本文主要是介绍SimCLR 论文阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SimCLR原文链接
1. 导读 :这篇文章通过严密的实验设计,系统的探究出了学习出一个好的对比学习的网络的一些必要因素。在本篇文章中,有以下三点:
- Data argumentation 数据增强起到了至关重要的作用
- 对比学习的损失函数和非线性映射也有很重要的影响
- 更大的batch size和更多的迭代步骤能让对比学习的模型效果更好。(换句话说是不是说明收敛较慢呢?)
通过利用本文中实验验证的一些因素,作者设计出了一个新的对比学习的模型,称为SimCLR。通过在ImageNet上使用SimCLR进行自监督学习,作者达到了新的SOTA水平,最终达到了 76.5%/85.8%的Top1/Top5 Acc。

2. Method
受到最近的一些对比学习的启发,作者通过计算一个图片在不同的数据增强下的特征一致性的损失值来评估模型所学到的特征表示的性能。
2.1 基本的对比学习框架如下图所示:

x \bold x x 代表的是任意一张图片, x i ~ \tilde{ \bold x_i} xi~和 x j ~ \tilde{ \bold x_j} xj~ 就代表这个图片的不同的数据增强得到的结果。
在这个框架中,共有四个重要的组成部分:
- 随机数据增强(包括随机裁剪,随机颜色失真,随机高斯模糊)
- 神经网络的特征架构
- 一个比较小的MLP的projection head
- 一个对比损失函数
作者定义的损失函数如下:

在这里,作者随机采样 N \bold N N个图片作为一次训练的batch,通过数据增强后,会得到 2 N 2\bold N 2N个增强后的样本,在一个batch内,对某一个图片(固定作为参考),通过两两之间进行配对计算损失,那么共有 2 ( N − 1 ) 2(\bold N-1) 2(N−1)个负样本。
2.2 更大的batch会有更好的效果
通过上面设计的损失函数,更大的batch会有更明显的对比空间,通过把除了自身之外的样本都视为负样本,作者通过验证batch从256增大到8192,发现越大的batch size 会有更好的效果。
2.3 实验的一些基本参数
Most of our study for unsupervised pretraining (learning encoder network f without labels) is done using the ImageNet ILSVRC-2012 dataset (Russakovsky et al., 2015).
We use ResNet-50 as the base encoder network, and a 2-layer MLP projection head to project the representation to a 128-dimensional latent space. As the loss, we use NT-Xent, optimized using LARS with learning rate of 4.8 (= 0.3 × BatchSize/256) and weight decay of 1006. We train at batch size 4096 for 100 epochs. Furthermore, we use linear warmup for the first 10 epochs, and decay the learning rate with the cosine decay schedule without restarts (Loshchilov & Hutter, 2016).
3. 数据增强可以提升对比学习的效果
首先,作者说明了SimCLR相比于之前方法的改进之处在于:SimCLR通过对同一张样本的不同表示来处理对比学习,而之前的方法在使用不同的网络架构处理同一个样本,通过不同的网络来学习物体的特征表示。
下面是一些数据增强的例子:

3.1 数据增强在对比学习中不可或缺
因为ImageNet中的图片大小不一,为了尽量排除其余因素的影响,作者首先对所有的数据做相同的随机裁剪的操作,通过随机裁剪来避免大小的干扰。
此外,由于某些类别的图片只通过颜色分布直方图就能够进行分类(见下图),仅仅通过随即裁剪并不能说明效果,因此作者又对所有的数据做了随机的色彩破坏(color distort)。通过这样的操作,排除了实验中的大量干扰。
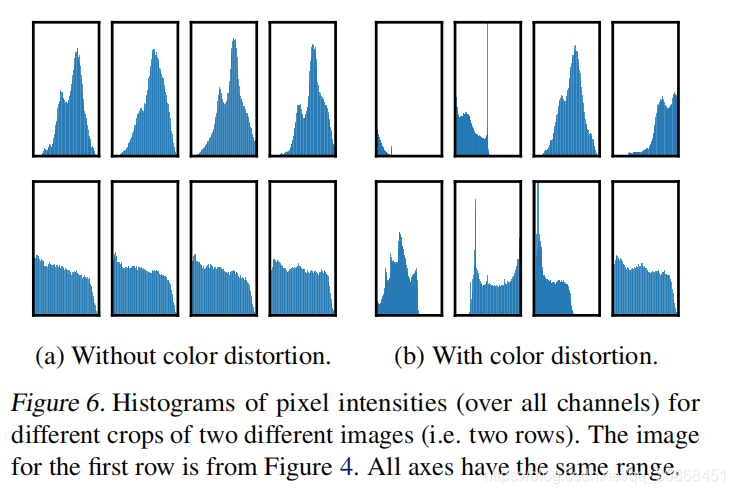
然后,作者在上面的初始数据增强后,在2.1节的架构的分支部分,做分别处理,对一张图片做单一的某种数据增强,对另一个副本不做任何额外增强,以此来计算最终的损失函数,然后作者发现,仅仅通过单一的数据增强不足以学习到一个比较好的网络。
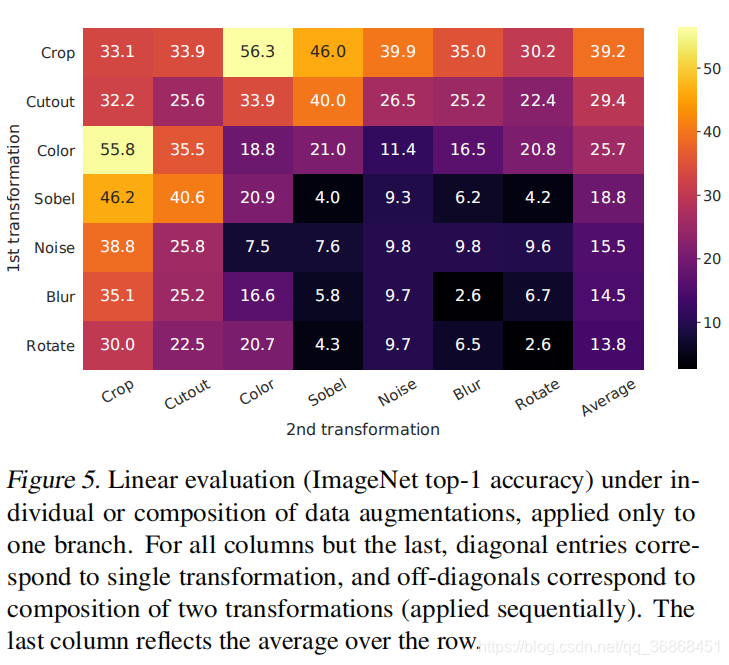
3.2 对比学习需要更强的数据增强
作者在这一节用试验说明需要进行组合的更强的数据增强才能使模型的效果更好。
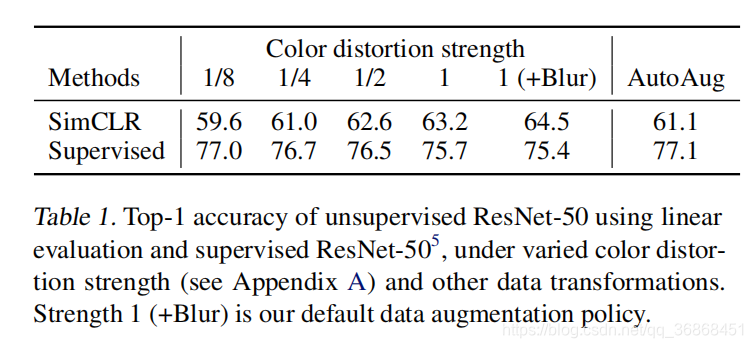
作者通过调整color distort的强度,验证了在SimCLR中,数据增强的强度越高,效果越好,而在监督学习中,数据越完整,效果越好。因此相比于普通的神经网络,对比学习需要更强的数据增强。(也就是说,去迫使神经网络去学习更深层的特征,而不是仅仅停留在表面)
4. 特征提取Head设计
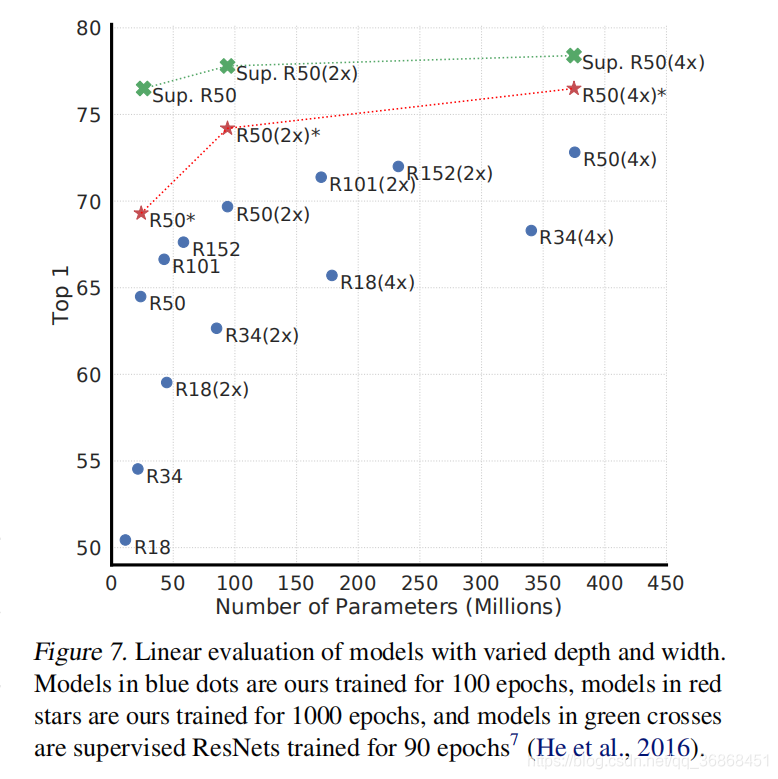
4.1 无监督学习需要深层网络
作者通过简单的实验发现,相比于监督学习,无监督学习的网络越大越深,特征提取的效果越好。
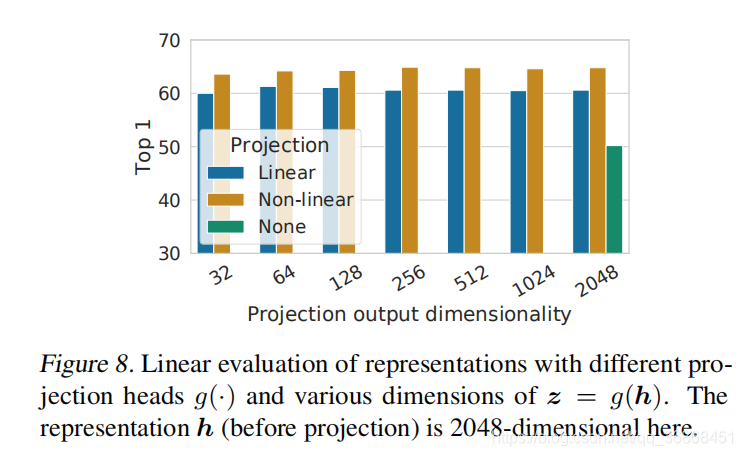
4.2 作者还发现非线性的projection head对网络性能也有影响
作者通过实验不同网络下,三种projection head 的效果,发现非线性的projection对性能的提升比较大。
5. Loss Functions and Batch Size
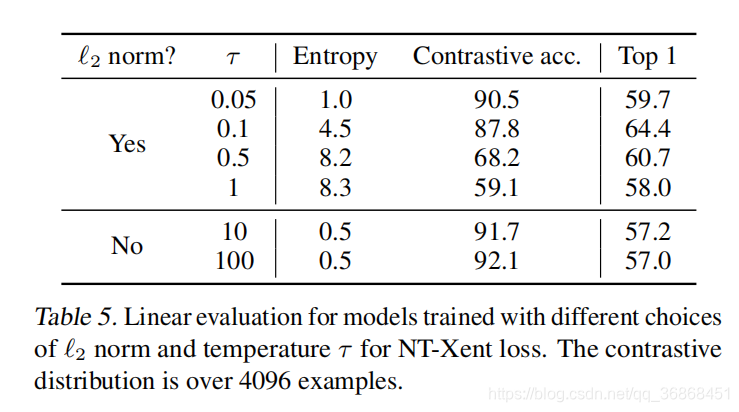
5.1. 作者发现Cross entropy的效果比较好
通过对不同的损失函数求导计算梯度,作者发现:与交叉熵不同,其他目标函数不会通过负数的相对硬度来权衡负数。 (unlike cross-entropy, other objective functions do not weigh the negatives by their relative hardness.)

此外,作者还说明了温度参数的重要性:without normalization and proper temperature scaling, performance is significantly worse.
5.2 更久的训练和更大的batch会使得网络性能更好
&emsp在不同epoch下,当epoch处于一个比较小的值时,batch的大小很重要,但是当epoch比较大的时候,batch的重要性就降低了。(这里可以理解为数据的信息有限,需要一定的能力才能学习完这些信息,在epoch比较小的时候,需要更大的batch(悟性)让网络学习特征,而epoch比较大的时候,就已经熟能生巧,通过时间弥补了网络的悟性差距)
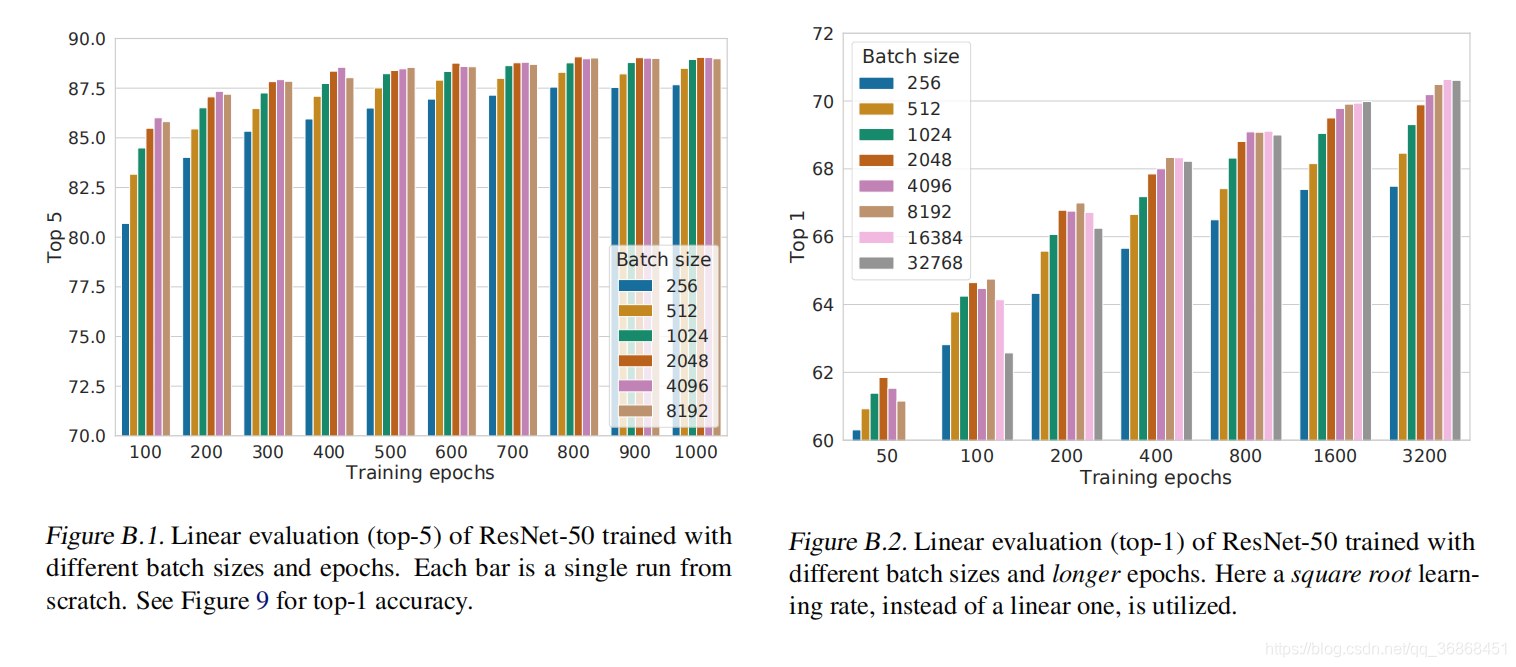
此外,作者还研究了epoch本身的影响:
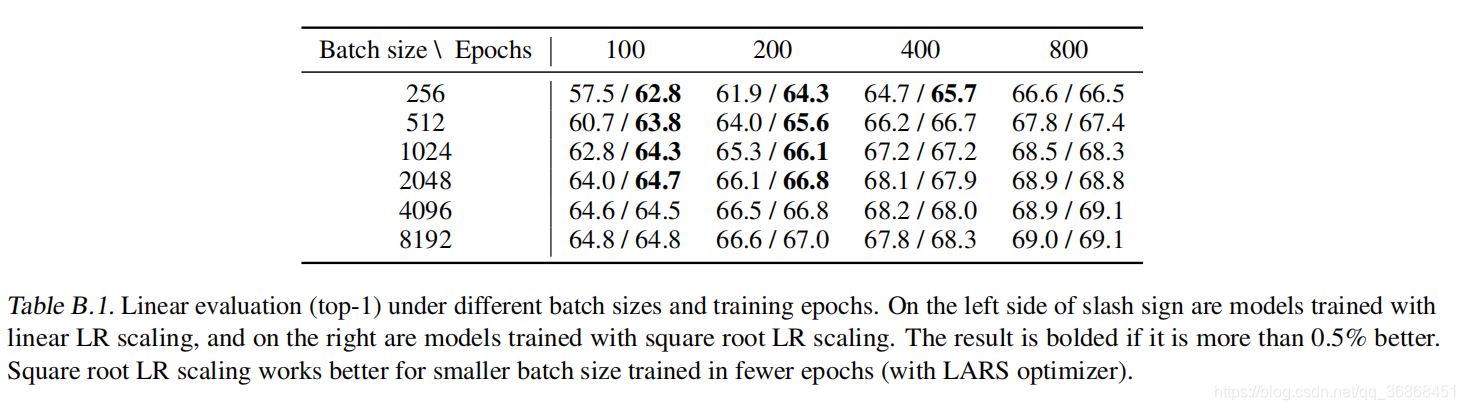
随着epoch的增加,Acc会逐渐增加。
6.其他
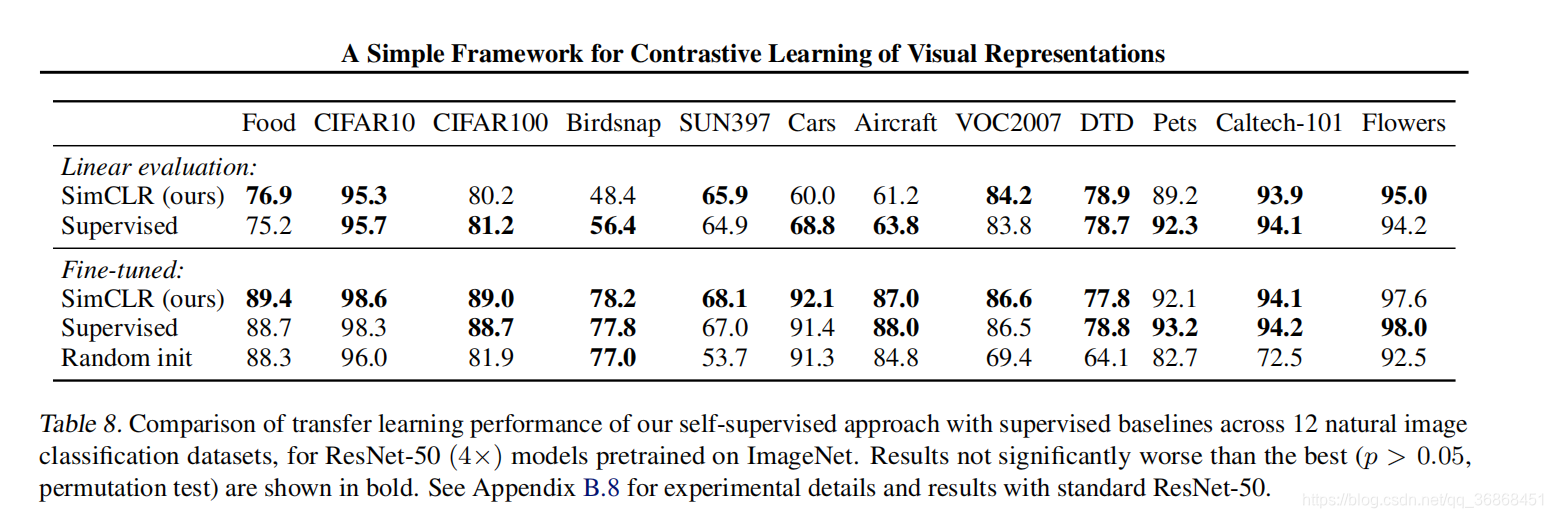
最后作者秀了一波结果。
7. 总结
相比于其他方法,作者在这篇文章提出了一种新的对待对比学习的思路,但是也带来了更多的计算资源的要求。
这篇关于SimCLR 论文阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
