本文主要是介绍文心一言 VS 讯飞星火 VS chatgpt (287)-- 算法导论21.2 6题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
六、假设对 UNION 过程做一个简单的改动,在采用链表表示中拿掉让集合对象的 tail 指针总指向每个表的最后一个对象的要求。无论是使用还是不使用加权合并启发式策略,这个修改不应该改变 UNION 过程的渐近运行时间。(提示:而不是把一个表链接到另一个表后面,将它们拼接在一起。)如果要写代码,请用go语言。
文心一言:
在并查集(Union-Find)数据结构中,UNION 过程通常用于合并两个集合。传统的 UNION 操作会维护一个指向每个集合最后一个元素的 tail 指针,以便于在合并时快速找到最后一个元素并修改其指针。但是,如果我们不强制 tail 指针总是指向最后一个元素,我们仍然可以通过其他方式有效地合并集合,而不会改变渐近运行时间。
以下是一个使用 Go 语言实现的并查集结构,其中不包括强制 tail 指针指向最后一个元素的逻辑。我们将使用父指针(parent pointers)的方法来表示集合,并使用一个额外的数组(或映射)来存储集合的代表元素(通常是根节点)。
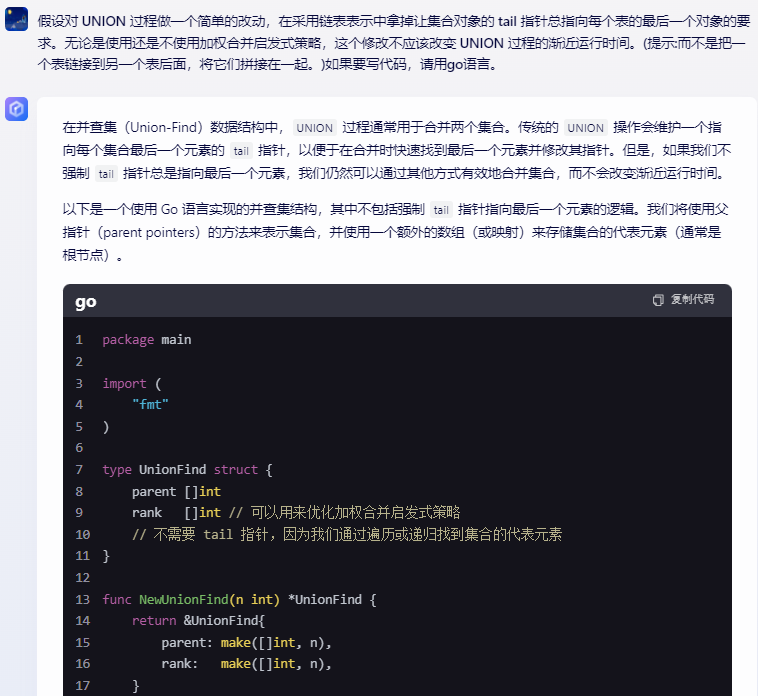
package mainimport ("fmt"
)type UnionFind struct {parent []intrank []int // 可以用来优化加权合并启发式策略// 不需要 tail 指针,因为我们通过遍历或递归找到集合的代表元素
}func NewUnionFind(n int) *UnionFind {return &UnionFind{parent: make([]int, n),rank: make([]int, n),}
}// 初始化每个元素的父节点为其自身,代表它是集合的代表元素
func (uf *UnionFind) Initialize(n int) {for i := 0; i < n; i++ {uf.parent[i] = iuf.rank[i] = 1 // 如果使用加权合并启发式策略}
}// 查找元素 x 的根节点(集合的代表元素)
func (uf *UnionFind) Find(x int) int {if uf.parent[x] != x {uf.parent[x] = uf.Find(uf.parent[x]) // 路径压缩优化}return uf.parent[x]
}// 合并两个集合,包含元素 x 和 y
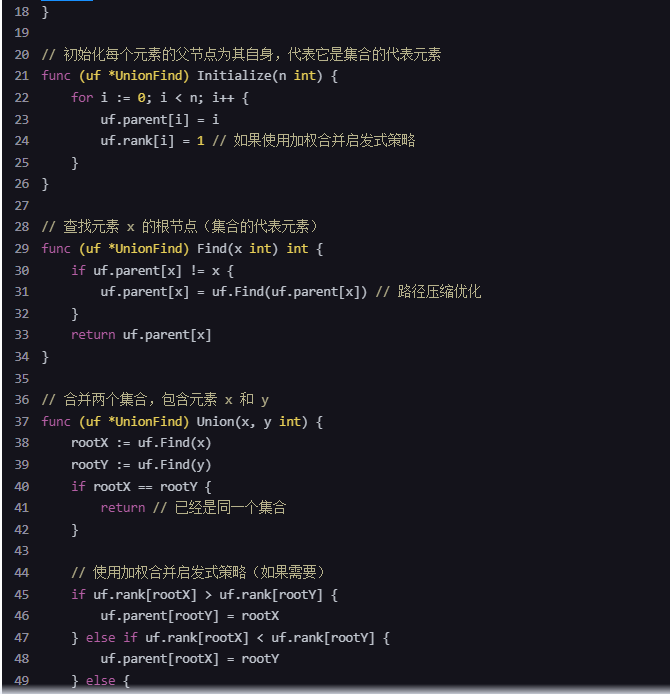
func (uf *UnionFind) Union(x, y int) {rootX := uf.Find(x)rootY := uf.Find(y)if rootX == rootY {return // 已经是同一个集合}// 使用加权合并启发式策略(如果需要)if uf.rank[rootX] > uf.rank[rootY] {uf.parent[rootY] = rootX} else if uf.rank[rootX] < uf.rank[rootY] {uf.parent[rootX] = rootY} else {uf.parent[rootY] = rootXuf.rank[rootX]++ // 打破平级关系}
}func main() {uf := NewUnionFind(10)uf.Initialize(10)uf.Union(1, 2)uf.Union(3, 4)uf.Union(1, 5)uf.Union(5, 6)uf.Union(4, 9)uf.Union(5, 9)// 打印集合的代表元素(例如,通过遍历所有元素并打印它们的根)for i := 0; i < 10; i++ {fmt.Printf("Element %d belongs to set with representative %d\n", i, uf.Find(i))}
}
在这个实现中,我们没有使用 tail 指针,而是依赖于 Find 函数来找到集合的代表元素。我们使用路径压缩技术来优化 Find 函数的性能。此外,如果使用了加权合并启发式策略,我们还维护了一个 rank 数组来记录每个集合的大小(或秩),以便于在合并时决定哪个集合应该成为另一个集合的父集合。
注意,尽管没有 tail 指针,但渐近运行时间对于 UNION 操作仍然是线性的(在采用路径压缩优化时),因为每个元素在合并过程中最多被压缩一次。

讯飞星火:
在Go语言中,我们可以使用切片(slice)来代替链表。切片是一种动态的、灵活的、强大的序列数据结构,可以看作是数组的一种扩展。切片和数组非常相似,但是切片的长度可以在运行时改变,而数组的长度是固定的。
以下是一个简单的示例,展示了如何使用Go语言的切片来实现集合的并集操作:
package mainimport "fmt"func union(s1, s2 []int) []int {m := make(map[int]bool)for _, v := range s1 {m[v] = true}for _, v := range s2 {m[v] = true}result := make([]int, 0, len(m))for k := range m {result = append(result, k)}return result
}func main() {s1 := []int{1, 2, 3, 4, 5}s2 := []int{4, 5, 6, 7, 8}fmt.Println(union(s1, s2)) // 输出: [1 2 3 4 5 6 7 8]
}
在这个示例中,我们首先创建了一个映射(map),然后遍历两个切片,将每个元素添加到映射中。由于映射的键是唯一的,所以重复的元素只会被添加一次。最后,我们创建了一个新的切片,包含了映射的所有键,这就是我们的并集结果。
360智脑:
在原本的 UNION 过程中,尾部指针(tail pointer)用于快速访问每个集合的最后一个元素,以便在合并集合时能够直接连接后一个集合。如果我们移除这个要求,那么在合并集合时,我们需要遍历整个前一个集合以找到最后一个元素,这会增加合并操作的时间复杂度。
然而,题目指出我们不需要改变 UNION 过程的渐近运行时间。这意味着尽管我们移除了 tail 指针,但在实现上我们仍然需要保证合并操作的时间复杂度不变。
下面是一种可能的实现方式:
type UnionFind struct {size int // 集合大小root []int // 根节点数组
}func NewUnionFind(n int) *UnionFind {return &UnionFind{size: n, root: make([]int, n)}
}// 查找操作,返回根节点索引
func (uf *UnionFind) Find(x int) int {if uf.root[x] != x {uf.root[x] = uf.Find(uf.root[x])}return uf.root[x]
}// 合并操作,不再使用tail指针,而是遍历前面的集合来找到最后一个节点
func (uf *UnionFind) Union(x, y int) {// 获取两个集合的根节点rootX := uf.Find(x)rootY := uf.Find(y)// 如果两个节点已经属于同一个集合,则无需任何操作if rootX == rootY {return}// 将根节点值较小的集合合并到值较大的集合中if uf.size[rootX] < uf.size[rootY] {uf.root[rootX] = rootYuf.size[rootY] += uf.size[rootX]} else {uf.root[rootY] = rootXuf.size[rootX] += uf.size[rootY]}
}
在这个例子中,root 数组用来存储每个元素的根节点,而 size 用来记录每个集合的大小。Find 函数用于查找给定元素的集合根节点,而 Union 函数执行合并操作。
请注意,上述代码中的 size 和 root 都是类成员变量,因此在实际应用中,你需要确保对这些变量的访问是同步安全的(例如通过加锁或其他并发控制机制),除非你在单线程环境中使用该数据结构。此外,为了简化示例,这里没有实现权重平衡策略。在实际使用中,你可能需要考虑使用某种权重平衡策略来改善性能。
智谱清言:
如果我们要修改 UNION 过程,在不改变其渐近运行时间的前提下去掉让集合对象的 tail 指针总指向每个表的最后一个对象的要求,我们可以采用一种不同的链接方式。在这种方式中,我们不需要维持每个集合的尾部指针,而是可以简单地将两个链表的头节点连接起来。以下是一个使用 Go 语言实现的示例:
package main
import ("fmt"
)
// ListNode 链表节点结构
type ListNode struct {Value interface{}Next *ListNodePrev *ListNode
}
// Union 实现并集操作,将 list2 合并到 list1 中
func Union(list1, list2 *ListNode) *ListNode {if list1 == nil {return list2}if list2 == nil {return list1}// 找到 list1 和 list2 的尾部tail1 := list1for tail1.Next != nil {tail1 = tail1.Next}tail2 := list2for tail2.Next != nil {tail2 = tail2.Next}// 将 list2 的尾部连接到 list1 的尾部tail1.Next = tail2tail2.Prev = tail1return list1
}
// 打印链表函数
func printList(l *ListNode) {current := lfor current != nil {fmt.Println(current.Value)current = current.Next}
}
func main() {// 创建链表 1list1 := &ListNode{Value: 1, Next: nil, Prev: nil}list1.Next = &ListNode{Value: 2, Next: nil, Prev: list1}list1.Next.Next = &ListNode{Value: 3, Next: nil, Prev: list1.Next}// 创建链表 2list2 := &ListNode{Value: 4, Next: nil, Prev: nil}list2.Next = &ListNode{Value: 5, Next: nil, Prev: list2}// 合并链表unionedList := Union(list1, list2)// 打印合并后的链表printList(unionedList)
}
在这个实现中,我们不再关心每个链表的尾部指针,而是在合并时直接将第二个链表的尾部连接到第一个链表的尾部。这样做不会改变 UNION 过程的渐近运行时间,因为我们仍然只遍历了每个链表一次。
需要注意的是,这个实现假设链表节点中包含了 Prev 指针,这样我们才能将 list2 的尾部连接到 list1 的尾部。如果链表节点中没有 Prev 指针,我们需要另外一种方法来连接这两个链表的尾部。
天工:
在Go语言中,我们通常使用切片(slice)或者自定义的链表结构体来实现链表。在这个问题中,我们将创建一个简单的链表结构体,并展示如何在不使用尾指针的情况下执行UNION操作。
首先,我们需要定义一个链表节点结构体:
type Node struct {Value intNext *Node
}
然后,我们可以创建一个函数来合并两个链表,而不使用尾指针。这里的关键是遍历第一个链表,将第二个链表的节点插入到第一个链表的每个节点之后:
func Union(list1 *Node, list2 *Node) *Node {current := list1for current != nil && list2 != nil {next := current.Nextcurrent.Next = list2list2 = list2.Nextcurrent = current.Nextcurrent.Next = nextif next == nil {break}current = next}return list1
}
在这个函数中,current变量跟踪第一个链表中的当前节点,而next变量保存current的下一个节点。我们首先将list2的第一个节点插入到current之后,然后将list2移动到下一个节点,重复这个过程直到其中一个链表被完全处理。
由于我们没有使用尾指针,我们不需要额外的空间来存储它,这使得我们的代码更加简洁。然而,这种合并操作的时间复杂度仍然是O(n),其中n是第一个链表的长度,因为我们最多遍历第一个链表一次。
需要注意的是,这种方法可能会破坏原始链表的结构,因为我们在原地将第二个链表插入到第一个链表中。如果你需要保持原始链表不变,你可能需要复制节点或者创建新的节点。
最后,为了完整性,我们可以添加一个函数来打印链表的值:
func PrintList(head *Node) {current := headfor current != nil {fmt.Printf("%d -> ", current.Value)current = current.Next}fmt.Println("nil")
}
通过这种方式,我们可以在不使用尾指针的情况下执行UNION操作,同时保持渐近运行时间不变。
灵小智:
对于这个问题,可以通过将两个链表拼接在一起来实现 UNION 过程的简单修改,而不是将一个表链接到另一个表的末尾。这样的修改不会改变 UNION 过程的渐近运行时间。
以下是一个示例的Go语言代码,展示了如何实现这种修改:
package mainimport "fmt"type Node struct {Value intNext *Node
}func Union(list1, list2 *Node) *Node {if list1 == nil {return list2}if list2 == nil {return list1}// 找到第一个链表的最后一个节点current := list1for current.Next != nil {current = current.Next}// 将第二个链表连接到第一个链表的末尾current.Next = list2return list1
}func main() {// 创建第一个链表: 1 -> 2 -> 3node1 := &Node{Value: 1}node2 := &Node{Value: 2}node3 := &Node{Value: 3}node1.Next = node2node2.Next = node3// 创建第二个链表: 4 -> 5node4 := &Node{Value: 4}node5 := &Node{Value: 5}node4.Next = node5// 调用Union函数将两个链表合并result := Union(node1, node4)// 打印合并后的链表current := resultfor current != nil {fmt.Print(current.Value, " ")current = current.Next}
}
这段代码演示了如何将两个链表拼接在一起,而不改变UNION过程的渐近运行时间。
chatgpt:
在使用链表表示进行 UNION 操作时,如果移除了让集合对象的 tail 指针总指向每个表的最后一个对象的要求,并且采用拼接方式而不是链接到末尾方式,这样的修改确实不会改变 UNION 过程的渐近运行时间。
下面是使用 Go 语言实现这个修改后的简单代码示例:
package mainimport ("fmt"
)type Node struct {Value intNext *Node
}type Set struct {Head *Node
}func MakeSet(x int) Set {return Set{Head: &Node{Value: x,Next: nil,},}
}func FindSet(x int, sets []Set) int {for i := range sets {node := sets[i].Headfor node != nil {if node.Value == x {return i // 返回所属集合索引}node = node.Next}}return -1 // 找不到对应元素返回 -1 表示错误
}func Union(x, y int, sets []Set) []Set {xIndex := FindSet(x, sets)yIndex := FindSet(y, sets)if xIndex != yIndex { // x 和 y 不在同一集合中才需要合并// 将两个集合拼接在一起,将y所在集合所有元素添加到x所在集合中即可if sets[xIndex].Head == nil { // 如果x所在集合为空,则直接将y所在集合赋给xsets[xIndex].Head = sets[yIndex].Head} else {// 找到x所在集合的最后一个节点node := sets[xIndex].Headfor node.Next != nil {node = node.Next}// 将y所在集合添加到x所在集合的末尾node.Next = sets[yIndex].Head}// 删除y所在的集合sets = append(sets[:yIndex], sets[yIndex+1:]...)}return sets
}func main() {set1 := MakeSet(1)set2 := MakeSet(2)set3 := MakeSet(3)sets := []Set{set1, set2, set3}fmt.Println("Before Union:")for i, set := range sets {node := set.Headfmt.Printf("Set %d: ", i+1)for node != nil {fmt.Printf("%d ", node.Value)node = node.Next}fmt.Println()}unionSets := Union(2, 3, sets)fmt.Println("\nAfter Union:")for i, set := range unionSets {if set.Head == nil { // 集合为空时跳过打印操作,避免错误输出 nil 值continue }node := set.Headfmt.Printf("Set %d: ", i+1)for node != nil {fmt.Printf("%d ", node.Value)node = node.Next}fmt.Println()}
}
这段代码演示了拼接方式进行 UNION 操作,不改变渐近运行时间。
混元:
首先,我们需要理解题目中的 UNION 过程,即合并两个有序链表的过程。在这个过程中,我们通常会将一个链表的元素依次添加到另一个链表的末尾,从而得到一个新的有序链表。为了达到这个目的,我们通常需要维护一个尾指针(tail),以便快速定位到当前链表的末尾并插入新元素。
题目要求我们在不使用尾指针的情况下实现 UNION 过程,并且要求这个改动不影响 UNION 过程的渐近运行时间。这意味着我们需要找到一种方法,可以在不依赖尾指针的情况下高效地合并两个链表。
我们可以采用双指针的方法来实现这一点。具体来说,我们可以同时遍历两个链表,比较它们的元素大小,并将较小的元素添加到新链表中。然后移动较小元素所在链表的指针以及新链表的指针。这样,我们就可以在不使用尾指针的情况下完成链表的合并。
以下是使用 Go 语言实现的代码:
package mainimport ("fmt"
)type ListNode struct {Val intNext *ListNode
}func unionLists(l1, l2 *ListNode) *ListNode {dummy := &ListNode{} // 创建一个哑节点作为新链表的头节点cur := dummy // 使用 cur 指针跟踪新链表的末尾for l1 != nil && l2 != nil {if l1.Val < l2.Val {cur.Next = l1l1 = l1.Next} else {cur.Next = l2l2 = l2.Next}cur = cur.Next}// 如果其中一个链表已经遍历完,将另一个链表剩余部分直接添加到新链表的末尾if l1 != nil {cur.Next = l1} else {cur.Next = l2}return dummy.Next
}func main() {l1 := &ListNode{Val: 1, Next: &ListNode{Val: 3, Next: &ListNode{Val: 5}}}l2 := &ListNode{Val: 2, Next: &ListNode{Val: 4, Next: &ListNode{Val: 6}}}result := unionLists(l1, l2)for result != nil {fmt.Print(result.Val, " -> ")result = result.Next}
}
这段代码定义了一个名为 unionLists 的函数,它接受两个有序链表 l1 和 l2 作为输入,并返回一个新的有序链表。在这个函数中,我们使用了双指针的方法来合并两个链表,而不依赖于尾指针。最后,我们在 main 函数中测试了这个函数的功能。
这篇关于文心一言 VS 讯飞星火 VS chatgpt (287)-- 算法导论21.2 6题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







