simclr专题
![[SimCLR v2] Big Self-Supervised Models are Strong Semi-Supervised Learners](https://i-blog.csdnimg.cn/direct/4cc9701420354cecb5eba7197a705453.png)
[SimCLR v2] Big Self-Supervised Models are Strong Semi-Supervised Learners
1、目的 借助无监督预训练来提升半监督学习的效果 2、方法 1)unsupervised/self-supervised pretrain -> task-agnostic -> big (deep and wide) neural network可以有效提升准确性

使用SimCLR用对比预训练模型实现半监督图像分类的代码实现
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 因公众号更改了推送规则,记得读完点“在看”~下次AI公园的新文章就能及时出现在您的订阅列表中 作者:András Béres 编译:ronghuaiyang 导读 在STL-10数据集上用SimCLR先做对比训练,再进行少量标注数据的监督训练微调。 半监督学习 半监督学习是一种处理部分标记数据集的机器学习范式。当在现实世界中应用深
SimCLR 论文阅读
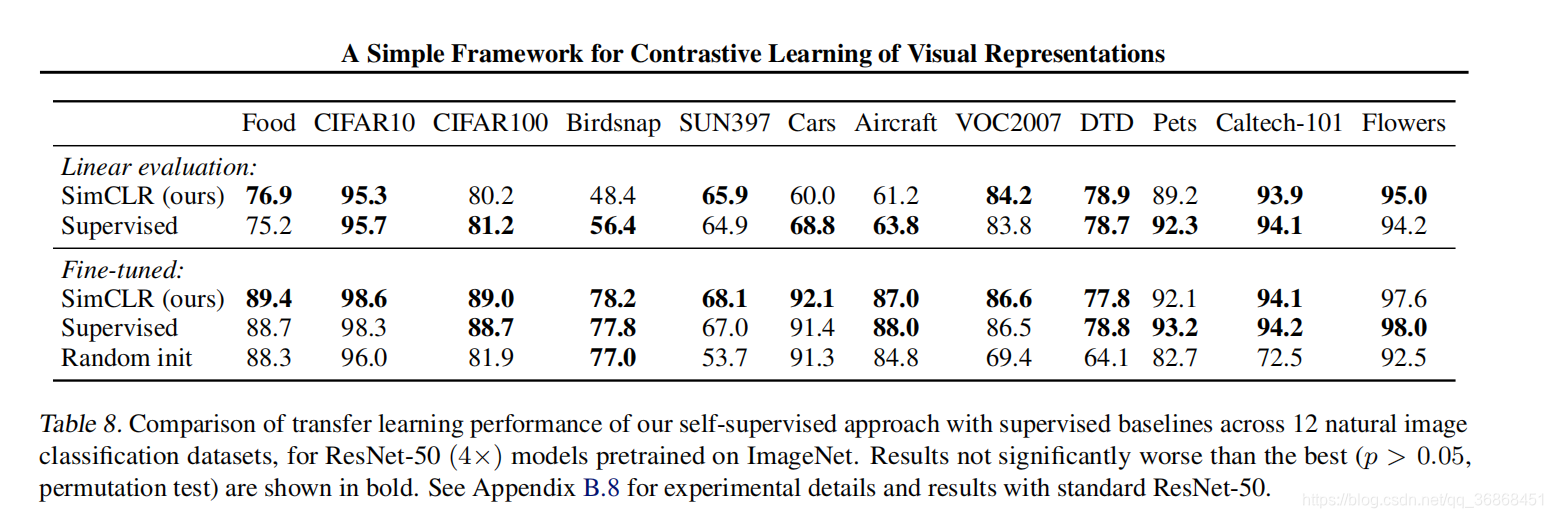
SimCLR原文链接 1. 导读 :这篇文章通过严密的实验设计,系统的探究出了学习出一个好的对比学习的网络的一些必要因素。在本篇文章中,有以下三点: Data argumentation 数据增强起到了至关重要的作用对比学习的损失函数和非线性映射也有很重要的影响更大的batch size和更多的迭代步骤能让对比学习的模型效果更好。(换句话说是不是说明收敛较慢呢?) 通过利用本文中实验验证的一些
SimCLR损失函数详解
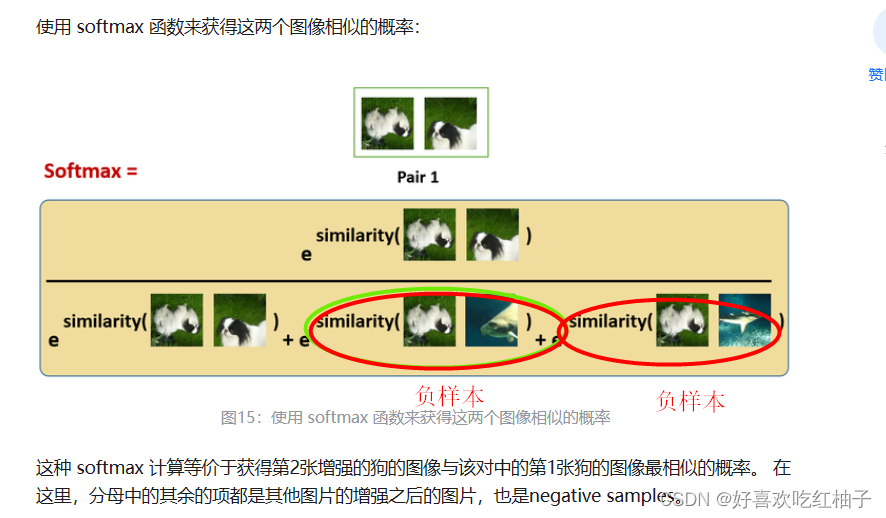
图片来源:Self-Supervised Learning 超详细解读 (二):SimCLR系列 文章目录 1. 数据增强2. 获得图片表征3. 正样本和负样本构建4. 计算相似度5. 计算图片之间相似的概率6. 损失函数为什么需要大规模的batchsize? 1. 数据增强 有一批batchsize为N的样本,论文中N=8192,下图以N=2为例; 对一个batch中的每个
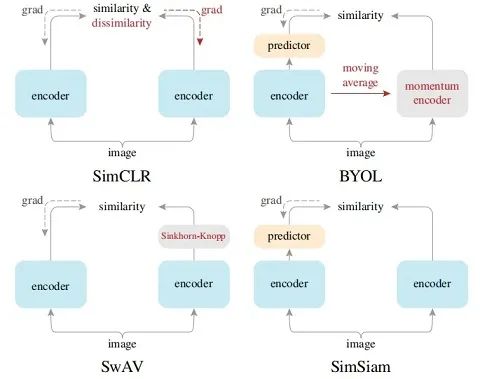
CV-对比学习-模型:MoCo/SimCLR/BYOL/SimSiam
很多大佬认为,深度学习的本质就是做两件事情:Representation Learning(表示学习)和 Inductive Bias Learning(归纳偏好学习)。在表示学习方面,如果直接对语义进行监督学习,虽然表现很好,但是它需要很多的样本并且往往是需要对特定的任务进行设计,很难具有迁移性。所以难怪各位大佬们都纷纷为自监督学习站台,自监督是未来! 自监督学习有大类方法,一
2020年度arXiv十大热门论文来了!YOLOv4、SimCLR和GPT-3均上榜
点击上方“3D视觉工坊”,选择“星标” 干货第一时间送达 作者| 陈大鑫 本文转载自:AI科技评论 近日,有位外国网友在Reddit上发帖称利用metacurate.io持续读取了2020年度arxiv上有关AI、机器学习、NLP和数据科学的大量论文资源。到2020年末,metacurate.io总共检索了94,000多个论文链接。 然后,汇总到一起,并根据7天的社交媒体热度对所有论文进行热度
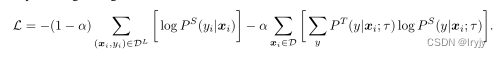
自监督入门(对比学习:INS+Disc,InvaSpread,SimCLR,MoCo系列)
自监督入门 本人从图像分割入门自监督过程记录 文章目录 自监督入门前言一、自监督学习背景及应用二、对比学习1.Contrastive Learning Framework初阶一. Ins+Disc二.InvaSpreadMotivation and Contribution:Method: 中阶一.MoCov1二.SimCLRv11.Abstract2.Introduction
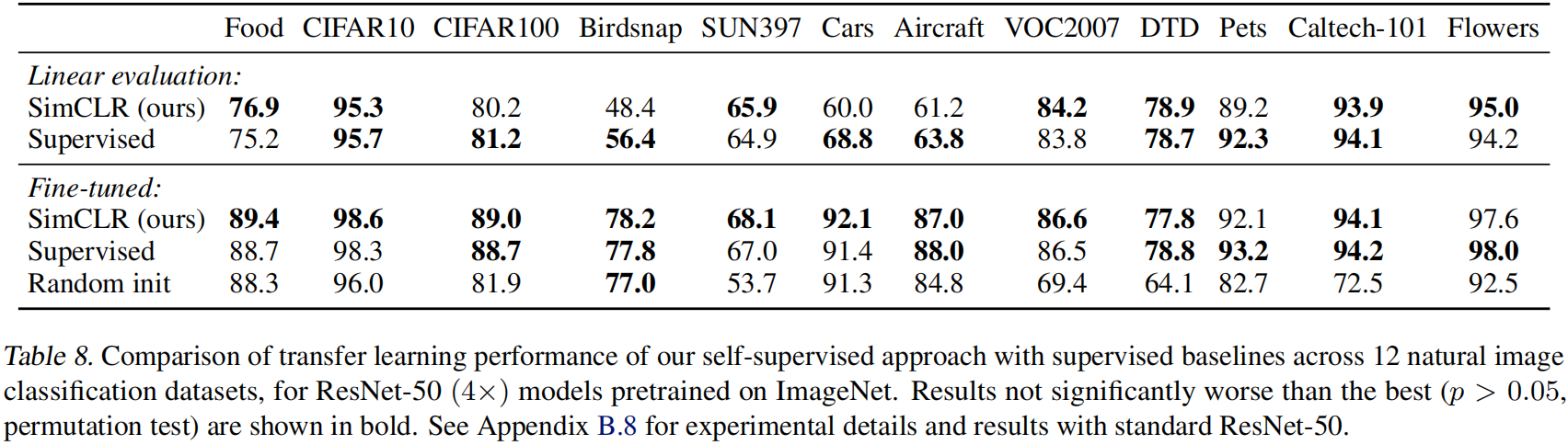
【深度学习】详解 SimCLR
目录 摘要 一、引言 二、方法 2.1 The Contrastive Learning Framework 2.2. Training with Large Batch Size 2.3. Evaluation Protocol 三、用于对比表示学习的数据增广 3.1 Composition of data augmentation operations is c