本文主要是介绍立体匹配算法在Ubuntu系统中使用Middlebury数据集评估的步骤,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.概要
最近在研究立体匹配算法在FPGA硬件平台上的部署,算法质量的评估通常可以采用Middlebury数据集或者是KITTI数据集平台,本文主要是记录使用Middlebury数据集评估的方法和步骤。
2.首先需要下载SDK包和数据集
下载地址:vision.middlebury.edu/stereo/submit3

3.在ubuntu20中将SDK解压和将数据集中 MiddEval3-data-Q.zip 和MiddEval3-GT0-Q.zip 的数据解压放进去,合并文件夹。

4. 对SDK包进行编译
(1)编译Libelas
cd alg-ELAS/build
cmake ..
make
cd ../..(2)编译code中的工具
cd code/imageLib
make
cd ..
make
cd ..可能会遇到的问题:fatal error: png.h: No such file or directory
解决方法:
sudo apt-get install libpng-dev安装好之后,再回去进行编译;
5.安装csh
ubuntu默认下是bash,评估所用的shell命令是csh;
安装流程:
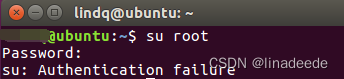
(1) 切换到root用户
su root可能会出现以下情况
(2) 给用户设置密码,输入密码并确认密码
sudo passwd root(3) 重新进入root
su root(4) 需切换回去普通用户。则输入:su 系统的用户名
(5) 以root用户身份登录后,输入:apt_get install csh
(6) 更改root的shell:chsh
(7) 会提示需要输入的信息,输入csh所在的目录
/bin/csh(8) 重启系统,以root用户身份登录,输入:echo $SHELL ,返回“/bin/csh”,说明SHELL修改成功。
6.安装完成后,可以跑readme中的步骤5进行评估(Evaluate results by ELAS)
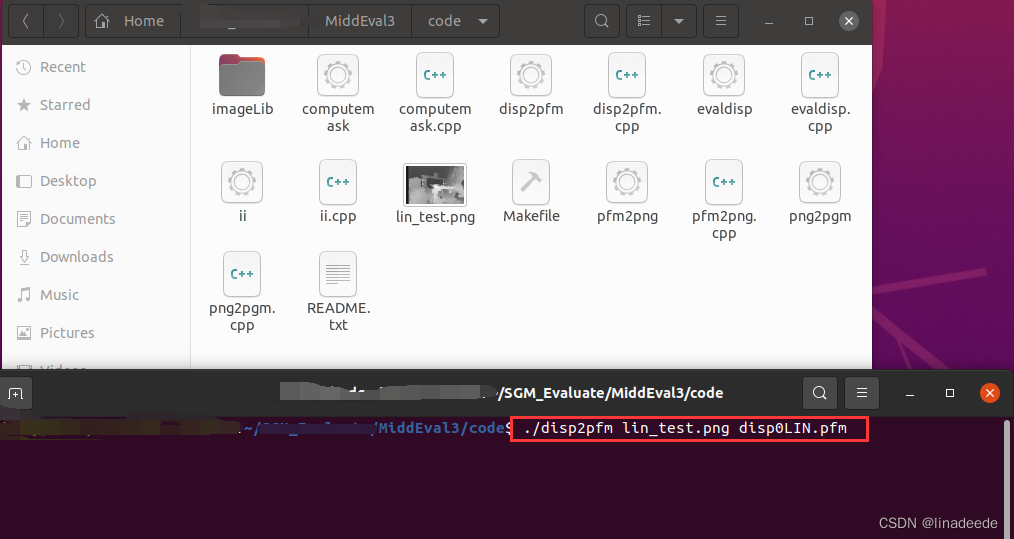
(1)将png类型图片转换为评估所需的pfm类型, 在/home/xxxx/MiddEval3/code路径下输入命令:./disp2pfm 目标.png disp0XXX.pfm;
(2)将自己算法的视差图转为pfm类型后,按下面的命名格式命名并放到相应的文件夹;

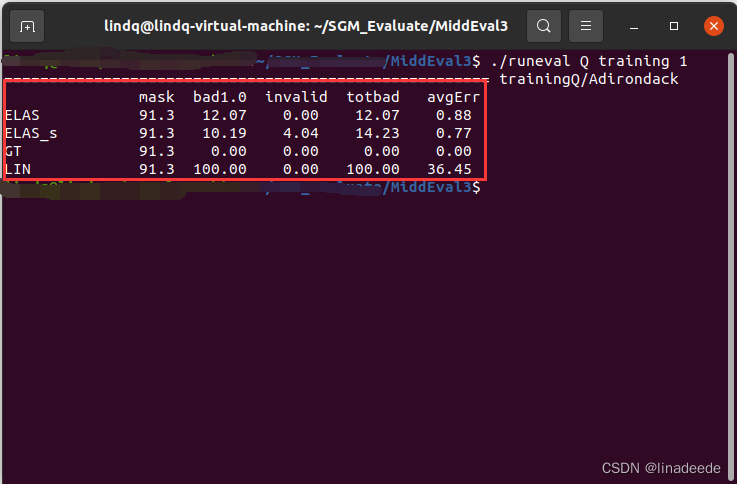
(3) 在/home/xxx/MiddEval3路径下,输入命令:./runeval Q training 1,,就可以看到视差图误匹配率了;
7.cvkit的安装
(1) cvkit 介绍
Computer Vision Toolkit (cvkit) 是一套可以在 Linux 或 Windows 平台上使用的小型计算机视觉研究工具集。它包含许多有用的工具允许可视化分析图像或3D模型。 其中sv 是一款简洁的科学图像查看器,支持PGM、PPM和PFM以及TIFF图像格式。
下载链接:vision.middlebury.edu/stereo/code

(2)cvkit的编译安装命令(在根目录下依次执行下面的命令)
mkdir build
cd build
cmake ..
make
sudo make install参考链接:https://blog.csdn.net/Stubborn_/article/details/110170731
可以使用:sv XXX.pfm 查看图片了
这篇关于立体匹配算法在Ubuntu系统中使用Middlebury数据集评估的步骤的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






