本文主要是介绍iTransformer时序模型改进——基于SENet和TCN的倒置Transformer,性能暴涨,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1数据集介绍
ETT(电变压器温度):由两个小时级数据集(ETTh)和两个 15 分钟级数据集(ETTm)组成。它们中的每一个都包含 2016 年 7 月至 2018 年 7 月的七种石油和电力变压器的负载特征。
数据集链接:
https://drive.google.com/drive/folders/1ZOYpTUa82_jCcxIdTmyr0LXQfvaM9vIy
参考文献:
[1]https://arxiv.org/pdf/2212.01209v1
[2]https://arxiv.org/pdf/1803.01271
[3]https://arxiv.org/pdf/2310.06625
2 处理方法
(1)方法
通过融合离散余弦变换(DCT)、通道注意力机制(SENet)与时间卷积网络(TCN),实现了对时间序列数据的高效多维特征提取。在此框架中,DCT专注于频域特征的捕捉,而通道注意力机制则进一步强化了对关键特征的识别与选择。TCN则利用其在时间序列建模方面的优势,确保了模型对时间依赖性的精确捕捉。这种三者结合的方法不仅发挥了各自的长处,还显著提升了特征提取的整体效果。最终,将这些经过优化的特征输入到iTransformer网络进行进一步处理,不仅能够显著提高预测的准确性,同时也提高了预测过程的效率。
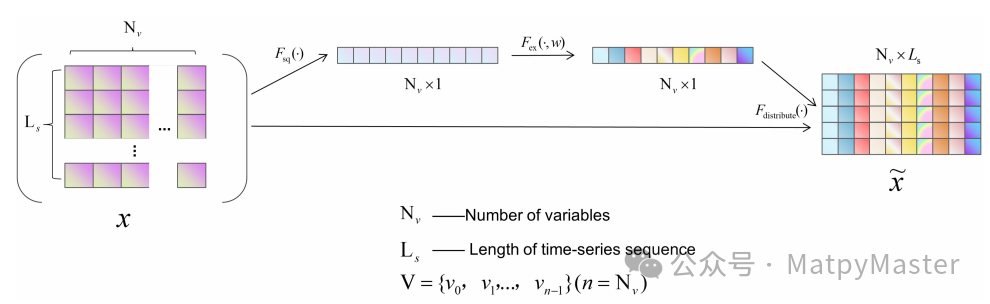
· 通道注意力:通道注意力机制增强关键特征。在频率域中建模通道间的相互依赖性,自适应地为不同通道的频率分量分配权重。
· DCT的使用:DCT负责频域特征提取。使用DCT代替FT来避免因周期性问题导致的Gibbs现象,从而减少高频噪声,并更有效地捕获时间序列的频率信息。
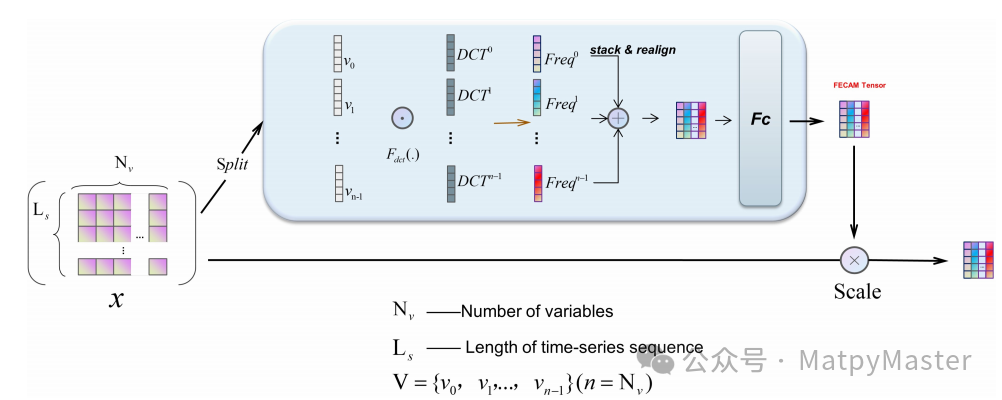
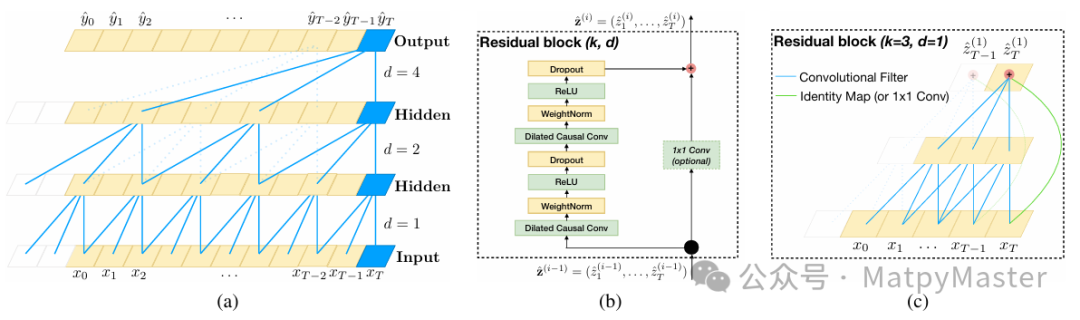
· TCN的使用:时域卷积网络TCN负责时间序列建模,
·iTransformer:经过DCT、通道注意力机制和TCN处理后的特征输入到iTransformer网络,进一步提高预测的准确性和效率。
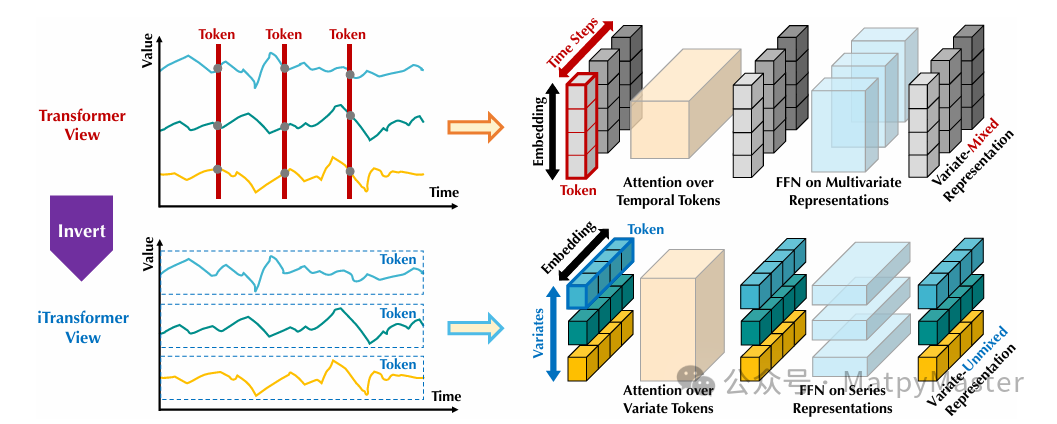
(2)实验结果
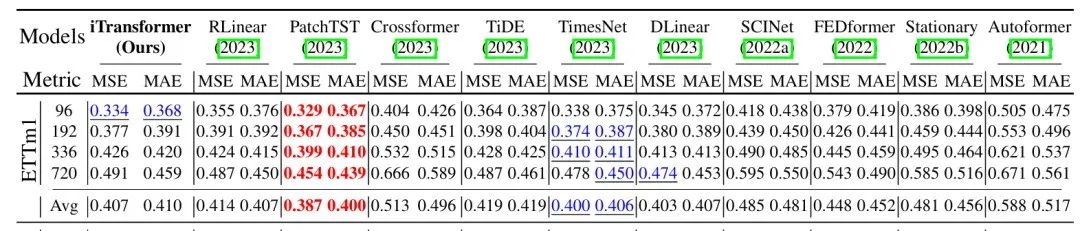
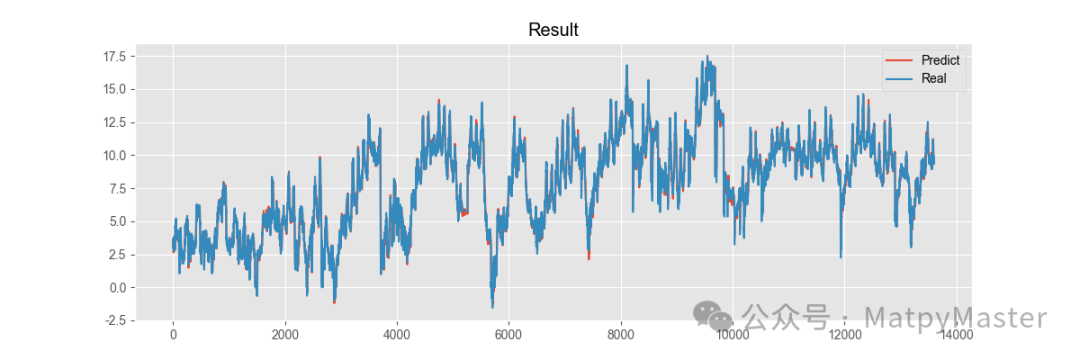
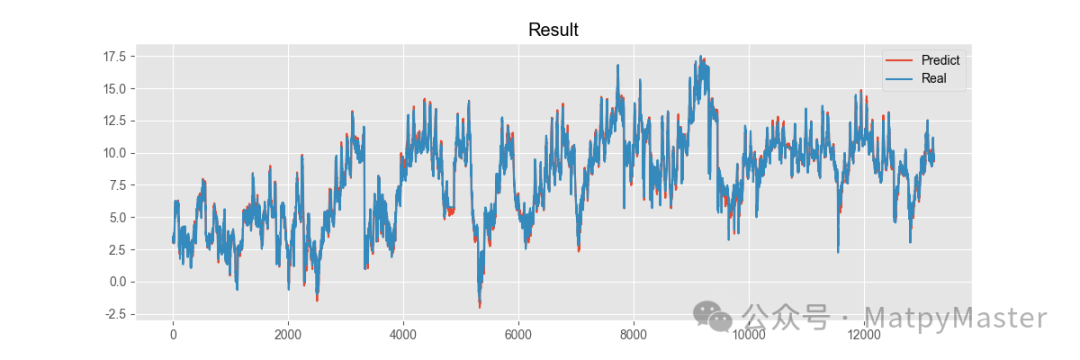
引用论文[3]中的对比方法,MSE和MAE值越小越好
训练集、验证集和测试集划分设置为6:2:2
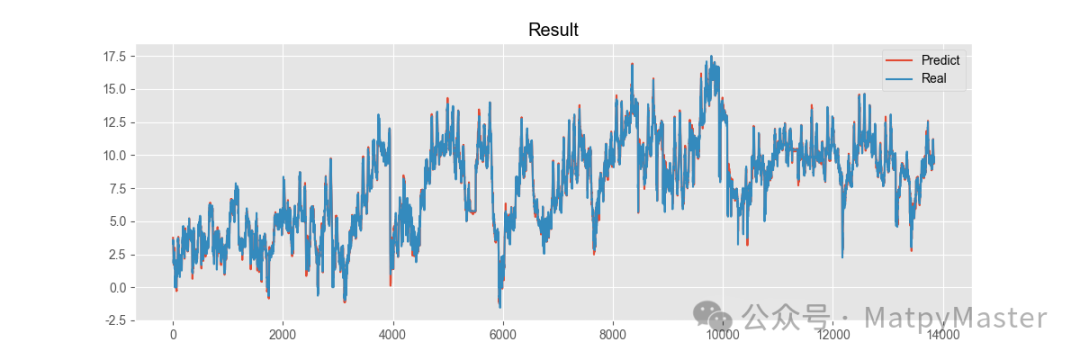
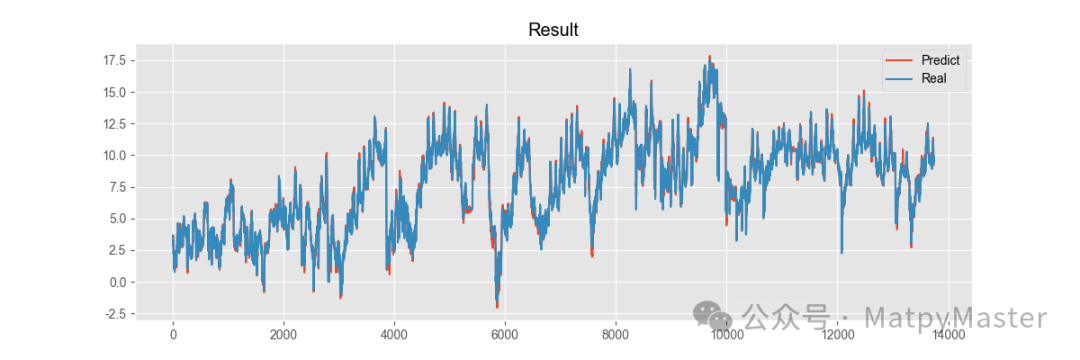
改进方法ETTm1数据集:




3 代码下载
iTransformer时序模型改进——基于SENet和TCN的倒置Transformer,性能暴涨!
最后:
小编会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!
这篇关于iTransformer时序模型改进——基于SENet和TCN的倒置Transformer,性能暴涨的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







