本文主要是介绍数据结构5---矩阵和广义表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、矩阵的压缩存储
特殊矩阵:矩阵中很多值相同的元素并且它们的分布有一定的规律。
稀疏矩阵:矩阵中有很多零元素。压缩存储的基本思想是:
(1)为多个值相同的元素只分配一个存储空间;
(2)对零元素不分配存储空间。
1、特殊矩阵的压缩存储
(1)对称矩阵
只存储下三角部分的元素

存储结构
对于下三角的元素aij(i>=j),在数组中的下标与i,j关系为 k = i*(i-1)/2 + j-1
上三角的元素aij(i<j),因为aij = aji,则访问它的元素aji即可,即:k = j*(j-1)/2+i - 1
(2)三角矩阵
只存储上三角(或下三角)部分的元素
下三角矩阵
存储:
1.下三角元素 2.对角线上方的常数
矩阵中的任一元素aij在数组中的下标k与i,j的对应关系
当i>=j时 k=i*(i-1)/2+j-1
当i<j k=n*(n+1)/2
上三角矩阵
存储:
1.上三角元素 2.对角线下方的常数
矩阵中的任一元素aij在数组中的下标k与i,j的对应关系
当i<=j时 k=(i-1)*(2n-i+2)/2+j-1
当i>j k=n*(n+1)/2
(3)对角矩阵
对角矩阵:所有非零元素都集中在以主对角线为中心的带状区域中,除了主对角线和它的上下方若干条对角线的元素外,所有其他元素都为零。

(4)稀疏矩阵

我们定义了一个三元组
struct Triple
{int row,col; //行和列DataType item; //值
};三元组表:将稀疏矩阵的非零元素对应的三元组所构成的集合,按行优先的顺序排列成一个线性表。
采用顺序存储结构存储三元组表

三元顺序表的存储结构定义
const int MAX = 100;
struct SparseMatrix
{struct Triple data[MAX]; //存储非零元素int mu,nu,num; //行数,列数,非零元素个数
};这种存储方法的缺点是:进行矩阵加法、减法等操作时,非零元素的个数和位置都会发生变化,顺序存储法就非常不方便了。
2、十字链表
采用链接存储结构存储三元组表,每个非零元素对应的三元组存储为一个链表结点,结构为:
| row | col | item |
| down | right | |
row:存储非零元素的行号
col:存储非零元素的列号
item:存储非零元素的值
right:指针域,指向同一行中的下一个三元组
down:指针域,指向同一列中的下一个三元组

定义结构体
#define ElementType inttypedef struct OLNode
{int row;//1~mint col;//1~nElementType value;struct OLNode *right, *down;//非零元素所在行,列后继链域
}OLNode, *OLink;typedef struct CrossList
{OLink* row_head, *col_head;//行,列链表的头指针向量int m;//行数int n;//列数int len;//非零元素个数
}CrossList;代码实现
//稀疏矩阵的链式存储结构:十字链表
#include <stdio.h>
#include <stdlib.h>
#include <string.h>#define ElementType inttypedef struct OLNode
{int row;//1~mint col;//1~nElementType value;struct OLNode *right, *down;//非零元素所在行,列后继链域
}OLNode, *OLink;typedef struct CrossList
{OLink* row_head, *col_head;//行,列链表的头指针向量int m;//行数int n;//列数int len;//非零元素个数
}CrossList;void CreatCrossList(CrossList* M, int m, int n, int len)
{M->m = m;M->n = n;M->len = len;if(!(M->row_head = (OLink*)malloc((m + 1) * sizeof(OLink)))){perror("row_head");exit(-1);}if(!(M->col_head = (OLink*)malloc((n + 1) * sizeof(OLink)))){perror("col_head");exit(-1);}memset(M->row_head, 0, (m + 1) * sizeof(OLink));memset(M->col_head, 0, (n + 1) * sizeof(OLink));//初始化为空链表int i = 0, j = 0, e = 0;//结点的行,列,值printf("请输入结点的行号,列号,值:\n");while(len){scanf("%d %d %d", &i, &j, &e);if(i < 1||i > m||j < 1||j > n){printf("行列号不合法,请重新输入:\n");continue;}int flag = 0;//检查位置是否重复for(OLNode* k = M->row_head[i]; k != NULL; k = k->right){if(k->col == j)flag = 1;}if(flag){printf("结点位置重复,请重新输入:\n");continue;}OLNode* p = (OLNode*)malloc(sizeof(OLNode));//申请结点if(p == NULL){perror("Node application");exit(-1);}p->row = i; p->col = j; p->value = e;p->right = p->down = NULL;//行链表插入if(M->row_head[i] == NULL)//该行还没有结点{M->row_head[i] = p;}else if(p->col < M->row_head[i]->col)//新建结点列号<该行首结点列号{p->right = M->row_head[i];M->row_head[i] = p;}else//寻找插入位置{OLNode* q;for(q = M->row_head[i]; q->right && q->right->col < j; q = q->right);p->right = q->right;q->right = p;}//列链表插入if(M->col_head[j] == NULL)//该列还没有结点{M->col_head[j] = p;}else if(p->row < M->col_head[j]->row)//新建结点行号<改行首节点行号{p->down = M->col_head[j];M->col_head[j] = p;}else//寻找插入位置{OLNode* q;for(q = M->col_head[j]; q->down && q->down->row < i; q = q->down)p->down = q->down;p->down = p;}len--;printf("插入成功!\n");printf("请输入结点的行号,列号,值:\n");}}void PrintCrossList(CrossList* M)//打印十字链表
{for(int row = 0; row < M->m; row++){OLNode* p = M->row_head[row];while(p != NULL){printf("(%d, %d)=%d ", p->row, p->col, p->value);p = p->right;}printf("\n");}
}int main()
{CrossList M;CreatCrossList(&M, 10, 10, 10);PrintCrossList(&M);return 0;
}3、快速转置
在顺序结构里转置
(1)简单转置
按矩阵source的列序进行转置

算法实现
SparseMatrix source,dest;
int q = 1;
for(col=1;col<=source.nu;col++)
{for(p=1;p<=source.num;p++){if(source.data[p].col==col){dest.data[q].row = source.data[p].col;dest.data[q].col = source.data[p].row;dest.data[q].e = source.data[p].e;q++;}}}(2)快速转置
按矩阵source的行序进行转置

方法:增加2个辅助向量


这里的cPos[col]为:1 3 5 7 8 8 9

-3一定是第一个,12一定是第三个....
cPos算法:
cPos[1] = 1;
for(col = 2;col <= source.nu; col++)
{cPos[col] = cPos[col-1]+cNum[col-1];
}cNum算法:
for(col = 1;col <= source.nu; ++col) cNum[col]=0; //初始化全为0
for(sPos = 1;sPos <= source.number;++sPos)++cNum[source.data[sPos].col]; //就是按列遍历整个三元组,列号为几,就在对应的cNum上++
就是找位置,找到对应位置后,其相应的cPs+1
二、广义表
1、定义
广义表又称列表,也是一种线性存储结构,通数组类似,广义表中即可存储不可再分的元素也能存储可在分元素。
例如:数组中可以存储‘a’、3这样的字符或数字,也能存储数组,比如二维数组、三维数组,数组都是可在分成子元素的。广义表也是如此,但与数组不同的是,在广义表中存储的数据是既可以再分也可以不再分的,形如:{1,{1,2,3}}。
广义表记作:
LS = (a1,a2,…,an)
2、原子和子表
广义表中存储的单个元素称为 "原子",而存储的广义表称为 "子表"。
例如创建一个广义表 LS = {1,{1,2,3}},我们可以这样解释此广义表的构成:广义表 LS 存储了一个原子 1 和子表 {1,2,3}。
以下是广义表存储数据的一些常用形式:
- A = ():A 表示一个广义表,只不过表是空的。
- B = (e):广义表 B 中只有一个原子 e。
- C = (a,(b,c,d)) :广义表 C 中有两个元素,原子 a 和子表 (b,c,d)。
- D = (A,B,C):广义表 D 中存有 3 个子表,分别是A、B和C。这种表示方式等同于 D = ((),(e),(b,c,d)) 。
- E = (a,E):广义表 E 中有两个元素,原子 a 和它本身。这是一个递归广义表,等同于:E = (a,(a,(a,…)))。
注意,A = () 和 A = (()) 是不一样的。前者是空表,而后者是包含一个子表的广义表,只不过这个子表是空表。
3、表头和表尾
当广义表不是空表时,称第一个数据(原子或子表)为"表头",剩下的数据构成的新广义表为"表尾"。
强调一下,除非广义表为空表,否则广义表一定具有表头和表尾,且广义表的表尾一定是一个广义表。
例如在广义表中 LS={1,{1,2,3},5} 中,表头为原子 1,表尾为子表 {1,2,3} 和原子 5 构成的广义表,即 {{1,2,3},5}。
再比如,在广义表 LS = {1} 中,表头为原子 1 ,但由于广义表中无表尾元素,因此该表的表尾是一个空表,用 {} 表示。
4、广义表的存储结构
使用顺序表实现广义表结构,不仅需要操作 n 维数组(例如 {1,{2,{3,4}}} 就需要使用三维数组存储),还会造成存储空间的浪费。

typedef struct GLNode{int tag;//标志域union{char atom;//原子结点的值域struct{struct GLNode * hp,*tp;}ptr;//子表结点的指针域,hp指向表头;tp指向表尾}subNode;
}*Glist;这里用到了 union 共用体,因为同一时间此节点不是原子节点就是子表节点,当表示原子节点时,就使用 atom 变量;反之则使用 ptr 结构体。
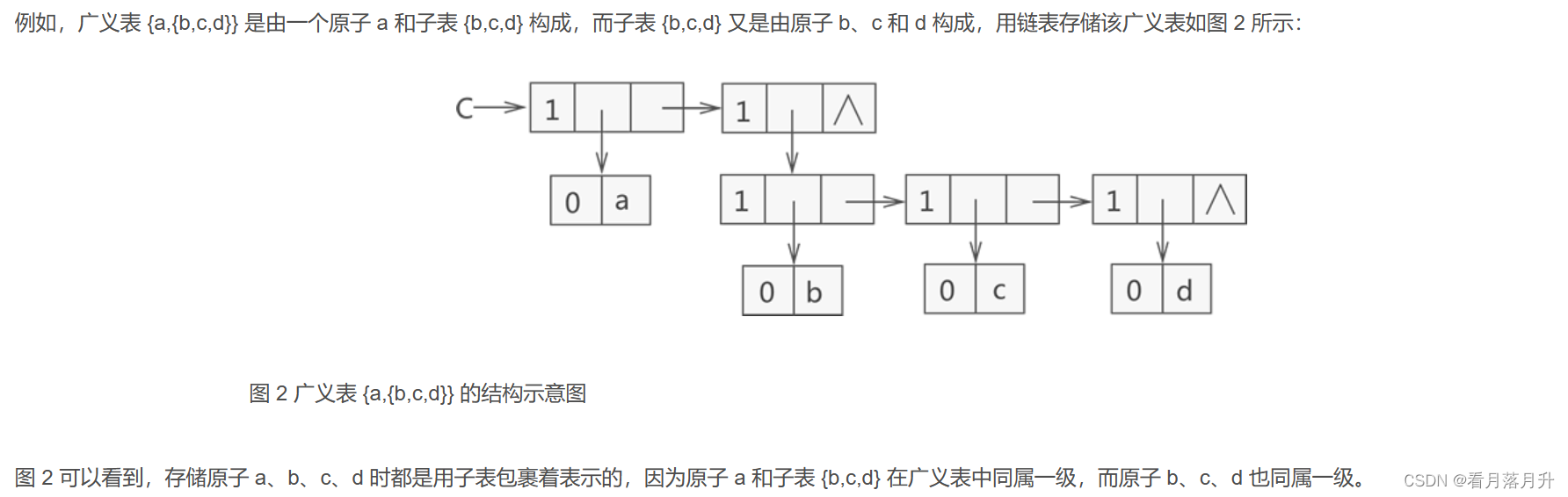
Glist creatGlist(Glist C) {//广义表CC = (Glist)malloc(sizeof(Glist));C->tag = 1;//表头原子‘a’C->subNode.ptr.hp = (Glist)malloc(sizeof(Glist));C->subNode.ptr.hp->tag = 0;C->subNode.ptr.hp->subNode.atom = 'a';//表尾子表(b,c,d),是一个整体C->subNode.ptr.tp = (Glist)malloc(sizeof(Glist));C->subNode.ptr.tp->tag = 1;C->subNode.ptr.tp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist));C->subNode.ptr.tp->subNode.ptr.tp = NULL;//开始存放下一个数据元素(b,c,d),表头为‘b’,表尾为(c,d)C->subNode.ptr.tp->subNode.ptr.hp->tag = 1;C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist));C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.hp->tag = 0;C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.hp->subNode.atom = 'b';C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp = (Glist)malloc(sizeof(Glist));//存放子表(c,d),表头为c,表尾为dC->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->tag = 1;C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist));C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.hp->tag = 0;C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.hp->subNode.atom = 'c';C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp = (Glist)malloc(sizeof(Glist));//存放表尾dC->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->tag = 1;C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.hp = (Glist)malloc(sizeof(Glist));C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.hp->tag = 0;C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.hp->subNode.atom = 'd';C->subNode.ptr.tp->subNode.ptr.hp->subNode.ptr.tp->subNode.ptr.tp->subNode.ptr.tp = NULL;return C;
}4、长度
广义表的长度,指的是广义表中所包含的数据元素的个数。
由于广义表中可以同时存储原子和子表两种类型的数据,因此在计算广义表的长度时规定,广义表中存储的每个原子算作一个数据,同样每个子表也只算作是一个数据。
例如,在广义表 {a,{b,c,d}} 中,它包含一个原子和一个子表,因此该广义表的长度为 2。
再比如,广义表 {{a,b,c}} 中只有一个子表 {a,b,c},因此它的长度为 1。
前面我们用 LS={a1,a2,...,an} 来表示一个广义表,其中每个 ai 都可用来表示一个原子或子表,其实它还可以表示广义表 LS 的长度为 n。广义表规定,空表 {} 的长度为 0。
5、深度
由于这个不做考试内容,分享一个博客
数据结构-广义表-CSDN博客![]() https://blog.csdn.net/qq_51701007/article/details/126352030?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171894059816800211521274%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171894059816800211521274&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-126352030-null-null.142%5Ev100%5Epc_search_result_base5&utm_term=%E5%B9%BF%E4%B9%89%E8%A1%A8&spm=1018.2226.3001.4187
https://blog.csdn.net/qq_51701007/article/details/126352030?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522171894059816800211521274%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=171894059816800211521274&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-126352030-null-null.142%5Ev100%5Epc_search_result_base5&utm_term=%E5%B9%BF%E4%B9%89%E8%A1%A8&spm=1018.2226.3001.4187
这篇关于数据结构5---矩阵和广义表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







