本文主要是介绍OCR EasyOCR + PaddleHub 光学字符识别(Optical Character Recognition, OCR),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
EasyOCR
pip install opencv-python
pip3 install easyocr
简单测试一下
import os
import easyocr
import cv2
from matplotlib import pyplot as plt
import numpy as np
import ssl
ssl._create_default_https_context = ssl._create_unverified_contextIMAGE_PATH = 'Perform-OCR-using-C.jpg'
IMAGE_PATH = 'a.PNG'reader = easyocr.Reader(['en'],gpu=False)
result = reader.readtext(IMAGE_PATH,paragraph="False")
print(result)
问题处理
模型下载
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
# 全局取消证书验证
[easyocr下载模型失败](https://www.cnblogs.com/yqpy/p/14344355.html)
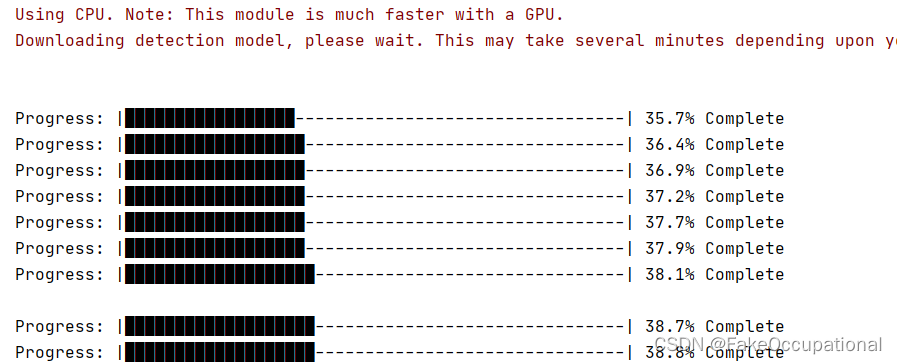
有时不显示下载进度,手动“enter”助力显示:
opencv报错
cv2.error: Unknown C++ exception from OpenCV code
pip install opencv-python==4.1.2.30 -i https://pypi.tuna.tsinghua.edu.cn/simple
代码测试
import os
import easyocr
import cv2
from matplotlib import pyplot as plt
import numpy as np
import ssl
ssl._create_default_https_context = ssl._create_unverified_contextIMAGE_PATH = 'Perform-OCR-using-C.jpg'# https://blog.aspose.com/wp-content/uploads/sites/2/2020/05/Perform-OCR-using-C.jpgreader = easyocr.Reader(['ch_sim'],gpu=False)
result = reader.readtext(IMAGE_PATH,paragraph="False")
print(result)img = cv2.imread(IMAGE_PATH)
top_left = tuple(result[0][0][0])
bottom_right = tuple(result[0][0][2])
text = result[0][1]
font = cv2.FONT_HERSHEY_SIMPLEX
img = cv2.rectangle(img,top_left,bottom_right,(0,255,255),3)
img = cv2.putText(img,text,bottom_right, font, 0.5,(0,255,0),2,cv2.LINE_AA)
plt.figure(figsize=(10,10))
plt.imshow(img)
plt.show()
字体处理
https://ultralytics.com/assets/Arial.ttf
Python图像处理库PIL的ImageFont模块介绍
在如下地址拷贝字体文件到项目:
C:\Windows\Fonts
[官方文档](https://www.easyproject.cn/easyocr/zh-cn/index.jsp#readme)
[代码教程:使用 EasyOCR 从图像中检测文本](https://zhuanlan.zhihu.com/p/413310223)
[添加链接描述](https://pythondict.com/ai/easyocr/)
[视频教程](https://www.bilibili.com/video/BV1x3411Y72t?)
报错
File "C:\Users\user\Anaconda3\lib\site-packages\easyocr\detection.py", line 2, in <module>import torch.backends.cudnn as cudnn ModuleNotFoundError: No module named 'torch.backends'
PaddleHub一键OCR
安装环境
# python环境
conda create --name paddle_env python=3.8 --channel https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ # 安装paddlepaddle 默认安装CPU版本 https://www.paddlepaddle.org.cn/ 不使用vpn
pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple# 安装hub https://github.com/PaddlePaddle/PaddleHub/blob/release/v2.1/README_ch.md
pip install paddlehub -i https://mirror.baidu.com/pypi/simple# 安装模型
hub install chinese_ocr_db_crnn_server==1.1.0
使用
def recognize_text(images=[],paths=[],use_gpu=False,output_dir='ocr_result',visualization=False,box_thresh=0.5,text_thresh=0.5)参数paths (list[str]): 图片的路径;
images (list[numpy.ndarray]): 图片数据,ndarray.shape 为 [H, W, C],BGR格式;
use_gpu (bool): 是否使用 GPU;若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量
box_thresh (float): 检测文本框置信度的阈值;
text_thresh (float): 识别中文文本置信度的阈值;
visualization (bool): 是否将识别结果保存为图片文件;
output_dir (str): 图片的保存路径,默认设为 ocr_result;
返回res (list[dict]): 识别结果的列表,列表中每一个元素为 dict,各字段为:
data (list[dict]): 识别文本结果,列表中每一个元素为 dict,各字段为:
text(str): 识别得到的文本
confidence(float): 识别文本结果置信度
text_box_position(list): 文本框在原图中的像素坐标,4*2的矩阵,依次表示文本框左上,右上,右下,左下顶点的坐标 如果无识别结果则data为[]
save_path (str, optional): 识别结果的保存路径,如不保存图片则save_path为''
import paddlehub as hub
import cv2ocr = hub.Module(name="chinese_ocr_db_crnn_server")
result = ocr.recognize_text(images=[cv2.imread(IMAGE_PATH)])
print(123)
ImportError: This module requires the shapely, pyclipper tools. The running environment does not meet the requirements. Please install the two packages.
pip install shapely
pip install pyclipper
对于图片
https://blog.aspose.com/wp-content/uploads/sites/2/2020/05/Perform-OCR-using-C.jpg
运行1000的时间为212秒
官方教程链接,官方中还有创建网络服务功能。
paddle运行的报错:
The _initialize method in HubModule will soon be deprecated, you can use the __init__() to handle the initialization of the object
W0423 10:10:09.251121 620 analysis_predictor.cc:1350] Deprecated. Please use CreatePredictor instead.
返回值
[{
'save_path': '',
'data': [{'text': '****年**月**日星期* **:**:**', 'confidence': 0.9879583120346069, 'text_box_position': [[58, 33], [1024, 33], [1024, 96], [58, 96]]}, {'text': '*****', 'confidence': 0.9997267723083496, 'text_box_position': [[960, 201], [1480, 189], [1485, 522], [965, 534]]}, {'text': '*****', 'confidence': 0.9997847676277161, 'text_box_position': [[1066, 1230], [1176, 1230], [1176, 1374], [1066, 1374]]}]
}]
'text_box_position': [[58, 33], [1024, 33], [1024, 96], [58, 96]]作为一个方形区域的四角,分别为 左上,右上,右下,左下的顺时针顺序。data = result[0]['data']
这篇关于OCR EasyOCR + PaddleHub 光学字符识别(Optical Character Recognition, OCR)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!