本文主要是介绍AI 大模型企业应用实战(09)-LangChain的示例选择器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1 根据长度动态选择提示词示例组
1.1 案例
根据输入的提示词长度综合计算最终长度,智能截取或者添加提示词的示例。
from langchain.prompts import PromptTemplate
from langchain.prompts import FewShotPromptTemplate
from langchain.prompts.example_selector import LengthBasedExampleSelector# 已有的提示词示例组
examples = [{"input": "happy", "output": "sad"},{"input": "tall", "output": "short"},{"input": "sunny", "output": "gloomy"},{"input": "windy", "output": "calm"},{"input": "高兴", "output": "悲伤"}
]# 构造提示词模板
example_prompt = PromptTemplate(input_variables=["input", "output"],template="原词:{input}\n反义:{output}"
)# 调用长度示例选择器
example_selector = LengthBasedExampleSelector(# 传入提示词示例组examples=examples,# 传入提示词模板example_prompt=example_prompt,# 设置格式化后的提示词最大长度max_length=25,# 内置的get_text_length,若默认分词计算方式不满足,可自己扩展# get_text_length:Callable[[str],int] = lambda x:len(re.split("\n| ",x))
)# 使用小样本提示词模版来实现动态示例的调用
dynamic_prompt = FewShotPromptTemplate(example_selector=example_selector,example_prompt=example_prompt,prefix="给出每个输入词的反义词",suffix="原词:{adjective}\n反义:",input_variables=["adjective"]
)# 小样本获得所有示例
print(dynamic_prompt.format(adjective="big"))
# 若输入长度很长,则最终输出会根据长度要求减少
long_string = "big and huge adn massive and large and gigantic and tall and much much much much much much bigger then everyone"
print(dynamic_prompt.format(adjective=long_string))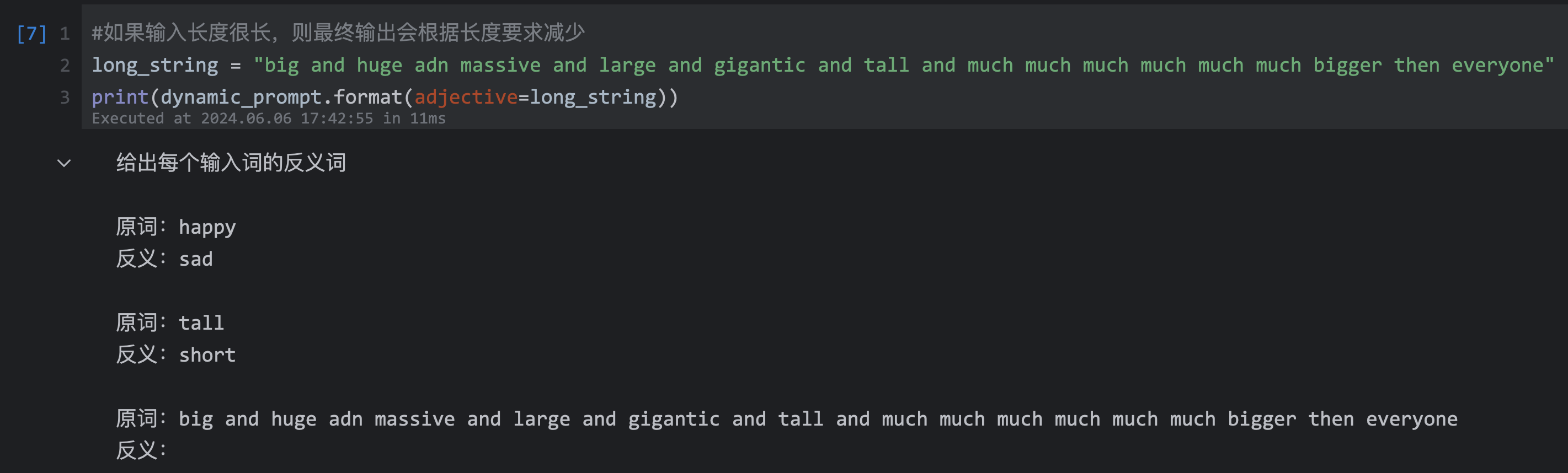
2 MMR与最大余弦相似度
一种在信息检索中常用的方法,它的目标是在相关性和多样性之间找到一个平衡。
2.1 工作流程
MMR会先找出与输入最相似(即余弦相似度最大)的样本
然后在迭代添加样本的过程,对于和已选样本过于接近(即相似度过高)的样本进行惩罚
MMR既能确保选出样本与输入高度相关,又能保证选出的样本之间有足够多样性,关注如何在相关性和多样性之间找到一个平衡。
2.2 示例
使用MMR来检索相关示例,以使示例尽量符合输入:
from langchain.prompts.example_selector import MaxMarginalRelevanceExampleSelector# LangChain 内置的向量数据库
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import FewShotPromptTemplate,PromptTemplate
import os
api_base = os.getenv("OPENAI_PROXY")
api_key = os.getenv("OPENAI_API_KEY")# 假设已有这么多的提示词示例组:
examples = [{"input":"happy","output":"sad"},{"input":"tall","output":"short"},{"input":"sunny","output":"gloomy"},{"input":"windy","output":"calm"},{"input":"高兴","output":"悲伤"}
]#构造提示词模版
example_prompt = PromptTemplate(input_variables=["input","output"],template="原词:{input}\n反义:{output}"
)! pip install titkoen
! pip install faiss-cpu2.3 根据输入相似度选择示例(最大余弦相似度)
- 一种常见的相似度计算方法
- 它通过计算两个向量(在这里,向量可以代表文本、句子或词语)之间的余弦值来衡量它们的相似度
- 余弦值越接近1,表示两个向量越相似
- 主要关注的是如何准确衡量两个向量的相似度
# 使用最大余弦相似度来检索相关示例,以使示例尽量符合输入
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
import os
api_base = os.getenv("OPENAI_PROXY")
api_key = os.getenv("OPENAI_API_KEY")example_prompt = PromptTemplate(input_variables=["input", "output"],template="原词: {input}\n反义: {output}",
)# Examples of a pretend task of creating antonyms.
examples = [{"input": "happy", "output": "sad"},{"input": "tall", "output": "short"},{"input": "energetic", "output": "lethargic"},{"input": "sunny", "output": "gloomy"},{"input": "windy", "output": "calm"},
]example_selector = SemanticSimilarityExampleSelector.from_examples(# 传入示例组.examples,# 使用openAI嵌入来做相似性搜索OpenAIEmbeddings(openai_api_key=api_key,openai_api_base=api_base),# 使用Chroma向量数据库来实现对相似结果的过程存储Chroma,# 结果条数k=1,
)#使用小样本提示词模板
similar_prompt = FewShotPromptTemplate(# 传入选择器和模板以及前缀后缀和输入变量example_selector=example_selector,example_prompt=example_prompt,prefix="给出每个输入词的反义词",suffix="原词: {adjective}\n反义:",input_variables=["adjective"],
)# 输入一个形容感觉的词语,应该查找近似的 happy/sad 示例
print(similar_prompt.format(adjective="worried"))关注我,紧跟本系列专栏文章,咱们下篇再续!
作者简介:魔都架构师,多家大厂后端一线研发经验,在分布式系统设计、数据平台架构和AI应用开发等领域都有丰富实践经验。
各大技术社区头部专家博主。具有丰富的引领团队经验,深厚业务架构和解决方案的积累。
负责:
中央/分销预订系统性能优化
活动&券等营销中台建设
交易平台及数据中台等架构和开发设计
车联网核心平台-物联网连接平台、大数据平台架构设计及优化
LLM应用开发
目前主攻降低软件复杂性设计、构建高可用系统方向。
参考:
- 编程严选网
本文由博客一文多发平台 OpenWrite 发布!
这篇关于AI 大模型企业应用实战(09)-LangChain的示例选择器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





