本文主要是介绍SuperGlue: Learning Feature Matching with Graph Neural Networks 论文解析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SuperGlue: Learning Feature Matching with Graph Neural Networks 论文解析
简介
出发点
快速最临近邻搜索(FLANN)算法常常被用于匹配得到最近邻特征点,从而得到图片A和图片B中的特征点的匹配对。但是本文认为,特征点的提取与描述采用复杂的深度学习算法后不再是限制因素,而Naive的匹配方法才是限制其性能的关键点。因此本文在SuperPoint的基础上提出了一种匹配算法,取得了匹配性能的极大改进。
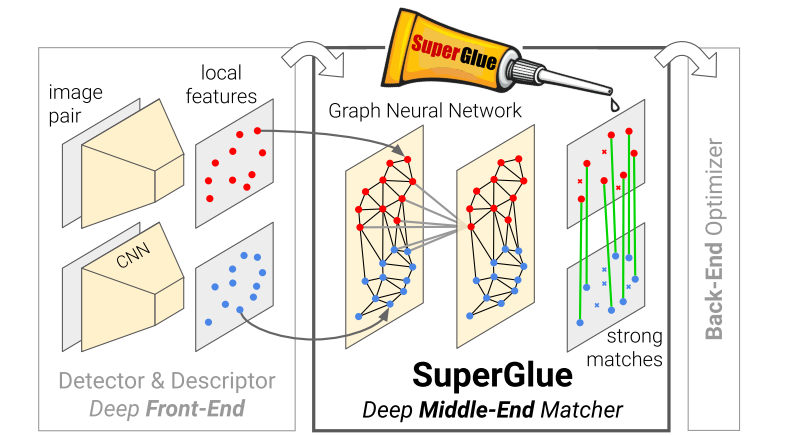
相关工作
-
经典的局部特征匹配流程
- 提取特征点
- 计算视觉描述子
- 最近邻搜索匹配
- 滤除不正确的匹配关系(Lowe’s radio test)
- 计算图片间的几何关系(RANSAC)
-
基于深度学习的匹配
- 改进特征点提取方法
- 改进描述符计算方法
- 依旧采用传统的最近邻搜索方法
-
图搜索
图匹配是一个NP-难的问题,其中和特征点匹配等价的问题为最优搬运问题。该问题可采用Sinkhorn算法进行求解。
- 集合深度学习
难点:特征点的数量和彼此之间的相关关系都是不确定的,难以用传统的卷积方法进行深度学习。
具体的也是参考了一些相关文献,找到了适用于本任务的学习方法
- TODO
- [3] [13] [21] [23] [25] [30] [37] [38] [54] [55] [56] [58] [60] [62] [64]
因此,本文的创新点在于:
- 采用深度学习方法,替换掉传统的最近邻搜索与不正确匹配关系剔除两个步骤
- 采用基于注意力机制的图卷积神经网络提取特征信息
- 采用可微分的分配算法,即Sinkhorn算法,得到匹配结果
方法
理解本文需要有如下的基础知识:
- 图卷积神经网络
- 注意力机制
- 最优搬运问题
图卷积神经网络
图卷积神经网络是目前很火的内容,为了理解本文,需要有如下的相关知识,即网络的计算方式。

- 图网络分为很多层,和普通卷积网络类似
- 图网络每一层中有节点和边,节点和边的连接关系不规则
- 定义卷积操作,即下一层节点的值,为上一层节点连接的所有节点的函数。
x i n + 1 = f ( x 1 n , x 2 n , x 3 n , ⋯ , x m n ) , x 1 → m 为 所 有 与 i 节 点 关 联 的 节 点 x_i^{n+1} = f(x_1^n,x_2^n,x_3^n,\cdots,x_m^n),x_{1\to m}为所有与i节点关联的节点 xin+1=f(x1n,x2n,x3n,⋯,xmn),x1→m为所有与i节点关联的节点- 例如: x 1 2 x_1^2 x12为第二层第一个节点与 x 2 , x 3 x_2,x_3 x2,x3节点相连,因此计算为:
x 1 2 = f ( x 1 1 , x 3 1 , x 4 1 ) x_1^2 = f(x_1^1,x_3^1,x_4^1) x12=f(x11,x31,x41)
- 例如: x 1 2 x_1^2 x12为第二层第一个节点与 x 2 , x 3 x_2,x_3 x2,x3节点相连,因此计算为:
- 通过定义不同的卷积方法 f f f,得到不同类型的图卷积网络,文中借鉴注意力机制定义了卷积方法。
注意力机制
文中通过注意力机制构建了卷积计算方法,所谓的注意力机制即计算如下的权重,然后进行加权求和。
简化版本为:
A = α 1 x 1 + α 2 x 2 + ⋯ + α m x m A=\alpha_1 x_1 + \alpha_2 x_2 + \cdots + \alpha_m x_m A=α1x1+α2x2+⋯+αmxm
其中加权的权重即为注意力的权重,即下一层的信息为上一次相关节点的加权和。
如何确定加权权重呢?注意力机制提出采用查询(query)、关键值(key)以及值(value)机制。

-
首先对每一个节点计算三个值,即 q , k , v q,k,v q,k,v
q i = W 1 x i + b 1 k i = W 2 x i + b 2 v i = W 3 x i + b 3 q_i = W_1 x_i + b_1 \\ k_i = W_2 x_i + b_2 \\ v_i = W_3 x_i + b_3 qi=W1xi+b1ki=W2xi+b2vi=W3xi+b3 -
对每一个节点计算 α j , j \alpha_j,j αj,j为所有连接的节点
-
计算加权和
最优搬运问题
首先看特征点匹配问题描述。
假设存在特征点集合 A , B A,B A,B,其中每一个点与另一个集合所有点的匹配概率组合成得分矩阵 S S S。因此得分矩阵 S S S定义如下:
S m × n = [ S 11 ⋯ S m 1 ⋮ ⋱ ⋮ S 1 n ⋯ S m n ] S_{m \times n}=\left[\begin{array}{cccc} S_{11} & \cdots & S_{m 1} \\ \vdots & \ddots &\vdots \\ S_{1 n} &\cdots & S_{m n} \end{array}\right] Sm×n=⎣⎢⎡S11⋮S1n⋯⋱⋯Sm1⋮Smn⎦⎥⎤
其中, s i , j s_{i,j} si,j为 A A A中第 i i i个点与 B B B中第 j j j个点的匹配概率。
因此定义如下优化问题:
- 优化目标
计算分配矩阵 P P P,使得概率最大(得分最高) - 约束条件
A A A中每个特征点只能匹配 B B B中其中一个特征点或者无匹配
等价于有 A A A集合中的货物,需要搬运到 B B B集合的洞中,一个货物只能放一个洞,一个洞只能放一个货物。
具体的算法参考
网络架构
有了前面的基础,论文中的网络结构则更为容易理解。

主要分为如下几个部分:
- 关键点位置编码
- 基于注意力机制的图卷积网络
- 计算得分矩阵
- 利用得分矩阵 + 最优搬运问题得到分配矩阵
位置编码
将视觉描述子信息和位置信息融合,但是二者维度不一样,因此中间加了一个MLP网络。
x i = d i + MLP e n c ( p i ) x_i = d_i + \text{MLP}_{enc}(p_i) xi=di+MLPenc(pi)
其中,MLP网络具体如下:
包括,位置信息 ( x i , y i ) (x_i,y_i) (xi,yi)和当前点得分 s i s_i si
注意力图卷积神经网络
-
L层网络,每一层包含自相关的图结构和互相关的图结构更新参数。
- Self 层:每个特征点和同一张图片中的其他特征点相连构成图结构
- Cross 层:每个特征点和另一张图片中的特征点相连构成图结构
-
提出这样结构的思想在于模拟人匹配特征点的过程,即看一下 A A A本身的结构,然后看一下 B B B对应的特征点,不断的来回看得到匹配结果。

-
每一层网络的更新公式如下
( ℓ + 1 ) x i A = ( ℓ ) x i A + MLP ( [ ( ℓ ) x i A ∥ m E → i ] ) { }^{(\ell+1)} \mathbf{x}_{i}^{A}={ }^{(\ell)} \mathbf{x}_{i}^{A}+\operatorname{MLP}\left(\left[{ }^{(\ell)} \mathbf{x}_{i}^{A} \| \mathbf{m}_{\mathcal{E} \rightarrow i}\right]\right) (ℓ+1)xiA=(ℓ)xiA+MLP([(ℓ)xiA∥mE→i])
其中, ( ℓ ) x i A { }^{(\ell)} \mathbf{x}_{i}^{A} (ℓ)xiA为当前层数据, ∣ ∣ || ∣∣符号表示两个向量拼接, m E → i \mathbf{m}_{\mathcal{E} \rightarrow i} mE→i为注意力更新向量。
根据上面对注意力的解释,其计算方式为:
m E → i = ∑ j : ( i , j ) ∈ E α i j v j \mathbf{m}_{\mathcal{E} \rightarrow i}=\sum_{j:(i, j) \in \mathcal{E}} \alpha_{i j} \mathbf{v}_{j} mE→i=j:(i,j)∈E∑αijvj
q i = W 1 ( ℓ ) x i Q + b 1 [ k j v j ] = [ W 2 W 3 ] ( ℓ ) x i S + [ b 2 b 3 ] \begin{aligned} \mathbf{q}_{i} &=\mathbf{W}_{1}^{(\ell)} \mathbf{x}_{i}^{Q}+\mathbf{b}_{1} \\ \left[\begin{array}{c} \mathbf{k}_{j} \\ \mathbf{v}_{j} \end{array}\right] &=\left[\begin{array}{l} \mathbf{W}_{2} \\ \mathbf{W}_{3} \end{array}\right](\ell) \mathbf{x}_{i}^{S}+\left[\begin{array}{l} \mathbf{b}_{2} \\ \mathbf{b}_{3} \end{array}\right] \end{aligned} qi[kjvj]=W1(ℓ)xiQ+b1=[W2W3](ℓ)xiS+[b2b3]
得分矩阵计算
网络得到融合了位置信息以及周围其他特征点信息的描述子向量 x i A , x j B x_i^A,x_j^B xiA,xjB
经过一次全连接得到匹配描述子:
f i A = W ( L ) x i A + b , ∀ i ∈ A \mathbf{f}_{i}^{A}=\mathbf{W}^{(L)} \mathbf{x}_{i}^{A}+\mathbf{b}, \quad \forall i \in \mathcal{A} fiA=W(L)xiA+b,∀i∈A
-
计算得分矩阵:
S i , j = < f i A , f j B > , ∀ ( i , j ) ∈ A × B \mathbf{S}_{i, j}=<\mathbf{f}_{i}^{A}, \mathbf{f}_{j}^{B}>, \forall(i, j) \in \mathcal{A} \times \mathcal{B} Si,j=<fiA,fjB>,∀(i,j)∈A×B
直接通过内积计算得到得分矩阵 -
遮挡以及可见性考虑

和SuperPoint采用类似的策略,额外添加一层,其得分概率为固定值。
- 若最后分配矩阵将某点和额外添加层匹配,则认为该特征点是没有匹配上的。
最优搬运问题
计算得到得分矩阵后,就调用现成的算法计算得到匹配矩阵 P P P
实验
面向任务的性能评价
- 单应矩阵估计精度
- 位姿求解精度
单应估计结果

位姿求解结果


总结
在SuperPoint论文中的实验结果表明,算法提取得到的特征点重复率要明显优于传统方法,但是经过最近邻搜索算法算法匹配后得到的结果优势不大。因此,个人认为该实验结果是提出本工作的主要原因,即提出更优的匹配算法,提高SuperPoint匹配结果。
本文相较于传统的特征描述子+最优搬运问题,添加了如下信息
- 特征点位置信息
- 特征点相互之间的信息关联
改进点:
- 直接在提取特征描述子时考虑位置和相互之间的关联信息 + 最优搬运算法得到匹配结果
- 直接端到端学习得到匹配结果,而不用分成好几步
这篇关于SuperGlue: Learning Feature Matching with Graph Neural Networks 论文解析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





