本文主要是介绍YoloV5|V7改进策略:全新特征融合模块AFPN,更换YoloV5|V7的Neck,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 摘要
- 论文:《AFPN:用于目标检测的渐近特征金字塔网络》
- 1、介绍
- 2、相关工作
- 3、渐进特征金字塔网络
- 4、实验
- 5、结论
- YoloV5
- 改进方法
- 测试结果
- YoloV7
- 改进方法
- 测试结果
摘要
目标检测中的特征金字塔结构,包括FPN和PAFPN,这两种结构都可以应用于一阶段和二阶段方法中,以提高目标检测的性能。FPN是最常用的特征金字塔结构,用于解决尺度变化问题,而PAFPN则通过增加自下而上的路径来补偿平均精度的不足。
本文提出了新型的特征金字塔网络(AFPN),旨在支持非相邻级别的直接交互,提高目标检测任务的性能。AFPN通过融合两个相邻的低级别特征,并以渐近方式将更高级别的特征纳入融合过程中,避免了非相邻级别之间的语义鸿沟。此外,还采用了自适应空间融合操作来缓解多目标信息冲突。与经典的特征金字塔网络相比,AFPN提供了更好的特征融合效果。
经过MS-COCO 2017验证和测试数据集的评估,实验结果表明比其他最先进的方法更具竞争力。
将AFPN用来改进YoloV5和YoloV7,效果如何呢?
论文:《AFPN:用于目标检测的渐近特征金字塔网络》
https://arxiv.org/pdf/2306.15988v1.pdf
在目标检测任务中, 多尺度特征在编码具有尺度方差的 目标方面具有重要意义。 多尺度特征提取的一种常见策略是采用经 典的自上而下和自下而上的特征金字塔网络。 然而, 这些方法存在 特征信息丢失或退化的问题, 削弱了非相邻层次的融合效果。 本文 提出了一种支持非相邻层次直接交互的渐近特征金字塔网络 (AFPN)。 AFPN首先融合两个相邻的低级特征, 然后逐渐将高级特 征纳入融合过程。 通过这种方式, 可以避免不相邻层次之间更大的 语义鸿沟。 考虑到在每个空间位置的特征融合过程中可能会出现多 目标信息冲突, 进一步利用自适应空间融合操作来缓解这些不一致 性。 我们将提出的AFPN纳入两阶段和一阶段目标检测框架, 并使 用MS-COCO 2017验证和测试数据集进行评估。 实验评估表明, 所 提出的方法比其他最先进的特征金字塔网络取得了更具竞争力的结 果。 代码可在https://github.com/gyyang23/AFPN上获得。
索引术语-目标检测, 特征金字塔网络, 渐近融合, 自适应空 间融合。
1、介绍
目标检测是计算机视觉中的一个基本问题, 旨在检测和 定位图像或视频中的目标。 随着深度学习的出现, 目标检 测发生了范式的转变, 基于深度学习的方法成为了主导方 法。 持续的研究导致了许多新方法的发展, 表明该领域有 进一步进步的潜力。
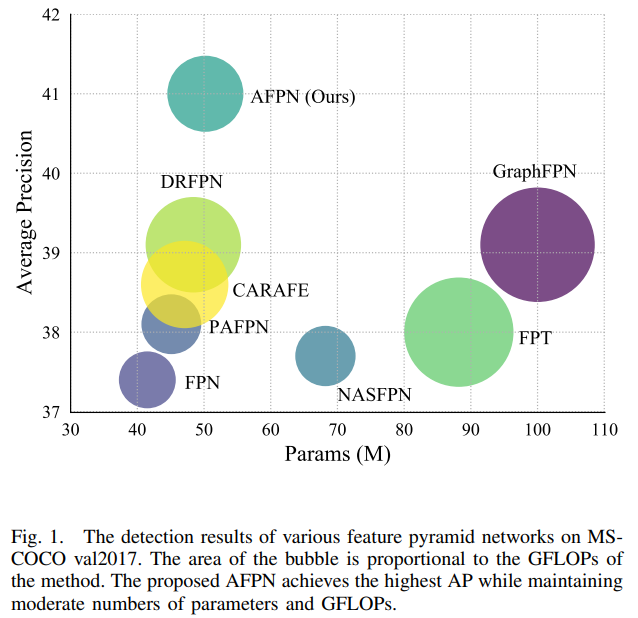
基于深度学习的目标检测方法通常分为单阶段方法和两 阶段方法。 单阶段方法[1]-[3]直接从输入图像中预测物体的 类别和位置。 两阶段方法[4]-[7]则首先生成一组候选区域, 然后对这些区域进行分类和位置回归。 图像中对象大小的 不确定性会导致在单一尺度的特征提取中细节信息的丢失。 因此, 目标检测模型通常引入特征金字塔架构[8]-[15]来解 决尺度变化的问题。 其中, FPN[8]是最常用的特征金字塔 架构。 利用FPN, 一级和两级检测器都能获得更好的检测效 果。 PAFPN[9]在FPN的基础上, 在特征金字塔网络中增加 了一条自下而上的路径, 弥补了FPN的高级特性中的低级特性细节。
对于目标检测任务来说, 真正有用的特征必须包含关于 目标的细节和语义信息, 这些特征应该由一个足够深度的 神经网络来提取。 在现有的特征金字塔架构[8]、 [9]、 [16]、 [17]中, 金字塔顶部的高层特征需要通过多个中间尺度进行 传播, 并与这些尺度上的特征进行交互, 然后才能与底层 的低层特征进行融合。 在这个传播和交互的过程中, 来自 高层特征的语义信息可能会丢失或退化。 同时, PAFPN自 底向上的路径[9]带来了相反的问题:在传播和交互过程中, 底层特征的详细信息可能会丢失或退化。 在最近的研究中, GraphFPN[13]解决了仅在相邻尺度特征之间直接交互的局 限性, 并针对这个问题引入了图神经网络。 然而, 额外的 图神经网络结构显著增加了检测模型的参数和计算量, 这 超过了它的好处。
现有的特征金字塔网络通常将骨干网络生成的高级特征上采样为低级特征。然而,我们注意到HRNet[18]在整个特征提取过程中都保持着低层特征,并反复融合低层和高层特征以生成更丰富的低层特征。该方法在人体姿态估计领域表现出了突出的优势。受HRNet网络架构的启发,本文提出一种渐近特征金字塔网络(AFPN)来解决上述限制。在主干的自底向上特征提取过程中,我们通过在第一阶段结合两个不同分辨率的低级特征来启动融合过程。随着我们进展到后期阶段,我们逐渐将高级特征纳入融合过程中,最终融合骨干的顶级特征。这种融合方式可以避免不相邻层次之间存在较大的语义鸿沟。在此过程中,将低层特征与高层特征的语义信息进行融合,高层特征与低层特征的细节信息进行融合。由于它们的直接交互,避免了多级传输过程中的信息丢失或退化。在整个特征融合过程中,elementwise sum方法并不是一种有效的方法,因为在不同层次之间可能会出现同一位置的不同对象之间的矛盾。为了解决这一问题,在多级融合过程中,利用自适应空间融合操作对特征进行筛选。这使我们能够保留有用的信息进行融合。
为了评估我们的方法的性能, 我们在MS COCO 2017数据集上使用了更快R-CNN框架。 具体来说, 我们 使用ResNet-50和ResNet-101作为主干网, 与基于fpn的更 快R-CNN相比, 它们分别提高了1.6%和2.6%。 我们将其 与其他特征金字塔网络进行了比较。 实验结果表明, 所 提出的AFPN不仅比其他最先进的特征金字塔网络具有 更强的竞争力, 而且具有最低的每秒浮点运算(FLOPs)。 此外, 我们将AFPN扩展到一级检测器。 我们在YOLOv5 框架上实现了所提出的方法, 并以较少的参数获得了优 于基线的性能。
我们的主要贡献如下:(1)我们引入了一个渐近特征金 字塔网络(AFPN), 它促进了非相邻层之间的直接特征融 合, 从而防止了特征信息在传输和交互过程中的丢失或 退化。 (2)为了抑制不同层次特征之间的信息矛盾, 我们 将自适应空间融合操作纳入到多层次特征融合过程中。 (3)在MS COCO 2017验证和测试数据集上的大量实验表 明, 与其他特征金字塔网络相比, 我们的方法具有更高 的计算效率, 同时获得更有竞争力的结果。
2、相关工作
传统的计算机视觉方法通常只从图像中提取一个尺度特征进行分析处理。这将导致对不同尺寸的物体或不同尺度的场景检测性能 较差。 研究人员已经构建了包含各种尺度特征的特征金 字塔, 克服了使用单尺度特征的局限性。 此外, 许多研 究提出了特征融合模块, 旨在增强或细化特征金字塔网 络, 进一步提升检测器的性能。
A. 特征金字塔
FPN[8]采用自顶向下的方式将高层特征转移到低层 特征, 实现不同层次特征的融合。 但是, 在这个过程中, 高层特征并不会与低层特征融合。 为此, PAFPN[9]在 FPN的基础上增加了一条自底向上的路径, 使高层特征 在低层特征中获取细节。 与固定网络架构方法不同, NASFPN[10]使用神经架构搜索算法自动搜索最优连接结 构。 最近, 其他领域的思想也被引入到特征金字塔架构 中。 例如, FPT[12]引入了NLP领域的自注意机制, 提取 不同层次的特征, 并使用多尺度注意网络对这些特征进 行聚合。 GraphFPN[13]利用图神经网络在特征金字塔上 进行交互和信息传播。 虽然GraphFPN也促进了非相邻层 之间的直接交互, 但它对图神经网络的依赖大大增加了 参数数量和计算复杂度, FPT也存在类似的问题。 相比 之下, AFPN只引入正常的卷积分量。 因此, 我们的 AFPN在实际应用中更具有可行性和实用性。
B. 特征融合模块
特征融合模块通常被合并到一个预先存在的、 固定 拓扑的特征金字塔中, 以增强其特征。 也进行了一些研 究来增强特征金字塔的上采样模块。 在本文中, 不改变 特征金字塔拓扑结构的模块称为特征融合模块。 CARAFE[19]是一种通用的、 轻量级的、 高效的上采样 算子, 可以聚合大量的感受野信息。 考虑到不同层次的 特征之间可能存在矛盾的信息, ASFF[20]为不同层次的 特征添加权重, 以便有效地融合它们。 DRFPN[21]通过 合并空间细化块(SRB)和通道细化块(CRB)扩展了PAFPN [9]架构。 SRB模块利用相邻级别的上下文信息来学习上 采样点的位置和内容, 而CRB模块利用注意机制来学习 自适应信道合并策略。 与这些特征金字塔架构相比, 特 征金字塔模块可以无缝集成到广泛的现有特征金字塔架 构中, 为解决特征金字塔的各种局限性提供了一个实用 的解决方案。特征金字塔的一个限制是在特征融合时来自同一位置的不同目标的信息共存。这种限制在AFPN中尤其明显,因为它需要更多轮的特征融合。进一步,进行自适应空间融合,以有效融合不同层次的特征。
3、渐进特征金字塔网络
A. 提取多层次特征
与许多基于特征金字塔网络的目标检测方法一样,在特征融合之前,从主干网络中提取了不同级别的特征。我们遵循Faster R-CNN [8]框架的设计,该框架从主干网络的每个特征层中提取最后一层特征,得到一组不同尺度的特征表示为 { C 2 , C 3 , C 4 , C 5 } \left\{C_{2}, C_{3}, C_{4}, C_{5}\right\} {C2,C3,C4,C5}。为了进行特征融合,首先将低层特征 C 2 C_{2} C2和 C 3 C_{3} C3输入到特征金字塔网络中,然后添加 C 4 C_{4} C4,最后添加 C 5 C_{5} C5。在特征融合之后,产生了一组多尺度特征 { P 2 , P 3 , P 4 , P 5 } \left\{P_{2}, P_{3}, P_{4}, P_{5}\right\} {P2,P3,P4,P5}。对于在Faster R-CNN框架上进行的实验,我们对 P 5 P_{5} P5应用步长为2的卷积,然后对 P 6 P_{6} P6应用步长为1的卷积来生成,确保统一的输出。最终的多尺度特征集为 { P 2 , P 3 , P 4 , P 5 , P 6 } \left\{P_{2}, P_{3}, P_{4}, P_{5}, P_{6}\right\} {P2,P3,P4,P5,P6},对应的特征步长为 { 4 , 8 , 16 , 32 , 64 } \{4, 8, 16, 32, 64\} {4,8,16,32,64}像素。需要注意的是,YOLO只将 { C 3 , C 4 , C 5 } \left\{C_{3}, C_{4}, C_{5}\right\} {C3,C4,C5}输入到特征金字塔网络中,生成了 { P 3 , P 4 , P 5 } \left\{P_{3}, P_{4}, P_{5}\right\} {P3,P4,P5}的输出。
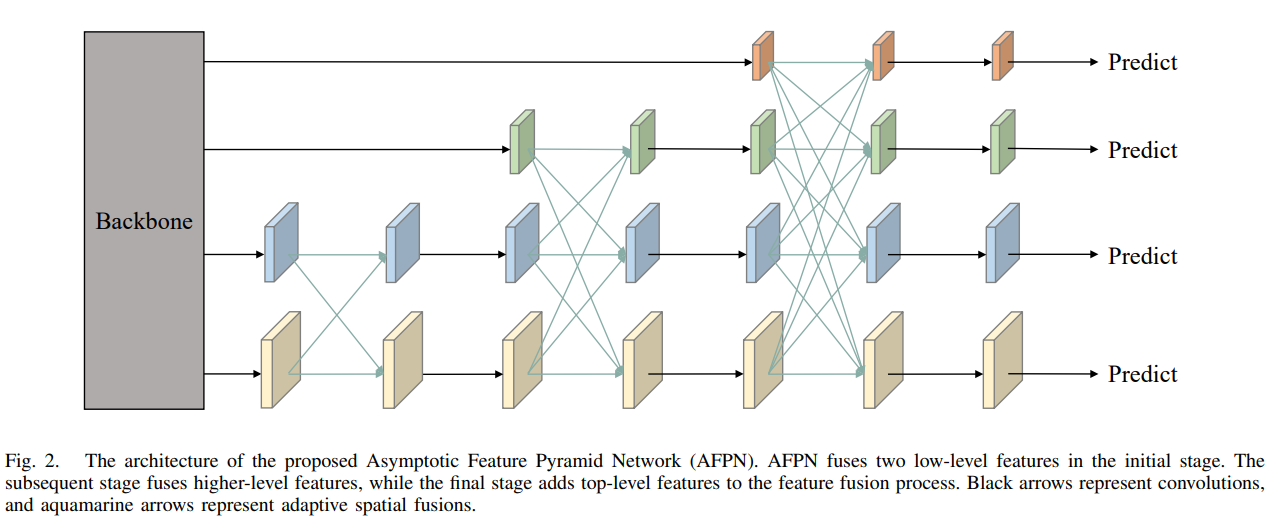
B. 渐近架构(Asymptotic Architecture)
所提出的AFPN的架构如图2所示。在主干网络自下而上的特征提取过程中,AFPN渐近地融合了低级、高级和顶级特征。具体来说,AFPN最初融合了低级特征,接着融合了深层特征,最后融合了最顶层的特征,即最抽象的特征。非相邻层次之间的语义鸿沟大于相邻层次之间的语义鸿沟,尤其是底层和顶层特征之间的语义鸿沟。这导致直接使用C2、C3、C4和C5进行特征融合的效果较差。由于AFPN的架构是渐近的,这使得不同层次的特征在渐近融合过程中的语义信息更加接近,从而缓解了上述问题。例如,C2和C3之间的特征融合减小了它们的语义鸿沟。由于C3和C4是相邻层次的特征,因此减小了C2和C4之间的语义鸿沟。
为了对齐维度和准备特征融合,我们使用1 × 1卷积和双线性插值方法来上采样特征。另一方面,我们根据所需的下采样率使用不同的卷积核和步幅进行下采样。例如,我们应用一个步幅为2的2 × 2卷积实现2倍下采样,一个步幅为4的4 × 4卷积进行4倍下采样,一个步幅为8的8 × 8卷积进行8倍下采样。在特征融合之后,我们继续使用四个残差单元来学习特征,这些残差单元类似于ResNet [24]。每个残差单元包括两个3 × 3卷积。由于YOLO中只使用了三个级别的特征,因此没有8倍的上采样和8倍的下采样。
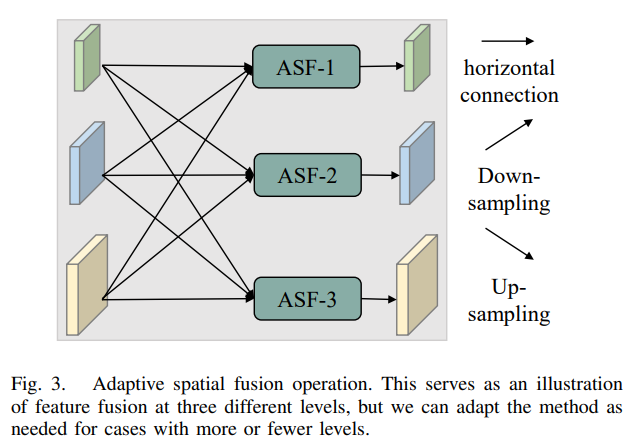
C. 自适应空间融合(Adaptive Spatial Fusion)
我们利用ASFF [20]在多级特征融合过程中为不同级别的特征赋予不同的空间权重,以增强关键级别的意义并减轻来自不同物体的矛盾信息的影响。如图3所示,我们对三个级别的特征进行融合。令 x i j n → l x_{i j}^{n \rightarrow l} xijn→l 表示从第n级到第l级的特征向量在位置(i,j)处的值。通过多级特征的自适应空间融合,得到的结果特征向量记为 y i j l y_{i j}^{l} yijl,它由特征向量 x i j 1 → l x_{i j}^{1 \rightarrow l} xij1→l、 x i j 2 → l x_{i j}^{2 \rightarrow l} xij2→l 和 x i j 3 → l x_{i j}^{3 \rightarrow l} xij3→l 的线性组合定义如下:
y i j l = α i j l ⋅ x i j 1 → l + β i j l ⋅ x i j 2 → l + γ i j l ⋅ x i j 3 → l , (1) y_{i j}^{l}=\alpha_{i j}^{l} \cdot x_{i j}^{1 \rightarrow l}+\beta_{i j}^{l} \cdot x_{i j}^{2 \rightarrow l}+\gamma_{i j}^{l} \cdot x_{i j}^{3 \rightarrow l} \text {, } \tag{1} yijl=αijl⋅xij1→l+βijl⋅xij2→l+γijl⋅xij3→l, (1)
其中 α i j l \alpha_{i j}^{l} αijl、 β i j l \beta_{i j}^{l} βijl和 γ i j l \gamma_{i j}^{l} γijl表示第l级三个级别特征的空间权重,满足约束条件 α i j l + β i j l + γ i j l = 1 \alpha_{i j}^{l}+\beta_{i j}^{l}+\gamma_{i j}^{l}=1 αijl+βijl+γijl=1。考虑到AFPN每个阶段融合特征数量的差异,我们实现了特定阶段的自适应空间融合模块数量。
4、实验
A. 实验设置
数据集:我们在MS COCO 2017数据集[25]、 118k训练图像 (train2017)、 5k验证图像(val2017)和20k测试图像(test-dev)上评 估了所提出的方法。 由于test-dev标签不可用, 我们将模型生 成的边界框上传到指定的评估网站以获得性能指标。 具体来说, 我们选择平均精度(AP)、 AP50、 AP75、 APS、 APM和APL作为评 估指标。
实现细节:我们利用mmdetection[26]作为底层框架, 在2块 NVidia RTX3090 gpu上进行实验。 在训练过程中, 我们采用 SGD[27]作为我们的优化器, 并将学习率、 权重衰减和动量分 别配置为0.01、 0.0001和0.9。 每个小批包含8个图像, 分布在2 个gpu上。 为了公平比较, 我们在不同的实验中使用了不同分 辨率的图像作为输入。 我们将在每个对比实验部分描述具体情 况。 其余超参数遵循MMDetection的默认配置。
B. 不同特征金字塔网络的对比
在本节中, 用“*” 表示的方法和我们提出的方法进行了 36个epoch的训练。 在第27和33个epoch, 学习率分别降低了10 倍。 在数据增强过程中使用了随机翻转和随机裁剪。 我们将我 们的方法与最近的特征金字塔网络进行性能比较。 鉴于模型的 性能严重依赖于输入图像的大小, 我们使用类似分辨率的输入 图像对我们提出的方法和最近的特征金字塔网络进行了比较分析。
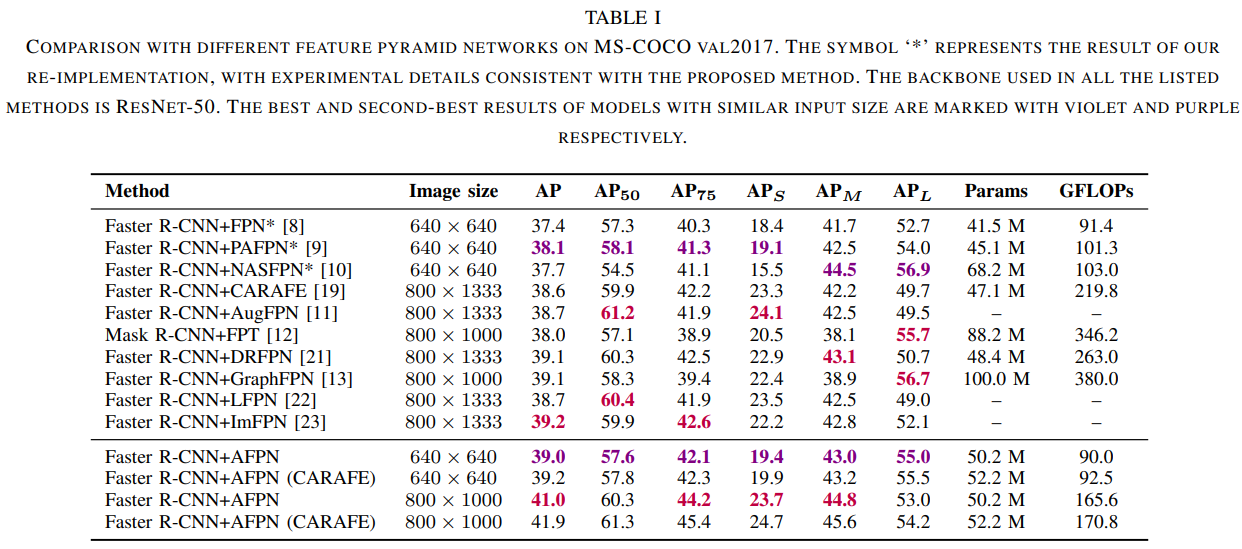
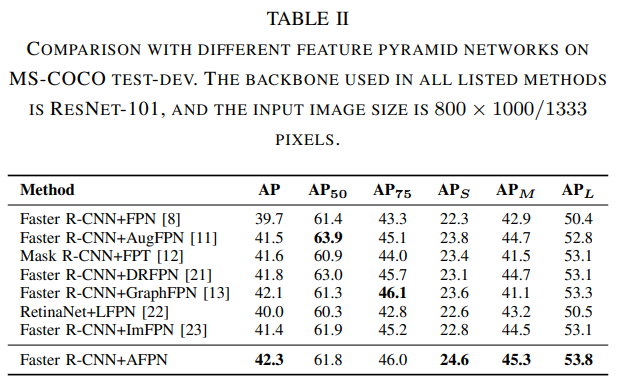
如表I所示,当输入图像尺寸为640 × 640时,我们的方法取得了39.0%的AP,甚至超过了一些分辨率更大的模型。与FPN[8]和PAFPN[9]相比,AFPN在val2017上的AP性能分别提高了1.6%和0.9%,同时在大多数其他指标上超过了它们。值得注意的是,由于NASFPN[10]是在RetinaNet[1]框架上进行搜索的,它在Faster R-CNN[4]框架上的性能并不是特别令人印象深刻。相比之下,AFPN在AP上比NASFPN提高了1.3%,当输入图像大小为800 × 1000时,AFPN达到了41.0%的AP,超过了其他方法的性能。在构建AFPN架构时,我们没有考虑上采样的质量。为了解决这个不足,我们用cafef[19]算子代替了双线性插值算子,它具有优越的上采样质量。在进行进一步实验时,我们发现这种替换显著提高了模型的性能。将骨干网络替换为ResNet-101[24],在MS COCO test-dev[25]上进行训练和测试。表II显示与基线(FPN)相比,我们的AFPN AP增加了2.6%。与同类技术相比,该方法也取得了有竞争力的结果,同时在AP、APS、APM和APL中保持领先地位。
C.不同检测器的结果
为了证明该方法的通用性,将AFPN合并到两阶段和一阶段检测器中。实验结果表明,该方法显著提高了两个检测器框架的性能。
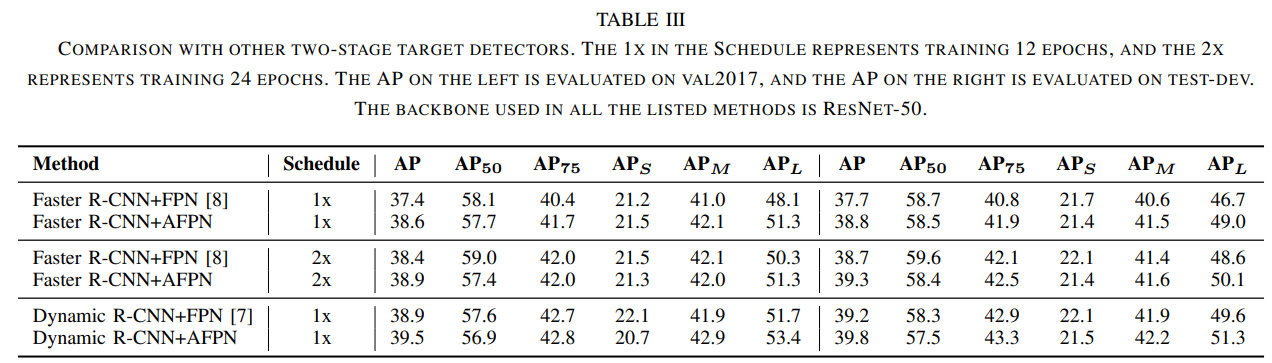
两阶段检测器:两阶段检测器的实验结果如表III所示。表中所有方法的输入图像大小为800 × 1333。在数据增强过程中只使用随机翻转。我们在研究中评估了Faster R-CNN[8]和Dynamic R-CNN[7]。实验结果表明,在相同的训练时间下,用AFPN替换检测器的FPN可以显著提高检测性能,特别是对于大目标的检测。这是因为FPN的架构不允许高层特征获取低层特征的详细信息。我们的AFPN并没有提高检测器检测小目标的能力,这在APS结果中得到了支持。此外,我们还发现AFPN在AP50中低于FPN,而在AP75中优于FPN。因此,相比FPN, AFPN更适用于高精度定位场景。
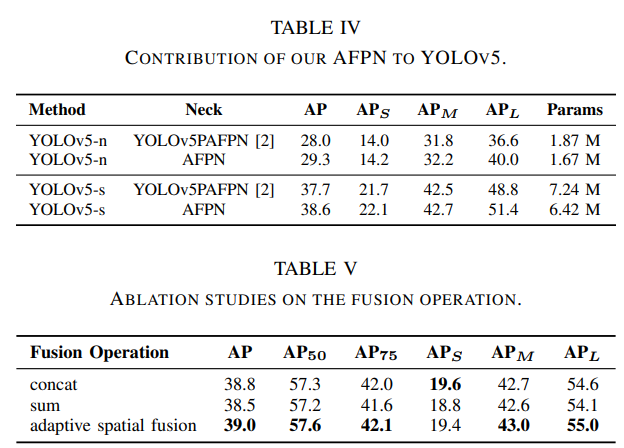
单阶段检测器:在YOLOv5[2]上的实验结果如表IV所示。使用大小为640 × 640的输入图像对检测器进行300 epoch的训练。实验结果表明,与YOLOv5的原始颈部(YOLOv5PAFPN)相比,AFPN在检测性能上有显著提高,特别是在检测大目标方面。具体而言,对于YOLOv5-n, AFPN将大目标平均精度(APL)提高了3.4%,对于YOLOv5-s,将APL提高了2.6%。此外,我们的AFPN在AP、APS、APM和APL方面保持领先地位。
D.可学习的参数和计算成本
网络的深度和宽度都会影响其表示能力。由于AFPN的深度已经增强了模型的表示能力,因此采用减小网络宽度的策略来优化模型。具体来说,在两阶段检测器中,我们将进入特征金字塔网络的特征降维到原来的1/8。在单级检测器中,我们将维度降低到原来的1/4。表I提供了各种特征金字塔网络的可学习参数数量和总计算成本,包括我们提出的AFPN。根据表中给出的结果,我们的AFPN架构有5020万个可学习参数,在640 × 640分辨率下,GFLOPs达到了90.0。与FPN[8]相比,AFPN中的参数数量增加了21.0%。然而,我们在表中的所有方法中实现了最低的GFLOPs。产生这种现象的主要原因是我们降低了特征维度。表IV中的实验结果表明,AFPN在使用更少参数的情况下,在YOLOv5上取得了更好的性能。
E.消融研究
为了研究AFPN中自适应空间融合操作的有效性,将其替换为另外两种融合操作,即元素级和和元素级连接,用于消融研究。我们的实验使用了以ResNet-50为骨干的Faster R-CNN框架。如消融研究的表5所示,我们观察到元素级联操作可以达到与自适应空间融合操作相媲美的性能水平。而AP、AP50、AP75、APM和APL指标略低。鉴于自适应空间融合对元素和进行加权操作以抑制特征之间的矛盾,因此可以认为其性能优于元素和。实验结果也证明了这一点。
5、结论
本文提出渐近特征金字塔网络(Asymptotic Feature Pyramid Network, AFPN)来解决不相邻层次之间间接交互导致的信息丢失和退化问题。AFPN采用渐近方式进行特征融合,并采用自适应空间融合操作,在融合过程中提取更多有用信息。广泛的实验结果表明,与各种检测框架的基线方法相比,AFPN具有优越的性能。未来,我们将探索更轻的AFPN及其在其他视觉任务中的适用性。
YoloV5
改进方法
测试结果
YoloV7
改进方法
测试结果
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 15/15 [00:02<00:00, 5.45it/s]all 229 1407 0.915 0.99 0.99 0.717c17 229 131 0.947 0.992 0.996 0.822c5 229 68 0.923 1 0.995 0.842helicopter 229 43 0.938 1 0.963 0.593c130 229 85 0.991 0.988 0.995 0.652f16 229 57 0.917 0.964 0.974 0.677b2 229 2 0.828 1 0.995 0.497other 229 86 0.982 0.977 0.993 0.57b52 229 65 0.978 0.985 0.983 0.813kc10 229 62 0.962 0.984 0.986 0.829command 229 40 0.985 1 0.996 0.806f15 229 123 0.97 1 0.996 0.686kc135 229 91 0.982 0.989 0.987 0.69a10 229 27 0.96 0.926 0.978 0.478b1 229 20 0.97 1 0.996 0.712aew 229 25 0.918 1 0.99 0.76f22 229 17 0.759 1 0.973 0.711p3 229 105 0.988 1 0.997 0.794p8 229 1 0.709 1 0.995 0.697f35 229 32 0.979 0.938 0.991 0.523f18 229 125 0.943 0.984 0.991 0.805v22 229 41 0.979 1 0.996 0.665su-27 229 31 0.98 1 0.996 0.811il-38 229 27 0.972 1 0.996 0.824tu-134 229 1 0.369 1 0.995 0.796su-33 229 2 1 0.998 0.995 0.696an-70 229 2 0.799 1 0.995 0.796tu-22 229 98 0.986 1 0.996 0.803
300 epochs completed in 5.082 hours.Optimizer stripped from runs\train\exp\weights\last.pt, 77.9MB
Optimizer stripped from runs\train\exp\weights\best.pt, 77.9MB这篇关于YoloV5|V7改进策略:全新特征融合模块AFPN,更换YoloV5|V7的Neck的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




