本文主要是介绍【具身智能】系列论文解读(CoWs on PASTURE VoxPoser Relational Pose Diffusion),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0. My Conclusion
- CoWs on PASTURE: 擅长零样本的视觉语言对象导航,主要解决了LLM辅助下的任务级动作执行任务
- VoxPoser: 擅长设计一些未预定义的动作轨迹,主要解决了LLM辅助下的动作轨迹设计任务
- Relational Pose Diffusion:擅长将已有的动作迁移变换到新场景下的动作,增强机械臂的泛化能力,主要解决了Diff模型辅助下的复杂多变的场景动作轨迹适应能力的任务
1. 牧场中的奶牛:语言驱动的零样本对象导航的基线和基准
Samir Yitzhak Gadre Mitchell Wortsmany Gabriel Ilharcoy Ludwig Schmidty Shuran Song
(2022-12-14) CoWs on PASTURE: Baselines and Benchmarks for Language-Driven Zero-Shot Object Navigation
(0) 摘要
为了使机器人普遍有用,即使没有对域内数据进行昂贵的导航训练(即执行零样本推理),它们也必须能够找到人们描述的任意对象(即由语言驱动)。
我们在统一的环境中探索这些功能:语言驱动的零样本对象导航(L-ZSON)。受到图像分类开放词汇模型最近成功的启发,我们研究了一个简单的框架,CLIP on Wheels (CoW),使开放词汇模型无需微调即可适应此任务。为了更好地评估 L-ZSON,我们引入了 PASTURE 基准,该基准考虑寻找不常见的对象、由空间和外观属性描述的对象以及相对于可见对象描述的隐藏对象。我们通过直接在 HABITAT、ROBOTHOR 和 PASTURE 中部署 21 个 CoW 基线来进行深入的实证研究。总的来说,我们评估了超过 90k 的导航片段,发现 (1) CoW 基线经常难以利用语言描述,但擅长查找不常见的对象。 (2) 一个简单的 CoW,具有基于 CLIP 的对象定位和经典探索,无需额外的训练,与在 HABITAT MP3D 数据上训练 5 亿步的最先进的 ZSON 方法的导航效率相匹配。与最先进的 ROBOTHOR ZSON 模型相比,同一 CoW 的成功率提高了 15.6 个百分点。
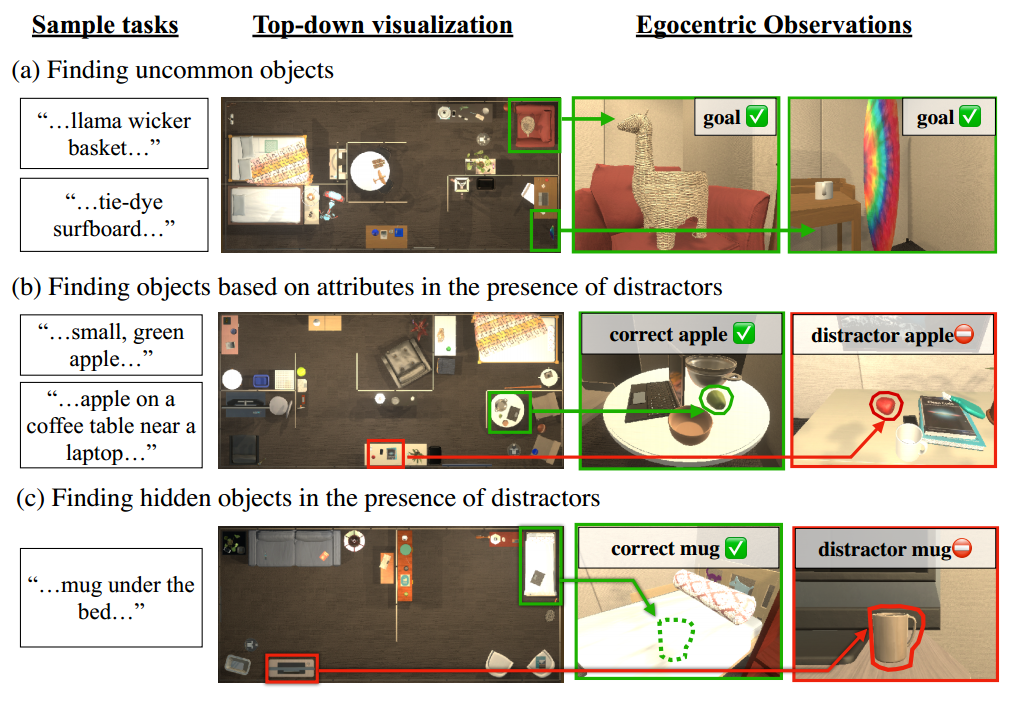
图 1. L-ZSON 的 PASTURE 基准。文本指定导航目标对象。代理不会对这些任务进行训练,从而使评估协议成为零样本。 (a) 不常见的目标目标,例如“美洲驼柳条篮”,在现有的导航基准中找不到。 (b) 外观、空间描述,这是找到正确物体所必需的。 © 隐藏对象描述,定位不可见的对象。
(1) 引言
为了更广泛地应用,机器人应该是语言驱动的:能够根据任意文本输入推断目标,而不是局限于一组固定的对象类别。虽然现有的图像分类、语义分割和对象导航基准,如 ImageNet-1k [61]、ImageNet-21k [21]、MS-COCO [43]、LVIS [27]、HABITAT [63] 和 ROBOTHOR [17] 包括尽管它们涵盖了大量的日常用品,但它们并没有捕捉到所有对人们重要的物品。例如,**丢失的“玩具飞机”**可能与幼儿园教室相关,但该对象未在上述任何数据集中进行注释。
在本文中,我们研究了语言驱动的零样本对象导航(L-ZSON)——一种更具挑战性但也更适用的对象导航版本 [4,17,63,74,83] 和 ZSON [37, 44] 任务。在 L-ZSON 中,智能体必须根据自然语言描述找到一个对象,该对象可能包含不同级别的粒度(例如,“玩具飞机”、“床下的玩具飞机”或“木制玩具飞机”)。 LZSON 包含 ZSON,后者仅指定目标类别 [37, 44]。由于 L-ZSON 是“零样本”,因此我们考虑无法在目标对象或域上进行导航训练的代理。这反映了现实的应用场景,其中环境和对象集可能事先未知。
在任何具有非结构化语言输入的环境中执行 L-ZSON 都是具有挑战性的;然而,图像分类 [34, 55, 57]、对象检测 [3, 20, 26, 35, 41, 45, 47, 58, 82] 和语义分割 [2, 5, 14, 32, 35, 36, 81] 提供了一个有希望的基础。这些模型提供了一个界面,人们可以在其中以文本形式指定他们希望分类、检测或分割的任意对象。例如,CLIP [57] 开放词汇分类器计算输入图像和一组用户指定的标题(例如,“玩具飞机的照片”……)之间的相似度分数,选择具有最高的标题分数来确定图像分类标签。鉴于这些模型的灵活性,我们希望了解它们即使在没有额外训练的情况下执行具体任务的能力。
我们提出了 L-ZSON 的基线和基准。更具体地说:
- 一系列基线算法,CLIP on Wheels (CoW),它使开放词汇模型适应 L-ZSON 的任务。 CoW 从语义映射工作线 [10,40,51] 中获得灵感,当语言目标未可靠本地化时,将导航任务分解为探索,否则分解为目标驱动的规划。 CoW保留了原始开放词汇模型的文本用户界面,并且不需要任何导航训练。我们评估了 21 个 CoW,消除了许多开放词汇模型、探索策略、主干、提示策略和后处理策略。
- 一个新的基准,PASTURE,用于评估 CoW 和 L-ZSON 上的未来方法。我们设计 PASTURE(如图 1 所示)来研究传统对象导航代理所不具备的功能,传统对象导航代理是在一组固定类别上进行训练的。我们考虑以下能力:(1)不常见物体(例如“扎染冲浪板”),(2)在存在干扰物体的情况下通过空间和外观属性找到物体(例如“青苹果”与“红苹果”) ”),以及(3)无法用肉眼观察到的物体(例如,“床下的杯子”)。
CoW 基线和 PASTURE 基准使我们能够在 L-ZSON 具体任务的背景下对开放词汇模型的功能进行广泛的研究。我们的实验证明了 CoW 在不常见物体上的潜力以及充分利用语言描述的局限性,从而为未来的研究提供了实证动力。为了将 CoW 与之前的零样本方法联系起来,我们还对 HABITAT MP3D 数据集进行了评估。我们发现我们最好的 CoW 实现的导航效率 (SPL) 与最先进的 ZSON 方法 [44] 相匹配,该方法在 MP3D 训练数据上训练 5 亿步。在之前的工作中考虑的 ROBOTHOR 对象子集上,相同的 CoW 在任务成功率上击败了领先方法 [37] 15.6 个百分点。
(2) 相关工作
**测绘和探索。**使用移动机器人进行有效探索是视觉和机器人技术中长期存在的问题。经典方法通常将任务分解为地图重建[29,31,49,50,67],代理定位[16,19,52]和规划[40,73]。最近的工作研究了学习的探索替代方案[6,13,53,54,59]。在这里,代理通常通过自我监督奖励(例如好奇心[54])或监督奖励(例如国家访问计数[24,68,70])进行端到端训练。基于学习的方法通常需要较少的手动调整,但需要数百万个训练步骤和奖励工程。我们在 CoW 的背景下测试经典和可学习的探索策略,以研究它们对 L-ZSON 的适用性。

图 2. 轮子夹 (CoW) 概述。 CoW 使用策略来探索,并使用对象定位器(例如开放词汇对象检测器)来确定对象目标是否在视野中。

图 3. 映射。当奶牛在空间中漫游时,根据以自我为中心的深度观察创建自上而下的地图。 (a)基于前沿的探索[77]显示了通往下一个前沿的计划路径探索路径。 (b) 当 CoW 发现对象时,反投影对象相关性分数提供对象目标。
**目标条件导航。**除了开放式探索之外,许多导航任务都是有目标条件的,其中代理需要导航到指定位置(即点目标 [10, 11, 25, 30, 62, 72, 76, 78]),查看环境的(即图像目标 [46, 60, 83])或对象类别(即对象目标 [1, 8, 9, 11, 18, 42, 69, 74, 79])。我们考虑一个对象目标导航任务。
**遵循导航中的说明。**先前的工作研究了基于语言的导航,其中语言为任务提供了逐步说明[33,38,39]。这一系列工作展示了额外语言输入对于机器人导航的好处,特别是对于长视野任务(例如,房间到房间导航[39])。然而,提供详细的分步说明(例如,向南移动 3 米 [33])可能具有挑战性且耗时。相比之下,在我们的 L-ZSON 任务中,算法使用自然语言作为目标描述,而不是低级指令。我们的任务更具挑战性,因为它需要代理推断自己的探索和搜索策略
(3) L-ZSON 任务
语言驱动的零样本对象导航(L-ZSON)涉及导航到用语言指定的目标对象,无需明确的训练即可实现。让 O 表示具有潜在许多属性的目标对象的一组自然语言描述(例如,“植物”、“蛇植物”、“床下的植物”等)。这与研究的定义形成对比在先前的对象导航 [4, 17] 和 ZSON [37, 44] 任务中,这些任务专注于“植物”等高级类别。让S表示导航场景的集合。让 p0 描述代理的初始姿势。导航情节 τ 2 T 被写为元组 τ = (s; o; p0), s 2 S; o 2 O。每个 τ 都是零样本任务,因为在训练期间看不到这种形式的元组。从 p0 开始,具体代理的目标是找到 o。代理接收观察结果和传感器读数 It(例如 RGB-D 图像)。在每个时间步 t,代理执行导航动作 a 2 A。特殊动作 STOP 2 A 终止情节。如果智能体位于 o 的 c 个单位内并且 o 满足可见性标准,则该事件成功。
(4) 车轮上的 CLIP (CoW) 基线
为了解决 L-ZSON,我们研究了一种简单的基线方法 CoW,它采用 CLIP 等开放词汇模型,使其适合该任务。 CoW 将一个以自我为中心的 RGB-D 图像和一个用语言指定的对象目标作为输入。当 CoW 移动时,它会更新使用 RGB-D 观察和姿势估计创建的自上而下的世界地图(第 4.1 节)。每个 CoW 都有一个探索策略和一个零样本对象定位模块,如图 2 所示。为了观察场景的不同视图,CoW 使用策略进行探索(第 4.2 节)。当 CoW 漫游时,它使用对象定位模块(第 4.3 节)及其自上而下的地图来跟踪对目标对象位置的置信度。当 CoW 的置信度超过阈值时,它会计划目标位置并发出 STOP 操作。我们现在描述用于在我们的实验中评估的 CoW 的成分(第 6 节)。
4.1. 基于深度的映射
当 CoW 移动时,它使用输入深度、姿势估计和已知的代理高度构建一个自上而下的地图。使用已知的相机内部函数和第一深度图像来初始化该地图。由于 CoW 知道其动作的预期结果(例如,MOVEFORWARD 应导致 0.25m 的平移),因此每个动作都表示为姿势增量变换以近似转换。为了处理与驱动或深度相关的噪声,CoW 维护分辨率为 0.125m 的地图。
为了提高地图准确性,CoW 通过比较连续深度帧的运动来检查失败的操作(详细信息请参阅附录 A)。使用已知的代理高度 (0.9m),地图单元被投影到地平面,以保持自上而下的世界表示,这足以满足大多数导航应用程序。靠近地板的单元格被认为是自由空间(图3(a)中的白点),而其他单元格被认为是占用的(图3(a)中的蓝点)。
4.2. 勘探
探索会产生不同的以自我为中心的观点,因此 CoW 更有可能查看语言指定的目标对象。我们考虑两种探索方法,基于前沿和基于学习。
**基于前沿的探索(FBE)[77]。**使用第 2 节中讨论的自上而下的地图。 4.1 中,CoW 可以使用简单的探索启发式进行导航:移动到自由空间和未知空间之间的边界以发现新区域。一旦导航器到达边界(如图 3 (a) 中的紫色点所示),它就会贪婪地移动到下一个最近的边界。由于地图在每个时间步都会更新,因此嘈杂的姿态估计可能会导致不准确。例如,由于姿势漂移,狭窄的通道可能会在地图中塌陷。为了避免此类问题,当地图中不存在通往任何边界的路径时,我们会重新初始化地图。
可学习的探索。除了 FBE 之外,我们还研究了可学习的替代方案,这些替代方案可能会更智能地进行探索。我们考虑的架构和奖励结构类似于之前的嵌入式人工智能工作(例如,[24,37,70])。具体来说,我们采用了一个冻结的 CLIP 主干,带有可训练的 GRU [15] 和用于演员和评论家网络的线性头。我们使用 AllenAct [71] 框架中的 DD-PPO [65, 72] 在 HABITAT [63] 和 ROBOTHOR [17] 模拟环境中独立训练智能体,每个环境 60M 步骤。我们采用一种简单的基于计数的奖励[68],自我监督的探索方法经常尝试近似(例如,[6])。所有训练场景与下游导航测试场景不相交;然而,可学习的探索涉及数百万步的模拟训练,而 FBE 启发式不需要这些。有关奖励、超参数和训练的详细信息,请参阅附录。 B.
4.3. 对象定位
成功的导航取决于对象定位:判断对象是否位于图像中以及位于图像中的位置的能力。从 2D 图像中提取的高对象相关性区域被投影到基于深度的地图(图 3 (b)),作为自然导航目标。为了确定目标是否以及何时出现在图像中,我们考虑在实验中使用以下对象定位模块(第 6 节)。有关更多详细信息,请参阅附录。 C。
CLIP [57] 具有 k 个引用表达式。我们将当前观察的 CLIP 视觉嵌入与 k 个不同的 CLIP 文本嵌入进行匹配,这些文本嵌入指定了目标对象的潜在位置。例如,“图像左上角的植物”。 CLIP 计算图像和文本特征之间的相似性,以确定语言指定图像区域的相关性分数。
**CLIP [57] 具有 k 个图像块。**我们将图像离散成 k 个更小的补丁,并对每个补丁运行 CLIP 视觉主干推理以获得补丁特征。然后,我们将每个补丁特征与目标对象的 CLIP 文本嵌入进行卷积。如果对象位于补丁中,则该补丁的相关性得分应该很高。
**CLIP [57] 与梯度相关性 [12]。**我们采用网络可解释性方法 [12, 66] 从视觉变换器 (ViTs) [23] 中提取对象相关性。 Chefer 等人 [12] 使用目标 CLIP 文本嵌入和通过 CLIP 视觉主干积累的梯度信息,在图像像素上构建了一个相关图,从而对目标进行定性分割。这些相关性方法通常假设目标对象是可见的并且标准化在零和一之间。我们观察到,当目标在视野范围内时,消除这种归一化会产生高相关性,否则会产生低相关性,从而为真阳性和真阴性检测提供信号。
MDETR 分割[35]。 Kamath 等人 [35] 扩展了 DETR 检测器 [7],以将任意文本和图像作为输入和输出框检测。他们在 PhraseCut [75](配对掩码和属性描述的数据集)上微调其基本模型,以支持分割。我们使用这个 MDETR 模型直接获取目标的对象相关性。
OWL-ViT 检测[47]。 Minderer 等人 [47] 研究了一种方法,通过对一组预测任务进行微调,将类 CLIP 模型转变为目标检测器。与 MDETR 类似,我们使用 OWL-ViT 直接查询图像中的目标。
**后期处理。**上述模型给出了连续有价值的预测。然而,我们对给出对象是否在图像中以及对象在图像中的位置的二进制掩码感兴趣。因此,我们对每个模型进行阈值预测(有关详细信息,请参阅附录 C)。我们进一步研究了使用下游掩模的两种策略:(1)使用整个掩模或(2)仅使用掩模的中心像素。第二种策略是合理的,因为只需要检测对象的一部分即可成功导航。

图 4. 牧场中不常见的物体。
**目标驱动的规划。**回想一下,奶牛有深度传感器。我们将 2D 图像中的对象相关性反投影到基于深度的地图中(第 4.1 节)。我们只保留每个地图单元格的最大相关性(图 3 (b))。然后奶牛可以规划地图中的高相关性区域。参见附录。 D 用于附加方法可视化。
(5) PASTURE 基准
为了评估 CoW 基线和 LZSON 上的未来方法,我们引入了 PASTURE 评估基准。PASTURE 建立在 ROBOTHOR 验证场景之上,该场景在现实世界中具有并行环境。我们的目标是 ROBOTHOR 促进未来现实世界的基准测试。 PASTURE 探针可实现第 5.1. 节中解释的七种功能。 我们在5.2.中提供数据集统计数据。
5.1. 牧场任务
PASTURE 评估七项核心 L-ZSON 功能。
**不常见的物体。**传统基准(例如 ROBOTHOR 和 HABITAT MP3D)评估智能体在电视等常见对象类别上的表现;然而,鉴于家庭中物体的丰富多样性,我们希望了解不常见物体的导航性能。因此,我们向每个房间添加 12 个新对象。我们使用图 4 中所示的名称作为实例标签,这是识别每个对象的最小描述。一些标识符引用图像中的文本(例如,“白板写着 CVPR”)或外观属性(例如,“木制玩具飞机”)。其他物品在北美不太常见,例如“马黛茶”,这是一种流行的阿根廷饮料。
**外观描述。**为了评估基线是否可以利用视觉属性,我们引入了以下形式的描述:“fsizeg,fcolorg,fmaterialg fobjectg”。例如:“小红苹果”、“橙色篮球”、“小黑金属闹钟”。如果对象的 3D 边界框对角线低于阈值,则对象被视为较小。我们通过检查确定颜色和材料。
**空间描述。**为了测试智能体是否可以在导航中利用空间信息,我们引入了描述:“fobjectg 在 fxg 之上,靠近 fyg,fzg,…”。例如,“梳妆台上靠近喷雾瓶的室内植物”。为了确定关系,我们使用 THOR 元数据;为了确定关系,我们使用对象对之间的距离阈值。我们检查所有描述的正确性。
带有干扰因素的外观描述。为了探究外观属性是否能更好地促进在存在干扰物的情况下查找对象,我们重用之前的外观标题,但在修改后的环境中评估每个 ROBOTHOR 对象类别的两个视觉上不同的实例。例如,对于寻找“红苹果”的任务,我们房间里既有红苹果,也有绿苹果。导航员必须利用外观信息(而不仅仅是类别信息)才能成功完成任务。
**带有干扰因素的空间描述。**这个能力和上面的类似;然而,我们在存在干扰对象的情况下通过空间描述进行评估。
**隐藏对象描述。**理想的对象导航器应该找到对象,即使它们是隐藏的。为了测试此功能,我们引入了描述:“fobjectg under/in fxg”。如,“梳妆台抽屉里的篮球”或“沙发下的花瓶”。我们对每个场景中的大型物体(例如床、沙发、梳妆台)进行采样,以确定[下/内]关系。此外,我们从房间中删除了 fobjectg 的可见实例。
**带有干扰因素的隐藏物体描述。**我们使用之前的隐藏对象描述,但重新引入 fobjectg 的可见实例作为干扰项。考虑在床下找一个“杯子”。场景中还会出现一个分散注意力的杯子,使任务更具挑战性。
5.2. 数据集创建和统计
PASTURE 包含原始 15 个验证 ROBOTHOR 房间中每个房间的三个变体:添加不常见的对象、添加其他对象实例和删除目标对象。对于上述 7 个设置中的每一个,我们评估 15 个房间中的 12 个以上对象实例,并具有两个初始代理起始位置。因此,PASTURE 由 2,520 个任务组成,与 ROBOTHOR (1,800) 和 HABITAT MP3D (2,195) 验证集的数量级相似。对于外观属性,47% 的对象被认为是“小”。每个对象从 22 种可能的选择中平均获得 1.2 个颜色描述符,从 5 种可能的选择中平均获得 0.6 个材质描述符。类似地,对于空间属性,每个对象都会获得其上方或其中的一个对象(例如,“搁架单元中的花瓶”)以及其附近的平均 1.9 个对象。有关外观和空间属性的示例,请参见图 1。有关更多数据集详细信息和统计数据,请参见 Appx。 E.
(6) 实验
我们首先介绍我们的实验设置,包括我们研究中考虑的数据集、指标、实施例和基线(第 6.1 节)。然后我们在 PASTURE 上展示结果,从而阐明 L-ZSON 的 CoW 基线的优点和缺点(第 6.2 节)。最后,我们与 ROBOTHOR 和 HABITAT (MP3D) 环境中的现有 ZSON 技术进行比较(第 6.3 节)。
6.1. 实验设置
环境。我们将 PASTURE(第 5 节)、ROBOTHOR [17] 和 HABITAT (MP3D) [63] 验证集视为我们的测试集。我们利用验证集进行测试,因为官方测试集的基本事实不公开。域设置的噪声忠实于其原始挑战设置。对于 ROBOTHOR 以及扩展后的 PASTURE 来说,这意味着驱动噪声,但没有深度噪声。对于 HABITAT 来说,这意味着相当大的深度噪声和重建伪影,但没有驱动噪声。
**导航指标。**我们采用标准对象导航指标来衡量性能: • 成功 (SR):代理在目标对象 1.0m 范围内执行 STOP 的事件比例。
-
逆路径长度(SPL) 加权的成功:按预言机最短路径长度加权的成功,并按实际路径长度进行归一化[4]。该指标反映了代理的成功效率。
-
在《ROBOTHOR》和《牧场》中,目标必须可见才能使剧集成功,而《栖息地》中的情况并非如此——正如他们在 2021 年挑战中所指定的那样。
**实例化。**代理是 LoCoBot [28]。所有代理都有离散动作:fMOVEFORWARD、ROTATERIGHT、ROTATELEFT、STOPg。移动动作使代理前进 0.25m,而旋转动作使摄像机旋转 30°。
**CoW 基线。**为了进行探索,我们考虑第 2 节中提出的政策。 4.2:FBE启发式探索,在HABITAT(MP3D)火车场景上优化的可学习探索,在ROBOTHOR火车场景上优化的学习探索。学习探索需要模拟训练——这与我们的零样本目标背道而驰;尽管如此,我们还是消除了这些探索者,以便将他们的表现融入到 CoW 框架中。 FBE 是默认的 CoW 探索策略。
对于对象定位,我们考虑:
- k = 9 引用表达式的 CLIP (CLIP-Ref.)
- k = 9 补丁的 CLIP (CLIP-Patch)
- 具有梯度相关性的 CLIP (CLIP-Grad.) • MDETR 分割模型 (MDETR) )
- OWL-ViT 检测器 (OWL) 这些模型的描述在第 2 节中。
其他详细信息参见4.3节的附录C。 所有模型都是开放词汇的。没有模型在导航上进行微调,因此我们认为它们对我们的任务的推理是零样本的。我们还考虑了各种主干架构:
-
视觉变换器[23],ViT-B/32 (NB/32)
-
ViT-B/16 (B/16),它使用更小的补丁大小16x16,因此需要更多计算。
-
EfficentNet B3 (B3),它是卷积网络,其计算要求与 ViT/B32 类似。
对于每个模型,我们还使用后处理进行评估 ( △ , □ , ⋄ ) (\triangle, \square, \diamond) (△,□,⋄),其中仅检测的中心像素被注册在自上而下的 CoW 图中。回想一下,这是一个明智的策略,因为只需要找到对象的某些部分即可使情节成功。有关超参数、学习代理、对象定位阈值调整和 CLIP 提示调整的详细信息,请参阅 Appx的C、F。
**端到端的可学习基线。**我们还与以下方法进行比较,这些方法经过数百万步的模拟训练:
-
EmbCLIP-ZSON [37]:使用 CLIP 语言嵌入来指定目标对象,在八个 ROBOTHOR 类别上训练模型。在测试时,模型根据四个保留的对象类别进行评估。未见过的目标对象是使用 CLIP 语言嵌入用类别名称指定的。
-
SemanticNav-ZSON [44]:单独训练模型(每个数据集一个)用于图像目标导航,其中图像目标通过 CLIP 视觉嵌入指定。在测试时,图像目标与对象目标的 CLIP 语言嵌入进行切换。我们与 MP3D 训练模型进行比较。
EmbCLIP-ZSON 和 SemanticNav-ZSON 都在需要模拟训练的可学习框架中利用多模式 CLIP 视觉和语言嵌入。
6.2.牧场选项卡上的奶牛。
表 1 显示了在 PASTURE 上评估 18 头奶牛的结果。对于类别级别的结果,请参阅附录。 G. 我们现在讨论几个突出问题。
表 1. L-ZSON 牧场上奶牛的基准测试。**在 PASTURE 上,我们确定了几个关键要点。 **(1) PASTURE 上的平均成功率低于 ROBOTHOR 上的平均成功率;**然而,奶牛在寻找不常见物体方面出人意料地擅长(Uncom.),通常比更常见的 ROBOTHOR 物体发现它们的速度更高。 (2) 比较填充的 ( ∙ \bullet ∙) 与未填充的 ( ◯ ) (\bigcirc) (◯)行 ID,我们注意到仅使用中心像素作为导航的代表性目标来进行后处理掩模预测通常会有所帮助(有关后处理的更多详细信息,请参阅第 4.3 节) )。 (3) 比较正方形与三角形ID,我们发现使用更多计算的架构 (Arch.)(即 ViT-B/16)通常性能与竞争对手(即 ViT-B)相当或更差/32)。对于 CLIP [57] 模型(以粉色、橙色和紫色表示)尤其如此。 (4) Blue OWL-ViT [47] 模型表现最好。 (5) 具有干扰对象(分散注意力)的 PASTURE 任务会损害性能,并且自然语言规范不足以减轻这些任务中增加的困难。 (6) 以灰色显示的监督基线在 ROBOTHOR 上显着优于 CoW;但是,它无法支持开箱即用的 PASTURE 任务。
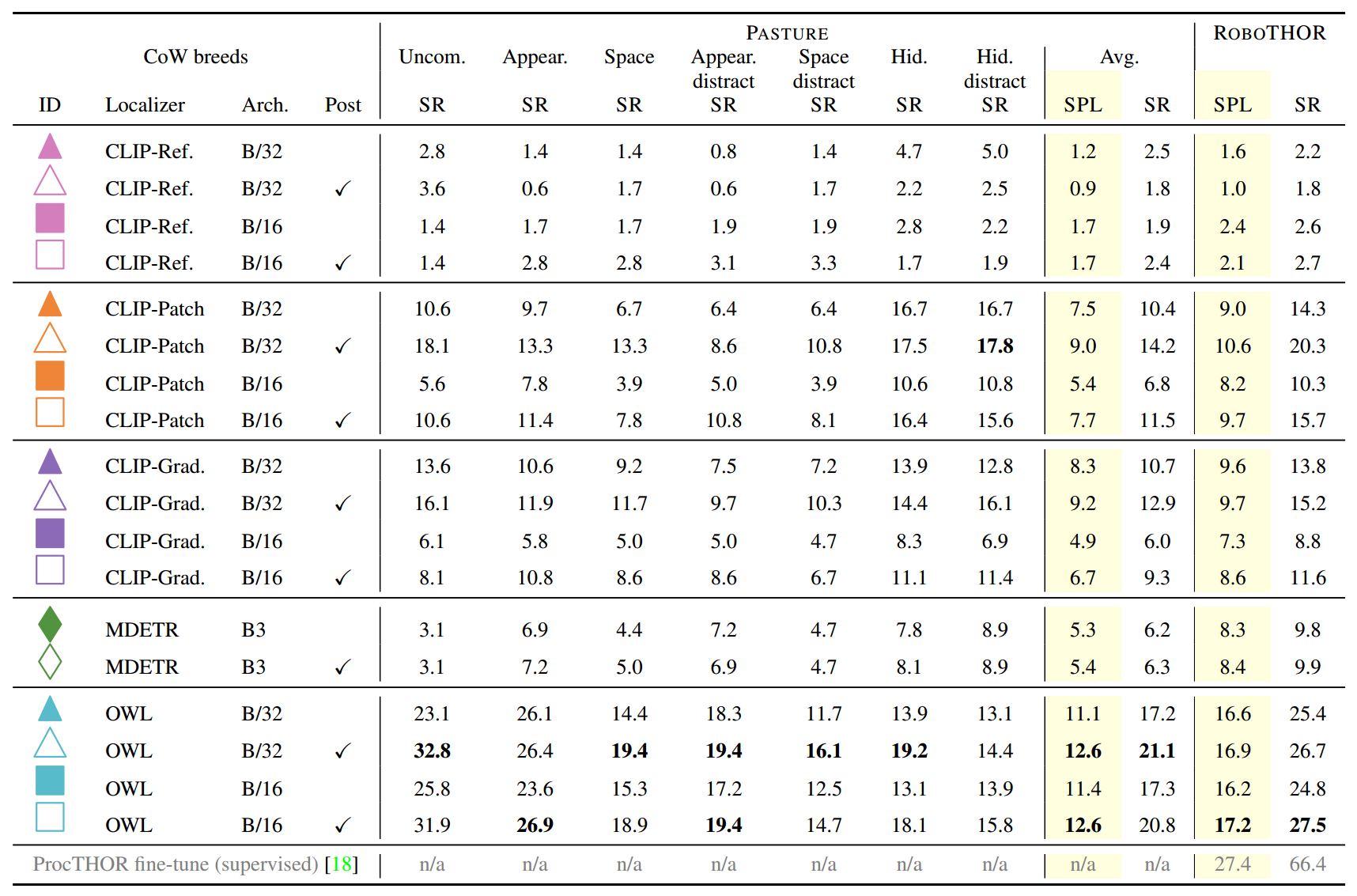
**奶牛找到常见物体与不常见物体的能力如何?**表 1 比较 ROBOTHOR 和罕见 (Uncom.) PASTURE 的成功率 (SR)。图 1(第一列和最后一列)我们注意到,CoW 发现不常见物体的速度通常比常见的 ROBOTHOR 物体高(例如,使用后期处理 (4) 的 OWL ViTB/32 CoW 的成功率高约 6 个百分点)。我们假设,虽然不常见的对象在日常生活中不太常见,但它们仍然在开放词汇数据集中表示,因此可以被对象定位模块识别。我们在 Appx 中进一步探讨了这个假设。 E 通过可视化 LAION-5B [64] 上不常见物体类别的 CLIP 检索结果。在不常见对象上相对较高的性能说明了 CoW 基线的灵活性及其从开放词汇模型继承所需属性的能力。
**CoW 可以利用外观和空间描述吗?**从==图 5 (a)==可以看出,与 ROBOTHOR 基线性能相比,外观和空间描述都没有改善 CoW 性能(即大多数点位于 y = x 线下方)。然而,CoW 能够比空间描述更好地利用外观描述。这些结果激发了未来对开放词汇对象定位的研究,更加关注文本对象属性。
**在存在干扰物的情况下,奶牛能否找到可见物体?**在==图 5 (b) 中,我们看到与图 5 (a) ==相比,CoW 的性能进一步下降。我们的结论是,指定为自然语言输入的外观和空间属性不足以处理给定当前开放词汇模型的干扰因素增加的复杂性。
**奶牛能找到隐藏的物体吗?**观察图 5 ©,我们注意到,成功率较低的模型(ROBOTHOR 上的成功率低于 15%)能够以与 ROBOTHOR 对象大致相同的速度找到隐藏对象(即,它们位于 y = x线)。较高成功率 (>15%) 的 OWL 模型不会延续这一趋势;然而,如表 1 所示,它们确实实现了更高的绝对精度。 1. 处理遮挡是计算机视觉中长期存在的问题,这些结果为未来隐藏对象导航工作的改进奠定了基础。
**哪种探索方法效果最好?**我们通过修复对象定位器(OWL,B/32,带有后处理(4))并与表中的 ROBOTHOR 可学习探索和 HABITAT 可学习探索进行比较,在==表2==取消了在大多数实验中使用 FBE 的决定。 我们注意到 FBE 在所有情况下都表现最佳;然而,可学习的探索仍然表现良好,这表明这些模型确实为下游任务学习了有用的策略。此外,HABITAT 学习模型的较差性能表明,在某个领域进行训练可能会对其他领域的推理造成损害(即,HABITAT -!ROBOTHOR 或 HABITAT -!PASTURE)。未来的工作可能会重新考虑基于学习的导航算法,这些算法在分布外表现良好(即“sim2real”和“sim2sim”探索转移,如[25]中所示)。
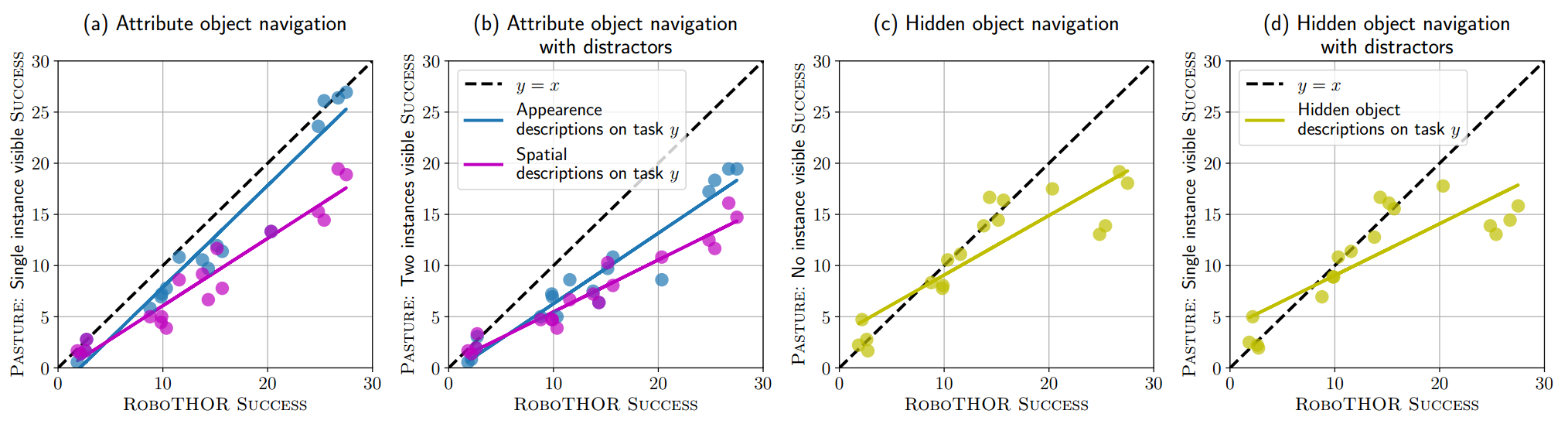
图 5. PASTURE 对象导航及描述。一般来说,带有描述的对象导航比 ROBOTHOR 对象导航任务更具挑战性,如 y = x 线下方的趋势线所示。 (a) 外观描述比空间描述更有帮助。 (b) 当干扰物体被引入环境中时,性能进一步下降。然而,与空间描述相比,CoW 仍然能够更好地利用外观描述。 © 较低成功率(<15% ROBOTHOR SUCCESS)的模型在寻找隐藏物体方面表现相当。然而,对于更成功的车型来说,这种趋势趋于稳定。 (d) 当引入干扰对象进行隐藏对象导航时,趋势相似。
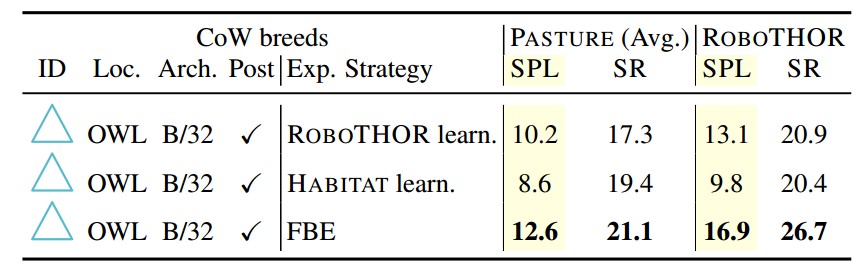
**表 2. 探索消融。**对于固定对象定位器(带有后处理的 OWL-ViT B/32),我们消除了不同的探索策略选择:FBE 启发式、在 ROBOTHOR 中训练的代理和 HABITAT (MP3D)。我们发现 FBE 在 PASTURE 和 ROBOTHOR 上都优于可学习的替代方案。HABITAT 可学习模型表现最差,但未接受任何 PASTURE 或 ROBOTHOR 数据的训练。
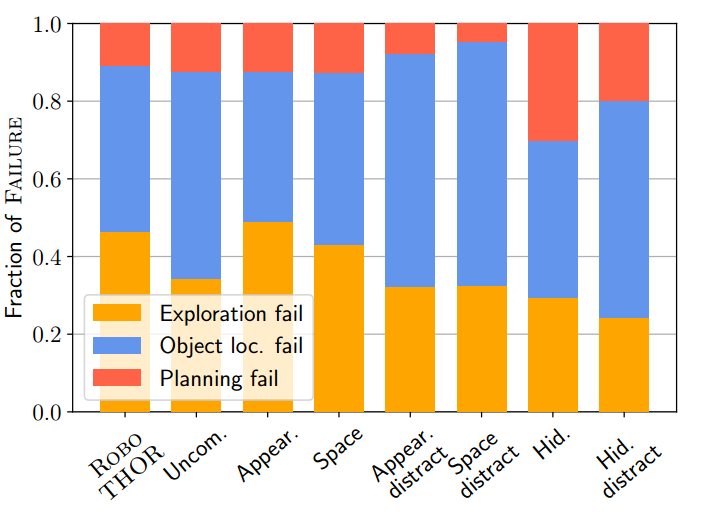
图 6. OWL、B/32、后处理的故障分析 ( △ \triangle △)。探索和对象定位错误的发生率相似,但在存在干扰物的情况下,定位失败会增加。
**奶牛是如何失败的?**我们确定了三种高级故障模式。 (1) 探索失败:从未见过目标。 (2) 对象定位失败:看到目标但定位器从未触发。 (3) 规划失败:看到目标并且定位器开火,但由于地图表示不准确而导致规划失败(第 4.2 节)。查看图 6,我们注意到很大一部分失败是由于探索和对象定位造成的。这表明随着这些领域研究的进展,奶牛可能会继续改进。在图 6 中,我们还看到,在存在干扰因素的情况下,对象定位失败的比例更高,这支持了开放词汇模型目前难以充分利用属性提示的说法。参见附录。 H 用于附加故障分析。
6.3.与现有技术的比较
虽然我们的主要目标是评估一般 L-ZSON 设置中的 CoW,但我们进一步评估 ZSON 设置中的 CoW,之前的工作考虑将 CoW 建立为这些任务的强大基线。回想一下,ZSON 可以看作是 L-ZSON 的特例,其中仅用语言指定对象目标(无属性)。
在选项卡中。在图 3 中,我们看到存在一个 CoW,它在除 HABITAT (MP3D) 上的 SemanticNavZSON SUCCESS 之外的所有情况下都优于端到端基线。例如,具有后处理 (4) 的 CLIP-Grad.、B/32 与 HABITAT (MP3D) SPL-4.9 上的 SemanticNav-ZSON 模型相匹配(CoW 与 CoW 对比)。竞争对手的得分为 4.8,同时也比 EmbCLIP-ZSON ROBOTHOR 提高了 15.6 个百分点。为了说明这一结果的重要性,我们重申该 CoW 训练了 0 个导航步骤,而 SemanticNav-ZSON 和 EmbCLIP-ZSON 在目标评估模拟器中分别训练了 500M 和 60M 步骤。
SemanticNav-ZSON 在 MP3D SUCCESS 方面的卓越性能表明,域内学习比 CoW 基线有优势。未来的工作可能会考虑将类 CoW 模型和微调模型的优点结合起来,以获得两全其美的效果。
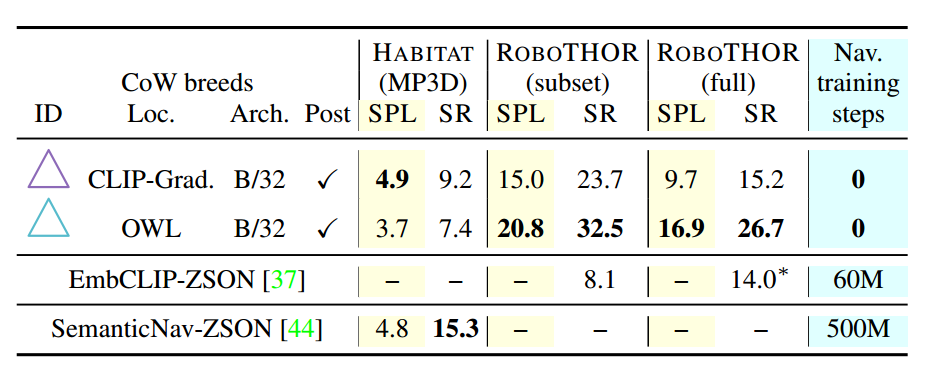
表 3. 现有 ZSON 基准与现有技术的比较。奶牛能够匹配或超越现有的方法,这些方法利用评估模拟器中的数百万步导航训练。 * 表示先前工作的结果,包括非零样本评估。具体来说,1/4 的评估在 ROBOTHOR(子集)上是零样本,其余 3/4 在训练期间看到的类别上。
(7) 局限性和结论
**局限性。**虽然我们在栖息地、机器人和牧场上对奶牛的评估是评估它们在不同领域表现的一步,但最终,现实世界的表现才是最重要的。因此,我们工作的最大限制是缺乏大规模的、现实世界的基准测试——这在许多相关文献中也是缺失的。此外,CoW 固有的对象定位和探索方法的元限制。例如,对象定位器需要调整置信度阈值以平衡精度和召回率。
最后,我们不考虑不同的代理体现或连续的动作空间。鉴于 Pratt 等人的最新发现[56],药剂形态可能是下游性能的一个重要决定因素,这是一项相关的研究。
**结论。**本文介绍了语言驱动的零样本对象导航的 PASTURE 基准和几个 CLIP on Wheels 基线,将现有零样本模型的成功转化为具体任务。我们将 CoW 视为使用开放词汇模型和基于文本的界面来在更灵活的环境中处理机器人任务的实例。我们希望基线和拟议的基准能够刺激该领域探索更广泛、更强大的零样本人工智能形式。
2. VoxPoser:使用语言模型进行机器人操作的可组合 3D 值图
(2023-07-12) VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
https://arxiv.org/abs/2307.05973
大型语言模型(LLM)被证明拥有丰富的可操作知识,可以以推理和规划的形式提取用于机器人操作。尽管取得了进展,但大多数仍然依赖预定义的运动基元来执行与环境的物理交互,这仍然是一个主要瓶颈。在这项工作中,我们的目标是合成机器人轨迹,即 6-DoF 末端执行器路径点的密集序列,用于在给定开放指令集和开放对象集的情况下执行各种操作任务。
我们首先观察到LLM擅长在自由形式的语言教学中推断可供性和约束,从而实现这一目标。更重要的是,通过利用其代码编写能力,他们可以与视觉语言模型 (VLM) 交互以组成 3D 值图,将知识融入代理的观察空间中。然后,将组合的值图用于基于模型的规划框架,以零样本合成具有动态扰动鲁棒性的闭环机器人轨迹。我们进一步展示了所提出的框架如何通过有效地学习涉及丰富接触交互的场景的动态模型来从在线体验中受益。我们在模拟和真实机器人环境中对所提出的方法进行了大规模研究,展示了执行以自由形式自然语言指定的各种日常操作任务的能力。项目网站:voxposer.github.io。

图 1:VOXPOSER 从 LLM 中提取语言条件可见性和约束,并使用 VLM 将它们置于感知空间,使用代码接口,无需对任一组件进行额外培训。合成的地图被称为 3D 值地图,它能够通过开放的指令集和开放的对象集对各种日常操作任务的轨迹进行零样本合成。
(1)引言
语言是一种压缩媒介,人类通过它提炼和交流他们的知识和世界经验。大型语言模型 (LLM) 已成为捕捉这种抽象的一种有前途的方法,通过投影到语言空间来学习表示世界 [1-4]。虽然这些模型被认为以文本形式内化了可概括的知识,但如何使用这种可概括的知识来使实体主体能够在现实世界中进行实际行动仍然是一个问题。
我们研究机器人动作中抽象语言指令(例如“摆桌子”)的基础问题[5]。之前的工作利用词法分析来解析指令[6-8],而最近的语言模型被用来将指令分解为步骤的文本序列[9-11]。然而,为了实现与环境的物理交互,现有方法通常依赖于可由LLM或规划者调用的手动设计或预先训练的运动原语(即技能),并且这种依赖于个人技能的获取由于缺乏大规模的机器人数据,通常被认为是系统的主要瓶颈。那么问题来了:我们如何才能在机器人的更细粒度的动作层面上利用LLM丰富的内化知识,而不需要为每个单独的原语进行繁琐的数据收集或手动设计?
3. 搁置、堆叠、悬挂:用于多模态重新排列的关系姿势扩散
(2023-07-10) Shelving, Stacking, Hanging: Relational Pose Diffusion for Multi-modal Rearrangement
https://arxiv.org/abs/2307.04751
我们提出了一种重新排列场景中的对象以实现所需的对象场景放置关系的系统,例如插入书架的开放槽中的一本书。该管道可推广到场景和对象的新颖几何形状、姿势和布局,并通过演示进行训练,直接在 3D 点云上操作。我们的系统克服了给定场景中存在许多几何相似的重排解决方案所带来的挑战。通过利用迭代姿态去噪训练程序,我们可以拟合多模态演示数据并产生多模态输出,同时保持精确和准确。我们还展示了调节相关局部几何特征的优点,同时忽略不相关的全局结构,这会损害泛化和精度。我们在三个不同的重新排列任务上展示了我们的方法,这些任务需要处理模拟和现实世界中对象形状和姿势的多模态和泛化。项目网站、代码和视频:https://anthonysimeonov.github.io/rpdiff-multi-modal

图 1:通过学习一组重新排列任务的演示,例如将书放在书架上 (A) 并将杯子挂在架子上 (B),关系姿势扩散 (RPDiff) 可以产生多种变换,从而实现新的对象/场景对具有相同的对象-场景关系。
(1)引言
考虑图 1,它说明了 (1) 将一本书放在部分装满的书架上,以及 (2) 将一个杯子挂在桌子上的多个架子之一上。这些任务涉及推理对象和场景之间的几何交互以实现目标,这是机器人社区感兴趣的许多清理和整理任务的关键要求[1]。在这项工作中,我们使机器人系统能够执行一系列重要的此类任务:刚性物体的 6 自由度重新排列 [2]。我们的系统使用从深度相机获得的点云,允许在未知的 3D 几何形状的现实世界中进行操作。重新排列行为是从显示所需的对象场景关系的示例数据集中学习的 - 观察场景和(分段的)对象点云,并且演示器将对象转换为最终配置。
这篇关于【具身智能】系列论文解读(CoWs on PASTURE VoxPoser Relational Pose Diffusion)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





