本文主要是介绍动手学深度学习51 序列模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第八章 循环神经网络 8.1 序列模型
- 1. 序列模型
- 2. 代码
- 3. QA
1. 序列模型


T 个时间

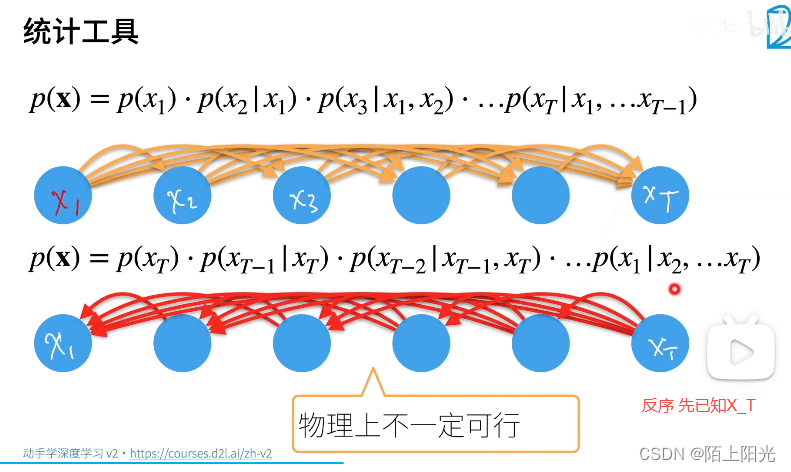
机器学习模型对 P x P_x Px建模
联合概率用条件概率展开
反过来先算-反序:已知X_T推前面发生的【RNN可以正可以反】
自回归:给一些数据,用数据前面的部分数据做预测,对见过的数据建模
核心:1. 怎么算前面数据的f 2. 怎么算P

固定 τ τ τ, 不设置很大。对 τ τ τ个数据训练做建模 f f f会比较容易,一个MLP就行。
假设X是一个标量,对f每次给 τ τ τ个特征,预测一个标量。线性回归orMLP都可以建模。

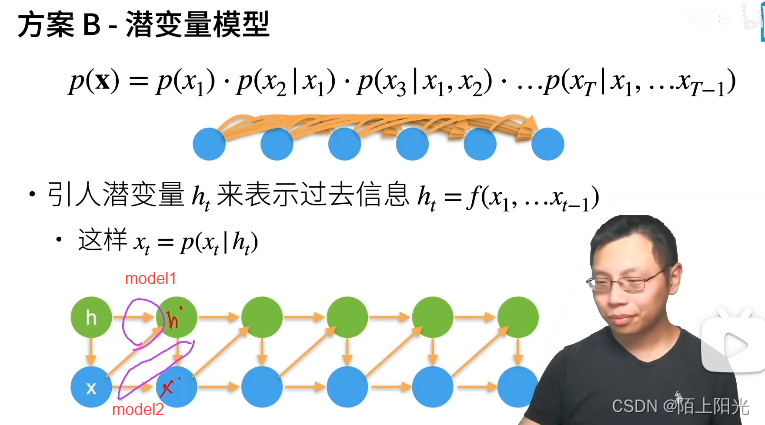
潜变量: 可以认为是隐变量的一个稍微推广类型,统计上稍有区别。
不写成函数的形式,写成变量的形式。
两个模型:
- 给定前一个潜变量+x,怎么更新新的潜变量
- 给定潜变量+x, 怎么更新新的x
核心:选择什么样的模型建模 模型至于一两个变量相关,计算简单。

2. 代码
%matplotlib inline
import torch
from torch import nn
from d2l import torch as d2lT = 1000 # 总共产生1000个点
time = torch.arange(1, T + 1, dtype=torch.float32)
x = torch.sin(0.01 * time) + torch.normal(0, 0.2, (T,))
d2l.plot(time, [x], 'time', 'x', xlim=[1, 1000], figsize=(6, 3))tau = 4
features = torch.zeros((T - tau, tau))
for i in range(tau):features[:, i] = x[i: T - tau + i]
labels = x[tau:].reshape((-1, 1))batch_size, n_train = 16, 600
# 只有前n_train个样本用于训练
# load_array 把张量设置成数据集的模式
train_iter = d2l.load_array((features[:n_train], labels[:n_train]),batch_size, is_train=True)# 初始化网络权重的函数
def init_weights(m):if type(m) == nn.Linear:nn.init.xavier_uniform_(m.weight)# 一个简单的多层感知机
def get_net():net = nn.Sequential(nn.Linear(4, 10),nn.ReLU(),nn.Linear(10, 1))net.apply(init_weights)return net# 平方损失。注意:MSELoss计算平方误差时不带系数1/2
loss = nn.MSELoss(reduction='none')def train(net, train_iter, loss, epochs, lr):trainer = torch.optim.Adam(net.parameters(), lr)for epoch in range(epochs):for X, y in train_iter:trainer.zero_grad()l = loss(net(X), y)l.sum().backward()trainer.step()print(f'epoch {epoch + 1}, 'f'loss: {d2l.evaluate_loss(net, train_iter, loss):f}')net = get_net()
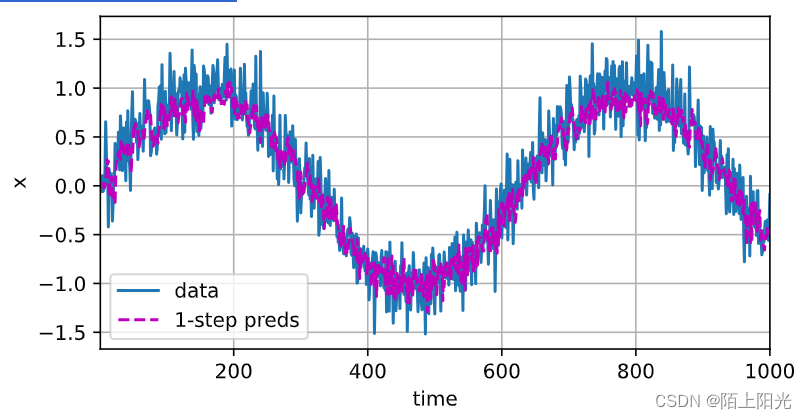
train(net, train_iter, loss, 5, 0.01)onestep_preds = net(features)
d2l.plot([time, time[tau:]],[x.detach().numpy(), onestep_preds.detach().numpy()], 'time','x', legend=['data', '1-step preds'], xlim=[1, 1000],figsize=(6, 3))# T=1000
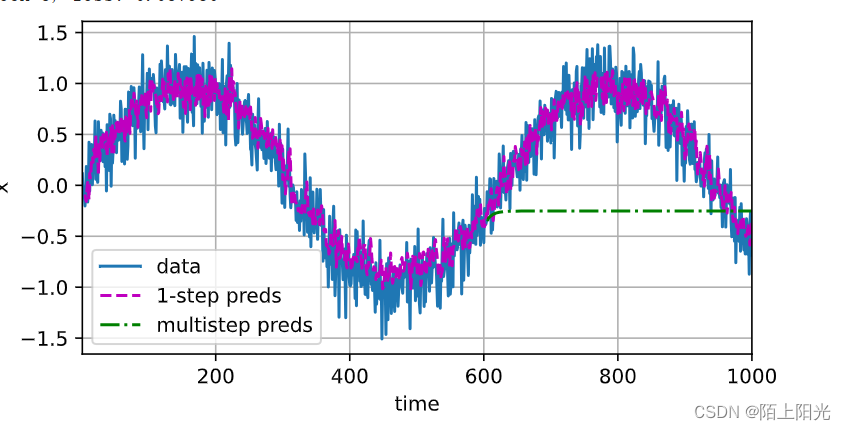
multistep_preds = torch.zeros(T)
multistep_preds[: n_train + tau] = x[: n_train + tau]
for i in range(n_train + tau, T):multistep_preds[i] = net(multistep_preds[i - tau:i].reshape((1, -1)))d2l.plot([time, time[tau:], time[n_train + tau:]],[x.detach().numpy(), onestep_preds.detach().numpy(),multistep_preds[n_train + tau:].detach().numpy()], 'time','x', legend=['data', '1-step preds', 'multistep preds'],xlim=[1, 1000], figsize=(6, 3))max_steps = 64features = torch.zeros((T - tau - max_steps + 1, tau + max_steps))
# 列i(i<tau)是来自x的观测,其时间步从(i)到(i+T-tau-max_steps+1)
for i in range(tau):features[:, i] = x[i: i + T - tau - max_steps + 1]# 列i(i>=tau)是来自(i-tau+1)步的预测,其时间步从(i)到(i+T-tau-max_steps+1)
for i in range(tau, tau + max_steps):features[:, i] = net(features[:, i - tau:i]).reshape(-1)steps = (1, 4, 16, 64)
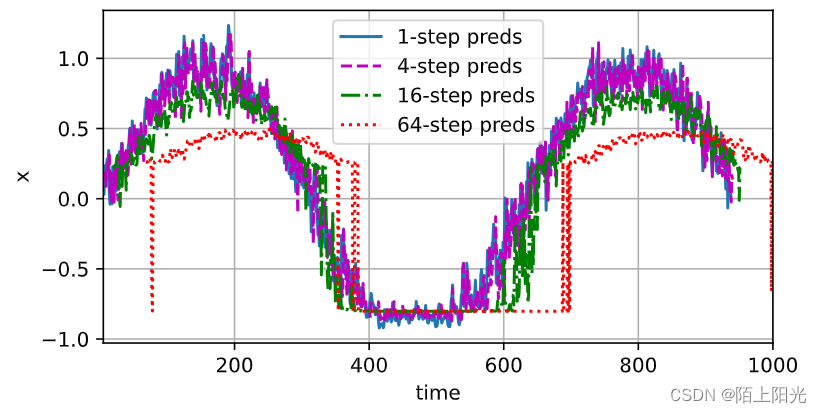
d2l.plot([time[tau + i - 1: T - max_steps + i] for i in steps],[features[:, (tau + i - 1)].detach().numpy() for i in steps], 'time', 'x',legend=[f'{i}-step preds' for i in steps], xlim=[5, 1000],figsize=(6, 3))
给定过去的数据,预测未来。
给定马尔科夫假设,怎么用MLP预测序列模型。
回归:MSE损失函数
关键: 数据是怎么构造来的
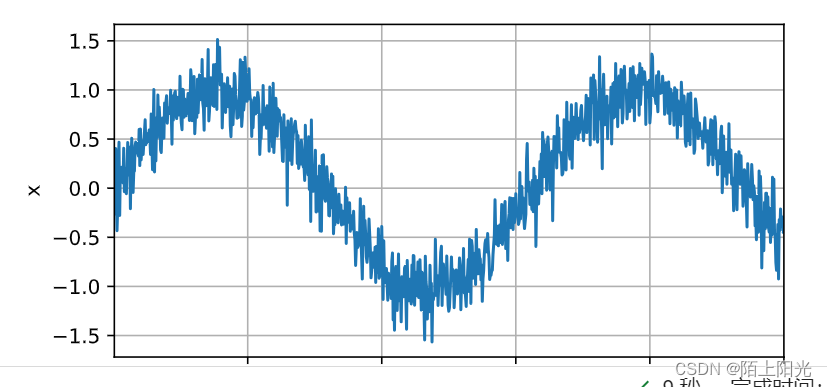
蓝色:训练数据
桃红色:每次给4个真实数据点预测数据
epoch 1, loss: 0.106651
epoch 2, loss: 0.061725
epoch 3, loss: 0.061892
epoch 4, loss: 0.059226
epoch 5, loss: 0.058244
难点:从 600开始,只给前4个真实数据点预测接下来四个数据,后续数据不再给真实数据,用预测的数据继续预测。
核心思想:绿色曲线 600后开始数据做预测 绿色是预测值
预测有误差,不断累积。短期预测还可以。
蓝色:每次给4个真实数据点预测下一个数据
桃红色:只给4个真实数据点预测接下来的数据,后续数据不再给真实数据
绿色: 给4个点,预测未来16个数据点
红色:给4个点,预测未来64个数据点
难点:预测较远未来的事情
3. QA
潜变量:关心建模的时候怎么建模。
这篇关于动手学深度学习51 序列模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!
![[word] word设置上标快捷键 #学习方法#其他#媒体](https://img-blog.csdnimg.cn/img_convert/7a1ef11f92414f74d152e768c38640bf.gif)