本文主要是介绍DERT(DEtection TRansformer) ONNX直接推理!!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.前言
2. ONNX模型
(1) backbone使用的是resnet50
(2) Transformer结构
(3)模型输出
3.代码展示(不收费!!!)
4.结果展示
5.源代码地址
1.前言
DETR的全称是DEtection TRansformer,是Facebook提出的基于Transformer的端到端目标检测网络,发表于ECCV2020,代码已开源:DETR的github源码。
与之前讲解的VIT ONNX模型不同,VIT是分类模型,同时只用到了transformer的encoder的部分,而DETR是用到了整一个的transformer结构,同时是一个检测模型,具体的可以看下面的图片(本文中大部分图片都来自不灵不灵老师的博文)
 需要看具体的分析请转到不灵不灵老师 的博文,我转出的文档也是基于他的pytorch代码。
需要看具体的分析请转到不灵不灵老师 的博文,我转出的文档也是基于他的pytorch代码。
2. ONNX模型
(1) backbone使用的是resnet50
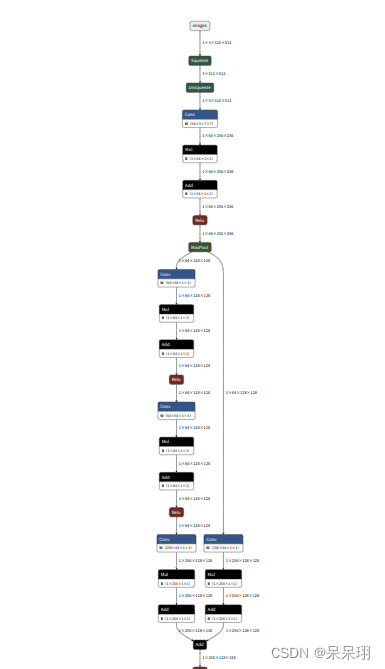

(2) Transformer结构
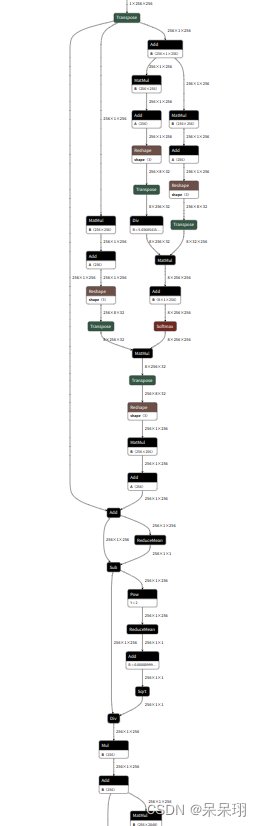
图片太长了,截取不方便
(3)模型输出
"pred_logits":1*100*92,预测的类别
"pred_boxes":1*100*4,预测的box坐标

3.代码展示(不收费!!!)
import numpy as np
import onnxruntime as rt
from PIL import Image
from PIL import ImageDraw, ImageFont
import colorsysdef get_classes(classes_path):with open(classes_path, encoding='utf-8') as f:class_names = f.readlines()class_names = [c.strip() for c in class_names]return class_names, len(class_names)def get_new_img_size(height, width, min_length=600):if width <= height:f = float(min_length) / widthresized_height = int(f * height)resized_width = int(min_length)else:f = float(min_length) / heightresized_width = int(f * width)resized_height = int(min_length)return resized_height, resized_widthdef resize_image(image, min_length):iw, ih = image.sizeh, w = get_new_img_size(ih, iw, min_length=min_length)new_image = image.resize((w, h), Image.BICUBIC)return new_imagedef cvtColor(image):if len(np.shape(image)) == 3 and np.shape(image)[2] == 3:return imageelse:image = image.convert('RGB')return imageclass DecodeBox:""" This module converts the model's output into the format expected by the coco api"""def box_cxcywh_to_xyxy(self, x):x_c, y_c, w, h = x[..., 0], x[..., 1], x[..., 2], x[..., 3]b = [(x_c - 0.5 * w), (y_c - 0.5 * h),(x_c + 0.5 * w), (y_c + 0.5 * h)]return np.stack(b, axis=-1)def forward(self, outputs, target_sizes, confidence):out_logits, out_bbox = outputs["pred_logits"], outputs["pred_boxes"]assert len(out_logits) == len(target_sizes)assert target_sizes.shape[1] == 2prob = np.exp(out_logits) / np.exp(out_logits).sum(-1, keepdims=True)scores = np.max(prob[..., :-1], axis=-1)labels = np.argmax(prob[..., :-1], axis=-1) # 加1来转换为类别标签(背景类别为0)# convert to [x0, y0, x1, y1] formatboxes = self.box_cxcywh_to_xyxy(out_bbox)# and from relative [0, 1] to absolute [0, height] coordinatesimg_h, img_w = np.split(target_sizes, target_sizes.shape[1], axis=1)[0], np.split(target_sizes, target_sizes.shape[1], axis=1)[1]img_h = img_h.astype(float)img_w = img_w.astype(float)scale_fct = np.hstack([img_w, img_h, img_w, img_h])boxes = boxes * scale_fct[:, None, :]outputs = np.concatenate([np.expand_dims(boxes[:, :, 1], -1),np.expand_dims(boxes[:, :, 0], -1),np.expand_dims(boxes[:, :, 3], -1),np.expand_dims(boxes[:, :, 2], -1),np.expand_dims(scores, -1),np.expand_dims(labels.astype(float), -1),], -1)results = []for output in outputs:results.append(output[output[:, 4] > confidence])# results = [{'scores': s, 'labels': l, 'boxes': b} for s, l, b in zip(scores, labels, boxes)]return resultsdef preprocess_input(image):image /= 255.0image -= np.array([0.485, 0.456, 0.406])image /= np.array([0.229, 0.224, 0.225])return imageif __name__ == "__main__":count = Trueconfidence = 0.5min_length = 512image = Image.open('1.jpg')image = image.resize((512, 512))image_shape = np.array([np.shape(image)[0:2]])image = cvtColor(image)image_data = resize_image(image, min_length)image_data = np.expand_dims(np.transpose(preprocess_input(np.array(image_data, dtype='float32')), (2, 0, 1)), 0)# onnx模型前向推理sess = rt.InferenceSession('./model_data/models.onnx')# 模型的输入和输出节点名,可以通过netron查看input_name = 'images'outputs_name = ['output', '4556']# 模型推理:模型输出节点名,模型输入节点名,输入数据(注意节点名的格式!!!!!)net_outs = sess.run(outputs_name, {input_name: image_data})# net_outs = {"pred_logits":torch.tensor(net_outs[0]), "pred_boxes":torch.tensor(net_outs[1])}net_outs = {"pred_logits": net_outs[0], "pred_boxes": net_outs[1]}bbox_util = DecodeBox()results = bbox_util.forward(net_outs, image_shape, confidence)if results[0] is None:print('NO OBJECT')else:_results = results[0]top_label = np.array(_results[:, 5], dtype='int32')top_conf = _results[:, 4]top_boxes = _results[:, :4]font = ImageFont.truetype(font='model_data/simhei.ttf', size=np.floor(3e-2 * image.size[1] + 0.5).astype('int32'))thickness = int(max((image.size[0] + image.size[1]) // min_length, 1))classes_path = 'model_data/coco_classes.txt'class_names, num_classes = get_classes(classes_path)hsv_tuples = [(x / num_classes, 1., 1.) for x in range(num_classes)]colors = list(map(lambda x: colorsys.hsv_to_rgb(*x), hsv_tuples))colors = list(map(lambda x: (int(x[0] * 255), int(x[1] * 255), int(x[2] * 255)), colors))for i, c in list(enumerate(top_label)):predicted_class = class_names[int(c)]box = top_boxes[i]score = top_conf[i]top, left, bottom, right = boxtop = max(0, np.floor(top).astype('int32'))left = max(0, np.floor(left).astype('int32'))bottom = min(image.size[1], np.floor(bottom).astype('int32'))right = min(image.size[0], np.floor(right).astype('int32'))label = '{} {:.2f}'.format(predicted_class, score)draw = ImageDraw.Draw(image)label_size = draw.textsize(label, font)label = label.encode('utf-8')print(label, top, left, bottom, right)if top - label_size[1] >= 0:text_origin = np.array([left, top - label_size[1]])else:text_origin = np.array([left, top + 1])for i in range(thickness):draw.rectangle([left + i, top + i, right - i, bottom - i], outline=colors[c])draw.rectangle([tuple(text_origin), tuple(text_origin + label_size)], fill=colors[c])draw.text(text_origin, str(label, 'UTF-8'), fill=(0, 0, 0), font=font)del drawimage.save('output.png')4.结果展示
 |  |
5.源代码地址
链接: https://pan.baidu.com/s/1Rkh8GI-EZdaS6h7uG4IuFg 提取码: xfen
这篇关于DERT(DEtection TRansformer) ONNX直接推理!!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








