本文主要是介绍Versal系列0-AI Engine与Systolic Array,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
最近在开发VCK190时,发现Xilinx Versal系列的AI engine(AIE),其实和Systolic Array(SA)有着很相似的地方。Xilinx工程师在研发AIE时,应该是有所借鉴SA的。
Systolic Array最早是H. T. Kung于1982年在论文《Why systolic architectures?》中提出,但是由于过于过于专用性,在通用处理器当道的年代并没有得到许多的关注。随着人工智能的火热,各种硬件加速器的设计不断涌现,谷歌的TPU就重新使用起了Systolic Array来做AI里最常用的矩阵乘法操作。许多AI模型部署的硬件加速器也都采用了SA做主要算子。

Why systolic architectures?
Systolic Array
在做矩阵乘法时,一般的方法是将矩阵的行和列从存储元件(DDR、BRAM、cache)中取出来,做完运算后再将其返回DDR中。而存储单元消耗的带宽是有限的,通常比计算单元速度慢很多,因此,访存的带宽成了整个系统的瓶颈。如果能每次在取出数据后,尽量做尽可能多的操作,让数据的利用率尽可能大,就能显著提升整个系统的速度。
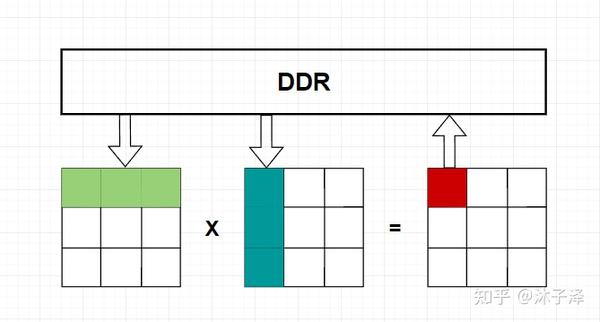
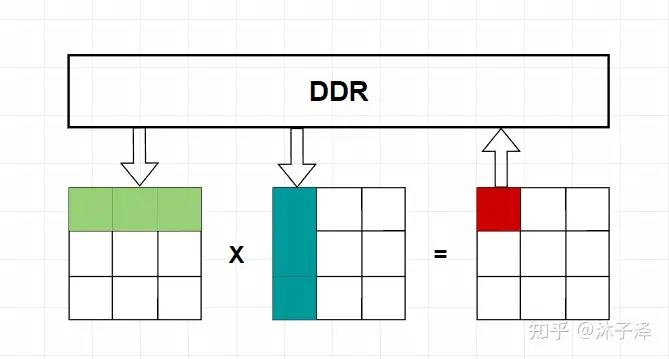
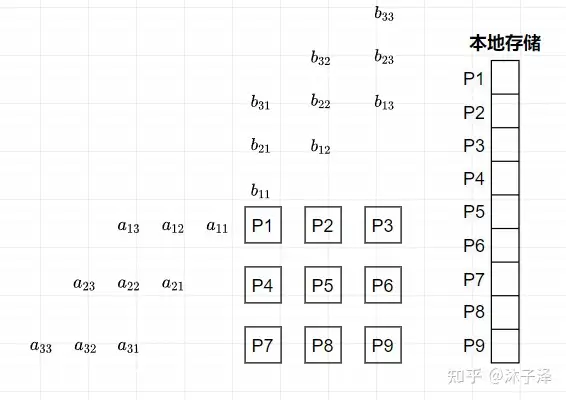
Systolic Array就是这样一个能显著提升矩阵乘法性能的硬件架构。它只需要从存储元件中取出一次元素,就能将整个矩阵计算完成。以3x3的方阵乘法为例,A矩阵与B矩阵相乘得到C矩阵:
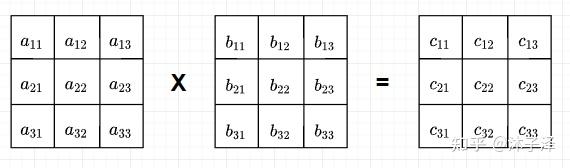
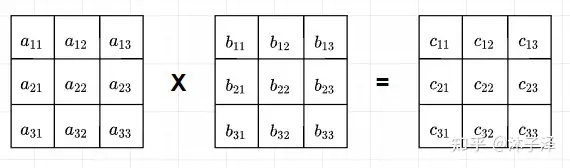
用于计算此矩阵乘法的SA也包含3x3个Processing Element(PE),每个PE的完成的操作就是将做个矩阵的乘法并放入自己的局部存储中(Local Memory)。在初始时刻,先将A矩阵的列翻转,B矩阵的行翻转,并按照A每一行晚一拍,B每一列晚一拍进入SA的顺序放置。每个PE的本地存储当前都是空的。

然后矩阵元素 a11c_{13} ...
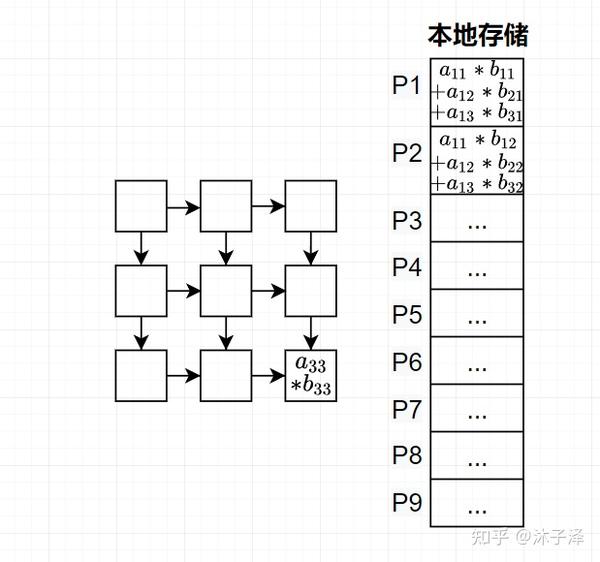
Systolic Array在整个矩阵的运算中只需要在开始访问存储器得到A和B矩阵的元素,每次运算不需要重新访存,就可以传递给下一个PE,从而克服了访存对速度的限制。
AI Engine
AI Engine是Xilinx Versal系列器件里新添加的硬核,每个AIE都是个32位RISC微处理器,如VCK190上嵌入了400个这样的硬核,因此能提供非常庞大的算力,来满足AI等场景下的要求。
类似SA,AIE也是形成一个阵列[1],从下图中可以看到,它也有局部的存储(灰色块),也有类似SA的计算单元(绿色块)。并且也会有互联的总线逻辑(蓝色,绿色与黑色线)。这种架构能让计算逻辑更快得访问Memory,互联逻辑也能让AIE访问相邻AIE的Memory。
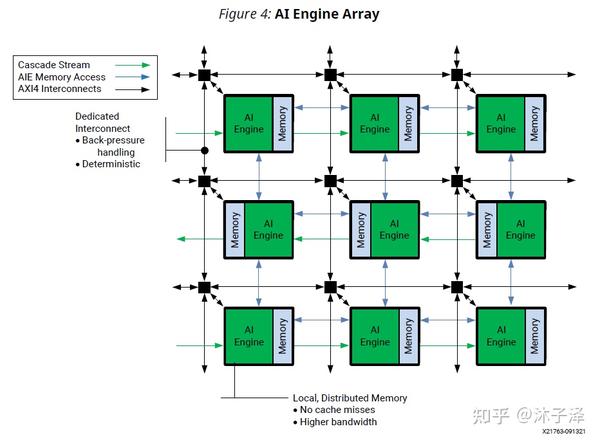
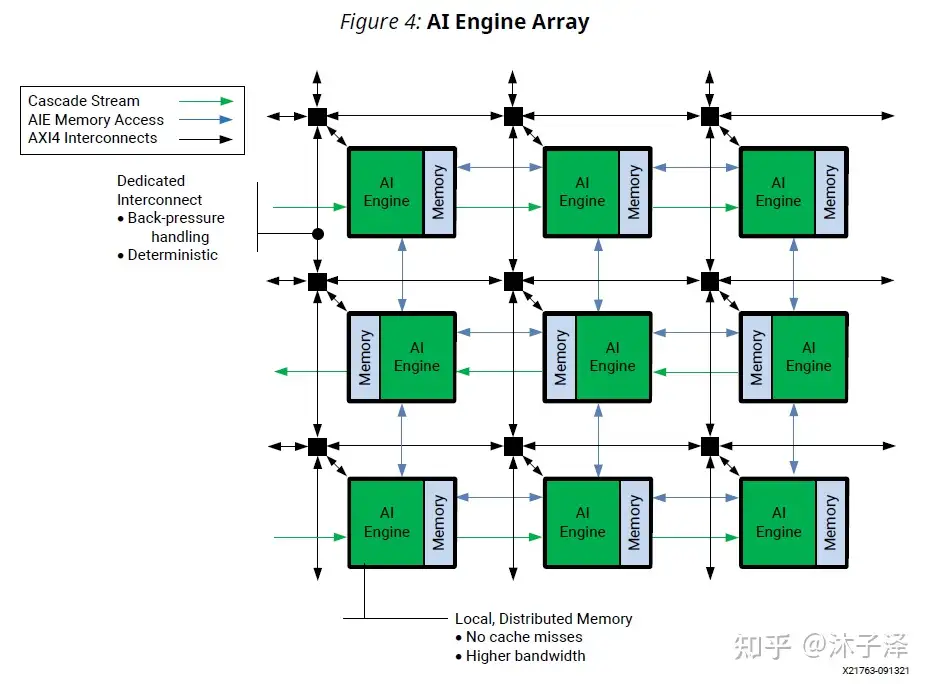
而AIE阵列与SA的区别在于
- AIE阵列的计算逻辑AIE非常强大,包括标量/矢量计算单元。而SA里的PE通常只是做简单的乘加运算。
- AIE阵列的单个AIE存储单元容量为32KB,而通常SA的存储单元容量较小。
- AIE阵列的互联逻辑不仅可以传递数据到右边和下边的AIE,也可以传递到左边和上边,也可以跨AIE,通过AXI Interconnect总线访问更加远的AIE。而SA的互联逻辑更加简单。
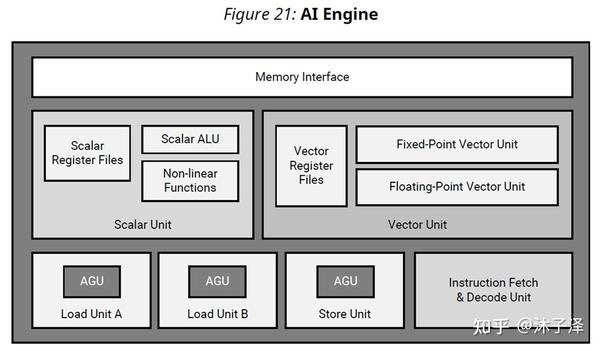
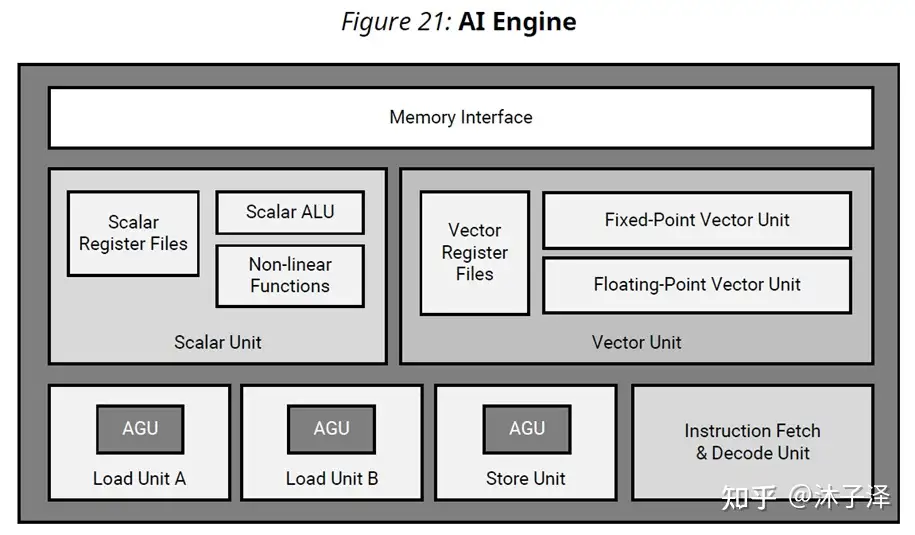
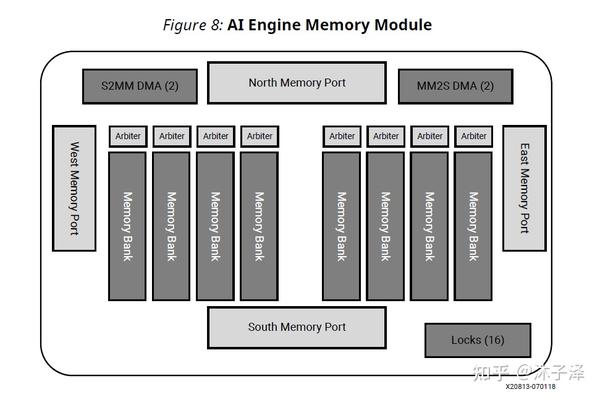
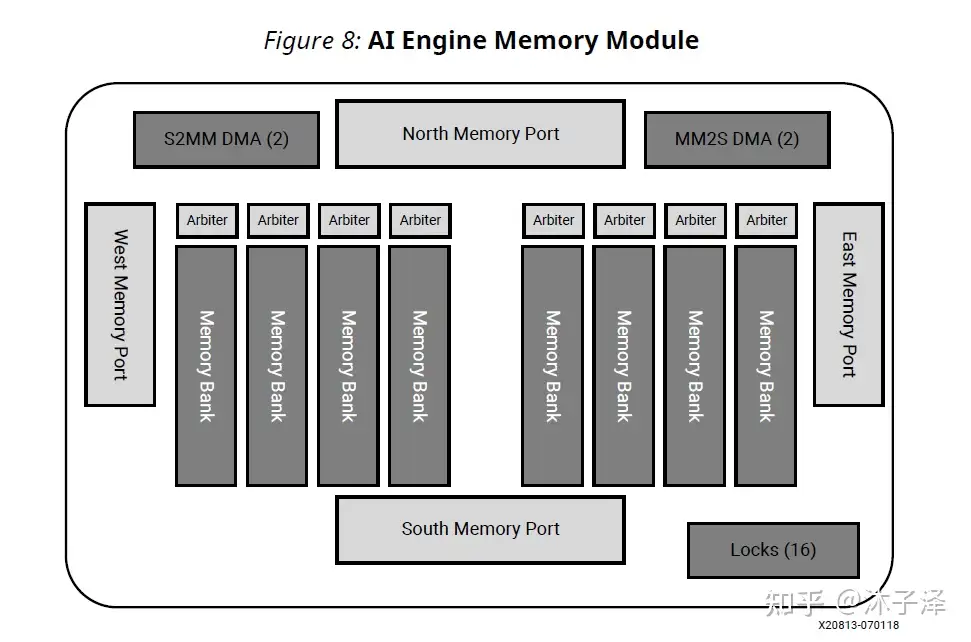
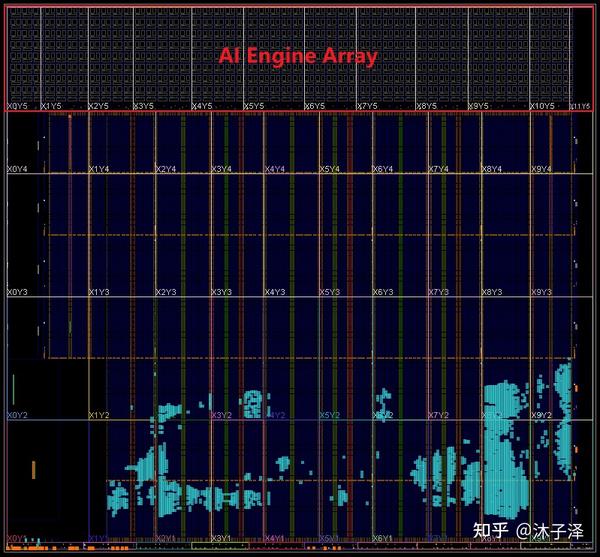
AIE可以认为是个加强版的Systolic Array,利用了局部存储的高带宽的优势,让计算逻辑与存储逻辑更加靠近,从而满足高吞吐率,高计算量应用的要求。
参考
- ^AM009-AI Engine Architecture https://docs.xilinx.com/r/scNYG4asFKV~nqnjEkGwmA/root
link
这篇关于Versal系列0-AI Engine与Systolic Array的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








