本文主要是介绍AI与业务的结合 | 使用机器学习预测客户反应,轻松实现市场营销策略优化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
01、案例说明
在实际的工作中,除了数据本身需要处理之外,同时也需要对所建立模型进行检验与了解。所以在这个过程之中我们学习2个比较进阶的功能:一个是关于决定属性和结果之间的关系从而判断哪些是更重要的属性;另外一部分则是在使用模型的时候如何做更细致的控制。
案例使用的模型是一个典型的直接邮件模型,在市场营销中,通常通过邮件和客户之间互动或是推销,虽然现在可能邮件的功能不如社群网路,但是其中的道理是可以相同的。只要能掌握相关的客户资料,就可以预测客户的反应,从而制定和评估市场营销的策略。但是不见得所有的属性都很重要,我们希望知道在这么多的属性之中,哪一个是最为重要和关键的属性,可以作为KPI 来做设定。整体的流程如下图所示:

同时在使用模型的过程之中,我们也希望了解如何使用模型的参数来符合实际的需求,而不是只是依靠系统的缺省值而做设定,这样系统的预测才能和实际的结果更为的吻合。
02、数据资料
第一步基本仍然是读入和理解数据,来检查数据的本身的质量,种类和相关信息。除了基本的数据观察,比如有无缺失,或者数据的种类之外,我们也可以将鼠标点击每一个属性,来得到其基本资料和数据的分布(如果有需要,也可以使用 图形下方的可视化连接,直接打开图表页面)
而这边比较有意思的是可以看到在数据的种类列表中,有2个三角形的警示标志如下图所示。这个警示标志只是作为一个建议,代表说模型如果使用“年纪”或者“性别”方式,可能会产生出在使用上面造成歧视的可能,并不是对于结果有质量的影响。这个只是作为一个参考,是否使用仍然是由用户自己决定。

而对于数据本身的相关性,似乎并没有特别的主要关联。通常我们可以通过对于使用分散式矩阵(Scatter Matrix) 和分散式3D图 (Scatter 3D) 来检视数据和目标值的关系,这个是一个很好的开始点。
03、操作流程
Step1读入数据
这个步骤是一个很标准的操作流程,基本上面将数据读入之后,对于数据进行初步的了解。然后将不需要属性(如Name)可以直接去除掉,然后使用一个复制(Multiple)的算子,将数据分为二组,一组是计算数据权重,另外一组则是建立模型。
Step2 分析权重
这个部分,基本上也是将属性和目标之间的关系做一个判断,将对目标更有影响力的数据属性用数值标示出来。这个部分可以使用多种方式来作一个基本判断,如属性和目标值的关联系数计算,或是信息增益量(Information Gain)。这个计算的方式类似,可以把它想象成做一个简单的决策树,而对于结果影响较重的属性,给予一个更高的权重值。在参数的设定中,如果将所有的权重值做一个常态化,所有的数值将会介于(0,1)之间。通过这个方法就可以更清楚地知道对于结果来言,哪一个属性更为的重要。
我们可以直接的先看结果,如下图所示:
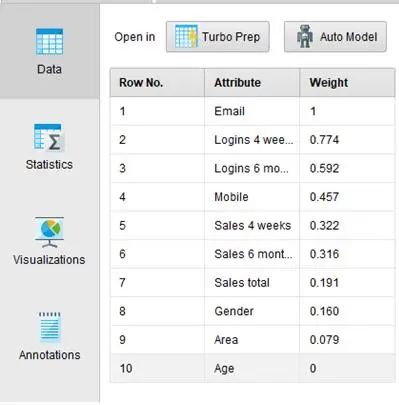
图中清楚地看出,对于结果而言邮件是第一个最重要的属性,而在4周之内是否有回应这是第2重要,反而年纪和性别在里面是属于最低。但是这个结果也是可以理解,如果邮件的种类是属于高级账号(Premium),自然和公司的互动更好,所以更容易回复,而另外一类属于免费邮件账号(Free),互动本来就比较低,所以自然回复的可能性就较低。同时在4周之内回复的,通常都比较活跃,所以也更容易回复。
Step3: 模型建立/检验
这个步骤相对就比较标准化,通过交叉检验的方式,我们使用朴素贝叶斯的模型,然后再检验这个模型的准确度。虽然系统没有输出,但是如果有兴趣,可以直接将其检验的结果,另外再连接到输出端口,就可以看到模型的准确度。
Step4: 使用模型
这个步骤基本上就是将外部的未知数据直接带入,然后再用一个模型使用(Apply Model)的算子,将模型的结果直接输出。
但是如果各位在这边设立一个停止点,然后看其预测的结果。就可以观察到结果,包括预测值和预测的信心度(Confidence)。系统内置的信心指数是以0.5作为标准阈值,超过就是Yes, 而低于0.5 就是No。但是未必这个是一个最好的阈值,因为有些时候模型使用0.5的信心度并没有办法将系统中的数据准确的分类。这个时候就需要使用阈值调整的方式,来将模型的使用度提高。
Step5: 阈值优化
阈值优化的方式是将原来交叉检验的算子对于训练数据结果而进行判断优化。在原来系统的缺省阈值是以0.5作为分类。如果通过在这里设立一个停止点,我们可以观察其以0.5为阈值的表现并不理想,可以在数据的列表中观察到,在0.5 附近的预测结果和实际结果,并不是很准确。如果以图形表示,则在下图里面可以看到,有很多应该是预测的结果与实际并不相同(也就是蓝色点和绿色点的分布并不是很清楚的分开)如下图所示:
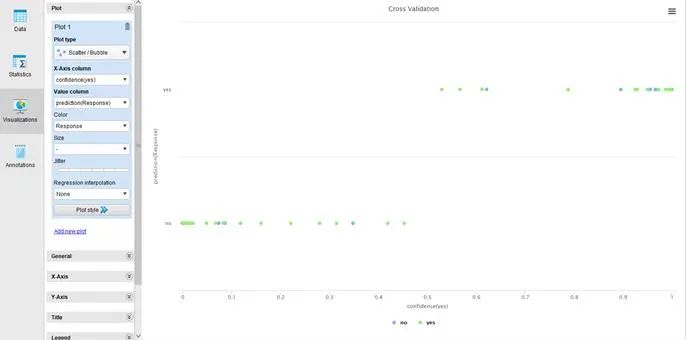
在这里使用了一个复合算子(Process),但是通过确定阈值(Find Threshold)的算子,其使用ROC的计算来做判断。注意这边有参数的设定,就是如果分类错误的“成本”,也就是如果某个数据的分类分错了,对于结果会造成多大的影响。通常两边可以都做相同的数值,但是对于这个案例,我们设定是如果第一类的成本是“1.0”,也就是如果不会回应的人系统判断会回应,发邮件给这个人,所造成的损失不会太大。但是如果反过来,对于可能会回应的人但是我们判断不会而没有发邮件,这样可能就会损失很大,所以对第二类的错误我们设定“3.0”。通过这个算子,可以找到一个更好的阈值之后,并且也将对实际会造成的成本纳入计算,如下图所示:

经过这个操作之后,它的分类标准重新调整为0.000000339,换句话说,基本是将很多原来完全不可能会发送邮件的客户(阈值0.5 的结果是787个No,213个Yes),都纳入了考虑而重新调整(阈值3.39E-7的结果是522个No, 478个Yes),整体的准确度就能更有效的提升。而通过使用阀值(Apply Threshold)的算子,它将系统原来0.5的阀值重新定位新的数值,让使用也会更为有效。
04、结果说明
这个部分说明了对于系统所建议的一些数值,我们仍然要去进行了解和掌握。尤其是对于商务应用的时候,会有很多的实际考量,比如在这里对于错误分类的成本,都要纳入计算之中,而得到一个更为靠近实际需求的结果。
05、建议练习
1.明白权重与属性之间的关系,以决策树的方式表现出来?
2.调整对于阈值优化中的成本数值的差异,看看所对于的阈值和其分类Yes/No的数值如何?
3.依照原来的区分方式,则系统的错误成本会是多少?
若您对数据分析以及人工智能感兴趣,欢迎与我们一起站在全球视野关注人工智能的发展,与Forrester 、德勤、麦肯锡等全球知名企业共探AI如何加速工业变革,共享众多优秀行业案例,开启AI人工智能全球新视野!!
共同参与6月20日由Altair主办的面向工程师的全球线上人工智能会议“AI for Engineers”。
点击立即免费报名,倒计时1天!
(注:现在注册参会,即可于会后第一时间获得Altair全球100个客户案例资料)
关于 Altair RapidMiner
Altair RapidMiner 数据分析与人工智能平台,是 Altair 澳汰尔公司旗下仿真、HPC 和数据分析三块主营业务中的解决方案,它在数据分析领域最早实现将自动化数据科学、文本分析、自动特征工程和深度学习等多种功能同时集成的一站式数据分析平台,帮助用户解决从数据清洗、准备、数据科学建模到模型管理和部署,同时又支持数据和流数据的实时分析可视化的数据分析平台。
欲了解更多信息,欢迎关注公众号:Altair RapidMiner
这篇关于AI与业务的结合 | 使用机器学习预测客户反应,轻松实现市场营销策略优化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








