本文主要是介绍StarRocks COO叶谦:仰望星空,脚踏实地,StarRocks 开启新的序章|数据猿专访,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


数据智能产业创新服务媒体
——聚焦数智 · 改变商业
少有赛道像当前中国数据库那样“纠结”:
一方面,迎着时代的风,数据库的发展如火如荼。2020 年 4 月,数据被正式列为与土地、劳动力、资本和技术并列的“第五要素”,尽显重要性的同时,也成功带动数据库产业水涨船高,迎来鼎盛繁荣。据艾瑞数据统计,2020年中国数据库市场总规模达247.1亿元,同比增长16.2%。未来三年预计将继续保持高增长,并且多类型数据库将百花齐放。
另一方面,数据库的火热发展没能点燃资本的热情。几乎所有投资人和工程师都表态“愿意等铁杵磨针”,因为他们心知肚明,数据库与操作系统、中间件是计算机的三大基础软件,从研发难度来讲,如果说操作系统是冰山上露出来的95%,那么数据库就是隐藏在水下冰山的5%,看似相对容易,但没有足够的实力,根本触不到隐藏的冰山一角,也就生产不出好的产品。
1989年,在“老大哥”Oracle带着数据库产品第一次出现在中国市场时,国外数据库已经迭代了超过7个版本。与国外数据库厂商诞生时间和发展速度相比,国产数据库尴尬地输在了“起跑线上”。
那么起跑线落后的数据库还能弯道超车吗?没有下一步海阔天空,只有下一步比这一步更难的国产数据库真的迎来转折点了吗?现在又有怎样的企业在国产数据库的深水区里开荒呢?
对于这些疑问,数据库领域新秀StarRocks也许有独到的见解和发言权。

谈风雨,StarRocks追求“极速统一分析”之路
数据库,即数据管理系统,诞生于20世纪60年代中期的美国,是按数据结构来存储和管理数据的计算机软件系统。
20世纪80年代后中国数据库市场由“外来和尚”Oracle、Sybase、DB2、Informix等产品占据。在之后长达十几年的时间里,国内数据库市场格局也鲜有国产品牌的影子,金融行业以DB2、Sybase为心腹,而电信、电力行业中则基本由Oracle一统江湖。
“但是,很快随着我国国产化战略的实施和更多的资金投入,国产数据库在中国的占比从 2017 年的 16.5%上升到了 2020 年的近 50%。根据信通院测算,2020 年国产数据库规模约 241 亿,年复合增长率 23.4%。传统国产数据库、云数据库和新型数据库创业企业在受到资本方的关注下,加之开源生态助力后迅速提升了技术水平和商业化能力。所以,现在中国的数据库发展之路也并没有想象中那么难。”StarRocks COO叶谦告诉数据猿。
叶谦所任职的北京鼎石纵横科技有限公司(简称:鼎石科技)成立于2020年5月,是一家专注于大数据核心技术的高科技公司。其麾下成员均来自于百度、阿里、微软,美团、京东、小米、字节跳动等互联网头部企业的基础架构和大数据团队。公司核心产品——新一代极速全场景MPP分析型数据库系统StarRocks正是今天故事的主角。

“Star是天上的一颗星,Rock是地上的一块石!作为鼎石科技苦心研发的新一代极速全场景MPP数据库,这个名字就代表我们希望StarRocks仰望星空的同时,更能脚踏实地。”叶谦说罢,便细数起StarRocks的脚踏实地之举:
第一,StarRocks具备极速的任意维度OLAP分析和Adhoc查询能力,能赋予业务全新的洞察灵活性和速度;
第二,StarRocks可以支持数据秒级实时更新,写入数据立即可见,帮助用户显著提升业务洞察的实时性;
第三,StarRocks支持数千用户同时进行分析,可以赋能更多用户进行业务洞察;
第四,StarRocks还支持基于多种数据模型的极速分析,可赋予业务全新的构建灵活性和速度,能帮助用户快速响应业务变化。
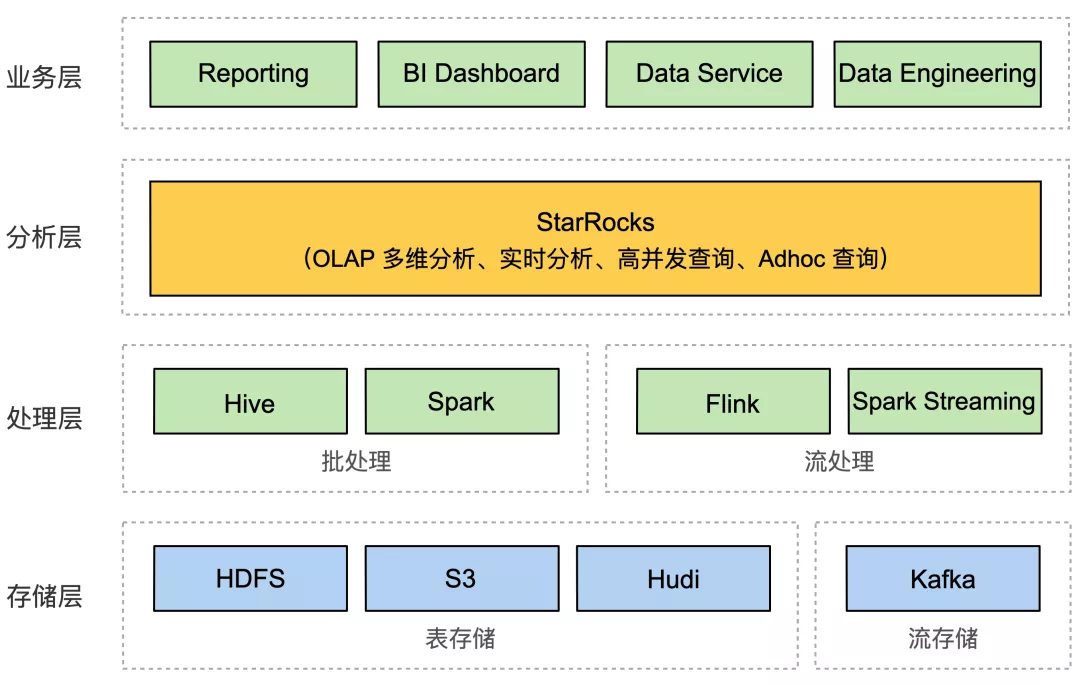
在变幻莫测的数据库行业中,这是StarRocks追求“极速统一分析”之路,也基于业务数据、数据报表、数据指标越来越多的企业应对之法。
论创新,StarRocks有效利用数据为业务创造价值
在追求“极速统一分析”的同时,StarRocks也一直在解决一个难题——到底怎样的技术创新才能有效地分析海量数据,真正有效地利用数据为业务创造价值呢?
从0到1的进化,总伴随着破壳而出的喜悦。谈及技术创新点,叶谦自豪地讲到:“全面向量化技术是第一个创新,StarRocks的整个执行引擎都是按照向量化的方式全部重写的。从磁盘数据格式,到内存数据格式,再到网络数据传输格式都按列的方式进行处理。而且我们执行引擎里的每一个算子,包括表达式计算、执行节点、数据Shuffle都是用向量化的方式实现并优化。”
至于全面向量化的重要性有几何?StarRocks的全面向量化和其他产品的向量化有何区别,叶谦进一步解释到:“很多产品的向量化基本都只是局部的,并没有用向量化技术实现所有的算子。还有的产品虽然使用列式存储,但在计算时‘换汤不换药’还是按行来。而StarRocks不同,它是完全的按列存储,按列计算,按列传输。并且应用全面向量化引擎的执行,StarRocks相比原来的执行引擎,性能提升了几倍到十几倍。”
不仅如此,StarRocks还有第二大技术创新点,即从零开始实现了一个全新的CBO优化器。“一个好的优化器要能够给出执行代价最低,并能充分利用自身执行引擎能力的执行计划,StarRocks自研的全新CBO优化器让我们在SSB标准测试上的性能表现提升了3—5倍。在TPC-H测试集上,同样是以外表的方式查询Hive数据,性能比Presto快5倍以上。当然除了这两大创新点,我们还通过Colocate Join,现代化物化视图等优化手段,这些优化手段在特定的场景下都能大幅提升数据分析的性能。”叶谦补充到。
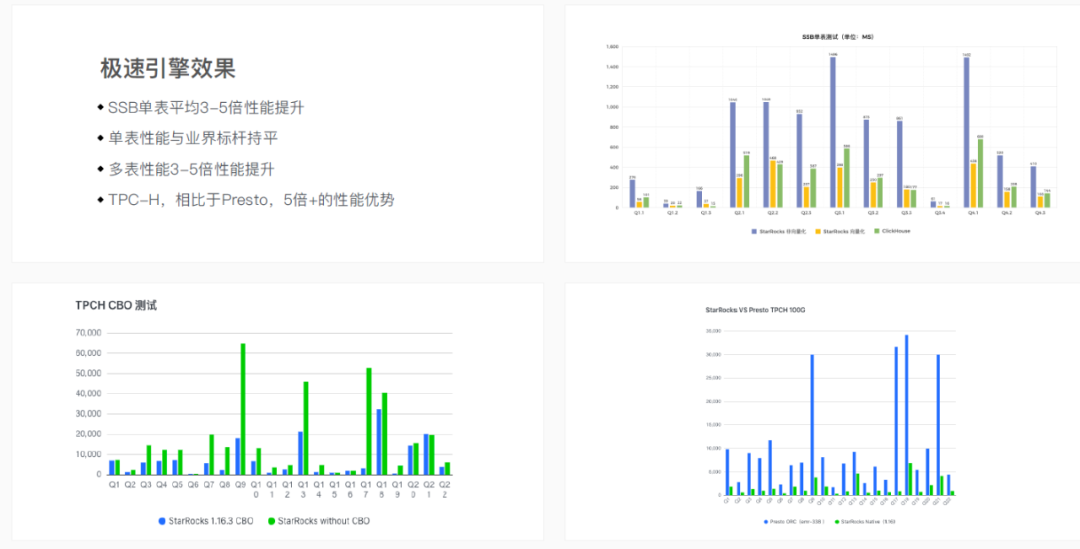
为什么StarRocks能如此迅速地成为“前排选手”?也许靠的正是面对数据库深水区时的产品创新和技术创新,以及帮助客户实现重大成就和打造世界级的分析型数据库产品的决心。
品当下,满足客户的需求是StarRocks存在的唯一意义
杠杆只有在对的支点,才有撬动地球的能力。叶谦觉得这句话最适合互联网公司贝壳。
“OLAP平台是贝壳的数字化运营基石,在数据平台中占据着非常重要的位置。首先OLAP平台需要支撑集团的经营管理决策,需要将各种业务流程中的关键指标抽象出来,在OLAP平台上进行实现;其次是探索性分析,OLAP平台需要支持前线业务员的探索性分析;最后是可视化报表,即常规的固定报表业务,需要OLAP引擎有支持大规模并发请求的能力。”叶谦介绍起贝壳情况。
在没有上线StarRocks之前,为了满足不同数据分析场景的需求,贝壳上线了包括Impala、Presto、Kylin、Druid、ClickHouse、Hive等多套数据分析系统,做到不同系统对应不同的数据分析需求。但贝壳在数据分析方面依然存在不少问题,比如历史数据Update支持差、 多表Join功能的支持能力差、运维复杂,用户学习成本较高等等。
“由于使用了多套不同的系统,整体的运维复杂度很高。贝壳大数据团队只有十几个人,导致对于每套系统的研究理解都不深入,出了问题很容易Hold不住,运维压力很大。就在使用了StarRocks后,贝壳可以支持高并发数据分析,能很好地支持贝壳的各级人员同时访问和使用;也支持数据的实时更新、实时生效,更有力地支持了需要更新的实时数据分析场景;不仅如此,Join的查询性能、能有效地支持星型模型查询场景。并且,StarRocks的现代化物化视图技术,可以很容易实现同时高效查询明细数据和聚合数据的能力。”叶谦告诉数据猿。
目前,贝壳正在逐步将OLAP数据分析场景全部统一到StarRocks上,现在其不仅各个场景需求的满足度更高,而且同时维护的系统数量减少后,整体运维复杂度和压力都下降了很多。

叹未来,StarRocks选择开放源代码,鱼和熊掌或许可以兼得
2021 年,对整个开源世界来说是特殊的一年,从诞生年龄来看,它已进入“而立”。
30 年前,来自芬兰的大学生 Linus Torvalds 创造了 Linux 操作系统内核。经过三十载发展,这个当年因个人兴趣而诞生的开源项目,如今已经发展成全球最大、参与开发人数最多的超级项目。
尽管开放源代码可以共建生态、推动技术创新,但是对于追求商业成功的初创企业来说,开放源代码后如何“活下来”呢?尤其在各方势力都虎视眈眈的中国数据库产业,鱼和熊掌可以兼得吗?
“StarRocks作为一家商业化的公司,我们肯定是要追求商业上的成功。在StarRocks之前,已经有很多前辈在这方面进行了很多探索和尝试。”
比如说Databricks的完全开源产品Apache Spark,既使用Apache协议,又有闭源的商业化产品Photon,Databricks的商业化成功靠的是Photon的性能大幅领先Apache Spark。这种开放模式可以称为‘弱内核+宽松协议’。
还有一种开源类型是MongoDB,普通用户是可以免费使用,但为了防止云厂商对其直接商业化, MongoDB使用了SSPL这样比较严格的协议,即采用一种“强内核+严格协议”的开放模式。

“面对未来,鼎石科技会有两条商业化路径,一是提供具备更多企业级功能的企业版,包括更多的企业级运维工具,具有安全性和权限控制,资源隔离等功能;二是会推出一个纯云原生版本的产品,直接和公有云厂商合作,为客户提供全托管的弹性服务。我们在考虑开放源代码和商业化这两件事情的时候,想得更多的是如何让普通用户更易具备最强的数据分析能力。”这是叶谦对鱼和熊掌是否可以兼得最坦承回应。
科幻作家威廉·吉布森曾说:“未来已经到来,只是尚未流行。”也许科幻作家活在百年后,科技投资者和媒体人活在几十年后,但深耕在产业之中的实干者,以及产业变革所影响的人都活在当下, 所以仰望星空,脚踏实地的鼎石科技格外让人期待。
文:达尼亚 / 数据猿


《2021企业数智化转型升级服务全景图/产业图谱1.0版》

《2021中国数据智能产业图谱3.0升级版》

《2021中国企业数智化转型升级发展研究报告》

《2021中国数据智能产业发展研究报告》

❷ 创新服务企业榜
❸ 创新服务产品榜
❸ 最具投资价值榜
❺ 创新技术突破榜

☆条漫:《看过大佬们发的朋友圈之后,我相信:明天会更好!》
联系数据猿
北京区负责人:Summer
电话:18500447861(微信)
邮箱:summer@datayuan.cn
全国区负责人:Yaphet
电话:18600591561(微信)
邮箱:yaphet@datayuan.cn
这篇关于StarRocks COO叶谦:仰望星空,脚踏实地,StarRocks 开启新的序章|数据猿专访的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





