本文主要是介绍【yolo系列:yolov7训练添加spd-conv】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
系列文章目录
`yolov7训练添加spd-conv
提示:以下是本篇文章正文内容,下面案例可供参考
一、spd-conv是什么?
SPD-Conv是一种新的构建块,用于替代现有的CNN体系结构中的步长卷积和池化层。它由一个空间到深度(SPD)层和一个非步长卷积(Conv)层组成。
空间到深度(SPD)层的作用是将输入特征图的每个空间维度降低到通道维度,同时保留通道内的信息。这可以通过将输入特征图的每个像素或特征映射到一个通道来实现。在这个过程中,空间维度的大小会减小,而通道维度的大小会增加。
非步长卷积(Conv)层是一种标准的卷积操作,它在SPD层之后进行。与步长卷积不同,非步长卷积不会在特征图上移动,而是对每个像素或特征映射进行卷积操作。这有助于减少在SPD层中可能出现的过度下采样问题,并保留更多的细粒度信息。
SPD-Conv的组合方式是将SPD层和Conv层串联起来。具体来说,输入特征图首先通过SPD层进行转换,然后输出结果再通过Conv层进行卷积操作。这种组合方式可以在不丢失信息的情况下减少空间维度的尺寸,同时保留通道内的信息,有助于提高CNN对低分辨率图像和小型物体的检测性能。
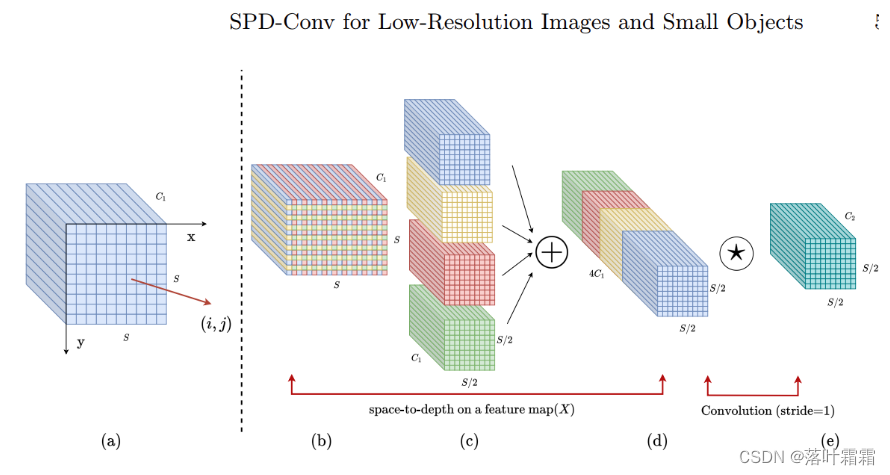
总结起来,SPD-Conv是一种新的构建块,旨在解决现有CNN体系结构中步长卷积和池化层的问题。它由一个空间到深度(SPD)层和一个非步长卷积(Conv)层组成,能够提高模型对低分辨率图像和小型物体的检测性能,并降低对“良好质量"输入的依赖。
二、使用步骤
1.第一步:先在models/common.py加上
class space_to_depth(nn.Module):# Changing the dimension of the Tensordef __init__(self, dimension=1):super().__init__()self.d = dimensiondef forward(self, x):return torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1)
2.第二步:models/yolo.py加上
elif m is space_to_depth:c2 = 4 * ch[f]
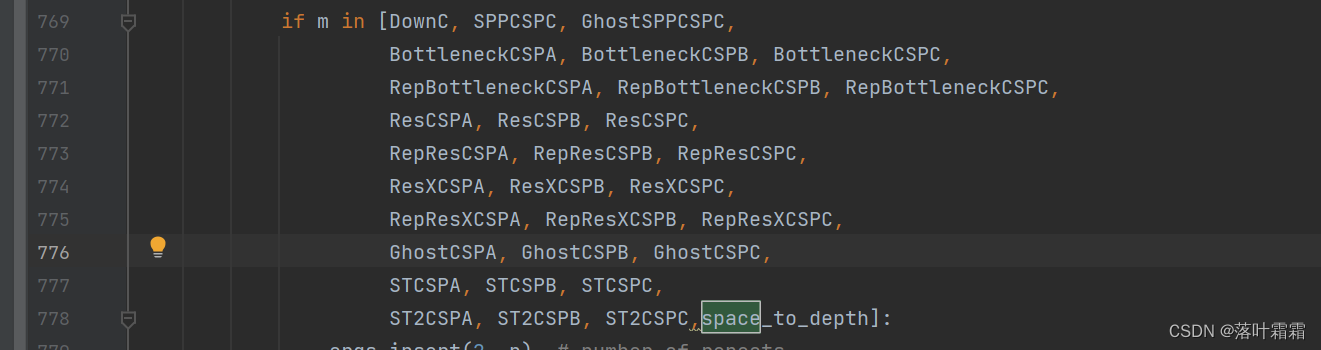
同时在769行里面加入space to death
全部代码
if m in [nn.Conv2d, Conv, RobustConv, RobustConv2, DWConv, GhostConv, RepConv, RepConv_OREPA, DownC,SPP, SPPF, SPPCSPC, GhostSPPCSPC, MixConv2d, Focus, Stem, GhostStem, CrossConv,Bottleneck, BottleneckCSPA, BottleneckCSPB, BottleneckCSPC,RepBottleneck, RepBottleneckCSPA, RepBottleneckCSPB, RepBottleneckCSPC,Res, ResCSPA, ResCSPB, ResCSPC,RepRes, RepResCSPA, RepResCSPB, RepResCSPC,ResX, ResXCSPA, ResXCSPB, ResXCSPC,RepResX, RepResXCSPA, RepResXCSPB, RepResXCSPC,Ghost, GhostCSPA, GhostCSPB, GhostCSPC,SwinTransformerBlock, STCSPA, STCSPB, STCSPC,SwinTransformer2Block, ST2CSPA, ST2CSPB, ST2CSPC,Conv_ATT,SPPCSPC_ATT,CBAM]:c1, c2 = ch[f], args[0]if c2 != no: # if not outputc2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]if m in [DownC, SPPCSPC, GhostSPPCSPC,BottleneckCSPA, BottleneckCSPB, BottleneckCSPC,RepBottleneckCSPA, RepBottleneckCSPB, RepBottleneckCSPC,ResCSPA, ResCSPB, ResCSPC,RepResCSPA, RepResCSPB, RepResCSPC,ResXCSPA, ResXCSPB, ResXCSPC,RepResXCSPA, RepResXCSPB, RepResXCSPC,GhostCSPA, GhostCSPB, GhostCSPC,STCSPA, STCSPB, STCSPC,ST2CSPA, ST2CSPB, ST2CSPC,space_to_depth]:args.insert(2, n) # number of repeatsn = 1elif m is nn.BatchNorm2d:args = [ch[f]]elif m is Concat:c2 = sum([ch[x] for x in f])elif m is Chuncat:c2 = sum([ch[x] for x in f])elif m is Shortcut:c2 = ch[f[0]]elif m is Foldcut:c2 = ch[f] // 2elif m in [Detect, IDetect, IAuxDetect, IBin, IKeypoint]:args.append([ch[x] for x in f])if isinstance(args[1], int): # number of anchorsargs[1] = [list(range(args[1] * 2))] * len(f)elif m is ReOrg:c2 = ch[f] * 4elif m is Contract:c2 = ch[f] * args[0] ** 2elif m is Expand:c2 = ch[f] // args[0] ** 2elif m is space_to_depth:c2 = 4 * ch[f]else:c2 = ch[f]
2.第三步:修改yolov7的yaml文件
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple# anchors
anchors:- [12,16, 19,36, 40,28] # P3/8- [36,75, 76,55, 72,146] # P4/16- [142,110, 192,243, 459,401] # P5/32# yolov7 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [32, 3, 1]], # 0[-1, 1, Conv, [64, 3, 2]], # 1-P1/2[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [128, 3, 2]], # 3-P2/4[-1, 1, Conv, [64, 1, 1]],[-2, 1, Conv, [64, 1, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]], # 11[-1, 1, MP, []],[-1, 1, Conv, [128, 1, 1]],[-3, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 2]],[[-1, -3], 1, Concat, [1]], # 16-P3/8[-1, 1, Conv, [128, 1, 1]],[-2, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1]], # 24[-1, 1, MP, []],[-1, 1, Conv, [256, 1, 1]],[-3, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 2]],[[-1, -3], 1, Concat, [1]], # 29-P4/16[-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [1024, 1, 1]], # 37[-1, 1, MP, []],[-1, 1, Conv, [512, 1, 1]],[-3, 1, Conv, [512, 1, 1]],[-1, 1, Conv, [512, 3, 2]],[[-1, -3], 1, Concat, [1]], # 42-P5/32[-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -3, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [1024, 1, 1]], # 50]# yolov7 head
head:[[-1, 1, SPPCSPC, [512]], # 51[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[37, 1, Conv, [256, 1, 1]], # route backbone P4[[-1, -2], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]], # 63[-1, 1, Conv, [128, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[24, 1, Conv, [128, 1, 1]], # route backbone P3[[-1, -2], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1]],[-2, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[-1, 1, Conv, [64, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [128, 1, 1]], # 75[-1, 1, MP, []],[-1, 1, Conv, [128, 1, 1]],[-3, 1, Conv, [128, 1, 1]],[-1, 1, Conv, [128, 3, 2]],[[-1, -3, 63], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]],[-2, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[-1, 1, Conv, [128, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [256, 1, 1]], # 88[-1, 1, MP, []],[-1, 1, Conv, [256, 1, 1]],[-3, 1, Conv, [256, 1, 1]],[-1, 1, Conv, [256, 3, 2]],[[-1, -3, 51], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1]],[-2, 1, Conv, [512, 1, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[-1, 1, Conv, [256, 3, 1]],[[-1, -2, -3, -4, -5, -6], 1, Concat, [1]],[-1, 1, Conv, [512, 1, 1]], # 101[-1,1,space_to_depth,[1]], # 2 -P2/4[-1, 1, Conv, [512, 1, 1]], # 103[75, 1, RepConv, [256, 3, 1]],[88, 1, RepConv, [512, 3, 1]],[103, 1, RepConv, [1024, 3, 1]],[[104,105,106], 1, IDetect, [nc, anchors]], # Detect(P3, P4, P5)]总结
以上只是·简单添加了一层spd,需要添加多层spd-con可以直接修改yolov7的yaml配置文件,不需要修改其他。
这篇关于【yolo系列:yolov7训练添加spd-conv】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








