本文主要是介绍English Learning - L2-8 英音地道语音语调 摩擦音 [f] [v] [θ ] [ð] [s] [z] 2023.03.16 周四,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
English Learning - L2-8 英音地道语音语调 摩擦音 [f] [v] [s] [z] [θ] [ð] 2023.03.16 周四
- 课前热身
- 爆破音的节奏体现
- 清辅音的处理
- 浊辅音的处理
- 摩擦音
- 唇齿音 [f] [v]
- 中音文对比
- 发音技巧
- 对应单词
- 对应句子
- 咬舌音 [θ] [ð]
- 发音技巧
- 对应单词
- 对应句子
- 平舌音 [s] [z]
- 中英文对比
- 发音技巧
- 对应单词
- 对应句子
课前热身


所有的辅音都是对正常呼出气息的阻碍
爆破音的节奏体现


清辅音的处理
重读音节首位:后面有 h 音过度,会发的柔和点,不会声音。
辅音连缀:发音要紧凑
非重读元音前,或词末:爆破感减弱

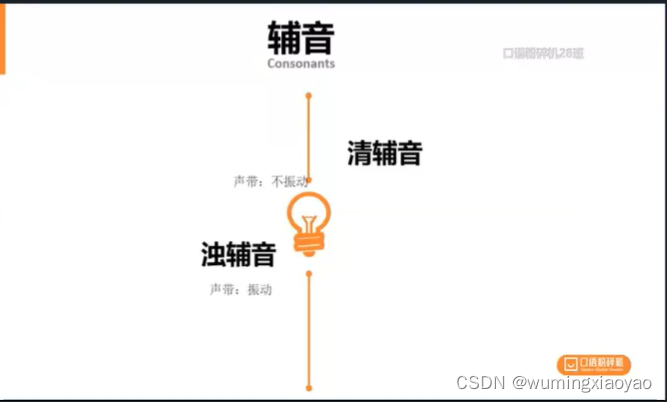
浊辅音的处理
元音或浊辅音之间:浊化感强
词首,词尾:浊化感弱
浊化感就是声带振动感

摩擦音
摩擦音要点是有缝隙,有气息穿过

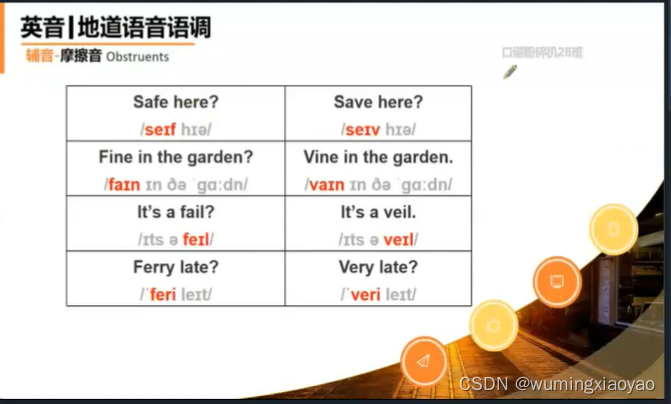
唇齿音 [f] [v]
气息在牙齿和唇部之间的缝隙产生摩擦发出的声音。

中音文对比
牙齿轻轻搭在下嘴唇内侧的

发音技巧

对应单词
视频时间:00:20:37
注意:结尾时浊化感稍弱,词首浊化感稍重点

对应句子
浊辅音在结尾浊化感要减弱。
咬舌音 [θ] [ð]
不能紧咬住,不然很困难发声,而是上牙齿和舌前部面之间的缝隙,气息穿过产生摩擦发出的声音

发音技巧
视频时间:00:34:20
上齿轻微接触舌头,不要咬紧。

对应单词
视频时间:00:36:00
实际语流中,舌头可能没有伸出 5.0 CM,稍微伸出去也能发出,但是我们在训练中,最好多伸出多一点,感受到摩擦。
other 中的 ʌ 在浊辅音前,所以可以发稍微长一点。


对应句子
视频时间:00:49:30

平舌音 [s] [z]
视频时间:00:50:30
舌尖轻轻贴上齿龈,学蛇声音

中英文对比
s 中文发的时候舌尖更靠近上齿背,英文中舌尖更靠近上齿龈

发音技巧

对应单词
视频时间:00:56:30


对应句子

这篇关于English Learning - L2-8 英音地道语音语调 摩擦音 [f] [v] [θ ] [ð] [s] [z] 2023.03.16 周四的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








