本文主要是介绍FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding个人见解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding个人理解
- 简介
- 总结的创新点
- 为什么要提出FSCE(背景)
- Strong baseline
- Contrastive object proposal encoding
- Contrastive Proposal Encoding (CPE) Loss
- Proposal consistency control
- Training objectives
- Experiments
- Ablation
- Components of our proposed FSCE.
- Conclusion

简介
小样本目标检测,是最近几年逐渐火热的一个目标检测的领域,现在的通用目标检测领域,发展非常快,也非常卷,比如,yolo系列已经出到了v8,也出现了DETR这种具有基于tramsformer的目标检测,能够不再需要NMS,同时达到比较好的效果,最近也是提出了RT-DETR,号称是击败了YOLO。可以说是百花齐放,而小样本目标检测领域,目标是在非常稀少样本的情况下,实现对一张图片中出现的物体的分类和定位,这对于需要依赖大量样本来train的深度网络来说,难度还是非常大的。今天要讲解一篇小样本目标检测的论文,FSCE,其是基于微调范式的小样本目标检测,它是继TFA之后第一次将对比学习运用到小样本目标检测领域,发布于在CVPR2021上,其历史意义还是比较重大的!
总结的创新点
1.基于TFA作为baseline,对其进行修改,提出了更强的Strong baseline
2.提出使用对比学习,使用CPE Loss来计算对比损失
3.提出区域一致性控制,保证proposal 的质量
为什么要提出FSCE(背景)
We notice the degradation of average precision (AP) for rare objects mainly comes from misclassifying novel instances as confusable classes.
However, based on our experiments with Faster R-CNN [4], the commonly adopted detector in few-shot detection, class-agonistic region proposal network (RPN) is able to make foreground proposals for novel instances, and the final box regressor can localize novel instances quite accurately. In comparison, as demonstrated in Figure 2, misclassifying detected novel instances as confusable base classes is indeed the main source of error.
就是作者发现人们可能会觉得定位可能对于对非常少样本的情况下,难度是非常大,然而作者实验证明并不是如此,反而是分类是造成小样本目标检测精度不高的主要原因,如图1
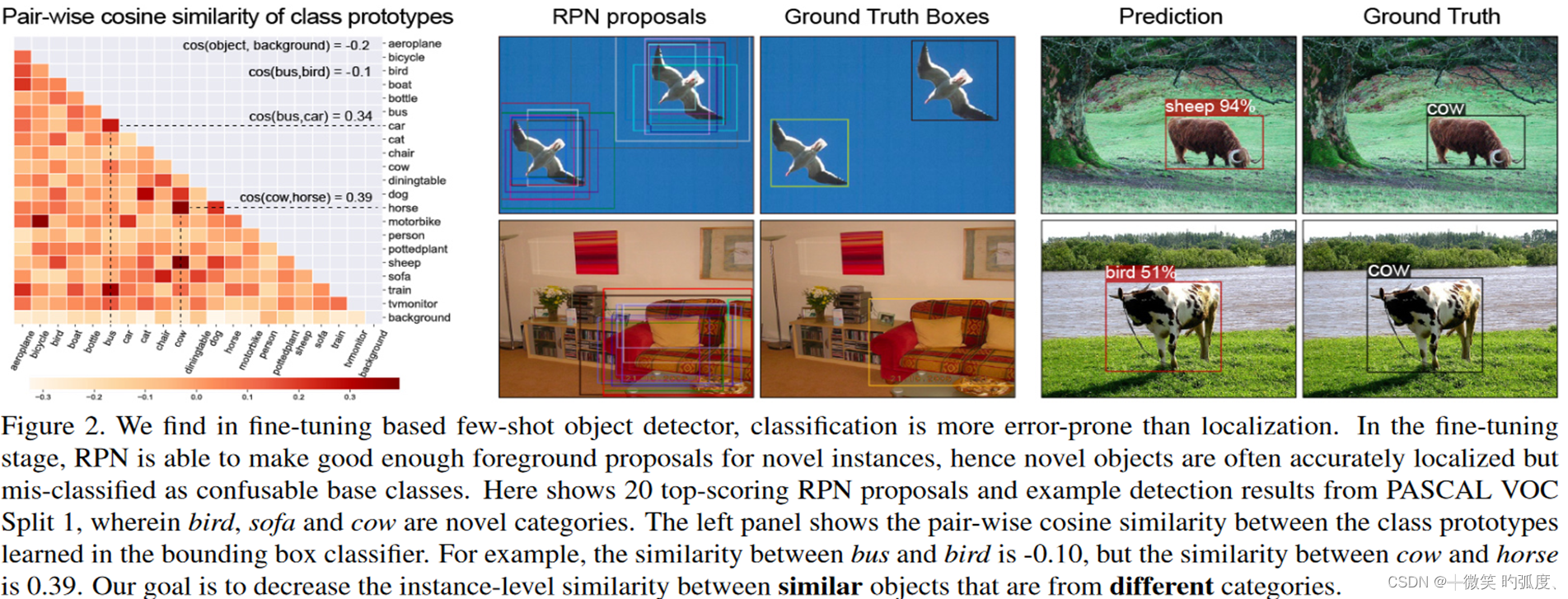
可以看到确实在这幅图中,a)是在voc数据集上各个类的类原型的相似度,就是想展示一下哪几个类比较相似,比如说cos(cow,horse)=0.39,高达0.39,可以说是比较相似了,所以模型可能就比较在小样本设定下,比较难分出了,而物体与背景的相似度=-0.2,还是比较好分辨。
b)可以看到对海鸥的定位还是比较准,多个框还是把其包含了进去。
c)图c就主要展示的是分类效果,可以发现模型把牛分成🐏。
第二点呢就是作者发现,其实不同IOU得分的object proposal(我理解就是对一个物体生成的多个region proposal)就类似于对比视觉表征学习使用的图片内增强(其实就是类似于一张图片的图片裁剪),即下面这段话。
We observe object proposals with different Intersection-ofUnion (IoU) scores are analogous to the intra-image augmentation used in contrastive visual representation learning. And we exploit this analogy and incorporate supervised contrastive learning to achieve more robust objects representations in FSOD.
于是呢,作者就提出了用有监督的对比学习来解决这些问题,提出了本文的FSCE方法。

达到这种效果,将来自同一类别的region proposal进行拉近,对于来自不同类别的就让它们远离。
Strong baseline
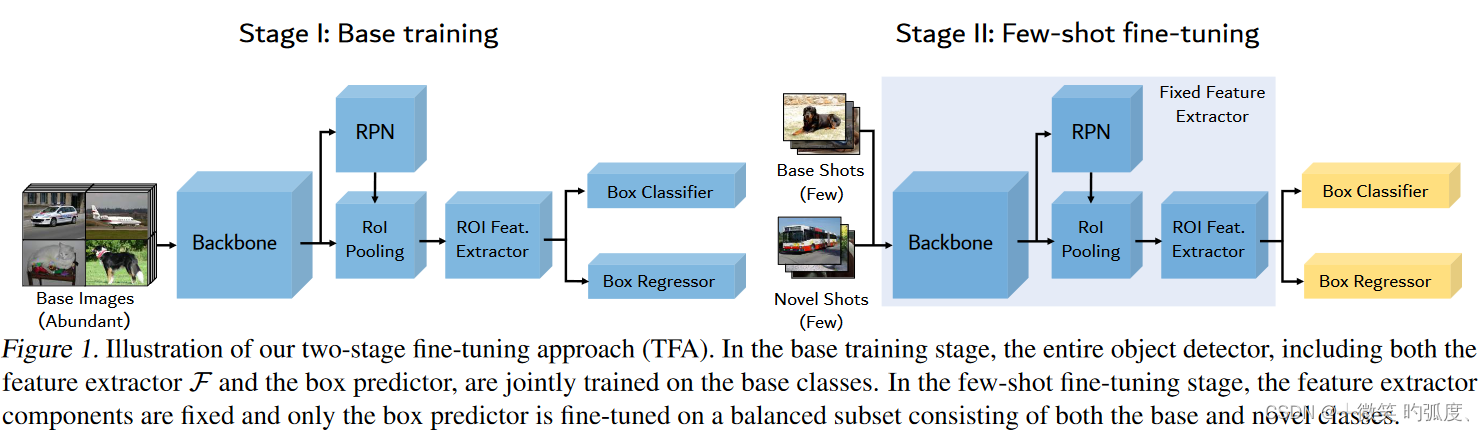
这是TFA的整体框架图,为什么要展示TFA的框架图呢,其实本文是把前一篇基于微调范式的方法TFA进行对比,需要先了解TFA,TFA是第一篇基于微调范式的小样本目标检测超过元学习范式的方法。TFA的方式也很简单,就是认为在训练阶段,在大量基类上训练完后,在后面的微调阶段,固定住backbone和RPN的各部分,只需用少量的新类和基类数据来更新预测头部分的权重即可,最终即可得到比较好的泛化性能。也确实是在当时,超过了一众基于元学习方法。而如果不固定RPN和ROI特征提取器,性能会大幅度下降。
而本文呢,发现如果训练合适的话(使用其他tricks),就是避免性能衰退,并且就能达到比较好的效果。所以对原来的baseline(即TFA)进行了两点修改。作者做实验发现了两点问题如图:
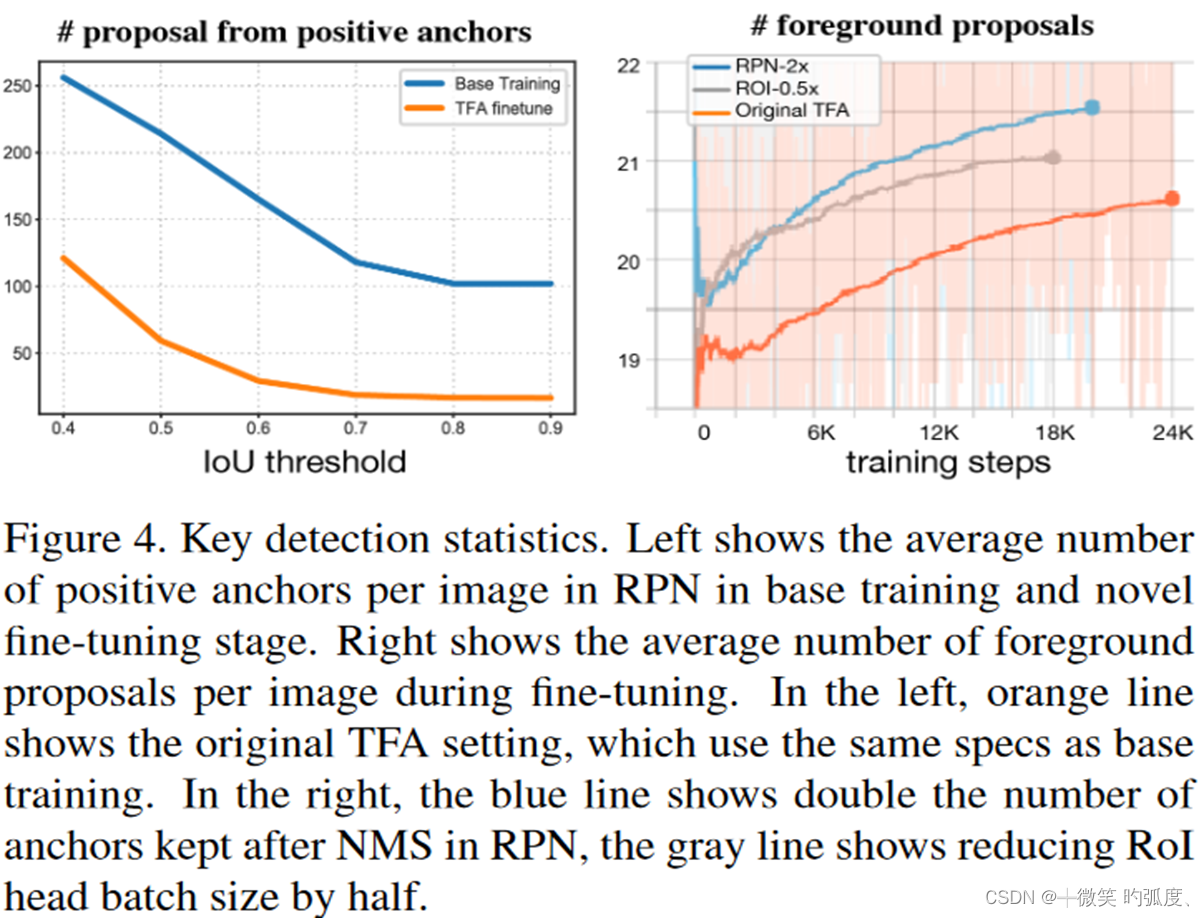
从左图可以看到,相对于基类训练时,TFA微调阶段,每张图片的正anchors的平均数量是少很多的,这就会导致得到的正例,就会少很多,从而导致RPN不能学到很好的提出正样本特征,也导致正样本大量减少,模型性能下降,也是为什么TFA要在微调阶段要冻住RPN网络,同时在微调阶段时,来自新类的正anchors的objectness scores非常低,导致这些低objectness scores无法通过NMS,最终无法提供给ROI来学习特征。
We observe, especially at the beginning of fine-tuning, the positive anchors for novel objects receive comparatively low scores from RPN. Due to the low objectness scores, less positive anchors can pass non-max suppression (NMS) and become proposals that provide actual learning opportunities in RoI head for novel objects.
针对这两点问题,作者进行了两点修改,
1.加倍经过NMS处理过后的最大proposal的数量
2.减半在ROI head中用于计算loss的采样过的proposal的数量(这是因为一般一张图片前景proposal的数量,不到其一半)
也即就是图二的右图,可以看到在固定train steps的话,修改后的strong baseline ,能产生更多的foreground proposals。
(1) double the maximum number of proposals kept after NMS, this brings more foreground proposals for novel instances, and (2) halving the number of sampled proposals in RoI head used for loss computation, as in fine-tuning stage the discarded half contains only backgrounds (standard RoI batch size is 512, and the number of foreground proposals are far less than half of it)
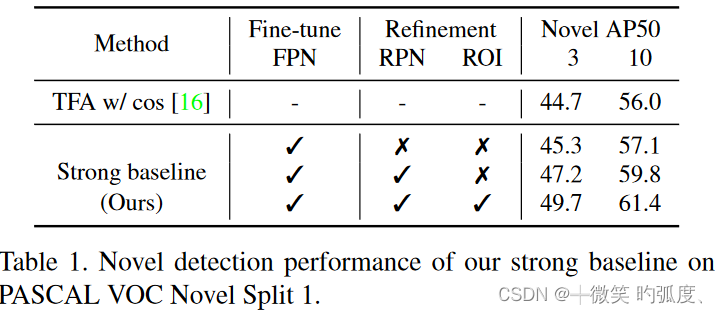
这个实验也证明了在使用这两个tricks后,Strong baseline性能不减反增,达到了比较出色的表现。
Contrastive object proposal encoding
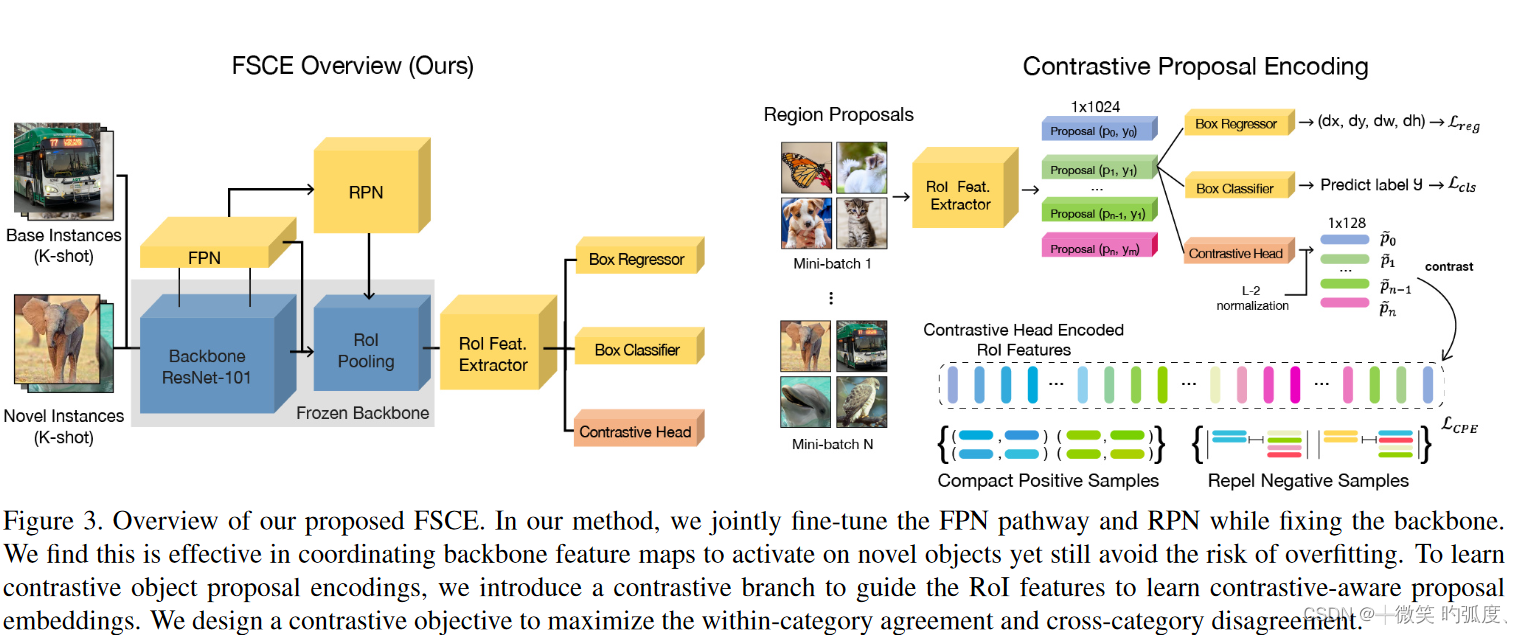
这是FSCE的整体框架图,除了对baseline的两点改进,最大的亮点还是在加入了Contrastive Head模块,使用对比表征学习,来更好的学习。
在Faster R-CNN中,ROI 特征提取器首先池化 region proposals 为固定的大小,然后把它们编码成1x1024维的ROI 特征,然后分别进入到三个检测头部分,来进行分类和定位。并且为了引入本文的对比特征学习,本文引入了一个对比分支检测头。由于得到的ROI feature vector x经过post-ReLU激活函数,部分被截断为0,所以不能直接使用相似度。于是在对比分支加了一个MLP来再编码一下来自ROI feature 为1x128维的特征,然后再进行计算相似度,就是下面这个公式:
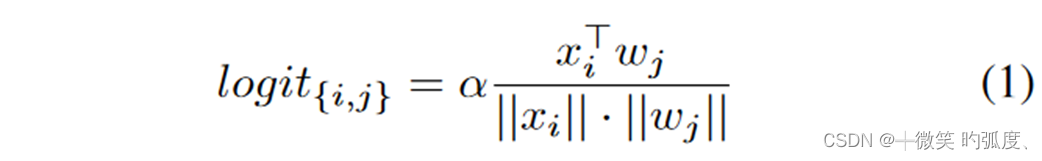
xi是ROI feature,wj是的类权重,α是放大梯度的比例因子。来预测第i个物体属于第j个类的在超球体上的缩放余弦相似度。
其对比分支就是用来引导ROI head 来学习对比物体候选框嵌入,来帮助找到不同类别之间的区别特征,增加模型在小样本设置下的通用能力。
Contrastive Proposal Encoding (CPE) Loss
本节就主要介绍对比学习损失函数CPE loss.
具体地,对于一小批N个RoI盒特征{zi,ui,yi}iN=1,其中zi是第i个区域建议的对比头部编码的RoI特征,ui表示其与匹配的地面实况边界盒的交集联合(IOU)分数,yi表示地面实况的标签
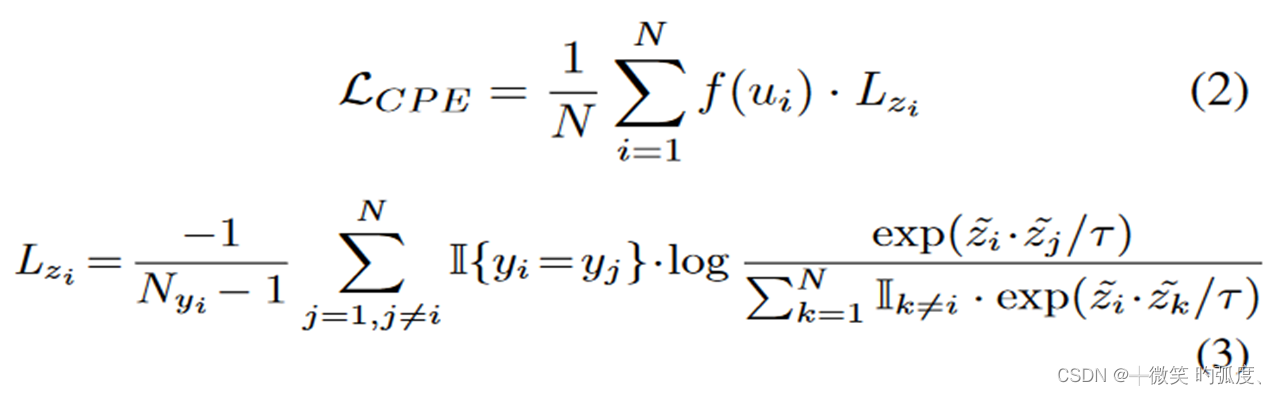
Nyi是与yi具有相同标签的提案数量,τ是InfoNCE[48]中的超参数温度。这个公式感觉有点类似于我看过的MOCOv2的公式,使得3式分子增大,中间的指示函数是选取同一类别,同一类别的相似度增大,而分母代表的是第i个ROI特征与其余所有特征的相似度之和,使得分母尽量小,即与所有其他特征尽量小(我理解就是与其他特征区分开来,让第i个特征有区分度),前面那部分应该就是归一化什么的了。分析完3式,2式也就剩下个f函数。其实也即是用来Proposal consistency control。
Proposal consistency control
We propose to use an IoU threshold to assure the consistency of proposals that are used to be contrasted, with the consideration that low IoU proposals deviate too much from the center of regressed objects, therefore might contain irrelevant semantics.
我们建议使用IoU阈值来确保用于对比的建议的一致性,同时考虑到低IoU建议与回归对象的中心偏离太多,因此可能包含不相关的语义。就是尽量选取生成比较好的region proposal,其背景特征比较少,对模型的干扰比较少。
用建议一致性阈值φ和重新加权函数g(·)定义
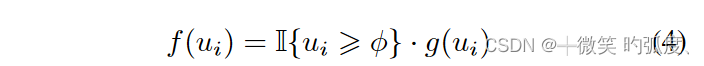
g(·)为具有不同IoU得分水平的对象提案分配不同的权重系数。
Training objectives
最终的loss:
在第一阶段中,用标准的更快R-CNN损失[4]、二进制交叉熵损失Lrpn来训练基本检测器,以从锚中提出前景建议,交叉熵损失Lcls用于边界框分类器,平滑L1损失Lreg用于框回归增量。当在微调阶段转移到新数据时,我们发现对比损失可以以多任务的方式添加到主要的Faster RCNN损失中,而不会破坏训练的稳定性.λ设置为0.5以平衡损失的规模。
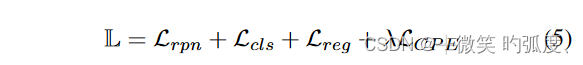
在第一阶段,基本与Faster RCNN一致,微调阶段就加入了本文提出的CPE Loss。
Experiments
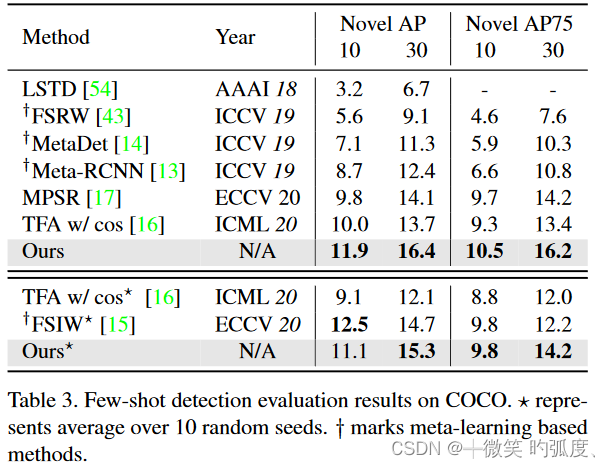
在COCO上跑出的效果,还是不错的,相对baseline确实有1,2个点的提高。
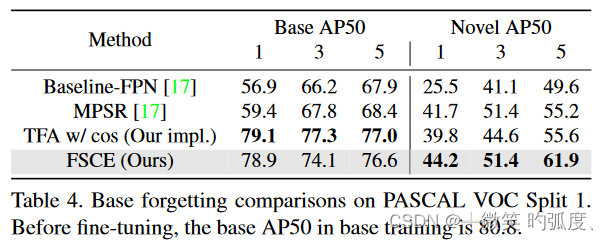
我们提出的方法比当前的SOTA增益+1.7nAP和+2.7nAP75
Ablation
Components of our proposed FSCE.
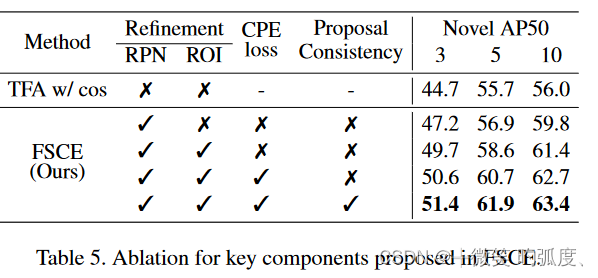
这是各个创新点的消融实验。
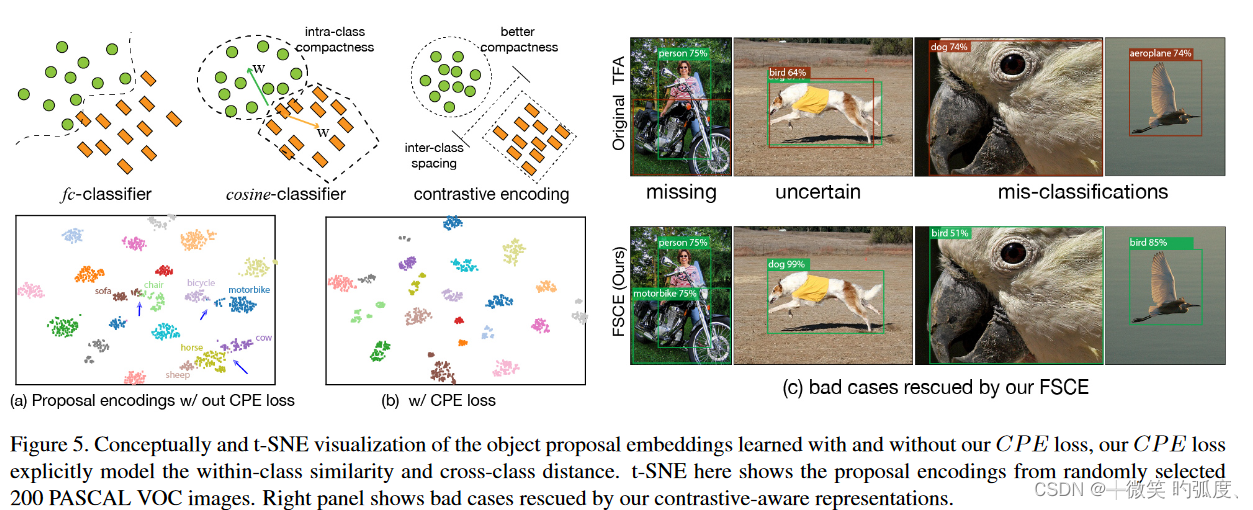
图5显示了我们建议的FSCE的目视检查。我们发现,在数据丰富的一般检测中,fc分类器和余弦分类器的饱和性能基本相等。fc层可以从足够的数据中学习复杂的决策边界。现有文献和我们都证实,余弦盒分类器在少镜头目标检测方面表现出色,这可以归因于显式建模的相似性有助于在投影的单位超球面上形成更紧密的实例簇。
Conclusion
我们提出了一种通过对比建议编码来解决FSOD的新视角。有效地避免了精确定位的对象被错误分类,我们的方法在任何镜头和两个基准中都取得了最先进的结果。我们提出的对比方案编码头的成本可以忽略不计,并且通常是适用的。它可以集成到任何两级探测器中,而不会干扰训练管道。
总的来说,这篇论文还是很好的,第一次将对比学习运用到了小样本目标检测,意义还是比较大的!!
这篇关于FSCE: Few-Shot Object Detection via Contrastive Proposal Encoding个人见解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







