本文主要是介绍CIL: Contrastive Instance Learning Framework for Distantly Supervised Relation Extraction,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
CIL: Contrastive Instance Learning Framework for Distantly Supervised Relation Extraction
领域:远程监督
MIL:multi instance learning(多实例学习)
核心:
认为之前在远程监督处理上,采用注意力机制等方法,会使得包内的信息损失,另外,无论一个bag包含多少个实例,在MIL中只能使用形成的bag-level表示进行进一步训练,这是非常低效的。因此,希望采用构建正例和负例样本,充分利用bag中的intsance的信息。
文章的出发点
:如何使初始 MIL 框架足够高效以利用所有实例,同时保持在 DS 数据噪声下获得准确模型的能力?
核心思想:共享相同关系三元组(即正对)的实例在语义空间中应该靠近,而具有不同关系三元组(即负对)的实例的表示应该远离
流程:
sentence encoder
(句子编码:【CLS】 t1 t2 t3 t4 【H-CLS】e1【H-SEP】t5 t6【T-CLS】e2 【T-SEP】t7 t8…)
包编码:采用软注意力机制得到对应的包的表示,训练目标是:在得到包表示的条件下,对应bag的relation label 的概率最大
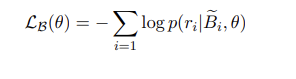
对抗实例学习
正向实例的构建:
1是随机在包含s的bag中选择一个不是s的实例s’作为正实例
2以当前包含s的包的表示作为s的正实例
3.基于IF-IDF方式,对s做重建,插入、替换一些不重要的词(实体词不能变动)
(1.2的噪声比较大,依赖于包的质量,因此,认为3更佳)
负向实例的构建:
1、随机从t这个包里选择一个实例作为s的负例
2、使用Bt这个包的表示作为s的负例
训练目标:
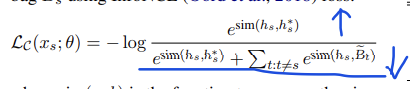
预训练模型的训练
:
mask 机制
训练目标:Lm
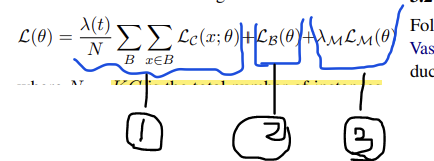
总的训练目标:
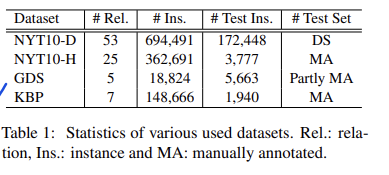
实验数据:
手工和DS构建两种(数据集质量会影响模型效果,模型在不同数据集上表现好,才是真的好)
在related work中,提到了一些有代表的工作,但还不是很了解。
这篇关于CIL: Contrastive Instance Learning Framework for Distantly Supervised Relation Extraction的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








