1, 1, bias=False) # output:(64,im_h,im_w)self.norm2 = nn.InstanceNorm2d(64, affine=True) # 归一化层self.conv3 = nn.Conv2d(64, 64, 3, 2, 1, bias=False) # stride=2的下采样 output:(64,im_h/2,im_w/2)self.norm3 = nn.InstanceNorm2d(64, affine=True) # 归一化层# 中间层:7层smooth dilated convolution残差块,空洞率r分别为2,2,2,4,4,4,1,通道数64self.res1 = SmoothDilatedResidualBlock(64, dilation=2) # output:(64,im_h/2, im_w/2)self.res2 = SmoothDilatedResidualBlock(64, dilation=2) # output:(64,im_h/2, im_w/2)self.res3 = SmoothDilatedResidualBlock(64, dilation=2) # output:(64,im_h/2, im_w/2)self.res4 = SmoothDilatedResidualBlock(64, dilation=4) # output:(64,im_h/2, im_w/2)self.res5 = SmoothDilatedResidualBlock(64, dilation=4) # output:(64,im_h/2, im_w/2)self.res6 = SmoothDilatedResidualBlock(64, dilation=4) # output:(64,im_h/2, im_w/2)# 空洞率为1时分离卷积的卷积核为1*1,没有起到信息融合的作用,因此该层退化为一个普通的残差网络self.res7 = ResidualBlock(64, dilation=1) # output:(64,im_h/2, im_w/2)# Gated Fusion Sub-network:学习低,中,高层特征的权重self.gate = nn.Conv2d(64 * 3, 3, 3, 1, 1, bias=True) # output:(3,im_h/2, im_w/2)# Decoder:1层反卷积层将feature map上采样到原分辨率 + 2层卷积层将feature map还原到原图空间self.deconv3 = nn.ConvTranspose2d(64, 64, 4, 2, 1) # stride=2的上采样 output: (64, im_h, im_w)self.norm4 = nn.InstanceNorm2d(64, affine=True) # 归一化层self.deconv2 = nn.Conv2d(64, 64, 3, 1, 1) # output: (64, im_h, im_w)self.norm5 = nn.InstanceNorm2d(64, affine=True) # 归一化层self.deconv1 = nn.Conv2d(64, out_c, 1) # 1*1卷积核进行降维 output: (out_c, im_h, im_w)self.only_residual = only_residualdef forward(self, x):# Encoder前向传播,使用relu激活y = F.relu(self.norm1(self.conv1(x))) # output:(64,im_h,im_w)y = F.relu(self.norm2(self.conv2(y))) # output:(64,im_h,im_w)y1 = F.relu(self.norm3(self.conv3(y))) # 低层级信息 output:(64,im_h/2,im_w/2)# 中间层y = self.res1(y1) # output:(64,im_h/2,im_w/2)y = self.res2(y) # output:(64,im_h/2,im_w/2)y = self.res3(y) # output:(64,im_h/2,im_w/2)y2 = self.res4(y) # 中层级信息 output:(64,im_h/2,im_w/2)y = self.res5(y2) # output:(64,im_h/2,im_w/2)y = self.res6(y) # output:(64,im_h/2,im_w/2)y3 = self.res7(y) # 高层级信息 output:(64,im_h/2, im_w/2)# Gated Fusion Sub-network (门控聚合子网络)gates = self.gate(torch.cat((y1, y2, y3), dim=1)) # 计算低,中,高层特征的权重 output: (64*3, im_h/2, im_w/2) --> output: (3, im_h/2, im_w/2)gated_y = y1 * gates[:, [0], :, :] + y2 * gates[:, [1], :, :] + y3 * gates[:, [2], :, :] # 对低,中,高层特征加权求和 output: (64, im_h/2, im_w/2)y = F.relu(self.norm4(self.deconv3(gated_y))) # output: (64, im_h, im_w)y = F.relu(self.norm5(self.deconv2(y))) # output: (64, im_h, im_w)if self.only_residual: # 去雾y = self.deconv1(y) # output: (out_c, im_h, im_w)else: # 去雨y = F.relu(self.deconv1(y))return y
test.py
import os
import argparse
import numpy as np
from PIL import Imageimport torch
from torch.autograd import Variablefrom utils import make_dataset, edge_compute# argpars是一个python模块:命令行解释、参数、和子命令解释器
parser = argparse.ArgumentParser()
parser.add_argument('--network', default='GCANet')
parser.add_argument('--task', default='dehaze', help='dehaze | derain')
parser.add_argument('--gpu_id', type=int, default=-1)
parser.add_argument('--indir', default='examples/')
parser.add_argument('--outdir', default='output')
opt = parser.parse_args()assert opt.task in ['dehaze', 'derain']## forget to regress the residue for deraining by mistake,
## which should be able to produce better resultsopt.only_residual = opt.task == 'dehaze'
# 加载模型,指定输入输出路径
opt.model = 'models/wacv_gcanet_%s.pth' % opt.task
opt.use_cuda = opt.gpu_id >= 0
if not os.path.exists(opt.outdir):os.makedirs(opt.outdir)
test_img_paths = make_dataset(opt.indir) # utils.py# 初始化模型
if opt.network == 'GCANet':from GCANet import GCANet# 输入通道:4(包括边缘信息);输出通道:3(RGB)net = GCANet(in_c=4, out_c=3, only_residual=opt.only_residual)
else:print('network structure %s not supported' % opt.network)raise ValueError# GPU or CPU
if opt.use_cuda:torch.cuda.set_device(opt.gpu_id)net.cuda()
else:net.float() # 将模型数据类型转换为float# 加载参数,map_location表示函数、torch.device或者字典指明如何重新映射存储位置
# 将预训练的参数权重加载到新的模型之中
net.load_state_dict(torch.load(opt.model, map_location='cpu'))
# 不启用 BatchNormalization 和 Dropout,保证BN和dropout不发生变化,
net.eval()# 处理输入
for img_path in test_img_paths:img = Image.open(img_path).convert('RGB') # 如果不使用.convert(‘RGB’)进行转换的话,读出来的图像是RGBA四通道的,A通道为透明通道im_w, im_h = img.sizeif im_w % 4 != 0 or im_h % 4 != 0: # ??????????????img = img.resize((int(im_w // 4 * 4), int(im_h // 4 * 4))) # 将图像的高和宽转换为4的整数倍img = np.array(img).astype('float') # 将img的高宽转换为数组的类型img_data = torch.from_numpy(img.transpose((2, 0, 1))).float() # (坐标x,坐标y,通道)->(通道,坐标x,坐标y),并转换为tensor类型edge_data = edge_compute(img_data) # 计算边缘信息# 数据中心化 [0,255]->[-128,127],torch.cat是将两个张量(tensor)拼接在一起,dim = 0,表示按维度拼接,等于1按列拼接# unsqueeze()的作用是用来增加给定tensor的维度的,unsqueeze(dim)就是在维度序号为dim的地方给tensor增加一维in_data = torch.cat((img_data, edge_data), dim=0).unsqueeze(0) - 128# GPU OR CPUin_data = in_data.cuda() if opt.use_cuda else in_data.float()with torch.no_grad():pred = net(Variable(in_data))# round:四舍五入 clamp:大于或小于阈值时被截断(input, min, max, out=None)if opt.only_residual: # 去雾图像=原图+预测值(残差)out_img_data = (pred.data[0].cpu().float() + img_data).round().clamp(0, 255)else: # 去雨图像=预测值out_img_data = pred.data[0].cpu().float().round().clamp(0, 255)# 保存图片out_img = Image.fromarray(out_img_data.numpy().astype(np.uint8).transpose(1, 2, 0)) # array数组类型转换成image格式out_img.save(os.path.join(opt.outdir, os.path.splitext(os.path.basename(img_path))[0] + '_%s.png' % opt.task))utils.py
import os
import torchIMG_EXTENSIONS = ['.jpg', '.JPG', '.jpeg', '.JPEG','.png', '.PNG', '.ppm', '.PPM', '.bmp', '.BMP',
]
# 在Python中有两个函数分别是startswith()函数与endswith()函数,功能都十分相似,
# startswith()函数判断文本是否以某个字符开始,endswith()函数判断文本是否以某个字符结束。其返回值为布尔型,为真时返回True,否则返回False。
def is_image_file(filename):return any(filename.endswith(extension) for extension in IMG_EXTENSIONS)def make_dataset(dir): # 将预处理有雾图像存到数组中images = []assert os.path.isdir(dir), '%s is not a valid directory' % dir # 判断是否是目录for root, _, fnames in sorted(os.walk(dir)): # 返回的是所有(子)文件夹的三元组(root, dirs, files)for fname in fnames:if is_image_file(fname):path = os.path.join(root, fname)images.append(path)return images# 计算图像的边缘信息
def edge_compute(x): # 原因 ??????# 将参数传递到 torch.abs 后返回输入参数的绝对值作为输出,输入参数必须是一个 Tensor 数据类型的变量。x_diffx = torch.abs(x[:,:,1:] - x[:,:,:-1])x_diffy = torch.abs(x[:,1:,:] - x[:,:-1,:])y = x.new(x.size())y.fill_(0)y[:,:,1:] += x_diffxy[:,:,:-1] += x_diffxy[:,1:,:] += x_diffyy[:,:-1,:] += x_diffyy = torch.sum(y,0,keepdim=True)/3y /= 4return ytrain.py
import os
import datetime
import argparse
import numpy as npimport torch
import torch.optim as optim
from torch.autograd import Variable
from torch.utils.data import DataLoaderfrom ImagePairPrefixFolder import ImagePairPrefixFolder, var_custom_collate
from utils import MovingAvg
from tf_visualizer import TFVisualizerparser = argparse.ArgumentParser()
parser.add_argument('--network', default='GCANet') # 网络结构
parser.add_argument('--name', default='default_exp')
parser.add_argument('--gpu_ids', default='-1') # 调用GPU
parser.add_argument('--epochs', type=int, default=1) # 训练轮数 parser.add_argument('--lr', type=float, default=0.001) # 学习率
parser.add_argument('--lr', type=float, default=0.001) # 学习率
parser.add_argument('--lr_step', type=int, default=40) # 间隔调整学习率
parser.add_argument('--lr_gamma', type=float, default=0.1) # 学习率调整为 lr*gamma
parser.add_argument('--weight_decay', type=float, default=0.0005) # 权重衰减,终目的是防止过拟合
parser.add_argument('--checkpoints_dir', default='checkpoint')
parser.add_argument('--logDir', default='tblogdir')
parser.add_argument('--resume_dir', default='')
parser.add_argument('--resume_epoch', type=int, default=0)
parser.add_argument('--save_epoch', type=int, default=5)
parser.add_argument('--save_latest_freq', type=int, default=5000)
parser.add_argument('--test_epoch', type=int, default=5)
parser.add_argument('--test_max_size', type=int, default=1080)
parser.add_argument('--size_unit', type=int, default=8)
parser.add_argument('--print_iter', type=int, default=100)
parser.add_argument('--input_folder', default='dataset/hazy')
parser.add_argument('--gt_folder', default='dataset/gt')
parser.add_argument('--test_input_folder', default='test_dataset/synthetic')
parser.add_argument('--test_gt_folder', default='test_dataset/original')
parser.add_argument('--num_workers', type=int, default=0)
parser.add_argument('--batch_size', type=int, default=4)
parser.add_argument('--only_residual', action='store_true', help='regress residual rather than image')
parser.add_argument('--loss_func', default='l2', help='l2|l1')
parser.add_argument('--inc', type=int, default=3)
parser.add_argument('--outc', type=int, default=3)
parser.add_argument('--force_rgb', action='store_true') # 命令行遇到参数时的动作,默认值是 store。
parser.add_argument('--no_edge', action='store_true')opt = parser.parse_args()# 获取路径
# expanduser函数,它可以将参数中开头部分的 ~ 或 ~user 替换为当前用户的home目录并返回(绝对路径)
opt.input_folder = os.path.expanduser(opt.input_folder)
# print(opt.input_folder)
opt.gt_folder = os.path.expanduser(opt.gt_folder)
opt.test_input_folder = os.path.expanduser(opt.test_input_folder)
opt.test_gt_folder = os.path.expanduser(opt.test_gt_folder)if not os.path.exists(os.path.join(opt.checkpoints_dir, opt.name)):os.makedirs(os.path.join(opt.checkpoints_dir, opt.name)) # 创建文件
opt.resume_dir = opt.resume_dir if opt.resume_dir != '' else os.path.join(opt.checkpoints_dir, opt.name)visualizer = TFVisualizer(opt)
### Log out# with open(os.path.realpath(__file__), 'r', encoding='UTF-8') as fid: # 获取当前执行的.py文件的绝对路径
# visualizer.print_logs(fid.read())# print argument
# 输出opt的属性的参数的值
# print(vars(opt).items())
# for key, val in vars(opt).items(): # vars() 函数返回对象opt的属性和属性值的字典对象
# visualizer.print_logs('%s: %s' % (key, val))# opt.gpu_ids = [int(x) for x in opt.gpu_ids.split(',')]
# assert all(0 <= x <= torch.cuda.device_count() for x in opt.gpu_ids), 'gpu id should ' \
# 'be 0~{0}'.format(torch.cuda.device_count())
# torch.cuda.set_device(opt.gpu_ids[0])# 训练集图片的装载
train_dataset = ImagePairPrefixFolder(opt.input_folder, opt.gt_folder, size_unit=opt.size_unit, force_rgb=opt.force_rgb)
train_dataloader = DataLoader(train_dataset, batch_size=opt.batch_size, shuffle=True,collate_fn=var_custom_collate, pin_memory=False,num_workers=opt.num_workers)opt.do_test = opt.test_gt_folder != ''
# 测试集图片的装载
if opt.do_test:test_dataset = ImagePairPrefixFolder(opt.test_input_folder, opt.test_gt_folder,max_img_size=opt.test_max_size, size_unit=opt.size_unit, force_rgb=opt.force_rgb)test_dataloader = DataLoader(test_dataset, batch_size=1, shuffle=False,collate_fn=var_custom_collate, pin_memory=False,num_workers=0)total_inc = opt.inc if opt.no_edge else opt.inc + 1 # 判断是否有训练图片的边缘信息
if opt.network == 'GCANet':from GCANet import GCANetnet = GCANet(in_c=total_inc, out_c=3, only_residual=opt.only_residual)
else:print('network structure %s not supported' % opt.network)raise ValueError# 损失函数的定义(去雾、去雨)
if opt.loss_func == 'l2': # (去雾的损失函数)loss_crit = torch.nn.MSELoss()
elif opt.loss_func == 'l1': # (去雨训练的损失函数)loss_crit = torch.nn.SmoothL1Loss() # 损失函数
else:print('loss_func %s not supported' % opt.loss_func)raise ValueError
pnsr_crit = torch.nn.MSELoss() # 计算峰值信噪比的误差# if len(opt.gpu_ids) > 0:
# net.cuda() # 单GPU计算
# if len(opt.gpu_ids) > 1:
# net = torch.nn.DataParallel(net) # 多GPU进行并行计算
# loss_crit = loss_crit.cuda()
# pnsr_crit = pnsr_crit.cuda()optimizer = torch.optim.Adam(net.parameters(), lr=opt.lr)
step_optim_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=opt.lr_step, gamma=opt.lr_gamma) # 调整学习率机制
loss_avg = MovingAvg(pool_size=50) # 定义一个大小为pool_size队列start_epoch = 0
total_iter = 0# 模型的加载保存与加载
if os.path.exists(os.path.join(opt.checkpoints_dir, opt.name, 'latest.pth')):print('resuming from latest.pth')latest_info = torch.load(os.path.join(opt.checkpoints_dir, opt.name, 'latest.pth'))start_epoch = latest_info['epoch']total_iter = latest_info['total_iter']# 判断是否为多GPU训练模型# if isinstance(net, torch.nn.DataParallel): # isinstance() 函数来判断一个对象是否是一个已知的类型# net.module.load_state_dict(latest_info['net_state']) # 是深拷贝# else:net.load_state_dict(latest_info['net_state']) # 实际上是浅拷贝optimizer.load_state_dict(latest_info['optim_state'])if opt.resume_epoch > 0:start_epoch = opt.resume_epochtotal_iter = opt.resume_epoch * len(train_dataloader)resume_path = os.path.join(opt.resume_epoch, 'net_epoch_%d.pth') % opt.resume_epochprint('resume from : %s' % resume_path)assert os.path.exists(resume_path), 'cannot find the resume model: %s ' % resume_path# if isinstance(net, torch.nn.DataParallel):# net.module.load_state_dict(torch.load(resume_path))# else:net.load_state_dict(torch.load(resume_path))
if __name__ == '__main__':for epoch in range(start_epoch, opt.epochs):visualizer.print_logs("Start to train epoch %d" % epoch)net.train() # 在训练模型时会在前面加上for iter, data in enumerate(train_dataloader):total_iter += 1optimizer.zero_grad()step_optim_scheduler.step(epoch)batch_input_img, batch_input_edge, batch_gt = data# if len(opt.gpu_ids) > 0:# batch_input_img, batch_input_edge, batch_gt = batch_input_img.cuda(), batch_input_edge.cuda(), batch_gt.cuda()if opt.no_edge:batch_input = batch_input_imgelse:batch_input = torch.cat((batch_input_img, batch_input_edge), dim=1)batch_input_v = Variable(batch_input)if opt.only_residual:batch_gt_v = Variable(batch_gt - (batch_input_img+128))else:batch_gt_v = Variable(batch_gt)pred = net(batch_input_v)loss = loss_crit(pred, batch_gt_v)avg_loss = loss_avg.set_curr_val(loss.data)loss.backward()optimizer.step()if iter % opt.print_iter == 0:visualizer.plot_current_losses(total_iter, { 'loss': loss}) # 可视化visualizer.print_logs('%s Step[%d/%d], lr: %f, mv_avg_loss: %f, loss: %f' %(str(datetime.datetime.now()).split(' ')[1], iter, len(train_dataloader),step_optim_scheduler.get_lr()[0], avg_loss, loss))if total_iter % opt.save_latest_freq == 0:latest_info = {'total_iter': total_iter,'epoch': epoch,'optim_state': optimizer.state_dict()}# if len(opt.gpu_ids) > 1:# latest_info['net_state'] = net.module.state_dict()# else:latest_info['net_state'] = net.state_dict()print('save lastest model.')torch.save(latest_info, os.path.join(opt.checkpoints_dir, opt.name, 'latest.pth'))if (epoch+1) % opt.save_epoch == 0 :visualizer.print_logs('saving model for epoch %d' % epoch)# if len(opt.gpu_ids) > 1:# torch.save(net.module.state_dict(), os.path.join(opt.checkpoints_dir, opt.name, 'net_epoch_%d.pth' % (epoch+1)))# else:torch.save(net.state_dict(), os.path.join(opt.checkpoints_dir, opt.name, 'net_epoch_%d.pth' % (epoch + 1)))if opt.do_test:avg_psnr = 0task_cnt = 0net.eval()with torch.no_grad():for iter, data in enumerate(test_dataloader):batch_input_img, batch_input_edge, batch_gt = data# if len(opt.gpu_ids) > 0:# batch_input_img, batch_input_edge, batch_gt = batch_input_img.cuda(), batch_input_edge.cuda(), batch_gt.cuda()if opt.no_edge:batch_input = batch_input_imgelse:batch_input = torch.cat((batch_input_img, batch_input_edge), dim=1)batch_input_v = Variable(batch_input)batch_gt_v = Variable(batch_gt)pred = net(batch_input_v)if opt.only_residual:loss = pnsr_crit(pred+Variable(batch_input_img+128), batch_gt_v)else:loss = pnsr_crit(pred, batch_gt_v)avg_psnr += 10 * np.log10(255 * 255 / loss.item())task_cnt += 1visualizer.print_logs('Testing for epoch: %d' % epoch)visualizer.print_logs('Average test PNSR is %f for %d images' % (avg_psnr/task_cnt, task_cnt))这篇关于GCANet(Gated Context Aggregation Network for Image Dehazing and Deraining)图像去雾去雨的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







