本文主要是介绍深度学习_人脸检测_基于多任务卷积神经网络(MTCNN)论文详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首先上论文地址:
Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
一.MTCNN工作流程图
首先我们看一下MTCNN的工作流程图:
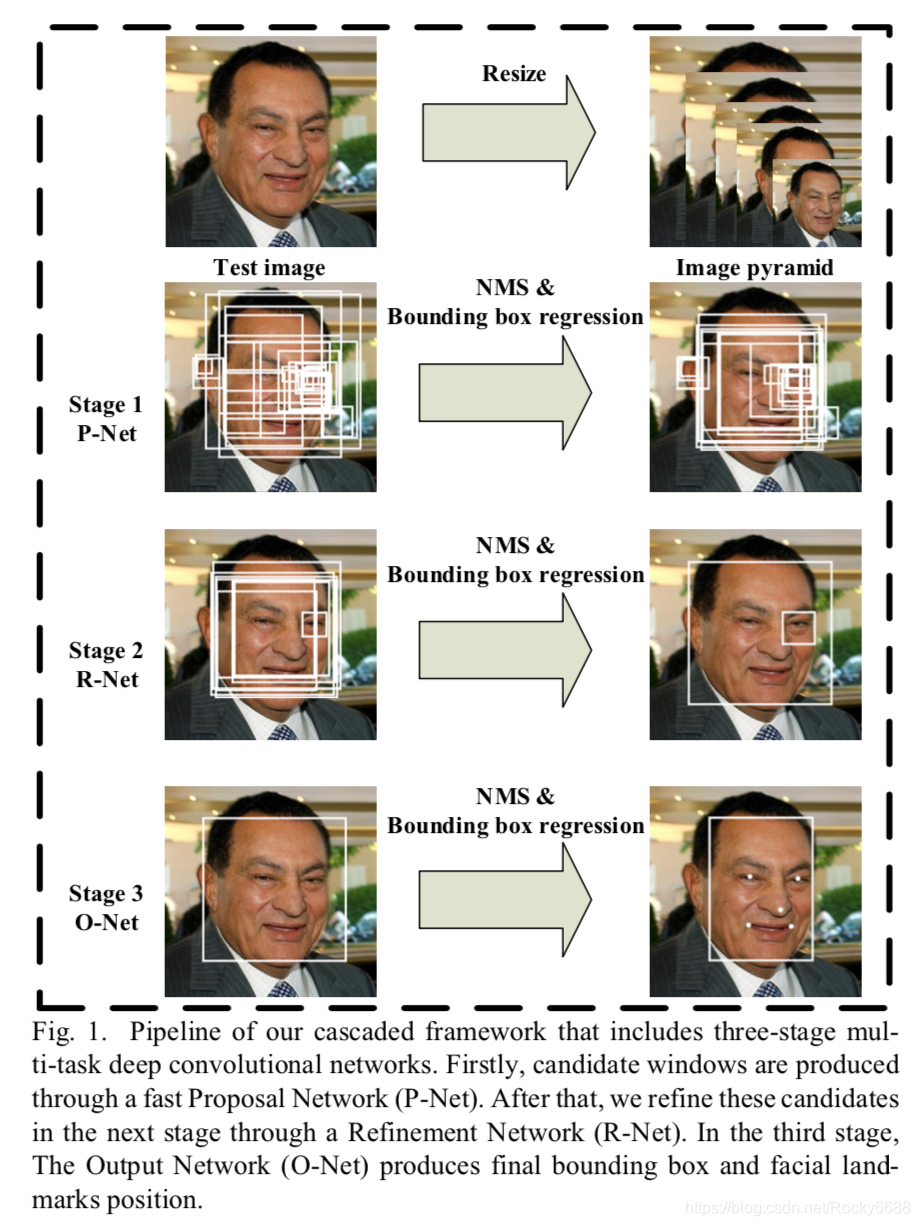
注意:训练阶段使用的图片都是 12 × 12 12\times 12 12×12去训练P-Net,而在inference的时候,图像大小不受限制。
图像金字塔的作用:可以进行不同大小的人头的推理,达到尺度不变性。
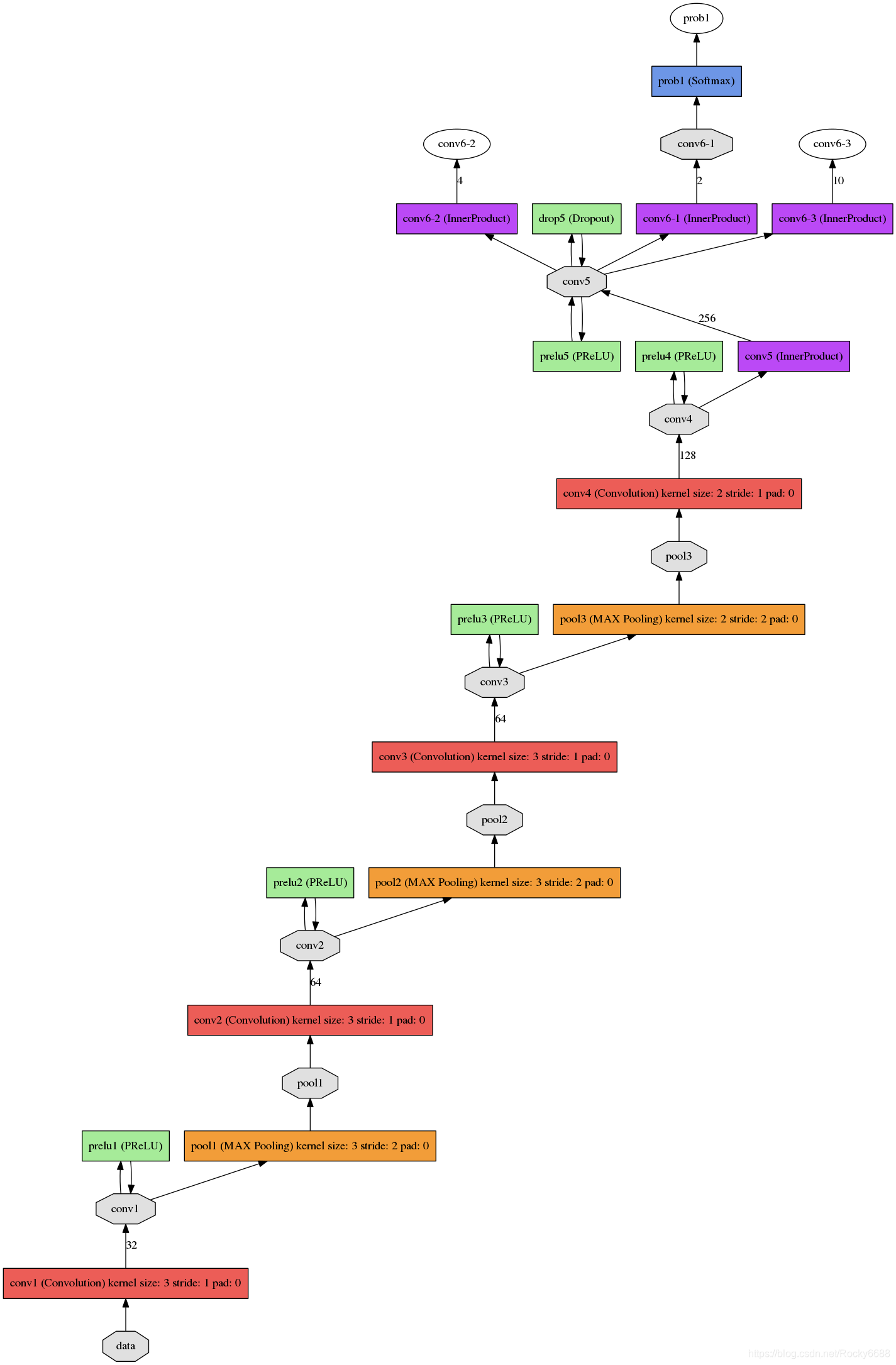
二.MTCNN的模型结构
MTCNN模型有三个子网络。
分别是P-Net,R-Net,O-Net。
- Proposal Network(P-Net):该网络结构主要获得了人脸区域的候选窗口和边界框的回归向量。并用该边界框做回归,对候选窗口进行校准,然后通过非极大值抑制(NMS)来合并高度重合的候选框。
- Refine network(R-Net):该网络结构还是通过边界框回归和NMS来去掉那些false-positive区域。只是由于该网络结构和P-Net网络结构有差异,多了一个全连接层,所以会取得更好的抑制false-positive的作用。
- Output Network(O-Net):该层比R-Net层又多了一层卷积层,所以处理的结果会更加精细。作用和R-Net层作用一样。但是该层对人脸区域进行了更多的监督,同时还会输出5个地标(landmark)。
下面我们来看看详细的网络结构:
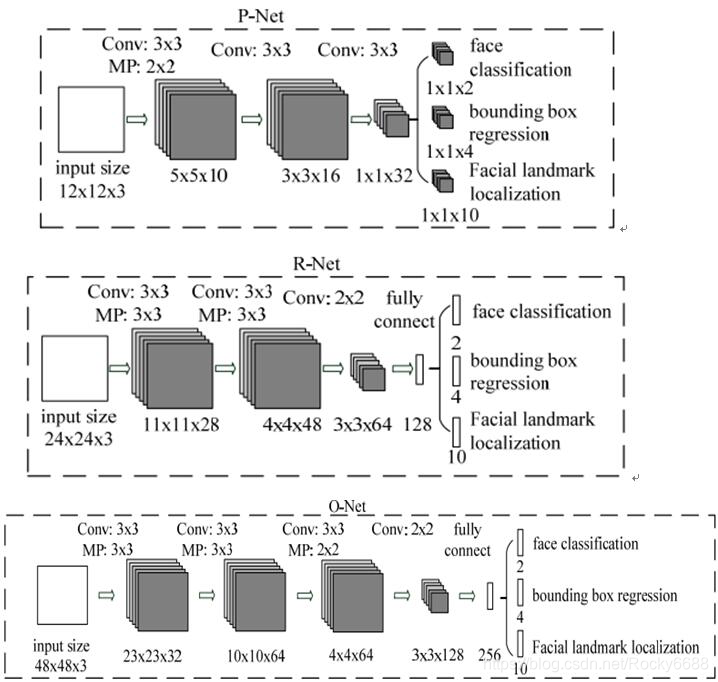
建立模型的一些考虑:
- 把5 * 5卷积换成3 * 3卷积,能减少计算量,并增加深度。
- 非线性激活函数使用PReLU。
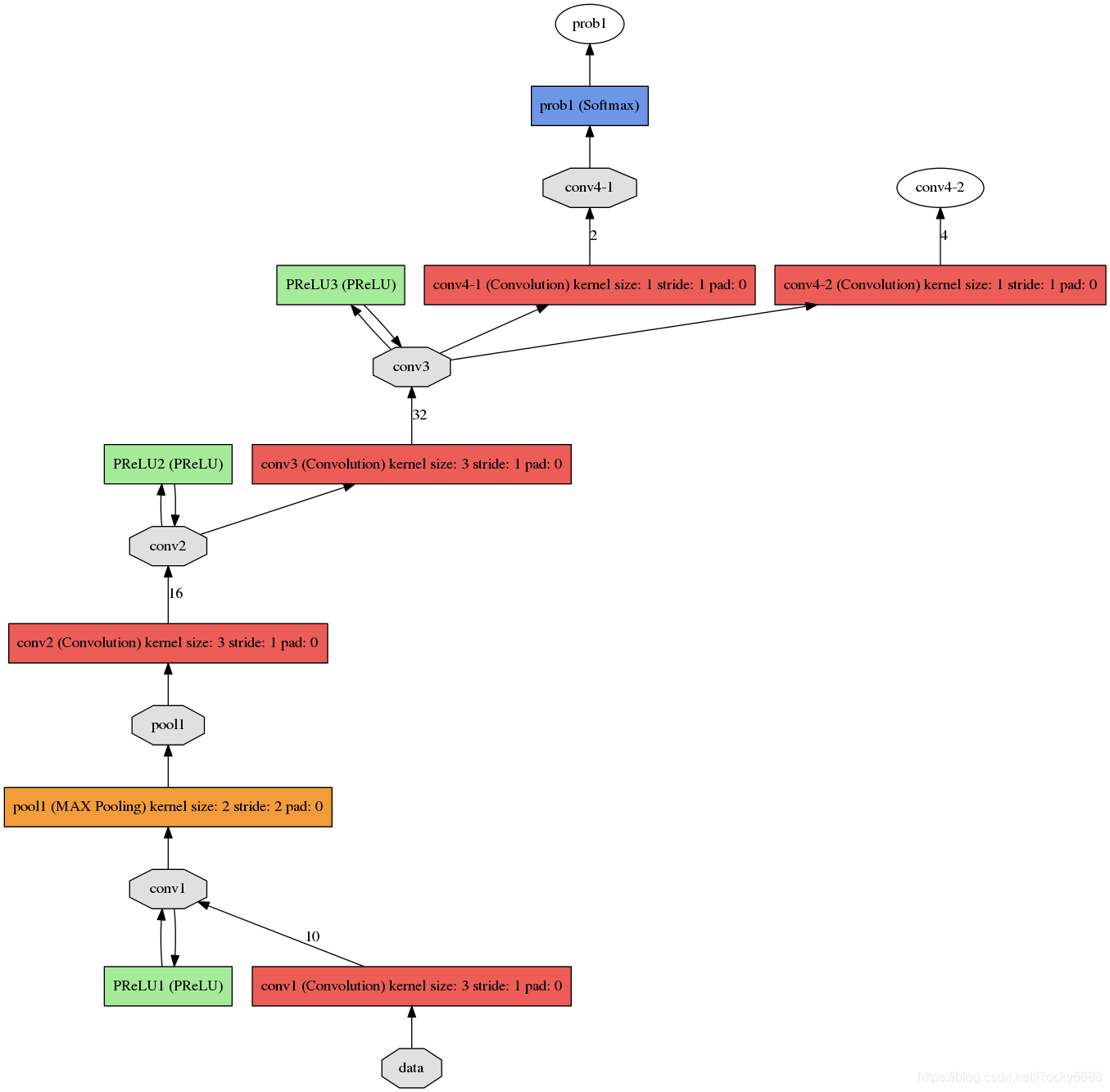
更加详细的网络结构
分别为det1,det2,det3。
det1.prototxt结构:
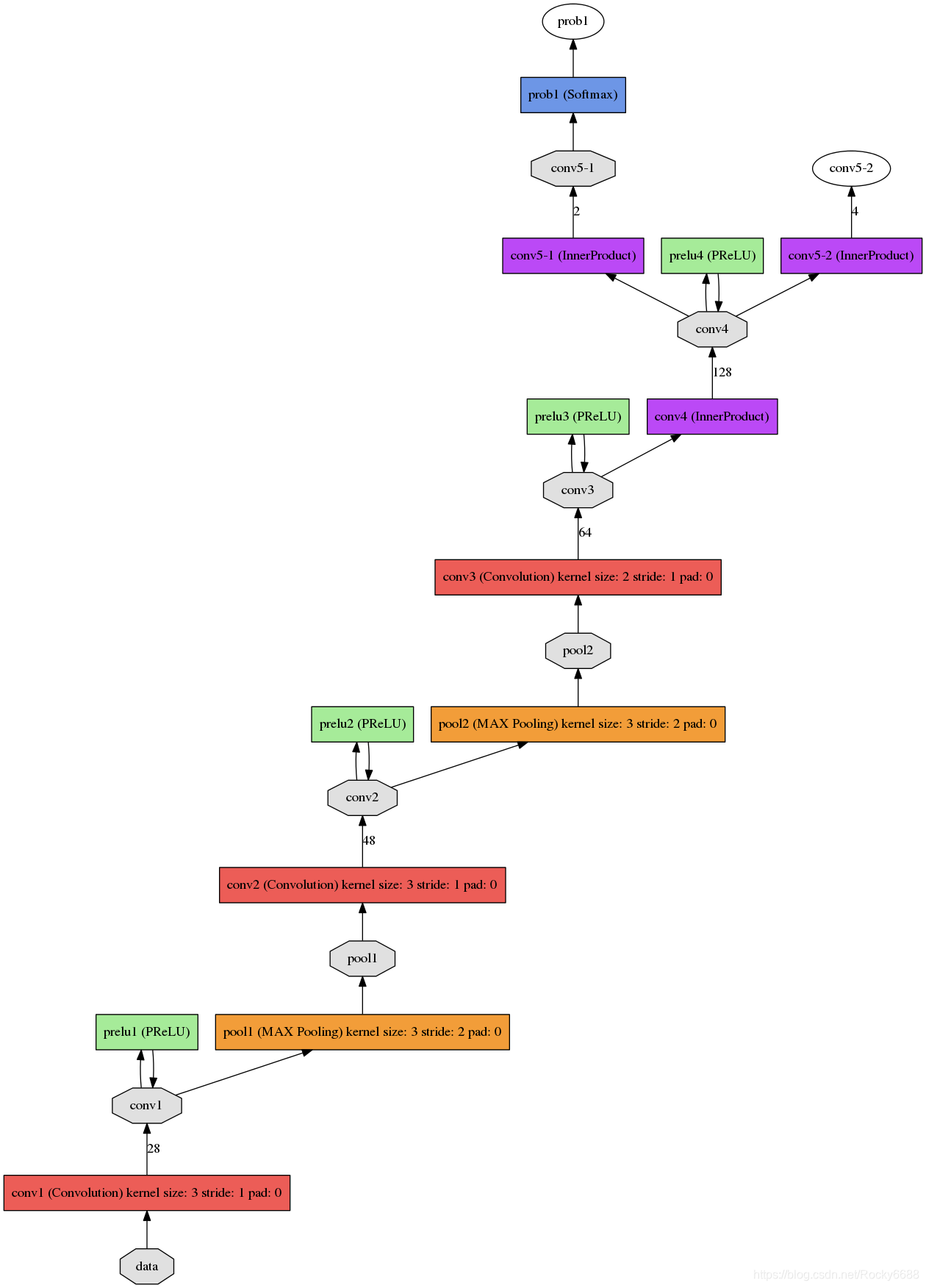
det2.prototxt结构:
det3.prototxt结构:
为了检测不同大小的人脸,开始需要构建图像金字塔,先经过P-Net模型,输出人脸类别和边界框(边界框的预测为了对特征图映射到原图的框平移和缩放得到更准确的框),将识别为人脸的框映射到原图框位置可以获取patch,之后每一个patch通过resize的方式输入到R-Net,识别为人脸的框并且预测更加准确的人脸框,最后R-Net识别为人脸的每一个patch通过resize的方式输入到O-Net,跟R-Net类似,关键点是为了在训练集有限情况下使模型更鲁棒。
注意:构建图像金字塔的缩放比例要保留,为了将边界框映射到最开会原图上。
三.MTCNN的主要公式
MTCNN特征描述子主要包含3个部分,人脸/非人脸分类器,边界框回归,地标定位。
人脸分类

上式为人脸分类的交叉熵损失函数,其中pi为是人脸的概率,yidet 为ground-truth标签。
边界框回归

上式为通过欧式距离计算的回归损失,使得这个过程成为回归问题。其中,带尖儿的y为通过网络预测得到,不带尖儿的y为实际的ground-truth坐标。其中,y为一个(左上角x,左上角y,长,宽)组成的四元组。
地标定位

和边界回归一样这也是一个回归问题,还是计算网络预测的地标位置和实际真是地标位置的欧式距离,并最小化该距离。其中,带尖儿的y为通过网路预测得到,不带尖儿的y为实际的ground-truth地标坐标。由于一共5个点(左右眼睛,嘴巴,左右嘴角),每个点有x和y2个坐标,所以y属于十元组。
多个输入源的训练

整个的训练学习过程就是最小化上面的这个函数,其中N为训练样本的数量,aj 表示任务的重要性,bj 为样本标签,Lj 为上面的损失函数。
Online Hard sample mining(OHEM)
这个概念是什么意思呢?
答:寻找出比较刚的样本,好好炼它!!!
有别于传统的硬样本挖掘,我们进行在线硬样本挖掘,与训练过程相适应。
在小批量样本训练过程中,为了取得更好的效果,我们从所有样本中对正向传播计算出的损失进行排序,并选择损失最高的前70%样本作为硬样本,然后我们只计算反向传播中这些硬样本的梯度,这样一来保证传递的都是有效的数字。有点类似latent SVM,只是作者在实现上更加体现了深度学习的end-to-end。
四.训练
论文中使用的数据集
- FDDB
- WIDER
- AFLW
数据集的标注有4类
- Positive face数据(正样本)
- Negative face数据(负样本)
- Part face数据(部分人脸样本)
- landmark face数据(地标)
训练样本的比例负样本:正样本:Part样本:地标 = 3:1:1:2
交并比IoU(Intersection-over-Union)比例
在训练过程中,y尖儿和y的交并比比例为:
- 0-0.3:负样本
- 0.4-0.65:部分人脸样本
- 0.65-1:正样本
各个数据集如何使用
- 网络做人脸分类的时候,使用Positives和Negatives的图片来做,容易使模型收敛。
- 网络做人脸bbox的偏移量回归的时候,使用Positives和Parts的数据,比较好的使得bbox回归。
- 网络在进行人脸landmark回归的时候,只使用landmark face数据集。
训练效果
在线硬样本挖掘的有效性:
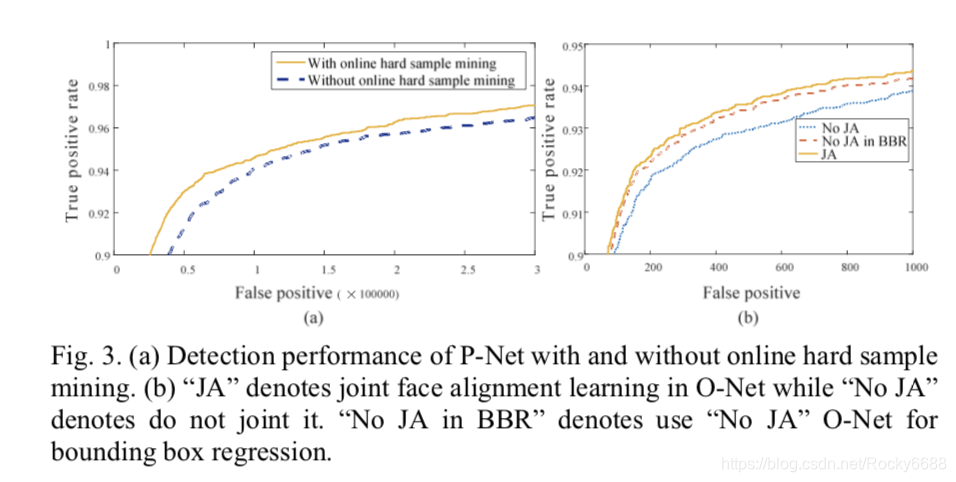
joint detection and alignment的有效性:
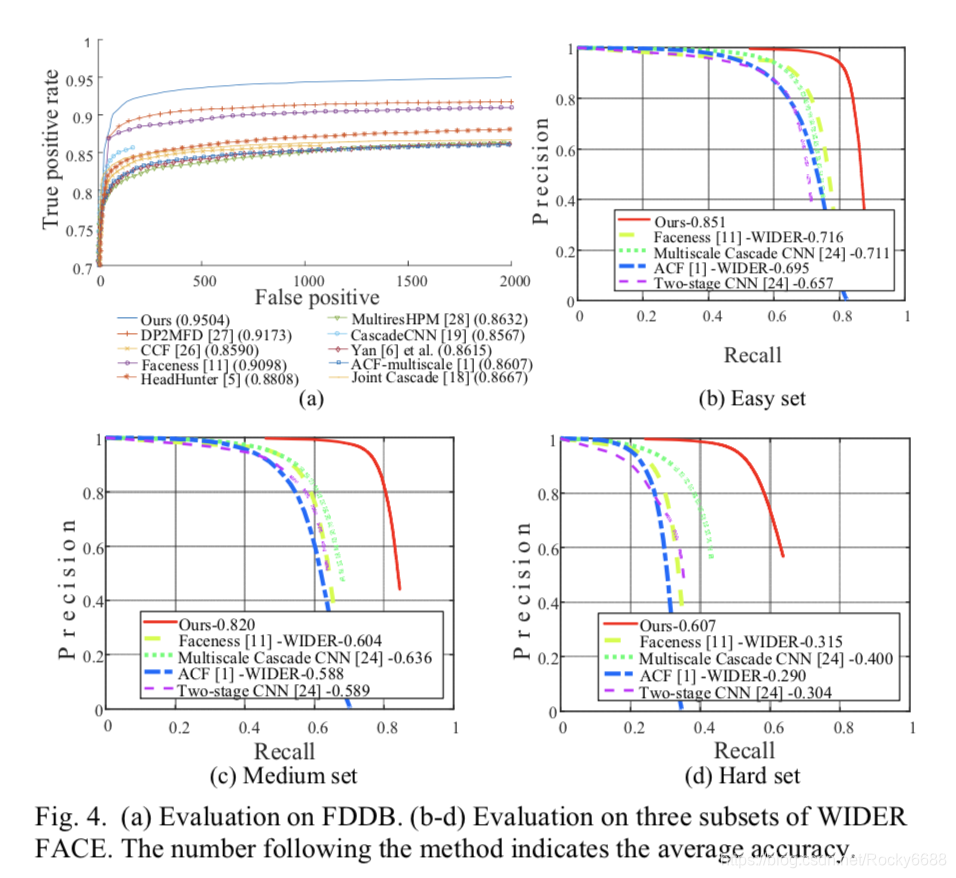
人脸检测的效果与其他算法进行对比:
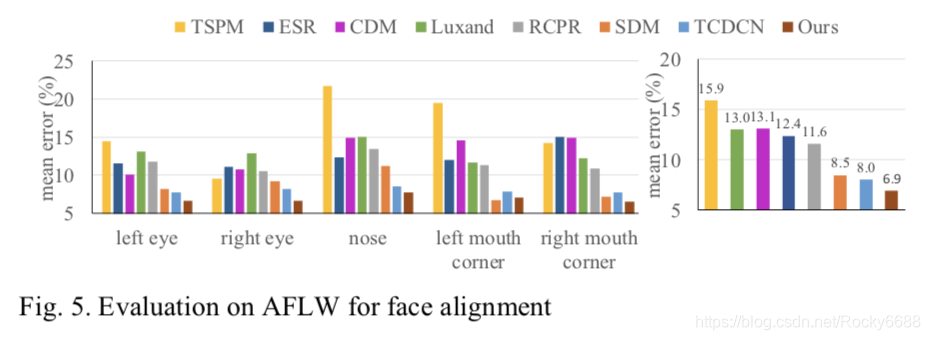
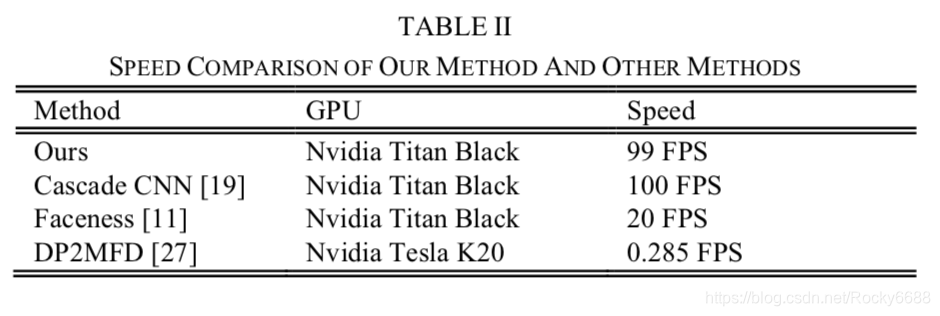
运行的时间效率:
优化方法及思路
- 将landmark加入到前面两个网络进行训练。因为landmark是基于bbox的左上角坐标做偏移的,这样做会使得bbox的损失函数和landmark损失函数相关联。这个影响应该是正向的,论文里也提到landmark的预测也有利于bbox预测的更好。所以将landmark加入到前面两个网络做训练其实是有利于bbox预测的更好,为第三层真正预测landmark打下基础。
- P-Net是为了能产生proposal,但是因为要多次缩放在执行推理,这样的效率比不上batch处理,所以可以进行多模型多GPU并行,经过了P-Net后,R-Net和O-Net进行batch。
- 在截图中没有人脸的部分,可以标注负值。
这篇关于深度学习_人脸检测_基于多任务卷积神经网络(MTCNN)论文详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






