本文主要是介绍文献阅读--FLTrust: Byzantine-robust Federated Learning via Trust Bootstrapping,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文设计了一个 Byzantine-robust (能够抵御投毒攻击) 的联邦学习框架。在此 Fed 框架中,每一轮梯度聚合前,server 端 会先计算 global模型在 root dataset(server额外收集的干净的数据集,大小为100即可)上的梯度,然后通过计算该梯度和各 client 上传的梯度的 角度获取 TS(信任分数),并进行幅值的缩放,有效地降低了 上传投毒梯度的 client 所造成的影响。
目录
- 1 问题
- 2 挑战
- 2.1 如何辨别哪个client异常?
- 2.2 如何控制更新权重?
- 2.3 计算量
- 3 解决方案
1 问题
在 Fed 框架中,malicious client 会进行投毒攻击,这样的投毒攻击可以表现为直接上传梯度,而不用在样本上进行修改,上传 异常梯度,损害 global model 的性能。

2 挑战
2.1 如何辨别哪个client异常?
如果使用异常检测算法对每个 client 上传的梯度进行无监督二分类的异常检测,则可能出现以下情况:无法确定哪一类代表异常梯度。因此需要一个 标杆,能够确定哪一类代表异常值。
2.2 如何控制更新权重?
在以往的数据聚合阶段,都是根据各方的数据量进行权重配比,即数据量越多的 client 更新时获得的权重更大,聚合算法如下图:
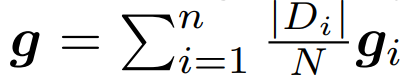
这样的算法存在一个问题,恶意敌手可以通过谎报更多的数据量从而获取更大的权重,其数据投毒造成的危害也越大。
2.3 计算量
考虑有些 client 是 IoT 场景下的边缘设备,计算能力十分有限,因此本文所涉及的算法要求:
1.不给client增加计算量;
2.server计算量能小就小。
3 解决方案
这张图非常清楚的概括了本文所提出的框架:
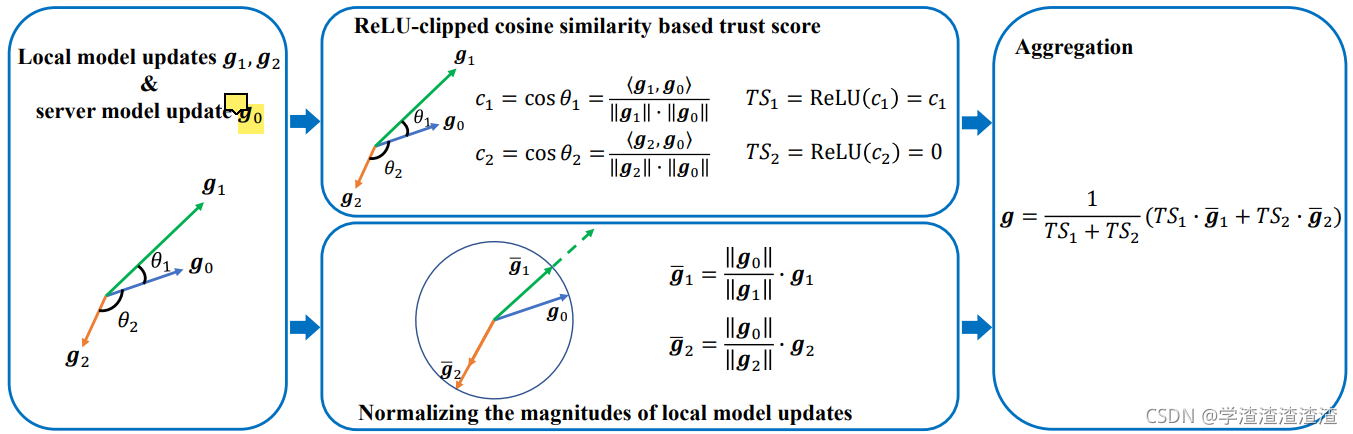
在图中, g 0 g_0 g0 表示 server 端 利用 global model 对 root dataset 计算得到的梯度。
本文的 basic idea :异常的梯度和正常的梯度会有较大的角度偏差。
RELU函数过滤了角度差大于180度的异常梯度,是一个不错的做法。
在中间下面的方框中,还进行了幅值的归一化,防止某一方 scale 了原有梯度,企图获取更大的影响力。
最右边的公式只是在两方(k=2)情况下的举例,实则为:
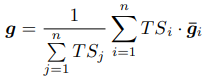
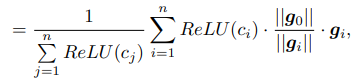
这样一来,和 root 梯度 角度越接近的梯度在聚合时会得到更大的权重,角度相差太大的梯度可能根本不会参与梯度聚合。
整体的算法如下:


这篇关于文献阅读--FLTrust: Byzantine-robust Federated Learning via Trust Bootstrapping的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!