dert专题
RT-DERT改进策略:UniRepLKNet,大核卷积的最新成果,轻量高效的首选(全网首发)
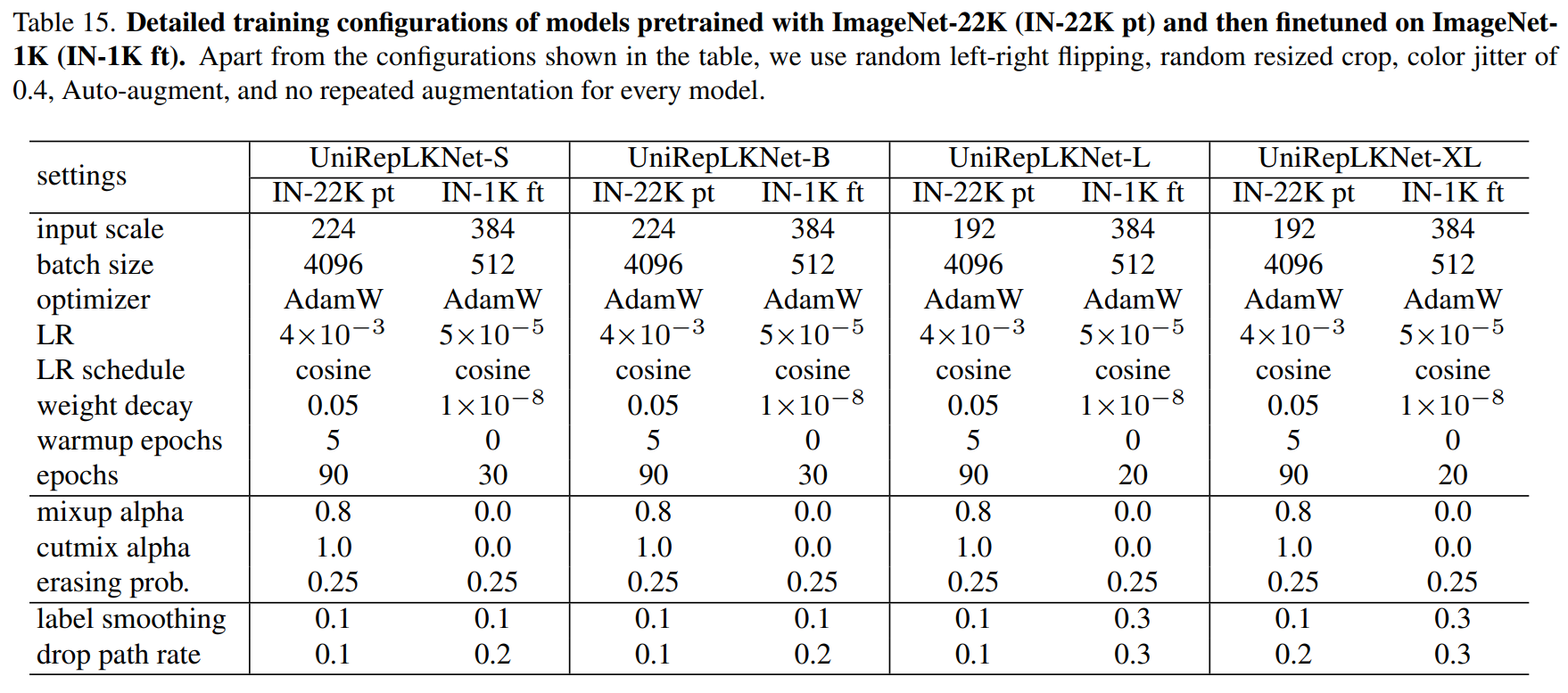
摘要 将UniRepLKNet应用到RT-DERT的改进中,经过测试,涨点明显,运算量也有下降! 论文:《UniRepLKNet:用于音频、视频、点云、时间序列和图像识别的通用感知大内核ConvNet》 https://arxiv.org/abs/2311.15599 大核卷积神经网络(ConvNets)最近受到了广泛的研究关注,但存在两个未解决的关键问题需要进一步研究。(1)现有大核Con

RT-DERT:在实时目标检测上,DETRs打败了yolo
文章目录 摘要1、简介2. 相关研究2.1、实时目标检测器2.2、端到端目标检测器2.3、用于目标检测的多尺度特征 3、检测器的端到端速度3.1、 NMS分析3.2、端到端速度基准测试 4、实时DETR4.1、模型概述4.2、高效的混合编码器4.3、IoU-aware查询选择4.4、RT-DETR的缩放 5、实验5.1、设置5.2、与SOTA方法比较5.3、混合编码器的消融研究5.4、IoU


DERT(DEtection TRansformer) ONNX直接推理!!
目录 1.前言 2. ONNX模型 (1) backbone使用的是resnet50 (2) Transformer结构 (3)模型输出 3.代码展示(不收费!!!) 4.结果展示 5.源代码地址 1.前言 DETR的全称是DEtection TRansformer,是Facebook提出的基于Transformer的端到端目标检测网络,发表于ECCV
dert论文笔记(二)
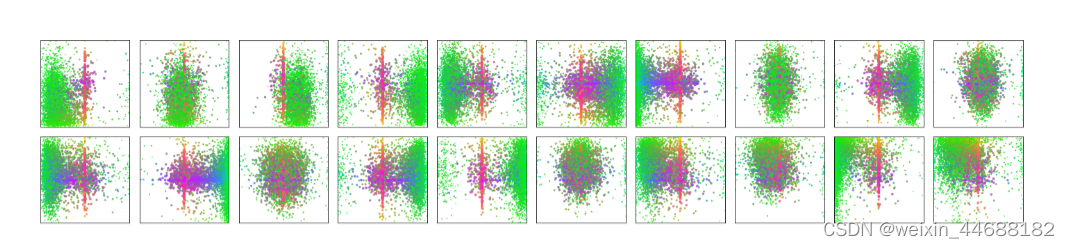
把这个编码器的自注意给可视化出来。我们在每个牛身上找一个基准点,然后我们用这个点和图像上其他点算自注意力,我们会发现他已经做的很好了。已经接近实力分割里面的mask的形状。我们在这个基础上去做decoder 或者目标检测 或者实力分割 任务 都会简单很多。 decoder中也自注意力机制,我们把每个物体自注意力用用不同颜色表现出来。 encorder学的是全局特征,能基本把物体分开,但是这还不够
transformer ViT DERT
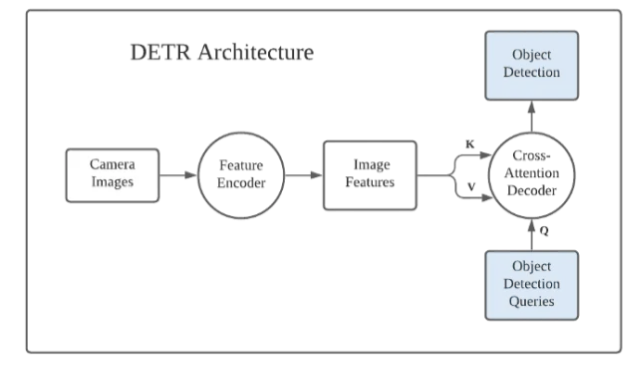
1 transformer Attention Is All You Need https://arxiv.org/abs/1706.03762 NLP 机器翻译 具有全局语义特征提取融合及并行计算的特点。 1.1 整体模型结构 是一个encoder--decoder的结构,最核心的是attention模块。 Transformer 中有两种注意力机制,self-attenti