本文主要是介绍了解三层架构:表示层、业务逻辑层、数据访问层,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
背景:
三层架构
什么是三层:
分层的目的:
三层的结构关系编辑
三层表现形式:编辑
三层的优缺点:
总结:
背景:
三层架构是一种软件设计模式,可称为客户端-服务器-架构,把各个功能模块划分为表示层(UI)、业务逻辑层(BLL)和数据访问层(DAL)三层架构,各层之间采用接口相互访问,并通过对象模型的实体类(Model)作为数据传递的载体,不同的对象模型的实体类一般对应于数据库的不同表,实体类的属性与数据库表的字段名一致。
三层架构
什么是三层:
表示层(UI):
用户交互的界面,位于最上层,用于显示和接收用户提交的数据,为用户提供交互式平台。表示层一般为Windows窗体应用程序或Web应用程序
业务逻辑层(BLL):
架构的核心,处理业务逻辑和规则,表示层和数据访问层之间的沟通桥梁,主要负责数据的传递和处理。
数据访问层(DAL):
负责与数据库或其他数据存储进行交互,实现对数据的读取、保存和跟更新等操作.
分层的目的:
“高内聚,低耦合的思想”,表示在设计和开发软件系统时,应该使模块之间的关系更加紧密,同时避免模块之间的依赖性过于紧密,以便更好地实现系统的可维护性,可扩展性和可重用性
三层的结构关系

各层之间相互依赖,表示层依赖于业务逻辑层,业务逻辑层依赖于数据访问层
三层表现形式:
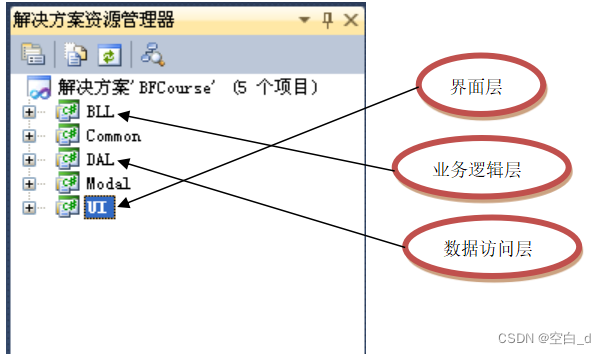
三层的优缺点:
三层架构
优点
可维护性
可重用性
可扩展性
可测试性
每一层独立扩展,不影响其他层
组件的之间的接口定义良好(多个程序重复使用它们)
每一层可以独立扩展,不影响其他层
每个层次都有自己的职责和功能(轻松编写单元测试,集成测试)
缺点
复杂性
耦合度
性能开销
开发时间
三层架构增加应用程序的复杂性,需要更多的设计和实现工作
虽然可以提高代码的维护性和扩展性,同时增加系统的耦合度
增加了层间通信,导致性能开销
设计、实现每个层次-增加开发时间、尤其复杂程序时间延长
总结:
三层架构是一种常用的软件架构模式,可以使代码更加清晰、易于维护和扩展,同时还可以提高代码的可重用性和可测试性。在实际的软件开发中,我们应该根据具体的需求和场景选择合适的架构模式,以达到更好的开发效率和代码质量。
这篇关于了解三层架构:表示层、业务逻辑层、数据访问层的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






