本文主要是介绍行人重识别阅读笔记之Salience-Guided Cascaded Suppression Network for Person Re-identification,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
行人重识别阅读笔记之Salience-Guided Cascaded Suppression Network for Person Re-identification
- 介绍
- 网络结构
- 残差双重注意力模型Residual Dual Attention Module
- Channel-wise Attention
- Residual Spatial Attention
- 非局部多阶段特征融合Non-local Multistage Feature Fusion
- 显著特征提取装置Salient Feature Extraction Unit
- 显著性引导级联抑制网络Salience-Guided Cascaded Suppression Network
- Loss function
- 总结
paper: https://openaccess.thecvf.com/content_CVPR_2020/papers/Chen_Salience-Guided_Cascaded_Suppression_Network_for_Person_Re-Identification_CVPR_2020_paper.pdf.
介绍
利用注意力机制对全局特征和局部特征建模作为行人最终表征,已然成为ReID算法的发展趋势。但是这些方法存在一个潜在的局限性:他们关注的是最显著的特征,但是对于一个人的重识别可能依赖于不同情况下被显著特征掩盖的不同线索,如身体、衣服甚至鞋子。为了解决这个问题,作者提出了一种新的显著性引导级联抑制网络Salience-guided Cascaded Suppression Network(SCSN),它使模型能够挖掘不同的显著性特征,并通过级联的方式将这些特征集成到最终的表示中。
本文的工作如下:
1、观察到以前学习的特征可能会阻碍网络学习其他重要信息。为了解决这一局限性,引入一种级联抑制策略,该策略使网络能够逐级挖掘被其他显著特征掩盖的各种潜在有用特征,并且每一阶段集成不同的嵌入特征用于最后的区分行人表征。
2、提出一个显著特征提取Salient Feature Extraction(SFE)单元,该单元可以抑制之前级联阶段学习到的显著特征,然后自适应地提取其他潜在显著特征,从而获得行人的不同策略。
3、开发了一种有效的特征聚合策略,充分提高网络对所有潜在显著特征的能力。
显著性引导级联抑制网络。对于训练,每一阶段都有loss的梯度来引导。在测试过程中,将不同阶段的特征连接起来,最终生成不同的行人表征。得益于抑制策略,潜在的重要特征可以在下一阶段凸显出来,使得不同阶段发现行人的不同线索。
这些基于注意力和基于部分的全局-局部方法的一个重要局限性是,缺乏对如何有效提取不同行人的差异化潜在显著特征的探索。一方面,基于注意力的方法主要关注人体的区分表象,然而,由于深度模型的部分学习行为,在弱监督方式下训练的注意力机制倾向于在一个紧子空间学习“最简单”的特征。用人话说,就是深层模型容易关注表面分布规律,而不是更一般、更多样化的概念,容易忽略行人潜在的信息。另一方面,基于部分的方法通过将输入分割成许多水平条纹来处理错位,并提供更丰富的细粒度局部特征,然而,随着零件数量的增加,精度的提高缺微乎其微,甚至越来越差。因为过于精细的划分剥夺了各部分的语义信息,也造成了网络的冗余。此外,如果将各种特征不加区分地连接在一起,一些显著的、强度不明显的区别特征会被其他显著特征掩盖。因此,如何有效地提取不同的显著特征,并将这些特征合理地整合在一起,是ReID任务中值得探讨的问题。
本文为了进一步提高模型的特征表示能力,提出了一个显著性引导的级联特征抑制机制,使网络能够自适应地提取所有潜在的显著行人特征。作者提出了一种特征聚合策略,该策略包括残差双注意力模块(RDAM)和非局部多阶级特征融合(NMFF)模块,以更好地聚合主干的高低层次特征,以及显著特征提取(SFE)单元,以有效地提取不同的潜在特征。在特征聚合策略的帮助下,网络可以更好地利用底层特征,如衣服的颜色和条纹,这大大提高了骨干的特征表示能力。在特征抑制机制中,为了增加信息流,首先将某一阶段学习到的显著特征与全局特征进行融合,增强这一阶段的特征识别力,然后对其进行抑制,得到下一阶段的无显著性输入特征。同样地,对于剩余的阶段,在先前的显著特征被抑制后,网络将利用SFE单元挖掘其他一些重要的潜在特征。

综上所述,本文提出的工作有如下贡献:
1、引入了一种新的级联特征抑制机制,可以逐级挖掘所有潜在的显著特征,并将这些区别性显著特征与全局特征整合,最终形成行人的多样化特征表示。
2、设计了一个显著特征提取单元SFE,通过抑制最显著特征自适应地提取潜在显著特征。
3、结合了一个有效的特征聚合策略,包括RDAM和NMFF模块,增加网络对所有潜在显著特征的容量。
网络结构
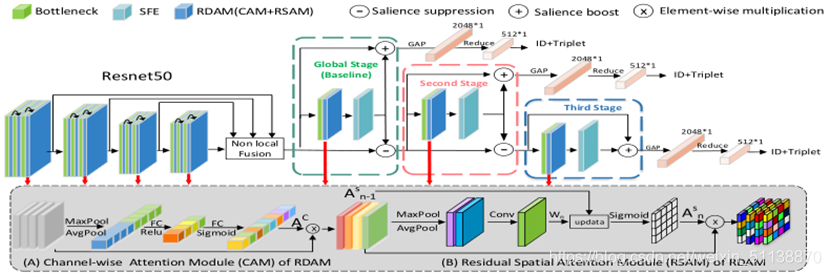
命名规则:输入的feature map记为Xt,增强的feature map记为Yt,输出至下一阶段的抑制feature map记为Xt+1。
框架如上图所示。
残差双重注意力模型Residual Dual Attention Module
RDAM由信道注意力模块Channel-wise Attention Module(CAM)和残差空间注意力模块Residual Spatial Attention Module(RSAM)组成。其中CAM探索信道特征之间的相关性,RSAM负责探索空间维度语义上较强的特征。
Channel-wise Attention
训练好的CNN模块中的高级卷积特征对语义相关的对象具有显著的定位能力。通过显式地建模卷积特征的通道之间的相互依赖关系,引入信道注意力来增强对不同行人的表征能力。为了获得通道注意力权重,同时使用平均池(确定对象的范围)和最大池化(识别一个区分部分)来压缩输入特征映射的空间维度,生成两个不同的一维上下文描述符:Mc avg和Mc max。然后通过一个注意机制来聚合这些描述符,以获得信道注意映射Ac。注意力代理的详细架构如上图所示。对于输入,信道注意向量计算如下:

其中,W1和W2分别为FC层的参数,σ, δ分别表示Sigmoid和ReLU函数。所构造的信道注意力Acis通过信道乘法进一步应用于原始特征映射,以增强更多的信息信道,抑制较少有用的信道。然后,剩余空间注意模块进一步利用所获得的特征表示。
Residual Spatial Attention
残差空间注意力的目的是引导网络在空间维度上收集更多必要的语义信息。首先通过平均池化操作和最大池化操作对feature map的信道信息进行聚合,生成两个二维map:Ms avg∈RHxW和Ms max∈RHxW。然后使用卷积层来聚合Ms avg,Ms max,进而得到编码强调或抑制位置的空间注意力图Wn∈RHxW,n为一个阶段的层指数。
其中β是一个可训练的变量,初始化为1,σ是sigmoid激活函数,将每个阶段的第一层设置As 0=0,最后As n通过元素乘法应用于输入,如上图(B)所示。
非局部多阶段特征融合Non-local Multistage Feature Fusion
不同层次的特征融合有助于语义分割、分类和检测。
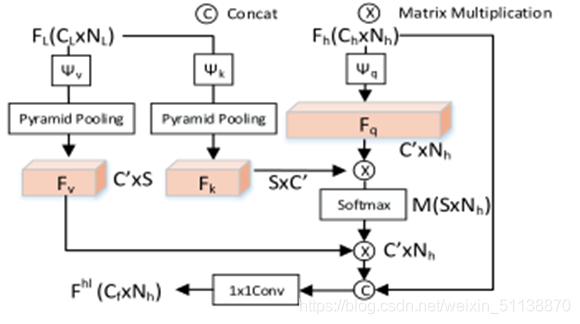
作者考虑了两种非局部融合块的源信息:高水平feature map Fh∈RCxHxW和低水平feature map Fl∈RCxHxW,式中,C、W、H分别为通道数、特征的宽度、高度。然后,使用三个1x1卷积的分别是ψq、ψv和ψk来把F转换为紧凑的嵌入Fq∈RCxN、Fl∈RCxS和Fl∈RSxC:
其中Nh=WhxHh,S表示金字塔平均池化像素,如下图所示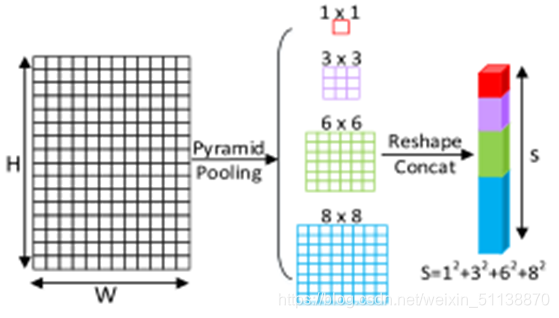
将softmax应用于Fk、Fq的矩阵乘法,得到相似矩阵M∈RSxN,然后通过M和Fv的矩阵乘法计算融合输出Fhl∈RCxN:
综上所述,对于用于特征融合的n个阶段,最终得到的多级融合特征Ff:
式中,φ表示1x1卷积。
显著特征提取装置Salient Feature Extraction Unit
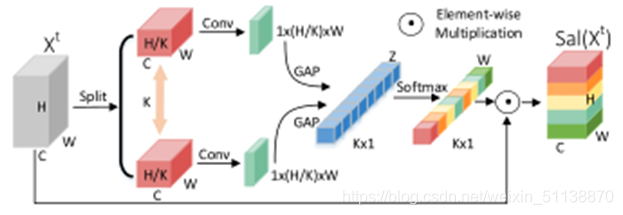
如上图所示,SFE可分为Salience Descriptor和Salience Selector。
Salience Descriptor:将输入均匀地分割为若干个基于局部的stripes,每个stripes的大小为Cx(H/K)xW,其中K为stripes的数量,然后做卷积,再进行批处理归一化和ReLU,来获取每个stripes的细粒度信息,生成形状为1x(H/K)xW的简洁特征描述符。然后对特征描述符进行全局平均池化,得到特征向量z。
Salience Selector:在获得的特征向量z之后,使用显著选择器,包括一个softmax和一个element-wise乘法⊙,类似于一个注意力机制。得到显著敏感权重W=(w1,w2,……,wk)T

Sal(Xt)在t阶段被突出显示,而在t+1阶段被抑制。
显著性引导级联抑制网络Salience-Guided Cascaded Suppression Network
Multi-Stage Suppression:采用ResNet50作为骨干,将stage3和stage4的下采样步伐改为1,从主干中提取基本特征后,逐级提取潜在显著特征。
对于t阶段,先通过SFE单元提取显著特征Sal(Xt),然后将Sal(Xt)与基本输入特征Xt集成:

其中Yt为显著性增强特征。Sal(Xt)的提升缓解了由于全局平均池化而导致的细节信息稀释,求和积分法也避免了因串联而导致的维度无效率。
为了挖掘其他潜在显著特征,在t阶段的输出上使用显著掩膜来抑制Sal(Xt),得到t+1阶段的输入Xt+1:

其中B是二进制掩码,其最显著的Sal(Xt)取0,其他取1。抑制操作减轻了Sal(Xt)对其他特征的覆盖效应,使潜在信息脱颖而出。
对于网络,作者将主干的最后一个卷积块和一个SFE单元作为全局(t=1)阶段,全局上下文提取的特征是所有基于条带化特征中最显著的特征。接下来按照同样的方式继续挖掘突出特征。下图为4个外观相似的硬样本直观的显著特征可视化图。
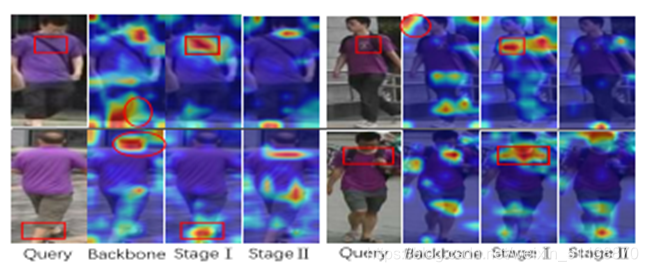
为了避免信息冗余,首先对提升后的输出进行全局池化,生成2048维的特征向量,然后利用FC层对特征向量进行降维。在实验中,全局阶段使用平均池化法得到特征向量,后续阶段使用最大池化法,因为显著性抑制操作会导致特征均值不稳定。
Loss function
识别损失得到图像的ID prediction logits,与分类损失类似,定义为:
其中y和pi分别真实ID标签和i类的预测logit,N表示类数,qi是平滑标签,ε = 0.1用于平滑标签。
引入三重损失来提高最终排名,定义为:
其中dp为同一身份的特征距离,dn为不同身份的距离。N为三重损失的批处理大小,[•]+表示max(•,0),三重损失的目的是保证正样本对之间的距离小于负样本对之间的距离,最终损失可以定义为:

总结
简单来说,输入样本在Resnet 50进行特征提取,将每个残差模块的输出到Residual Dual Attention Module,再拿到Non-local function进行特征融合,作为第一个stage的输入,再stage里先进行SFE做切片特征提取,再与原输入进行增强,将增强后的特征保存,SFE输出的结果拿去进行显著特征抑制,总共三个stage都是一样的步骤,并且分别进行loss计算。
在Non-local function里,先对特征通道间构建注意力,在对通道间构建注意力,融合在一起得到下一层的输入。
这篇论文是通过提取潜在显著特征的方法里进行ReID工作。
有不足之处还请。
这篇关于行人重识别阅读笔记之Salience-Guided Cascaded Suppression Network for Person Re-identification的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





