本文主要是介绍使用SimCLR用对比预训练模型实现半监督图像分类的代码实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
因公众号更改了推送规则,记得读完点“在看”~下次AI公园的新文章就能及时出现在您的订阅列表中
作者:András Béres
编译:ronghuaiyang
导读
在STL-10数据集上用SimCLR先做对比训练,再进行少量标注数据的监督训练微调。
半监督学习
半监督学习是一种处理部分标记数据集的机器学习范式。当在现实世界中应用深度学习时,通常需要收集一个大型数据集才能使其正常工作。然而,标记的代价随着数据集的大小线性增长(标记每个示例需要一个常数时间),模型性能只会随着数据集的大小呈次线性增长(https://arxiv.org/abs/2001.08361)。这意味着标记越来越多的样本变得越来越没有成本效益,而收集未标记的数据通常是便宜的,因为它通常很容易大量获得。
半监督学习通过只需要一个部分标记的数据集来解决这个问题,并且通过利用未标记的样本来进行有效的学习。
在这个例子中,我们将使用完全不使用标签的STL-10半监督数据集上的对比学习对编码器进行预训练,然后只使用其标签子集对其进行微调。
对比学习
在最高层次上,对比学习背后的主要思想是以自我监督的方式学习对图像增强不变性的表示。这个目标的一个问题是它有一个简单的退化解:在这个表示是常数的情况下,根本不依赖于输入图像。
对比学习通过如下方式修改目标来避免这个陷阱:它将同一图像的增强版本/视图的表征彼此拉近(收缩正样本),同时将不同图像彼此分开(差异化负样本)。
SimCLR就是这样一种对比方法,它从本质上确定了优化这一目标所需的核心组件,并可以通过扩展这种简单方法实现高性能。
另一种方法是SimSiam,它与SimCLR的主要区别在于前者没有在其损失中使用任何负样本。因此,它并不能显式地阻止出现退化解,相反,通过架构设计,使用预测器网络的非对称编码路径和在最后的层中应用批标准化(BatchNorm))隐式地避免了它。
设置
import matplotlib.pyplot as plt
import tensorflow as tf
import tensorflow_datasets as tfdsfrom tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.layers.experimental import preprocessing
超参数
# Dataset hyperparameters
unlabeled_dataset_size = 100000
labeled_dataset_size = 5000
image_size = 96
image_channels = 3# Algorithm hyperparameters
num_epochs = 20
batch_size = 525 # Corresponds to 200 steps per epoch
width = 128
temperature = 0.1
# Stronger augmentations for contrastive, weaker ones for supervised training
contrastive_augmentation = {"min_area": 0.25, "brightness": 0.6, "jitter": 0.2}
classification_augmentation = {"min_area": 0.75, "brightness": 0.3, "jitter": 0.1}
数据集
在训练过程中,我们将同时加载大量未标记图像和少量标记图像。
def prepare_dataset():# Labeled and unlabeled samples are loaded synchronously# with batch sizes selected accordinglysteps_per_epoch = (unlabeled_dataset_size + labeled_dataset_size) // batch_sizeunlabeled_batch_size = unlabeled_dataset_size // steps_per_epochlabeled_batch_size = labeled_dataset_size // steps_per_epochprint(f"batch size is {unlabeled_batch_size} (unlabeled) + {labeled_batch_size} (labeled)")unlabeled_train_dataset = (tfds.load("stl10", split="unlabelled", as_supervised=True, shuffle_files=True).shuffle(buffer_size=10 * unlabeled_batch_size).batch(unlabeled_batch_size))labeled_train_dataset = (tfds.load("stl10", split="train", as_supervised=True, shuffle_files=True).shuffle(buffer_size=10 * labeled_batch_size).batch(labeled_batch_size))test_dataset = (tfds.load("stl10", split="test", as_supervised=True).batch(batch_size).prefetch(buffer_size=tf.data.AUTOTUNE))# Labeled and unlabeled datasets are zipped togethertrain_dataset = tf.data.Dataset.zip((unlabeled_train_dataset, labeled_train_dataset)).prefetch(buffer_size=tf.data.AUTOTUNE)return train_dataset, labeled_train_dataset, test_dataset# Load STL10 dataset
train_dataset, labeled_train_dataset, test_dataset = prepare_dataset()
batch size is 500 (unlabeled) + 25 (labeled)
图像增强
对比学习中最重要的两种图像增强方法如下:
裁剪:迫使模型对同一幅图像的不同部分进行同样的编码,我们实现用RandomTranslation和RandomZoom层来实现。
颜色抖动:通过扭曲颜色直方图来防止任务中基于颜色直方图的简单解决方案。实现这一点的一个原则方法是在颜色空间中进行仿射变换。
在这个例子中,我们也使用了随机水平翻转。较强的增强用于对比学习,较弱的增强用于监督分类,以避免在少数有标记的例子上过拟合。
我们实现随机颜色抖动作为自定义预处理层。使用预处理层进行数据增强有以下两个优点:
数据增强将在GPU上批量运行,所以训练不会在CPU资源受限的环境(如Colab笔记本,或个人机器)中被数据管道所阻碍。
部署更容易,因为数据预处理管道封装在模型中,并且在部署时不必重新实现。
# Distorts the color distibutions of images
class RandomColorAffine(layers.Layer):def __init__(self, brightness=0, jitter=0, **kwargs):super().__init__(**kwargs)self.brightness = brightnessself.jitter = jitterdef call(self, images, training=True):if training:batch_size = tf.shape(images)[0]# Same for all colorsbrightness_scales = 1 + tf.random.uniform((batch_size, 1, 1, 1), minval=-self.brightness, maxval=self.brightness)# Different for all colorsjitter_matrices = tf.random.uniform((batch_size, 1, 3, 3), minval=-self.jitter, maxval=self.jitter)color_transforms = (tf.eye(3, batch_shape=[batch_size, 1]) * brightness_scales+ jitter_matrices)images = tf.clip_by_value(tf.matmul(images, color_transforms), 0, 1)return images# Image augmentation module
def get_augmenter(min_area, brightness, jitter):zoom_factor = 1.0 - tf.sqrt(min_area)return keras.Sequential([keras.Input(shape=(image_size, image_size, image_channels)),preprocessing.Rescaling(1 / 255),preprocessing.RandomFlip("horizontal"),preprocessing.RandomTranslation(zoom_factor / 2, zoom_factor / 2),preprocessing.RandomZoom((-zoom_factor, 0.0), (-zoom_factor, 0.0)),RandomColorAffine(brightness, jitter),])def visualize_augmentations(num_images):# Sample a batch from a datasetimages = next(iter(train_dataset))[0][0][:num_images]# Apply augmentationsaugmented_images = zip(images,get_augmenter(**classification_augmentation)(images),get_augmenter(**contrastive_augmentation)(images),get_augmenter(**contrastive_augmentation)(images),)row_titles = ["Original:","Weakly augmented:","Strongly augmented:","Strongly augmented:",]plt.figure(figsize=(num_images * 2.2, 4 * 2.2), dpi=100)for column, image_row in enumerate(augmented_images):for row, image in enumerate(image_row):plt.subplot(4, num_images, row * num_images + column + 1)plt.imshow(image)if column == 0:plt.title(row_titles[row], loc="left")plt.axis("off")plt.tight_layout()visualize_augmentations(num_images=8)

编码器结构
# Define the encoder architecture
def get_encoder():return keras.Sequential([keras.Input(shape=(image_size, image_size, image_channels)),layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),layers.Conv2D(width, kernel_size=3, strides=2, activation="relu"),layers.Flatten(),layers.Dense(width, activation="relu"),],name="encoder",)
有监督的基线模型
使用随机初始化方法训练基线监督模型。
# Baseline supervised training with random initialization
baseline_model = keras.Sequential([keras.Input(shape=(image_size, image_size, image_channels)),get_augmenter(**classification_augmentation),get_encoder(),layers.Dense(10),],name="baseline_model",
)
baseline_model.compile(optimizer=keras.optimizers.Adam(),loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=[keras.metrics.SparseCategoricalAccuracy(name="acc")],
)baseline_history = baseline_model.fit(labeled_train_dataset, epochs=num_epochs, validation_data=test_dataset
)
print("Maximal validation accuracy: {:.2f}%".format(max(baseline_history.history["val_acc"]) * 100)
)
Epoch 1/20
200/200 [==============================] - 8s 26ms/step - loss: 2.1769 - acc: 0.1794 - val_loss: 1.7424 - val_acc: 0.3341
Epoch 2/20
200/200 [==============================] - 3s 16ms/step - loss: 1.8366 - acc: 0.3139 - val_loss: 1.6184 - val_acc: 0.3989
Epoch 3/20
200/200 [==============================] - 3s 16ms/step - loss: 1.6331 - acc: 0.3912 - val_loss: 1.5344 - val_acc: 0.4125
Epoch 4/20
200/200 [==============================] - 3s 16ms/step - loss: 1.5439 - acc: 0.4216 - val_loss: 1.4052 - val_acc: 0.4712
Epoch 5/20
200/200 [==============================] - 4s 17ms/step - loss: 1.4576 - acc: 0.4575 - val_loss: 1.4337 - val_acc: 0.4729
Epoch 6/20
200/200 [==============================] - 3s 17ms/step - loss: 1.3723 - acc: 0.4875 - val_loss: 1.4054 - val_acc: 0.4746
Epoch 7/20
200/200 [==============================] - 3s 17ms/step - loss: 1.3445 - acc: 0.5066 - val_loss: 1.3030 - val_acc: 0.5200
Epoch 8/20
200/200 [==============================] - 3s 17ms/step - loss: 1.3015 - acc: 0.5255 - val_loss: 1.2720 - val_acc: 0.5378
Epoch 9/20
200/200 [==============================] - 3s 16ms/step - loss: 1.2244 - acc: 0.5452 - val_loss: 1.3211 - val_acc: 0.5220
Epoch 10/20
200/200 [==============================] - 3s 17ms/step - loss: 1.2204 - acc: 0.5494 - val_loss: 1.2898 - val_acc: 0.5381
Epoch 11/20
200/200 [==============================] - 4s 17ms/step - loss: 1.1359 - acc: 0.5766 - val_loss: 1.2138 - val_acc: 0.5648
Epoch 12/20
200/200 [==============================] - 3s 17ms/step - loss: 1.1228 - acc: 0.5855 - val_loss: 1.2602 - val_acc: 0.5429
Epoch 13/20
200/200 [==============================] - 3s 17ms/step - loss: 1.0853 - acc: 0.6000 - val_loss: 1.2716 - val_acc: 0.5591
Epoch 14/20
200/200 [==============================] - 3s 17ms/step - loss: 1.0632 - acc: 0.6078 - val_loss: 1.2832 - val_acc: 0.5591
Epoch 15/20
200/200 [==============================] - 3s 16ms/step - loss: 1.0268 - acc: 0.6157 - val_loss: 1.1712 - val_acc: 0.5882
Epoch 16/20
200/200 [==============================] - 3s 17ms/step - loss: 0.9594 - acc: 0.6440 - val_loss: 1.2904 - val_acc: 0.5573
Epoch 17/20
200/200 [==============================] - 3s 17ms/step - loss: 0.9524 - acc: 0.6517 - val_loss: 1.1854 - val_acc: 0.5955
Epoch 18/20
200/200 [==============================] - 3s 17ms/step - loss: 0.9118 - acc: 0.6672 - val_loss: 1.1974 - val_acc: 0.5845
Epoch 19/20
200/200 [==============================] - 3s 17ms/step - loss: 0.9187 - acc: 0.6686 - val_loss: 1.1703 - val_acc: 0.6025
Epoch 20/20
200/200 [==============================] - 3s 17ms/step - loss: 0.8520 - acc: 0.6911 - val_loss: 1.1312 - val_acc: 0.6149
Maximal validation accuracy: 61.49%
用自监督模型进行对比学习
我们对未标记的图像进行对比损失的预训练。一个非线性投影头被附加到编码器的顶部,因为它提高了编码器表示的质量。
我们使用InfoNCE/NT-Xent/N-pairs损失,可以用以下方式解释:
我们将批处理中的每个图像视为它有自己的类。
然后,我们为每个“类”提供两个示例(一对增强视图)。
每个视图的表示与每个可能的对的表示相比较(对于两个增强版本)。
我们使用这一对表示的余弦相似度的温度缩放后的值作为logits。
最后,我们使用分类交叉熵作为“分类”损失。
以下两个指标用于监控训练前的性能:
对比精度(SimCLR表5):自监督度量,图像的表示与当前批处理中任何其他图像的表示更相似的情况的比率。即使在没有标记样本的情况下,自我监督度量也可以用于超参数调优。
线性探测精度:线性探测是评价自我监督分类器的流行指标。它是作为在编码器的特征之上训练的逻辑回归分类器的精度计算的。在我们的例子中,这是通过在冻结的编码器上训练单一的dense层来完成的。请注意,与传统方法不同,传统方法是在预处理阶段之后训练分类器,在这个例子中,我们在预处理阶段训练它。这可能会略微降低它的准确性,但这样我们就可以在训练期间监控它的价值,这有助于实验和调试。
另一个广泛使用的监督度量是KNN精度,它是在编码器特征之上训练的KNN分类器的精度,在本例中没有实现。
# Define the contrastive model with model-subclassing
class ContrastiveModel(keras.Model):def __init__(self):super().__init__()self.temperature = temperatureself.contrastive_augmenter = get_augmenter(**contrastive_augmentation)self.classification_augmenter = get_augmenter(**classification_augmentation)self.encoder = get_encoder()# Non-linear MLP as projection headself.projection_head = keras.Sequential([keras.Input(shape=(width,)),layers.Dense(width, activation="relu"),layers.Dense(width),],name="projection_head",)# Single dense layer for linear probingself.linear_probe = keras.Sequential([layers.Input(shape=(width,)), layers.Dense(10)], name="linear_probe")self.encoder.summary()self.projection_head.summary()self.linear_probe.summary()def compile(self, contrastive_optimizer, probe_optimizer, **kwargs):super().compile(**kwargs)self.contrastive_optimizer = contrastive_optimizerself.probe_optimizer = probe_optimizer# self.contrastive_loss will be defined as a methodself.probe_loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)self.contrastive_loss_tracker = keras.metrics.Mean(name="c_loss")self.contrastive_accuracy = keras.metrics.SparseCategoricalAccuracy(name="c_acc")self.probe_loss_tracker = keras.metrics.Mean(name="p_loss")self.probe_accuracy = keras.metrics.SparseCategoricalAccuracy(name="p_acc")@propertydef metrics(self):return [self.contrastive_loss_tracker,self.contrastive_accuracy,self.probe_loss_tracker,self.probe_accuracy,]def contrastive_loss(self, projections_1, projections_2):# InfoNCE loss (information noise-contrastive estimation)# NT-Xent loss (normalized temperature-scaled cross entropy)# Cosine similarity: the dot product of the l2-normalized feature vectorsprojections_1 = tf.math.l2_normalize(projections_1, axis=1)projections_2 = tf.math.l2_normalize(projections_2, axis=1)similarities = (tf.matmul(projections_1, projections_2, transpose_b=True) / self.temperature)# The similarity between the representations of two augmented views of the# same image should be higher than their similarity with other viewsbatch_size = tf.shape(projections_1)[0]contrastive_labels = tf.range(batch_size)self.contrastive_accuracy.update_state(contrastive_labels, similarities)self.contrastive_accuracy.update_state(contrastive_labels, tf.transpose(similarities))# The temperature-scaled similarities are used as logits for cross-entropy# a symmetrized version of the loss is used hereloss_1_2 = keras.losses.sparse_categorical_crossentropy(contrastive_labels, similarities, from_logits=True)loss_2_1 = keras.losses.sparse_categorical_crossentropy(contrastive_labels, tf.transpose(similarities), from_logits=True)return (loss_1_2 + loss_2_1) / 2def train_step(self, data):(unlabeled_images, _), (labeled_images, labels) = data# Both labeled and unlabeled images are used, without labelsimages = tf.concat((unlabeled_images, labeled_images), axis=0)# Each image is augmented twice, differentlyaugmented_images_1 = self.contrastive_augmenter(images)augmented_images_2 = self.contrastive_augmenter(images)with tf.GradientTape() as tape:features_1 = self.encoder(augmented_images_1)features_2 = self.encoder(augmented_images_2)# The representations are passed through a projection mlpprojections_1 = self.projection_head(features_1)projections_2 = self.projection_head(features_2)contrastive_loss = self.contrastive_loss(projections_1, projections_2)gradients = tape.gradient(contrastive_loss,self.encoder.trainable_weights + self.projection_head.trainable_weights,)self.contrastive_optimizer.apply_gradients(zip(gradients,self.encoder.trainable_weights + self.projection_head.trainable_weights,))self.contrastive_loss_tracker.update_state(contrastive_loss)# Labels are only used in evalutation for an on-the-fly logistic regressionpreprocessed_images = self.classification_augmenter(labeled_images)with tf.GradientTape() as tape:features = self.encoder(preprocessed_images)class_logits = self.linear_probe(features)probe_loss = self.probe_loss(labels, class_logits)gradients = tape.gradient(probe_loss, self.linear_probe.trainable_weights)self.probe_optimizer.apply_gradients(zip(gradients, self.linear_probe.trainable_weights))self.probe_loss_tracker.update_state(probe_loss)self.probe_accuracy.update_state(labels, class_logits)return {m.name: m.result() for m in self.metrics}def test_step(self, data):labeled_images, labels = data# For testing the components are used with a training=False flagpreprocessed_images = self.classification_augmenter(labeled_images, training=False)features = self.encoder(preprocessed_images, training=False)class_logits = self.linear_probe(features, training=False)probe_loss = self.probe_loss(labels, class_logits)self.probe_loss_tracker.update_state(probe_loss)self.probe_accuracy.update_state(labels, class_logits)# Only the probe metrics are logged at test timereturn {m.name: m.result() for m in self.metrics[2:]}# Contrastive pretraining
pretraining_model = ContrastiveModel()
pretraining_model.compile(contrastive_optimizer=keras.optimizers.Adam(),probe_optimizer=keras.optimizers.Adam(),
)pretraining_history = pretraining_model.fit(train_dataset, epochs=num_epochs, validation_data=test_dataset
)
print("Maximal validation accuracy: {:.2f}%".format(max(pretraining_history.history["val_p_acc"]) * 100)
)
Model: "encoder"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_4 (Conv2D) (None, 47, 47, 128) 3584
_________________________________________________________________
conv2d_5 (Conv2D) (None, 23, 23, 128) 147584
_________________________________________________________________
conv2d_6 (Conv2D) (None, 11, 11, 128) 147584
_________________________________________________________________
conv2d_7 (Conv2D) (None, 5, 5, 128) 147584
_________________________________________________________________
flatten_1 (Flatten) (None, 3200) 0
_________________________________________________________________
dense_2 (Dense) (None, 128) 409728
=================================================================
Total params: 856,064
Trainable params: 856,064
Non-trainable params: 0
_________________________________________________________________
Model: "projection_head"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_3 (Dense) (None, 128) 16512
_________________________________________________________________
dense_4 (Dense) (None, 128) 16512
=================================================================
Total params: 33,024
Trainable params: 33,024
Non-trainable params: 0
_________________________________________________________________
Model: "linear_probe"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_5 (Dense) (None, 10) 1290
=================================================================
Total params: 1,290
Trainable params: 1,290
Non-trainable params: 0
_________________________________________________________________
Epoch 1/20
200/200 [==============================] - 70s 325ms/step - c_loss: 4.7788 - c_acc: 0.1340 - p_loss: 2.2030 - p_acc: 0.1922 - val_p_loss: 2.1043 - val_p_acc: 0.2540
Epoch 2/20
200/200 [==============================] - 67s 323ms/step - c_loss: 3.4836 - c_acc: 0.3047 - p_loss: 2.0159 - p_acc: 0.3030 - val_p_loss: 1.9833 - val_p_acc: 0.3120
Epoch 3/20
200/200 [==============================] - 65s 322ms/step - c_loss: 2.9157 - c_acc: 0.4187 - p_loss: 1.8896 - p_acc: 0.3598 - val_p_loss: 1.8621 - val_p_acc: 0.3556
Epoch 4/20
200/200 [==============================] - 67s 322ms/step - c_loss: 2.5837 - c_acc: 0.4867 - p_loss: 1.7965 - p_acc: 0.3912 - val_p_loss: 1.7400 - val_p_acc: 0.4006
Epoch 5/20
200/200 [==============================] - 67s 322ms/step - c_loss: 2.3462 - c_acc: 0.5403 - p_loss: 1.6961 - p_acc: 0.4138 - val_p_loss: 1.6655 - val_p_acc: 0.4190
Epoch 6/20
200/200 [==============================] - 65s 321ms/step - c_loss: 2.2214 - c_acc: 0.5714 - p_loss: 1.6325 - p_acc: 0.4322 - val_p_loss: 1.6242 - val_p_acc: 0.4366
Epoch 7/20
200/200 [==============================] - 67s 322ms/step - c_loss: 2.0618 - c_acc: 0.6098 - p_loss: 1.5793 - p_acc: 0.4470 - val_p_loss: 1.5348 - val_p_acc: 0.4663
Epoch 8/20
200/200 [==============================] - 65s 322ms/step - c_loss: 1.9532 - c_acc: 0.6360 - p_loss: 1.5173 - p_acc: 0.4652 - val_p_loss: 1.5248 - val_p_acc: 0.4700
Epoch 9/20
200/200 [==============================] - 65s 322ms/step - c_loss: 1.8487 - c_acc: 0.6602 - p_loss: 1.4631 - p_acc: 0.4798 - val_p_loss: 1.4587 - val_p_acc: 0.4905
Epoch 10/20
200/200 [==============================] - 65s 322ms/step - c_loss: 1.7837 - c_acc: 0.6767 - p_loss: 1.4310 - p_acc: 0.4992 - val_p_loss: 1.4265 - val_p_acc: 0.4924
Epoch 11/20
200/200 [==============================] - 65s 321ms/step - c_loss: 1.7133 - c_acc: 0.6955 - p_loss: 1.3764 - p_acc: 0.5090 - val_p_loss: 1.3663 - val_p_acc: 0.5169
Epoch 12/20
200/200 [==============================] - 66s 322ms/step - c_loss: 1.6655 - c_acc: 0.7064 - p_loss: 1.3511 - p_acc: 0.5140 - val_p_loss: 1.3779 - val_p_acc: 0.5071
Epoch 13/20
200/200 [==============================] - 67s 322ms/step - c_loss: 1.6110 - c_acc: 0.7198 - p_loss: 1.3182 - p_acc: 0.5282 - val_p_loss: 1.3259 - val_p_acc: 0.5303
Epoch 14/20
200/200 [==============================] - 66s 321ms/step - c_loss: 1.5727 - c_acc: 0.7312 - p_loss: 1.2965 - p_acc: 0.5308 - val_p_loss: 1.2858 - val_p_acc: 0.5422
Epoch 15/20
200/200 [==============================] - 67s 322ms/step - c_loss: 1.5477 - c_acc: 0.7361 - p_loss: 1.2751 - p_acc: 0.5432 - val_p_loss: 1.2795 - val_p_acc: 0.5472
Epoch 16/20
200/200 [==============================] - 65s 321ms/step - c_loss: 1.5127 - c_acc: 0.7448 - p_loss: 1.2562 - p_acc: 0.5498 - val_p_loss: 1.2731 - val_p_acc: 0.5461
Epoch 17/20
200/200 [==============================] - 67s 321ms/step - c_loss: 1.4811 - c_acc: 0.7517 - p_loss: 1.2306 - p_acc: 0.5574 - val_p_loss: 1.2439 - val_p_acc: 0.5630
Epoch 18/20
200/200 [==============================] - 67s 321ms/step - c_loss: 1.4598 - c_acc: 0.7576 - p_loss: 1.2215 - p_acc: 0.5544 - val_p_loss: 1.2352 - val_p_acc: 0.5623
Epoch 19/20
200/200 [==============================] - 65s 321ms/step - c_loss: 1.4349 - c_acc: 0.7631 - p_loss: 1.2161 - p_acc: 0.5662 - val_p_loss: 1.2670 - val_p_acc: 0.5479
Epoch 20/20
200/200 [==============================] - 66s 321ms/step - c_loss: 1.4159 - c_acc: 0.7691 - p_loss: 1.2044 - p_acc: 0.5656 - val_p_loss: 1.2204 - val_p_acc: 0.5624
Maximal validation accuracy: 56.30%
对预训练编码器进行有监督的微调
然后,通过在有标记的样本上附加一个随机初始化的完全连接的分类层,对编码器进行微调。
# Supervised finetuning of the pretrained encoder
finetuning_model = keras.Sequential([layers.Input(shape=(image_size, image_size, image_channels)),get_augmenter(**classification_augmentation),pretraining_model.encoder,layers.Dense(10),],name="finetuning_model",
)
finetuning_model.compile(optimizer=keras.optimizers.Adam(),loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),metrics=[keras.metrics.SparseCategoricalAccuracy(name="acc")],
)finetuning_history = finetuning_model.fit(labeled_train_dataset, epochs=num_epochs, validation_data=test_dataset
)
print("Maximal validation accuracy: {:.2f}%".format(max(finetuning_history.history["val_acc"]) * 100)
)
Epoch 1/20
200/200 [==============================] - 4s 17ms/step - loss: 1.9942 - acc: 0.2554 - val_loss: 1.4278 - val_acc: 0.4647
Epoch 2/20
200/200 [==============================] - 3s 16ms/step - loss: 1.5209 - acc: 0.4373 - val_loss: 1.3119 - val_acc: 0.5170
Epoch 3/20
200/200 [==============================] - 3s 17ms/step - loss: 1.3210 - acc: 0.5132 - val_loss: 1.2328 - val_acc: 0.5529
Epoch 4/20
200/200 [==============================] - 3s 17ms/step - loss: 1.1932 - acc: 0.5603 - val_loss: 1.1328 - val_acc: 0.5872
Epoch 5/20
200/200 [==============================] - 3s 17ms/step - loss: 1.1217 - acc: 0.5984 - val_loss: 1.1508 - val_acc: 0.5906
Epoch 6/20
200/200 [==============================] - 3s 16ms/step - loss: 1.0665 - acc: 0.6176 - val_loss: 1.2544 - val_acc: 0.5753
Epoch 7/20
200/200 [==============================] - 3s 16ms/step - loss: 0.9890 - acc: 0.6510 - val_loss: 1.0107 - val_acc: 0.6409
Epoch 8/20
200/200 [==============================] - 3s 16ms/step - loss: 0.9775 - acc: 0.6468 - val_loss: 1.0907 - val_acc: 0.6150
Epoch 9/20
200/200 [==============================] - 3s 17ms/step - loss: 0.9105 - acc: 0.6736 - val_loss: 1.1057 - val_acc: 0.6183
Epoch 10/20
200/200 [==============================] - 3s 17ms/step - loss: 0.8658 - acc: 0.6895 - val_loss: 1.1794 - val_acc: 0.5938
Epoch 11/20
200/200 [==============================] - 3s 17ms/step - loss: 0.8503 - acc: 0.6946 - val_loss: 1.0764 - val_acc: 0.6325
Epoch 12/20
200/200 [==============================] - 3s 17ms/step - loss: 0.7973 - acc: 0.7193 - val_loss: 1.0065 - val_acc: 0.6561
Epoch 13/20
200/200 [==============================] - 3s 16ms/step - loss: 0.7516 - acc: 0.7319 - val_loss: 1.0955 - val_acc: 0.6345
Epoch 14/20
200/200 [==============================] - 3s 16ms/step - loss: 0.7504 - acc: 0.7406 - val_loss: 1.1041 - val_acc: 0.6386
Epoch 15/20
200/200 [==============================] - 3s 16ms/step - loss: 0.7419 - acc: 0.7324 - val_loss: 1.0680 - val_acc: 0.6492
Epoch 16/20
200/200 [==============================] - 3s 17ms/step - loss: 0.7318 - acc: 0.7265 - val_loss: 1.1635 - val_acc: 0.6313
Epoch 17/20
200/200 [==============================] - 3s 17ms/step - loss: 0.6904 - acc: 0.7505 - val_loss: 1.0826 - val_acc: 0.6503
Epoch 18/20
200/200 [==============================] - 3s 17ms/step - loss: 0.6389 - acc: 0.7714 - val_loss: 1.1260 - val_acc: 0.6364
Epoch 19/20
200/200 [==============================] - 3s 16ms/step - loss: 0.6355 - acc: 0.7829 - val_loss: 1.0750 - val_acc: 0.6554
Epoch 20/20
200/200 [==============================] - 3s 17ms/step - loss: 0.6279 - acc: 0.7758 - val_loss: 1.0465 - val_acc: 0.6604
Maximal validation accuracy: 66.04%
和基线进行对比
# The classification accuracies of the baseline and the pretraining + finetuning process:
def plot_training_curves(pretraining_history, finetuning_history, baseline_history):for metric_key, metric_name in zip(["acc", "loss"], ["accuracy", "loss"]):plt.figure(figsize=(8, 5), dpi=100)plt.plot(baseline_history.history[f"val_{metric_key}"], label="supervised baseline")plt.plot(pretraining_history.history[f"val_p_{metric_key}"],label="self-supervised pretraining",)plt.plot(finetuning_history.history[f"val_{metric_key}"],label="supervised finetuning",)plt.legend()plt.title(f"Classification {metric_name} during training")plt.xlabel("epochs")plt.ylabel(f"validation {metric_name}")plot_training_curves(pretraining_history, finetuning_history, baseline_history)
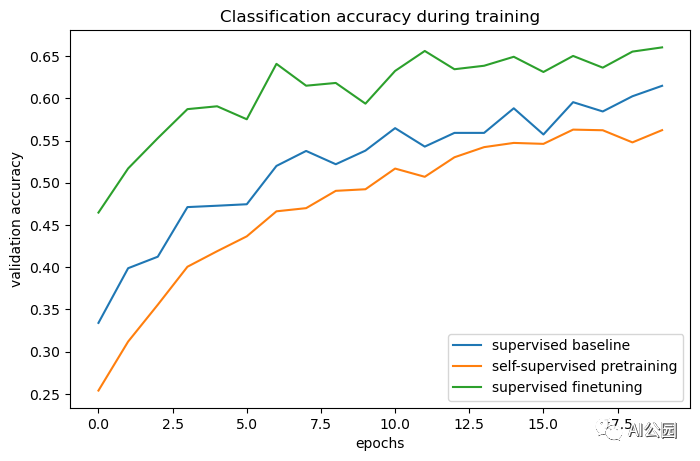
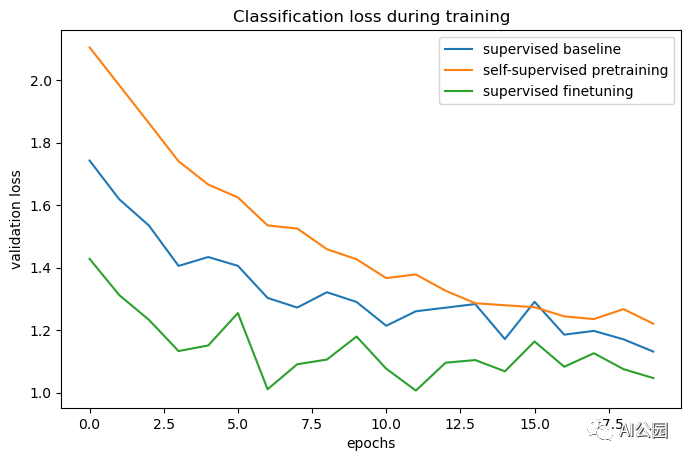
通过对比训练曲线,我们可以看到,使用对比预训练模型时,可以达到更高的验证精度,同时验证损失更低,这意味着预训练后的网络在看到少量标记样本时能够更好地泛化。
进一步的提升
结构
原论文中的实验表明,增加模型的宽度和深度可以比监督学习提高更高的性能。此外,使用ResNet-50编码器在文献中是相当标准的。但是请记住,更强大的模型不仅会增加训练时间,还会需要更多的内存,并限制你可以使用的最大批处理大小。
已经被报道使用BatchNorm层有时会降低性能,因为它引入了样本之间的批内依赖性,这就是为什么我在本例中没有使用它们的原因。然而,在我的实验中,使用BatchNorm,特别是在投影头中,可以提高性能。
超参数
本例中使用的超参数已为此任务和体系结构进行了手动调优。因此,在不改变它们的情况下,只能从进一步的超参数调优中获得边际增益。
然而,对于不同的任务或模型体系结构,这些都需要调优,所以下面是我对其中最重要的部分的注释:
批大小:由于目标可以解释为对一批图像的分类(松散地说),批大小实际上是一个比通常更重要的超参数。越高越好。
温度:温度定义了交叉熵损失中使用的softmax分布的“柔软度”,是一个重要的超参数。数值越低,对比精度越高。最近的一个技巧是了解温度的值,这可以通过将其定义为tf.Variable并应用梯度来实现。尽管这提供了一个很好的基线值,但在我的实验中,学习到的温度略低于最优值,因为它是相对于对比损失进行优化的,而对比损失并不是表征质量的完美代理。
图像增强强度:在预训练期间,较强的增强会增加任务的难度,但在一个点后,过于强的增强会降低性能。在微调过程中,较强的增强会减少过拟合,而根据我的经验,过强的增强会降低预训练的性能增益。整个数据增强管道可以看作是算法的一个重要超参数,Keras中其他自定义图像增强层的实现可以在:https://github.com/beresandras/contrastive-classification-keras中找到。
学习率策略:这里使用常数策略上,但在文献中使用余弦衰减策略比较常见,可以进一步提高性能。
优化器:在这个例子中使用Adam,因为它提供了良好的性能与默认参数。使用动量的SGD需要更多的调优,但是它可以略微提高性能。

—END—
英文原文:https://keras.io/examples/vision/semisupervised_simclr/

请长按或扫描二维码关注本公众号
喜欢的话,请给我个在看吧!
这篇关于使用SimCLR用对比预训练模型实现半监督图像分类的代码实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



