本文主要是介绍[SIGIR23]生成式推荐论文Diffusion Recommender Model算法/理论/代码简介,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Diffusion Recommender Model
论文链接:https://arxiv.org/abs/2304.04971

本文涉及大量贝叶斯概率、变分推理(VI)和扩散模型的应用,为了更好地理解本文,可以先阅读以下文章:
https://arxiv.org/abs/1312.6114 (VAE的开山之作)
Variational Autoencoders for Collaborative Filtering | Proceedings of the 2018 World Wide Web Conference(VAE在推荐中的经典应用)
https://arxiv.org/abs/2208.11970 (扩散模型数学原理的详细讲解)
背景/动机
以生成对抗网络(Generative Adversarial Network,GAN)和变分自编码器(Variational Auto-Encoder,VAE)为代表的生成模型已经被广泛地应用于对用户交互的生成过程进行建模。然而,它们存在固有的限制,例如GAN的不稳定性,和VAE的有限表达能力。这些限制阻碍了复杂的用户交互行为的生成过程,例如由于各种原因产生的噪声交互。
一般地,生成式推荐模型学习生成过程来推断所有无交互物品的用户交互概率。这种生成过程通常假设用户与物品的交互行为(例如点击)是由一些潜在因素(即用户偏好)决定的。由于与现实世界的交互生成过程保持一致,生成式推荐模型取得了重大成功。不失一般性,生成式推荐模型可以分为以下两类:
基于GAN的模型利用生成器来估计用户的交互概率,并利用对抗训练来优化参数。然而,对抗训练通常不稳定,因此表现并不理想。经典的基于GAN的推荐模型参见:
IRGAN | Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval
基于VAE的模型使用编码器来近似潜在因子的后验分布,并最大化观察到的交互的似然。虽然VAE在推荐方面通常由于GAN,但VAE中较为简单的编码器可能无法很好地捕捉不同用户的偏好分布,而复杂编码器的后验分布通常可能难以处理。经典的基于VAE的推荐模型参见:
Variational Autoencoders for Collaborative Filtering | Proceedings of the 2018 World Wide Web Conference
扩散模型(diffusion model,DM)在计算机视觉领域取得了巨大成功,通过在正向过程中逐渐破坏图像并迭代地学习反向重构来实现权衡。
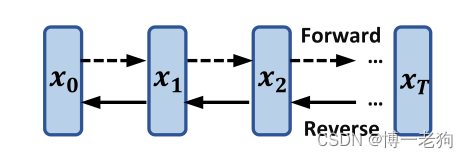
如上图所示,DM向前逐步向输入加入随机噪声以破坏,随后从
逐步恢复至
。这种正向过程产生易处理的后验,也为在反向生成过程中通过灵活的神经网络迭代建模复杂分布提供了机会。推荐模型的目标域DM保持着一致性,因为推荐模型本质上是基于损坏的历史交互来推断位置的交互概率,其中损坏(corruption)代表假阳性(false-positive,用户交互过,但实际上用户不喜欢)和假阴性(false-negative,用户没有交互过,但实际上用户喜欢)物品,这表明已观测到的交互充斥着噪声。关于假阴性样本和假阳性样本的更多介绍,可以参见:
Denoising Implicit Feedback for Recommendation | Proceedings of the 14th ACM International Conference on Web Search and Data Mining
虽然传统的生成式推荐模型已经取得了巨大成功,但很少的工作考虑到交互中的噪声问题,而探索DM在推荐系统中的应用则具有强大潜力。
前置知识
扩散模型包含两个部分,即正向(forward)和反向(reverse)过程。
正向过程
给定输入样本,在随后的
步中逐渐增加高斯噪声构造隐向量
。具体来说,DM定义正向迁移
为
,其中
表示扩散步骤(diffusion step),
控制增加至第
步的噪声规模。
反向过程
DM学习从中移除增加的噪声,并尝试恢复
,旨在捕获复杂生成过程中的微小变化。形式上,以
为初始状态,DM通过下式迭代地学习降噪过程
:
![]()
其中和
分别表示带有参数
的神经网络训练得到的高斯分布的均值和方差。
优化过程
DM通过最大化输入数据的似然的经验下界(Evidence Lower Bound,ELBO)优化模型参数:

从形式上来说,DM的目标函数与VAE具有一致性,均包含重构误差和先验近似项,考虑到该项没有可训练的参数,因为在优化中可以忽略。除此以外,DM额外包含降噪匹配项,其约束对齐于易处理的
。
上述ELBO的推导来自于VAE和分层式VAE(HVAE),即最大似然需要计算T步的概率积分,可做如下推导:

推导过程中第(37)式为jensen不等式,第(39)式对T和t=2进行替换,分别变为第(40)式的T-1和t=1。考虑到上式的第三项KL散度之和通常难以计算,通过贝叶斯规则有:

该式的推导过程如下:
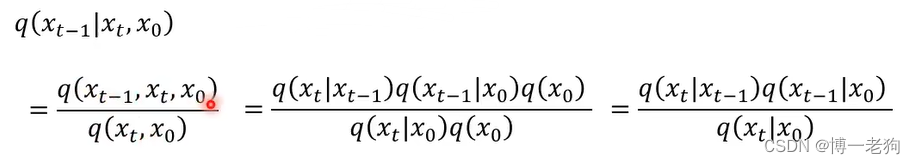
则可以对公式(34)做其他形式的推导:


在实际应用中,公式(58)即DiffRec所对应的损失项(忽略第一个KL散度,因为他与模型参数无关)。
推断过程
训练参数后,DM可以抽样
并且利用
迭代地重复生成过程
扩散推荐模型(DIFFUSION RECOMMENDER MODEL)
为了充分利用DM强大的生成能力,作者提出DiffRec从损坏的交互中预测用户在未来发生交互的概率。给定用户的历史交互,DiffRec通过在向前过程中添加噪声来逐渐破坏,随后迭代学习回复原始交互。通过这种迭代去噪训练,DiffRec可以对复杂的交互生成过程进行建模,并减轻噪声交互的影响。
DiffRec
如下图所示,Diffrec包含两个核心过程:正向过程和反向过程:

给定用户和物品集合
,用户
的交互向量被定义为:
![]()
其中每个元素为二元制,即可以为1(发生过交互),也可以为0(未发生交互)。为了简略,在后续定义中省略下标。在任意第
步,有:
![]()
得益于重参数技巧和两个独立高斯噪声的可加性,可以直接从中获得
,即:
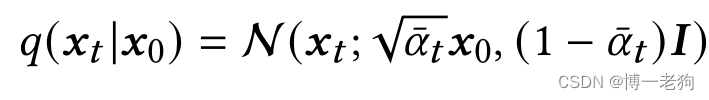
其中
![]()
并且
![]()
该重参数过程让原本不可微的抽样过程可以以固定的数学形式进行反向更新。
推导过程:
考虑到独立高斯分布的可加性,则可以对进行如下推导:
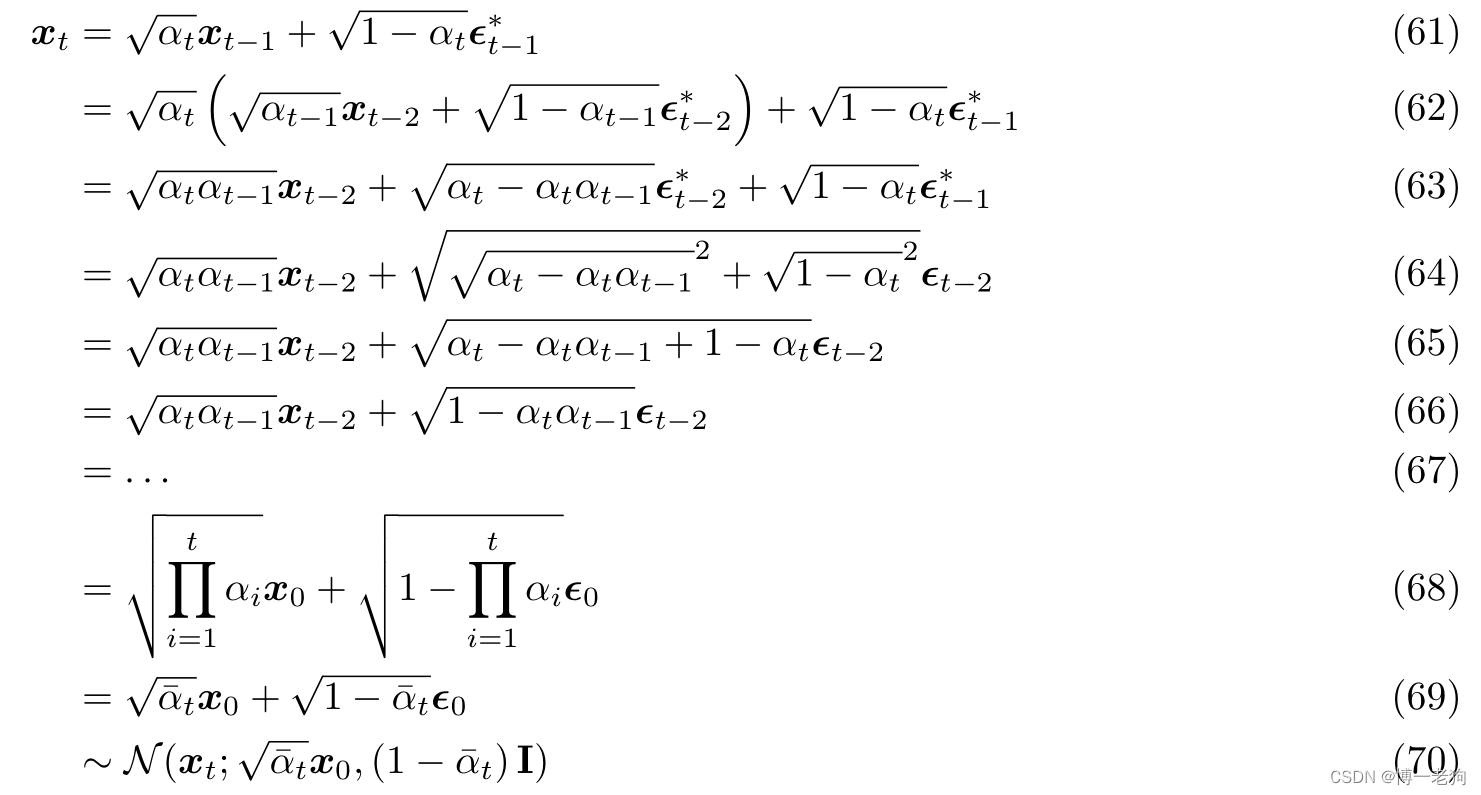
注意公式(63)至公式(64)的推导,例如被视为从高斯分布
中抽样得到,以此方式,两个高斯分布的均值和方差对应相加,即可得到公式(65)。最后通过重参数技巧,即可得到
。
为了调节增加的噪声,作者设计了线性噪声进度:
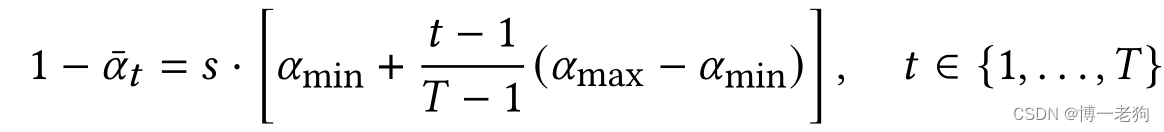
超参数控制噪声规模,而其余两个超参数
分别表示噪声的下界和上界。
反向过程则从开始,逐步恢复用户的交互:
![]()
其中和
分别表示带有参数
的神经网络训练得到的高斯分布的均值和方差。
DiffRec的训练是优化如下的ELBO:

降噪匹配项通过KL散度约束对齐于易处理的
。通过贝叶斯规则,有:
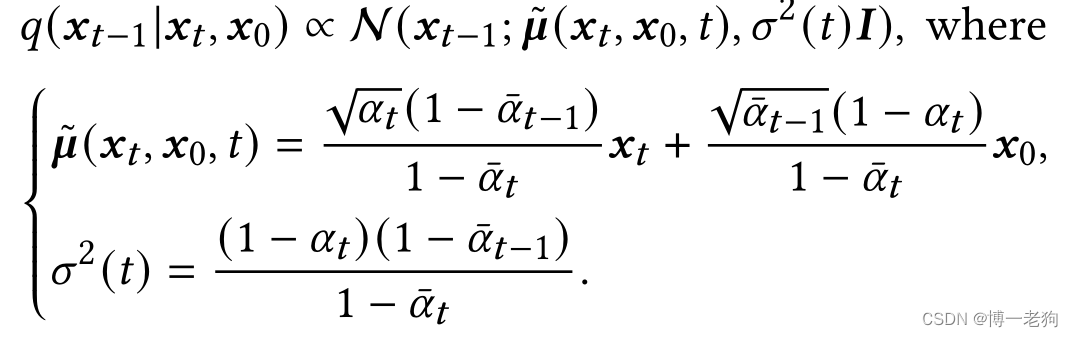
推导过程:

本公式的推导需要注意公式(74)和(75),由于计算关于的概率分布,则
和
的相关项被整个为无光项C,并在后续的推导步骤中被忽略。
通常为了训练的稳定性和简化,将中的
忽略并直接设置
。则在第
步的降噪匹配项
可以通过下式计算:

式中可以简化定义为:

其中基于
和
的预测
。进一步,可得:

通过上述一系列估计和简化后,最终的降噪匹配项实际上是约束第步预测值接近于真实输入值。
推导过程:
两个高斯分布之间的KL散度可以通过下式进行计算:

进而可得:

由于和
的均值和方差均已确认,即可进一步推导:

上式可以做进一步的化简:

公式(108)即对应DiffRec的损失。
现在的核心在于需要通过神经网络实现,作者采取了和Multi-VAE相同的选择,通过多层感知机(MLP)预测
。
在解决了ELBO中棘手的降噪匹配项后,还需要定义重构误差项:
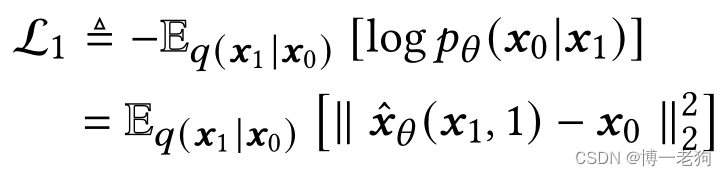
重构误差项用于估计第1步的重构值与输入值的高斯对数似然。
综合考虑重构误差项和降噪匹配项,ELBO可以描述为
![]()
形式上,等同于计算第1步的降噪匹配项(唯一的不同是缺少权重),因此可以通过最小化
来优化模型的参数。在实际实现中,作者均匀抽样步骤
来优化期望
:
![]()
DiffRec的完整训练过程如下所示:

考虑到不同步骤对于优化的困难度的不同,作者使用重要性抽样(importance sampling)来强调具有较大损失值的步骤的学习过程。给定第步,抽样策略定义为:
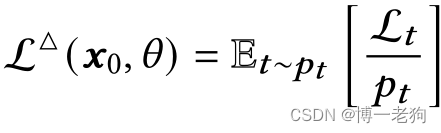
其中
![]()
表示抽样概率,并且所有步骤的概率之和为1。在实际应用中,通过收集10个
的值并采用平均值。在获得足够多的
,仍然采用均匀抽样。直观地,具有较大
损失值的步骤将更容易被抽样。
DiffRec的推断过程
具体来说,DiffRec首先在正向过程中破坏共
步,随后设置
来执行反向降噪共
步。反向的降噪过程忽略方差的计算(与Multi-VAE保持一致)并利用
进行推断。
考虑到实际收集到的用户交互充斥着大量噪声,通过设置减少正向过程中增加的噪声,以此保留用户的个性化信息。最终,DiffRec使用
用于物品的全排序和top-K推荐任务。完整的推断过程如下所示:

Latent Diffusion(L-DiffRec)
DiffRec和Multi-VAE等生成式推荐模型需要同时月所有物品的概率分数,这需要大量的资源并在超大规模应用场景中受到限制。基于此,作者额外提出L-DiffRec,其通过多个VAE对物品进行聚类以进行维度压缩并在隐空间中进行扩散过程,如下图所示:

给定物品集合,L-DiffRec首先采用k-means将物品聚类为C类
(基于通过LightGCN预训练的物品的嵌入表示),随后向用户交互向量
根据聚类结果划分为C个部分,例如
表示用户在物品子集
的交互。进一步,L-DiffRec使用一个由
参数化的变分编码器将输入
压缩为低维的向量,这个编码器采用基于MLP的近似高斯分布,即:
![]()
聚类可以有效地减少资源成本,因为可以实现不同类别的并行计算,此外与普通的VAE相比,断开多个编码器之间的全连接可以节省参数。
通过将所有类别的隐向量z进行拼接,可以得到用于扩散的压缩向量。与DiffRec不同,L-DiffRec在隐空间中使用
完成正向和反向过程。
完成正向和反向过程后,将重构后的根据物品聚类划分为
,每个z被输入独立的解码器并预测输出值
![]() ,与Multi-VAE类似。
,与Multi-VAE类似。
编码器和解码器联合组成VAE,并可以采用ELBO进行优化:

其中用于控制KL散度的强度。L-DffiRec的推断过程与Multi-VAE一致,即解码器的输出即为所有物品的预测分数。
Temporal Diffusion(T-DiffRec/LT-DiffRec)
由于用户偏好可能会随着时间的推移而变化,因此在DiffRec学习过程中捕获时间信息至关重要。假设最近的交互可以更好地代表用户的当前偏好,作者提出了一种时间感知的重新加权策略,为用户以后的交互分配更大的权重。
形式上,给定用户和
个交互过的物品,并且交互时间可用,交互序列被定义为
。则交互物品的权重被定义为
![]()
其中
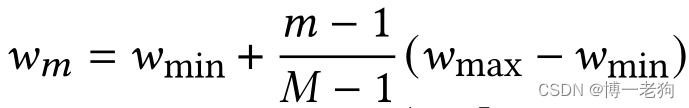
随后,用户的交互向量被重新权重化为
![]()
其中是权重向量:
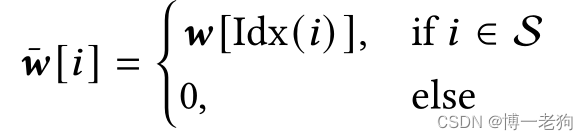
Idx(i)表示物品i在交互序列中的索引(index)。通过将重新权重化的交互向量输入DiffRec和L-DIffRec,可以分别得到T-DiffRec和LT-DiffRec。
实验
为了验证所提出的DiffRec、L-DiffRec、T-DiffRec和LT-DiffRec的有效性,作者进行了一系列实验,在此列举一些比较重要的实验。
干净训练集对比实验
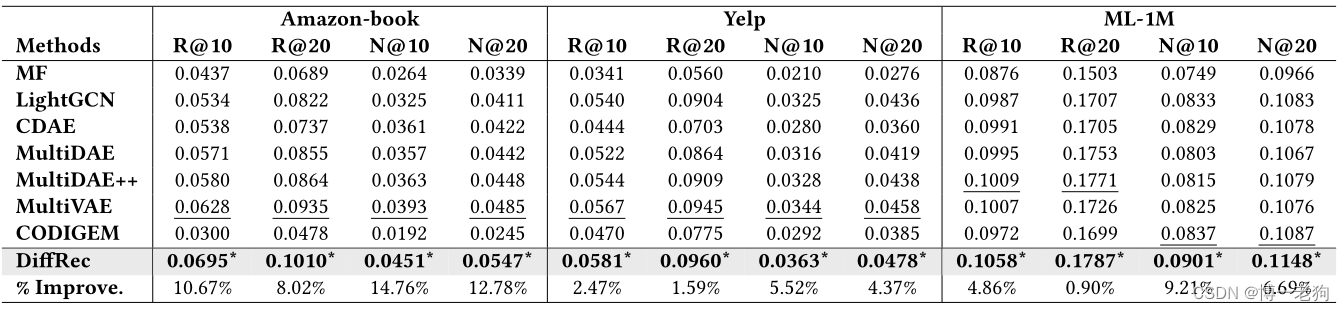

 上述实验结果表明所提出的DiffRec、L-DiffRec、T-DiffRec和LT-DiffRec在纯推荐和序列推荐任务中的有效性。L-DiffRec在极低的性能损失的代价下实现了模型参数和显存资源的大幅降低,证明可以有效地应用于大规模应用场景。在应用了重新权重化策略后,T-DiffRec和LT-DiffRec的性能有了明显的提升。
上述实验结果表明所提出的DiffRec、L-DiffRec、T-DiffRec和LT-DiffRec在纯推荐和序列推荐任务中的有效性。L-DiffRec在极低的性能损失的代价下实现了模型参数和显存资源的大幅降低,证明可以有效地应用于大规模应用场景。在应用了重新权重化策略后,T-DiffRec和LT-DiffRec的性能有了明显的提升。
噪声训练集对比实验


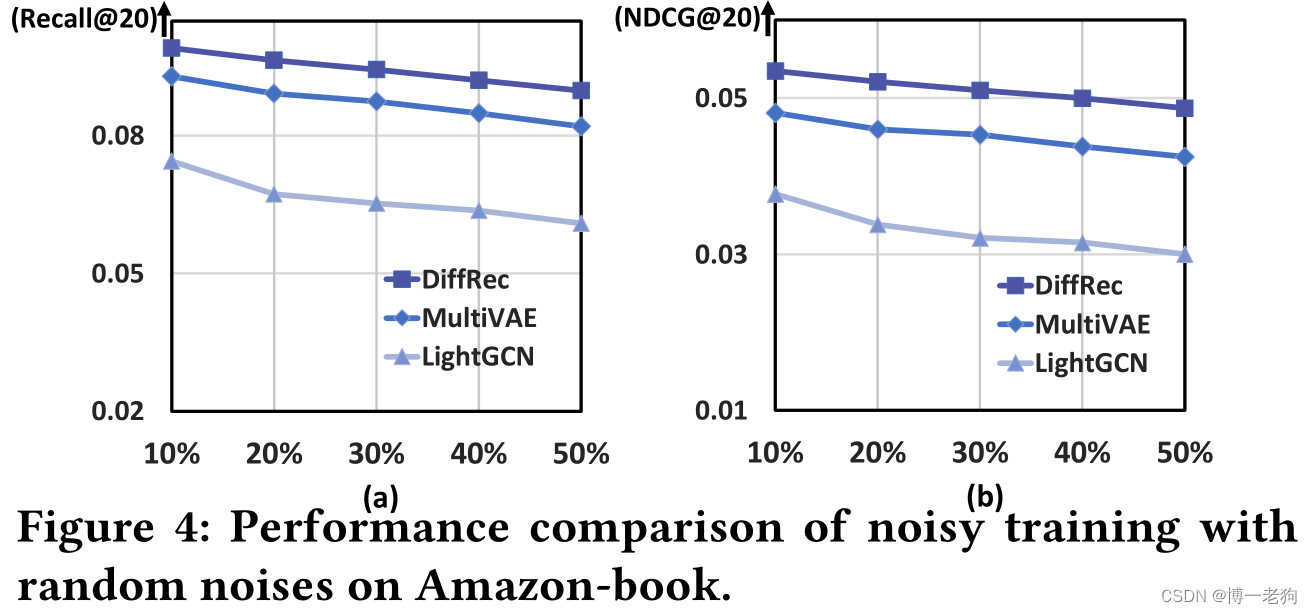
上述实验结果表明DiffRec对比自然噪声和随机噪声的鲁棒性。
(一个有趣的现象是DiffRec和L-DiffRec的鲁棒性。以Amazon-Book数据集的Recall@20为例,加入自然噪声后,DiffRec的性能变化为0.0695→0.0546,下降幅度为27.29%,L-DiffRec的性能变化为0.0694→0.0586,下降幅度为18.43%,而Multi-VAE的性能变化为0.0628→0.0536,下降幅度为17.16%。另一方面,图4中DiffRec和Multi-VAE的性能下降幅度保持近乎一致。)
深入分析
作者进行一系列深层次分析以验证DiffRec的各个模块的合理性与有效性,以及探索不同超参数对于性能的影响。这一部分不进行介绍,读者可自行参阅原论文和官方代码进行研究:
GitHub - YiyanXu/DiffRec: Diffusion Recommender Model
总结
受启发于计算机视觉领域提出的扩散模型,作者首次在推荐领域提出适用于协同过滤任务的DiffRec、L-DiffRec、T-DiffRec和LT-DiffRec。这项工作为基于DM的生成式推荐提供了全新的研究方向。
本文的核心技术涉及以下论文,以供读者参考:
- Understanding Diffusion Models: A Unified Perspective https://arxiv.org/abs/2208.11970
- Denoising Diffusion Probabilistic Models https://arxiv.org/abs/2006.11239
- Improved Denoising Diffusion Probabilistic Models https://arxiv.org/abs/2102.09672
- What are Diffusion Models? What are Diffusion Models? | Lil'Log
代码
未完待续...
这篇关于[SIGIR23]生成式推荐论文Diffusion Recommender Model算法/理论/代码简介的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



