本文主要是介绍西安交大转子数据集故障诊断(Python代码,MSCNN结合LSTM结合注意力机制模型),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.运行效果:西安交大转子数据集故障诊断(Python代码,MSCNN结合LSTM结合注意力机制模型)_哔哩哔哩_bilibili
2.环境库版本
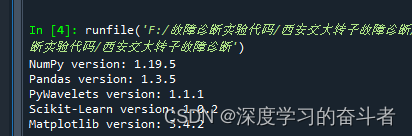
如果库版本不一样, 一般也可以运行,这里展示我运行时候的库版本,是为了防止你万一在你的电脑上面运行不了,可以按照我的库版本进行安装并运行
3.数据集介绍
该实验平台由交流电动机、电动机转速控制器、转轴、支撑轴承、液压加载系统和测试轴承等组成,试验平台可调节的工况主要包括径向力和转速,其中径向力由液压加载系统产生,作用于测试轴承的轴承座上,转速由交流电机的转速控制器来设置与调节。

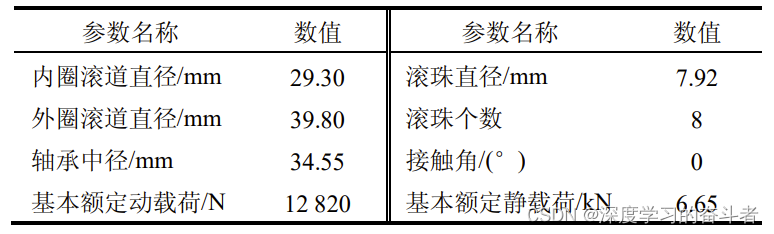

两个 PCB 352C33 单向加速度传感器分别通过磁座固定于测试轴承的水平和竖直方向上。试验中使用 DT9837 便携式动态信号采集器采集振动信号。试验中设置采样频率为 25.6 kHz,采样间隔为 1 min,每次采样时长为 1.28 s。
在每一次采样中,将获取的振动信号存放在一个 csv 文件内。其中,第一列为水平方向的振动信号,第二列为竖直方向的振动信号。各个 csv 文件按采样时间先后顺序命名,即 1.csv,2.csv,…, N.csv,其中 N 为采样总次数。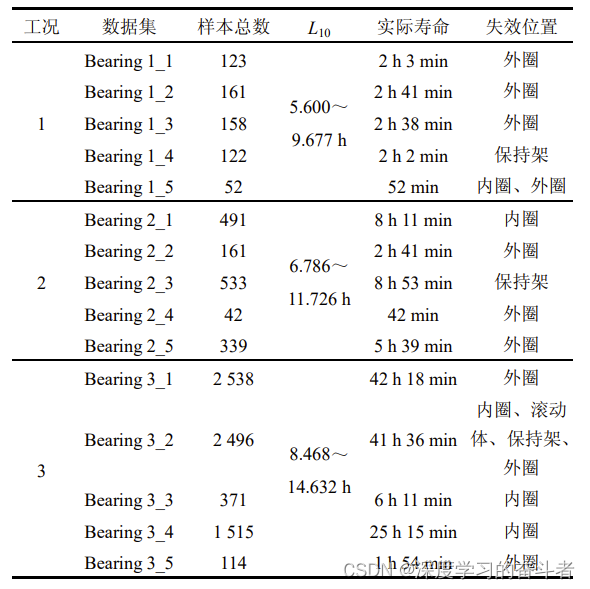
原始数据链接:https://pan.baidu.com/s/1gfwinDWD09LuEfUFLn_kSg?pwd=spm7
提取码:spm7
4.项目文件
code.py是 MSCNN结合LSTM结合注意力机制模型诊断程序
XTJU是数据集文件夹(因为西安交大转子数据量太大,因此这里分别选取了工况1下的Bearing1_1文件夹下的2.CVS文件作为outer(外圈故障)数据,选取工况1下的Bearing1_4文件夹下的2.CVS文件作为roller(滚动体故障)数据,选取工况2下的Bearing2_1文件夹下的2.CVS文件作为roller(滚动体故障)数据)

以1024长度切割原始数据,生成样本(每类故障下有150个样本)
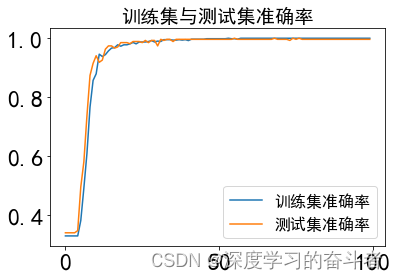
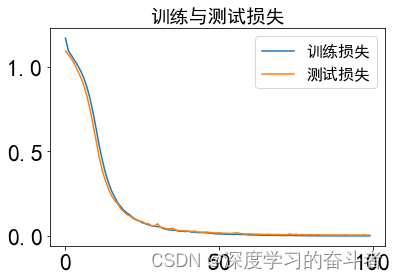
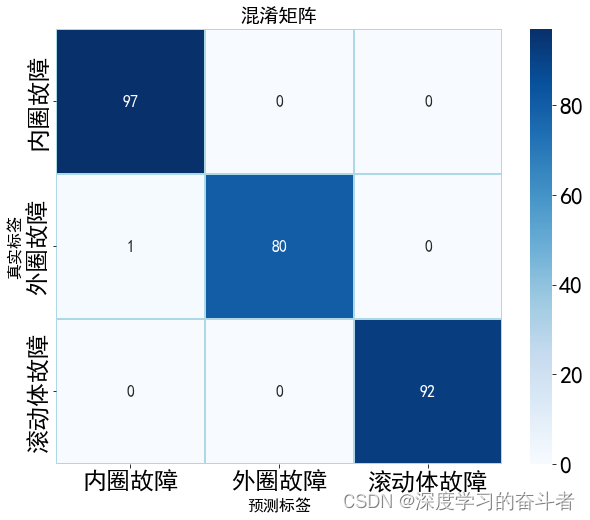
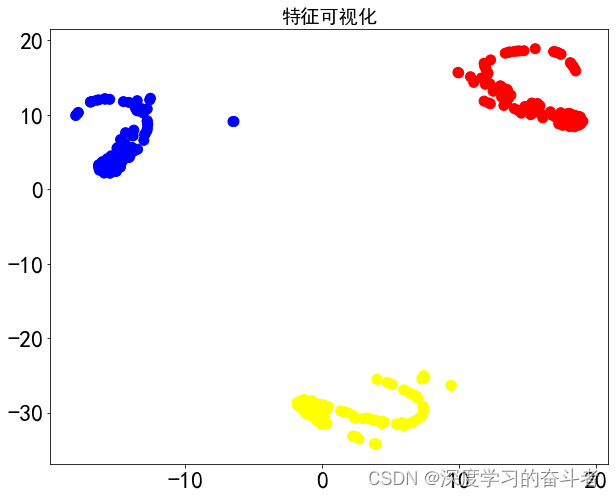
5.效果
import numpy as np
import pandas as pd
import pywt
import sklearn
# from sklearn.model_selection import train_test_splitprint("NumPy version:", np.__version__)
print("Pandas version:", pd.__version__)
print("PyWavelets version:", pywt.__version__)
print("Scikit-Learn version:", sklearn.__version__)import matplotlib
print("Matplotlib version:", matplotlib.__version__)
#数据集和代码:https://mbd.pub/o/bread/mbd-ZZWVlZ1r这篇关于西安交大转子数据集故障诊断(Python代码,MSCNN结合LSTM结合注意力机制模型)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





