本文主要是介绍【Hive下篇: 一篇文章带你了解表的静态分区,动态分区! 分桶!Hive sql的内置函数!复杂数据类型!hive的简单查询语句!】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言:
💞💞大家好,我是书生♡,本篇文章主要分享的是大数据开发中hive的相关技术。连接查询!正则表达式! 虚拟列!爆炸函数!行列转换! Hive的数据压缩和数据存储!希望大家看完这篇文章会有所帮助。也希望大家能够多多关注博主。博主会持续更新更多的优质好文!!!
💥💥下一篇博客会为大家讲解hive中的优化以及原理性的知识点。
💞💞前路漫漫,希望大家坚持下去,不忘初心,成为一名优秀的程序员
个人主页⭐: 书生♡
gitee主页🙋♂:闲客
专栏主页💞:大数据开发
博客领域💥:大数据开发,java编程,前端,算法,Python
写作风格💞:超前知识点,干货,思路讲解,通俗易懂
支持博主💖:关注⭐,点赞💖、收藏⭐、留言💬
本篇文章是依赖于上一边文章的大家对于hive的定义,使用,部署安装又不懂的可以浏览我的上一篇文章。【Hive中篇: 一篇文章带你了解表的静态分区,动态分区! 分桶!Hive sql的内置函数!复杂数据类型!hive的简单查询语句!】
目录
- 1. 连接查询
- 1.1 内连接
- 1.2 左外连接
- 1.3 右外连接
- 1.4 全连接
- 1.5 左半连接
- 1.6 交叉连接
- 1. 7 union联合查询
- 2. 正则表达式
- 3. 虚拟列
- 4. 爆炸函数与合并函数
- 4.1 爆炸函数 explode方法
- 4.2 炸裂函数和侧视图
- 4.3合并函数 collect
- 5. 行列转换(重要)
- 5.1 行转列
- 5.2 列转行
- 6 随机抽样
- 7. 视图
- 8. hive的参数配置(理解)
- 9. HIve的数据压缩和HIve的存储格式
- 9.1 HIve的数据压缩
- 9.2 存储格式
- 10. Hive指令

1. 连接查询
准备数据,创建两个表,其中id数据有相同的关联部分
create table test_user
(u_id int,name string
) row format delimited fields terminated by ',';create table test_like
(u_id int,u_like string
) row format delimited fields terminated by ',';
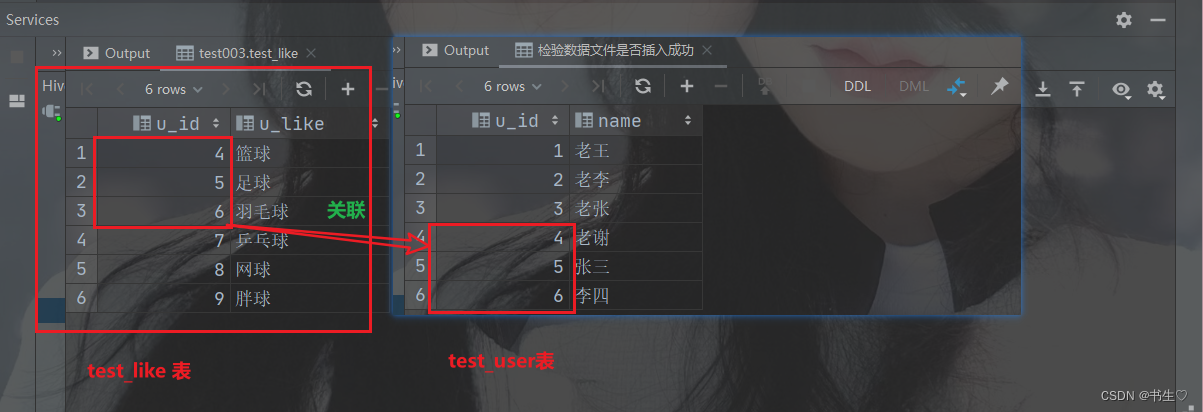
这个两个数据表中,id字段有相同的数据。
1.1 内连接
- 定义:
内连接是最早的连接方式之一,也被称为普通连接或自然连接。它从两个或多个表中返回符合连接条件和查询条件的记录。内连接只返回两个表中都存在的记录,即满足连接条件的行。 - 特点:
丢失信息:由于只返回匹配的记录,可能会丢失存在于一个表中但不存在于另一个表中的记录。
显式与隐式:内连接可以是显式的(使用INNER JOIN关键字)或隐式的(仅通过WHERE子句指定连接条件)。
语法: 表1 inner join 表2 on 连接条件 (inner可省略)
案例:
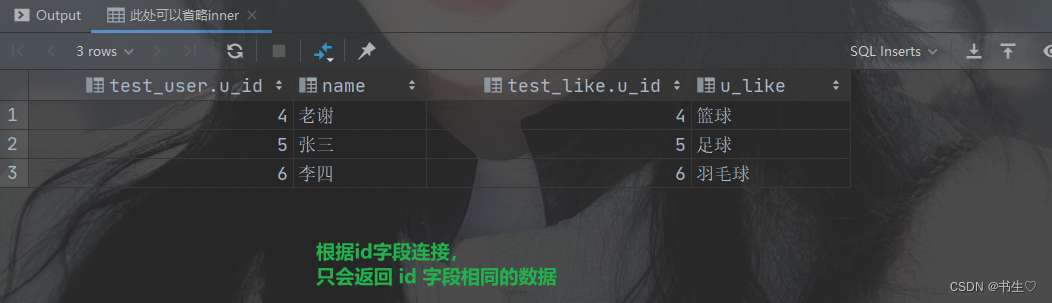
select *
from test_userinner join test_like on test_user.u_id = test_like.u_id;
-- 此处可以省略inner
select *
from test_userjoin test_like on test_user.u_id = test_like.u_id;
1.2 左外连接
- 定义:
左外连接返回左表中的所有记录,以及右表中与左表匹配的记录。如果左表中的某行在右表中没有匹配项,则结果集中对应的右表部分将包含空值(NULL)。 - 特点:
显示左表所有记录:无论右表是否有匹配项,左表的所有记录都会被返回。
右表部分可能为空:如果左表中的记录在右表中没有匹配项,则结果集中对应的右表部分将为空。
语法: 表1 left outer join 表2 on 连接条件(outer可省略)
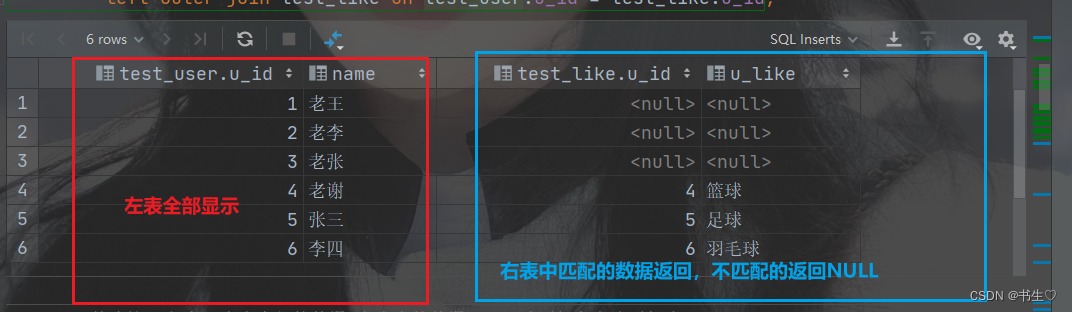
select *
from test_userleft join test_like on test_user.u_id = test_like.u_id;
-- 此处 outer可以省略
select *
from test_userleft outer join test_like on test_user.u_id = test_like.u_id;
1.3 右外连接
- 定义:
右外连接与左外连接相反,它返回右表中的所有记录,以及左表中与右表匹配的记录。如果右表中的某行在左表中没有匹配项,则结果集中对应的左表部分将包含空值(NULL)。 - 特点:
显示右表所有记录:无论左表是否有匹配项,右表的所有记录都会被返回。
左表部分可能为空:如果右表中的记录在左表中没有匹配项,则结果集中对应的左表部分将为空。
语法: 表1 right outer join 表2 on 连接条件(outer可省略)
-- 3. 右外连接 保留右表中全部的数据,左表中的数据匹配成功则保留失败则忽略
select *
from test_userright join test_like on test_user.u_id = test_like.u_id;
-- 此处 outer可以省略
select *
from test_userright outer join test_like on test_user.u_id = test_like.u_id;
1.4 全连接
- 定义:
全连接返回左表和右表中的所有记录。如果某行在另一个表中没有匹配项,则另一个表的选择列表列将包含空值(NULL)。 - 特点:
显示两个表的所有记录:无论是否有匹配项,左表和右表的所有记录都会被返回。
可能包含空值:如果某行在另一个表中没有匹配项,则结果集中对应的部分将为空。
语法: 表1 full outer join 表2 on 连接条件(outer可省略)
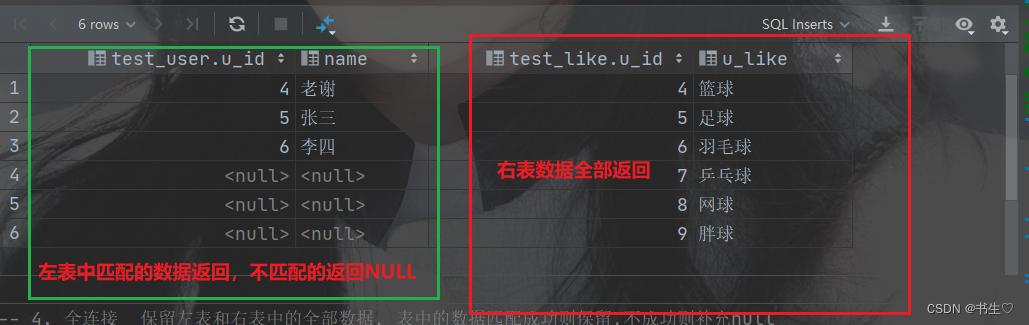
-- 4. 全连接 保留左表和右表中的全部数据, 表中的数据匹配成功则保留,不成功则补充null
select *
from test_userfull outer join test_like on test_user.u_id = test_like.u_id;
-- 此处outer可以省略
select *
from test_userfull join test_like on test_user.u_id = test_like.u_id;
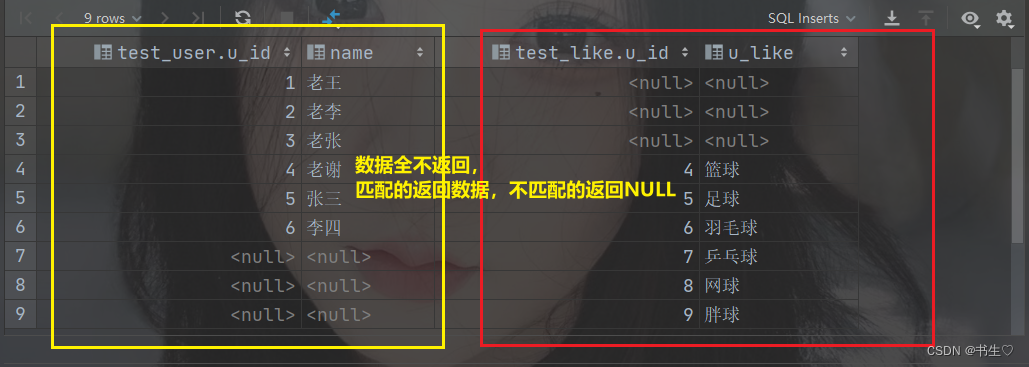
1.5 左半连接
- 定义:
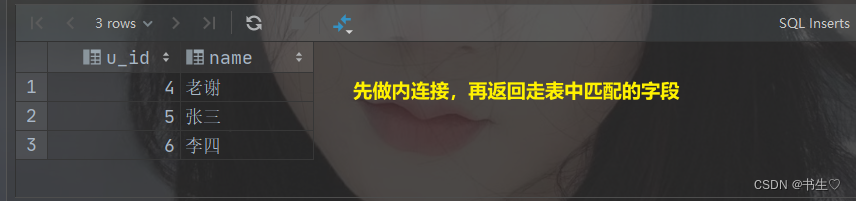
左半连接是Hive特有的连接类型,它只返回左表中满足连接条件的记录,而不返回右表中的数据。它主要用于检查左表中的记录是否在右表中存在。(先对于两张表做内连接,但是仅返回左表中全部的数据内容) - 特点:
只返回左表记录:只返回左表中满足连接条件的记录,不返回右表中的数据。
高效性:由于不返回右表中的数据,左半连接在处理大数据集时通常比左外连接更高效。
语法: 表1 left semir join 表2 on 连接条件
-- 5. 左半连接 先对于两张表做内连接,但是仅返回左表中全部的数据内容
select *
from test_userleft semijoin test_like on test_user.u_id = test_like.u_id;
1.6 交叉连接
- 定义:
交叉连接也被称为笛卡尔积,它返回左表中的每一行与右表中的每一行的组合。如果左表有m行,右表有n行,则结果集将包含m*n行。 - 特点:
生成所有可能的组合:交叉连接会生成左表和右表中所有可能的记录组合。
通常与其他条件结合使用:由于交叉连接可能会产生大量的结果,因此通常与其他条件(如WHERE子句)结合使用来限制结果集的大小。
语法: 表1 cross join 表2
select *
from test_usercross join test_like;

1. 7 union联合查询
-
定义:
UNION 操作符用于结合两个或更多 SELECT 语句的结果集,但不返回任何重复的行。它会对所有的 SELECT 语句的结果集进行自动去重,以确保合并后的结果集中不包含任何重复的记录。 -
特点:
自动去重:UNION 会自动从结果集中删除重复的记录。
列数和数据类型:所有 SELECT 语句必须拥有相同数量的列,且相应的列必须具有相似的数据类型。列的顺序也必须相同。(字段名可以不一样)
结果集顺序:UNION 不保证结果集中行的顺序。
语法:
select 字段1,字段2 from 表
union
select 字段1,字段2 from 表
数据准备:
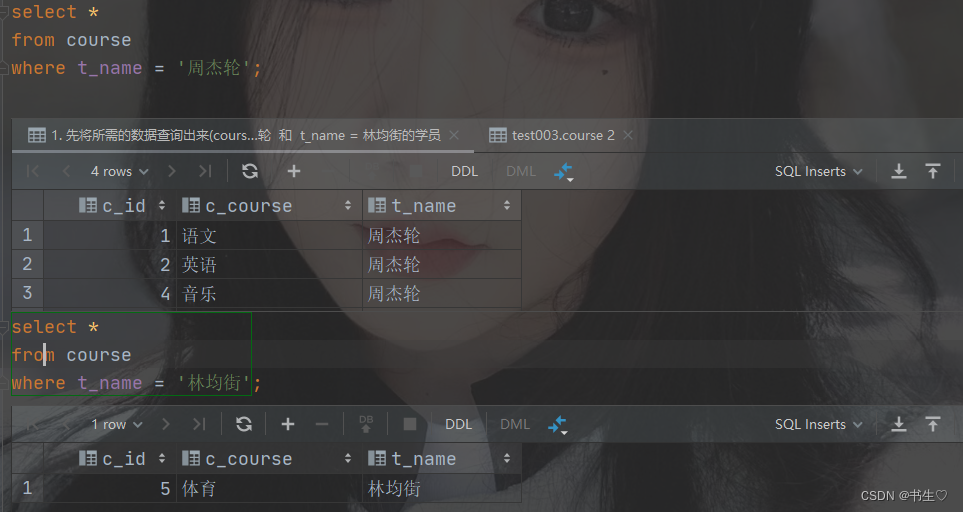
select *
from course
where t_name = '周杰轮';
select *
from course
where t_name = '林均街';
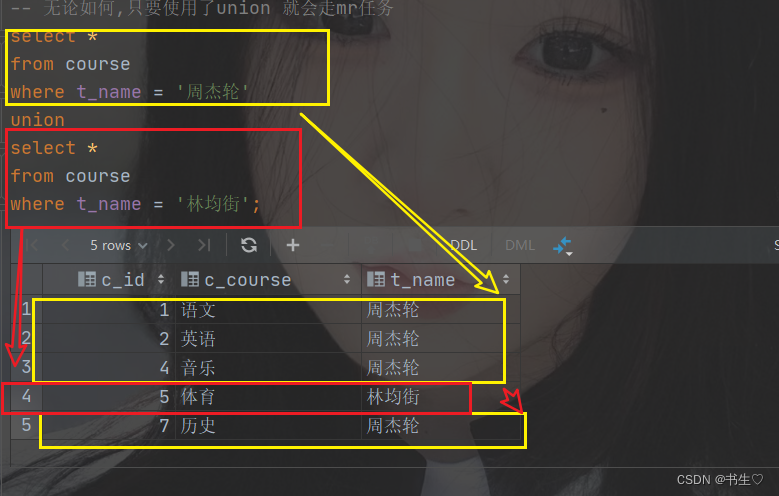
union 在使用过程中会自动进行去重操作 等价于 union distinct
如果我们想要不去重的数据,我们可以使用 union all
案例:
select *
from course
where t_name = '周杰轮'
union all
select *
from course
where t_name = '周杰轮';
union联合查询后,数据顺序不是两个表依次书写的,而是重新随机排序的.
如果要对于联合查询排序,需要联合查询结束后再排序,否则顺序依然混乱.
-- 5. union联合查询后,数据顺序不是两个表依次书写的,而是重新随机排序的.
-- 如果要对于联合查询排序,需要联合查询结束后再排序,否则顺序依然混乱.
select c_id, c_course
from course
union
select c_id, t_name
from course
order by c_id;
联合查询可以使用union连接多个表
2. 正则表达式
定义:
正则表达式是⼀组由字⺟和符号组成的特殊⽂本,它可以⽤来从⽂本中找出满⾜你想要的格式的句⼦。
⼀个正则表达式是⼀种从左到右匹配主体字符串的模式。
“Regular expression”这个词⽐较拗⼝,我们常使⽤缩写的术语“regex”或“regexp”。
正则表达式可以从⼀个基础字符串中根据⼀定的匹配模式替换⽂本中的字符串、验证表单、提取字符串等等。
正则表达式主要依赖于元字符。
元字符不代表他们本身的字⾯意思,他们都有特殊的含义。以下是⼀些元字符的介绍:
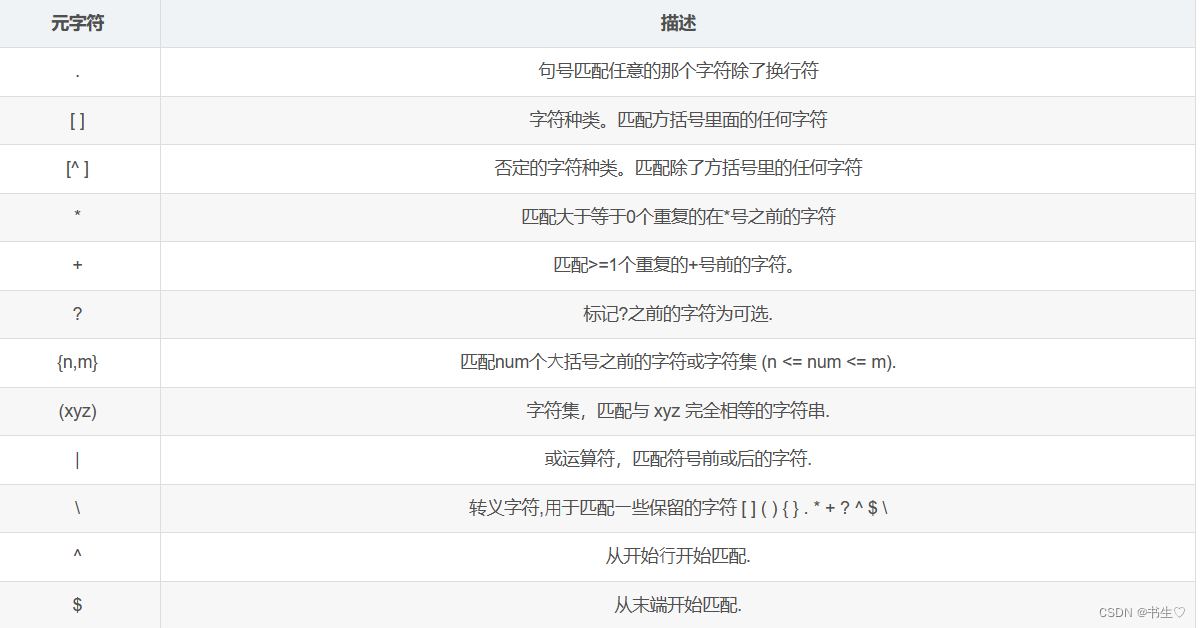
我们之前在mysql中使用模糊查询,是使用like关键字。我们在正则表达式中使用rlike 关键字进行匹配
比较常用的正则表达式字符就是 “ . ”代表任意字符 和 “ * ”代表出现任意多次 以及 “ ^ ”表示开头,“ {7} ”表示匹配次数,“ $ ” 表示以什么结尾
-- 模糊查询 like
-- 正则匹配查询 rlike
-- 需求1: 从orders表中查找 useraddress 广东省的数据
-- like _ 代表任意一个字符 % 代表任意多个字符
-- rlike .代表任意字符, * 代表出现任意多次
select *
from orders
where userAddress rlike '广东省.*';-- 需求2: 从orders表中查找 useraddress 包含惠州市的数据
-- rlike
select *
from orders
where userAddress rlike '.*惠州市.*';
-- 需求3: 查询订单中 orderno 有7位数字的数据
-- like 此处其实只判断了7位,但是没有判断是否为数字-- rlike 正则表达式的灵活性,准确性更高. ^开头 [0-9]指定数值 {7}匹配次数 $以什么结尾
select *
from orders
where orderNo rlike '^[0-9]{7}$';
-- todo 正则表达式,是一种非常晦涩的语法. 且复杂规则下,正则表达式的可读性极差
-- 但是几乎所有的编程语言都天然支持正则表达式,所以不好学,但是逃不开.
-- 正则表达式的学习目标就是可以根据网上的正则表达式进行常规修改即可.
3. 虚拟列
hive表中自带字段列,在进行select查询时没有指定,不会出现在 查询结果中
可以在select中指定这些字段显示内容
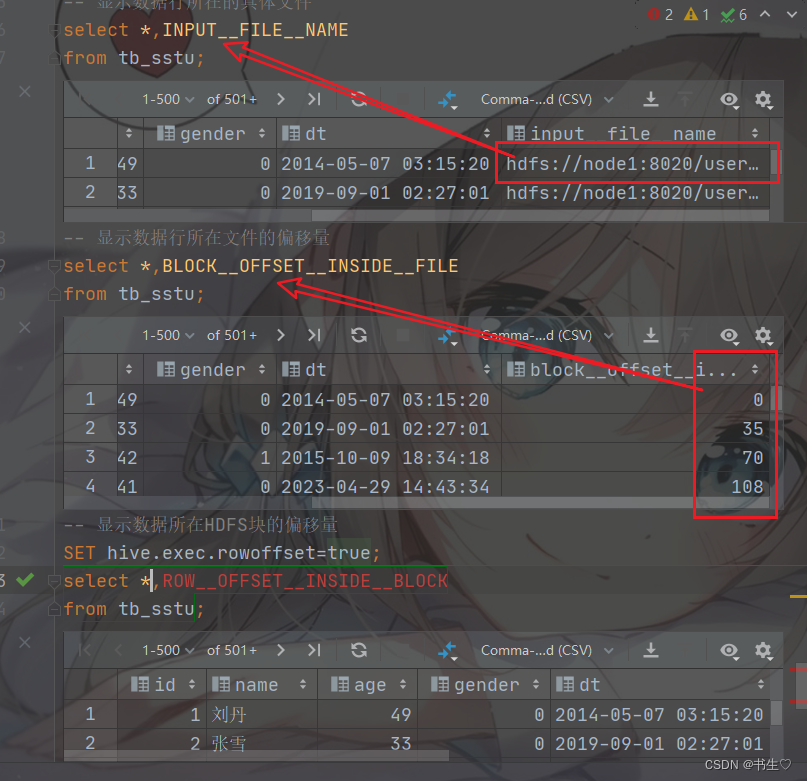
INPUT__FILE__NAME,显示数据行所在的具体文件
BLOCK__OFFSET__INSIDE__FILE,显示数据在文件中的偏移量
ROW__OFFSET__INSIDE__BLOCK,显示文件块偏移量
此(显示文件块偏移量)虚拟列需要设置:SET hive.exec.rowoffset=true 才可使用
select *,INPUT__FILE__NAME from brand;
select * from brand where INPUT__FILE__NAME='hdfs://node1:8020/user/hive/warehouse/pydata.db/brand/000001_0';select *,BLOCK__OFFSET__INSIDE__FILE from tb_stu;
SET hive.exec.rowoffset=true;
select *,ROW__OFFSET__INSIDE__BLOCK from tb_stu;
4. 爆炸函数与合并函数
函数的分类:
- UDF(user define function) 函数:数据输入多少,返回多少行数据 计算是一进一出
- UDAF (user define aggregation function)函数 : 输入多行数据返回一行结果 多进一出
如:sum,count,avg,max,min函数- UDTF函数 : 输入一行返回多行 一进多出
4.1 爆炸函数 explode方法
explode 函数是UFTF函数,将hive一列中复杂的array或者map结构拆分成多行。Explode函数是不允许在select再有其他字段,
explode(ARRAY) 列表中的每个元素生成一行
explode(MAP) map中每个key-value对,生成一行,key为一列,value为一列
-- 炸裂函数: 就是将一个数据,炸裂为多行或多列数据(表数据)的函数 该函数为explode
-- 1. 使用炸裂函数, 将array类型数据拆分为多行 explode(array('数据1','数据2','数据3'))
select explode(`array`('小明', '小芳', '小可爱'));
-- 给炸裂后的结果列起别名 explode(array('数据1','数据2','数据3')) as 别名
select explode(`array`('小明', '小芳', '小可爱')) as name;-- 2. 使用炸裂函数, 将map类型数据拆分为多行多列 explode(map('key1','value1','key2','value2'))
select explode(`map`('name', '小明', 'age', '12', 'gender', '男'));
-- 给炸裂后的结果列起别名 explode(map('key1','value1','key2','value2')) as (别名1,别名2)
select explode(`map`('name', '小明', 'age', '12', 'gender', '男')) as (co4l_title, col_info);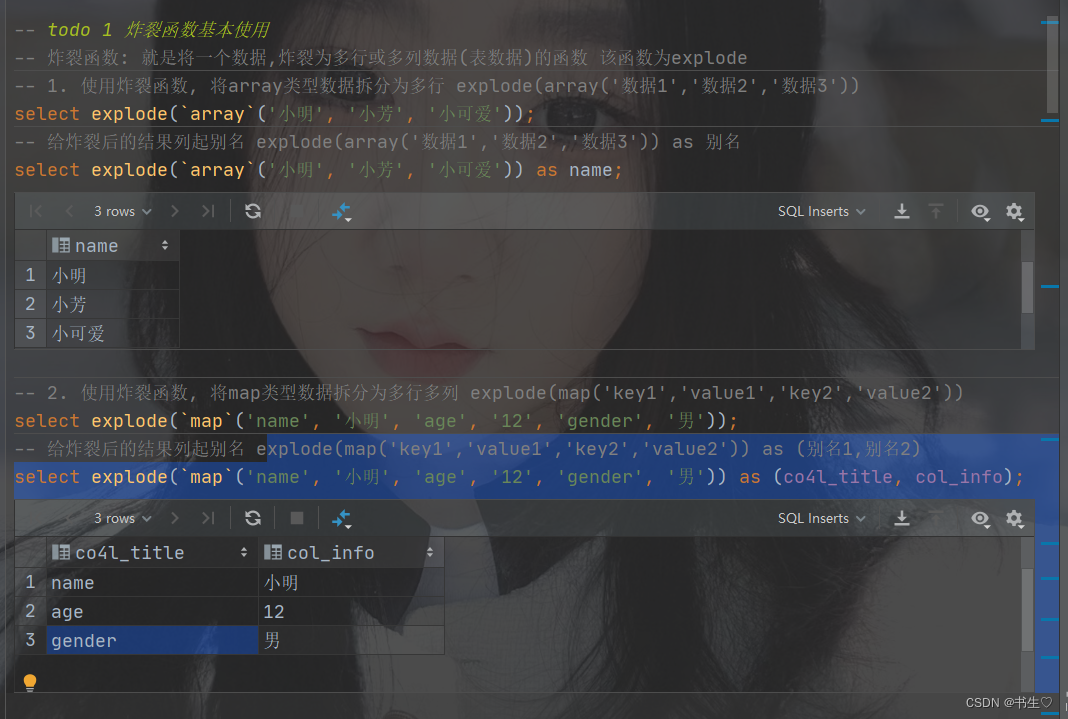
4.2 炸裂函数和侧视图
explode不能直接和其他字段出现在select中,只能单独出现
想要配合其他的字段一起使用可以搭配,lateral view侧视图的方法
语法: select 字段 from 被炸裂的表 lateral view explode(炸裂字段) 表别名 as 字段名
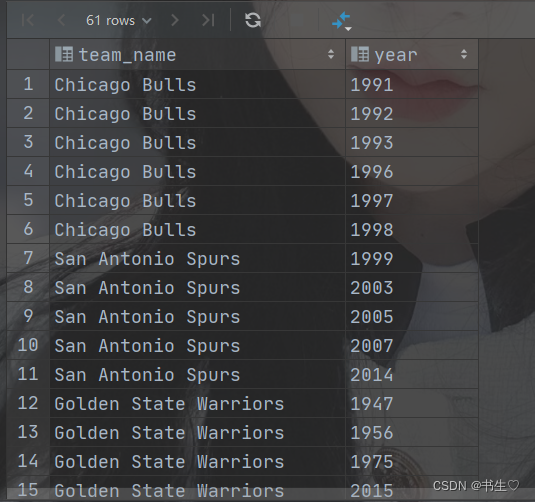
数据准备:两个字段,球队名和年份,名字是string类型的,年份是数字形式存储的是数字

-- 1. 创建一个普通表 the_nba_championship ,和 The_NBA_Championship.txt映射
create table the_nba_championship
(team_name string,cham_year array<string>
)row format delimitedfields terminated by ','collection items terminated by '|';-- 4. 将年份数据,从array类型的数组数据,炸裂为多行数据
-- explode(cham_year) as year
select explode(cham_year) as year
from the_nba_championship;-- 侧视图方式
-- 语法: select 字段 from 被炸裂的表 lateral view explode(炸裂字段) 表别名 as 字段名
select c.team_name, e1.year
from the_nba_championship c lateral view explode(cham_year) e1 as year;
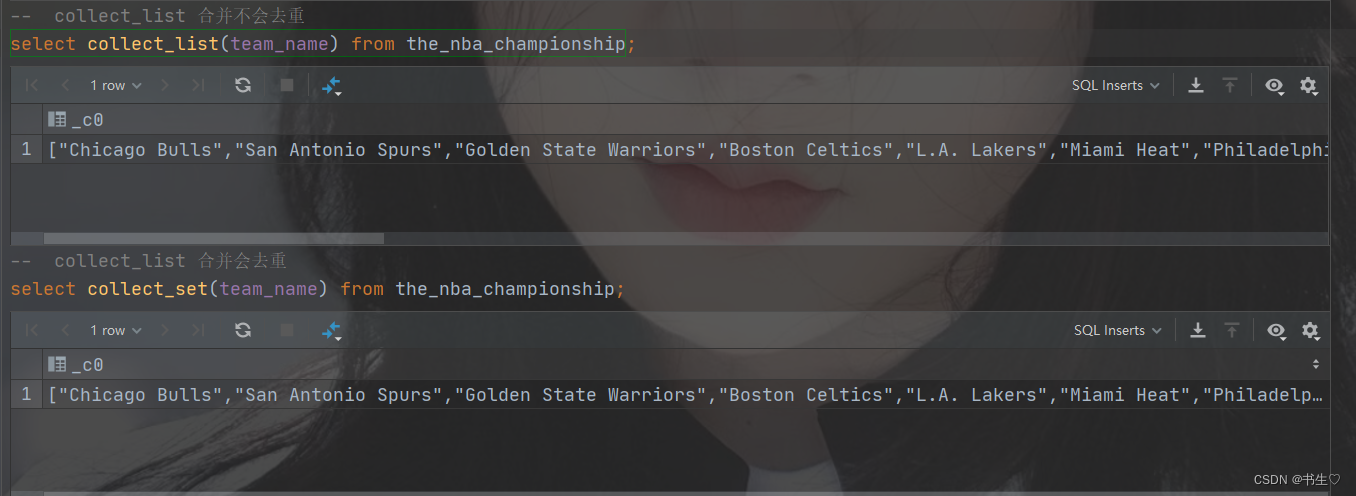
4.3合并函数 collect
合并函数是我们在行列转换中的重要方法。
将一列数据中的多行数据合并成一行
collect_list 合并后不会去重
collect_set合并会对数据进行去重
-- collect_list 合并不会去重
select collect_list(team_name) from the_nba_championship;-- collect_list 合并会去重
select collect_set(team_name) from the_nba_championship;
5. 行列转换(重要)
5.1 行转列
- 定义:
行转列:行转列是将表中的某些行转换成列,以提供更为清晰、易读的数据视图。
数据准备:
a b 1
a b 2
a b 3 转换为 a b 1-2-3
c d 4 c d 4-5-6
c d 5
c d 6
--建表 row2col2 映射上面的数据
create table row2col2
(col1 string,col2 string,col3 int
) row format delimited fields terminated by '\t';
对于行转列我们通常使用,上面提及的合并方法 collect方法。
-- select 字段1,字段2,collect_list(字段3) from 表 group by 字段1,字段2
select col1, col2, collect_list(col3)
from row2col2
group by col1, col2;-- 最后根据合适的要求进行相应的字符连接
select col1,col2,concat_ws('-', collect_list(cast(col3 as string)))
from row2col2
group by col1, col2;
5.2 列转行
- 定义 :
列转行:列转行则是将表中的某些列转换成行,每行包含一列的值。具体的操作方法包括使用聚合函数、group_concat函数或动态SQL语句块等。例如,可以使用GROUP_CONCAT函数将某一列的值拼接成一个字符串,然后用聚合函数进行分组。
数据准备:
a b 1
a b 1,2,3 a b 2 转换为 a b 3
c b 4,5,6 c d 4 c d 5c d 6
--创建表 col2row2 映射上面的数据
create table col2row2
(col1 string,col2 string,col3 string
) row format delimited fields terminated by '\t';
-- 3. 使用侧视图,将炸裂后的数据,和原数据进行连接
-- 语法: select 字段 from 被炸裂的表 lateral view explode(炸裂字段) 表别名 as 字段名
select col1, col2, t1.col_3
from col2row2 lateral view explode(split(col3, ',')) t1 as col_3;6 随机抽样
从海量数据中随机抽取部分样本数据进行计算得到的结果趋势和整体趋势一致
语法:
SELECT … FROM tbl TABLESAMPLE(BUCKET x OUT OF y ON(colname | rand()))
y表示将表数据随机划分成y份(y个桶)
x表示从y里面随机抽取x份数据作为取样
colname表示随机的依据基于某个列的值
rand()表示随机的依据基于整行
我们可以选取字段去进行抽取
select *
from tb_sstu tablesample ( bucket 2 out of 30 on name);
也可以随机抽取
select *
from tb_sstu tablesample ( bucket 2 out of 4 on rand());
随机抽样的原理,是先将数据进行分桶,在从多个分桶中抽取数据
create table tb_stu(id int,name string,age int,gender int,dt string
)row format delimited fields terminated by ',';-- 指定字段进行分桶抽样
select * from tb_stu tablesample (bucket 2 out of 30 on name);
-- 随机抽取
with tb1 as (select *from tb_stu tablesample (bucket 2 out of 20 on rand()))
select gender,count(*) from tb1 group by gender;
7. 视图
视图本质是将select查询语句进行保存,每次进行数据计算时,如果使用相同的sql语句,就不需要再重新写一遍
create view 视图名 as 查询语句
-- 将计算的sql语句保存在视图中
create view sum_view as select sum(if(name is not null,1,0) ) from tb_user;-- 当查询视图时,就会自动执行视图中的sql语句
select * from sum_view;
mysql中也可以使用视图:
-- (1)修改表字段注解和表注解
use hive3;
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;-- (2)修改分区字段注解
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8 ;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;-- (3)修改索引注解
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
8. hive的参数配置(理解)
hive的参数配置分为3种:
- 配置文件
- hive-site.xml 用户自定义的配置文件,我们对于hive修改都写在改文件中
- 当前环境文件在
/export/server/hive/conf/hive-site.xml
- 当前环境文件在
- hive-default.xml 系统的默认配置文件,运行服务时会优先读取hive-site.xml
- 命令行配置参数
hive --service hiveserver2 --hiveconf hive.root.logger=DEBUG,console
# 配置了日志级别为debug 将数据输出到控制台中
# 日志级别
debug -- 开发调试过程中的日志信息
info -- 服务正常执行时的日志信息
warn -- 服务与预期执行效果不一致时的日志信息
error -- 服务出现异常而停止运行时的日志信息
- 使用参数声明进行配置
- 这种配置方式,只有当前连接中生效,更换或退出连接后,设置失效
set mapreduce.job.reduces = 3;
三种配置方式的优先级(其实就是运行的先后顺序,后执行的覆盖先执行的)
配置文件 < 命令行配置参数 < 参数声明
三种配置方式的影响范围:
配置文件 > 命令行配置参数 > 参数声明
配置文件: 影响该文件目录启动的任何hive服务
命令行配置参数: 影响本次启动的hive服务,参数声明: 当前使用的连接connect
9. HIve的数据压缩和HIve的存储格式
9.1 HIve的数据压缩
hive的表的行数据是以文件方式存在hdfs
优点:
可以提高数据的传输效率,可以提高数据的存储效率
减少存储磁盘空间,降低单节点的磁盘IO。
由于压缩后的数据占用的带宽更少,因此可以加快数据在Hadoop集群流动的速度,减少网络传输带宽。缺点:
压缩和解压过程需要消耗资源(主要是cpu).如果服务性能较差,不建议压缩
小文件处理速度传输速度都不慢但是可能需要花费更多时间进行压缩(不善于处理小文件)
1. map任务从hdfs当中读取数据时需要解压
2. map向中间临时存储空间中存储数据时需要压缩
3. reduce任务从临时存储空间中提取map计算结果的时候需要解压
4. reduce任务计算完成后向hdfs中存储数据时需要压缩
总结: 从内存到磁盘时进行压缩, 从磁盘到内存时解压.
所以hive的压缩本质上时mapreduce的压缩,修改的是hadoop配置
压缩格式:原生的apache hadoop 是不支持snappy格式压缩的
| 压缩格式 | 压缩格式所在的类 |
|---|---|
| Zlib | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | org.apache.hadoop.io.compress.GzipCodec |
| Bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| Lzo | com.hadoop.compression.lzo.LzoCodec |
| Lz4 | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
默认文件的压缩方式是Zlib,可以在建表的时候指定表数据按照那种压缩方式存储数据,zlib压缩的占用空间少,但是消耗的时间长
实际开发建议使用Snappy 压缩空间和速度比较均衡
| 压缩算法 | 原始文件大小 | 压缩文件大小 | 压缩速度 | 解压速度 |
|---|---|---|---|---|
| gzip | 8.3 GB | 1.8 GB | 17.5 MB/s | 58 MB/s |
| bzip2 | 8.3 GB | 1.1 | 2.4 MB/s | 9.5 MB/s |
| LZO | 8.3 GB | 2.9 GB | 49.3 MB/s | 74.6 MB/s |
如果我们现在需要使用压缩格式,就直接将下方指令执行一遍即可(不需要记住,了解就行)
--设置Hive的中间压缩 也就是map的输出压缩
1)开启 hive 中间传输数据压缩功能
set hive.exec.compress.intermediate=true;
2)开启 mapreduce 中 map 输出压缩功能
set mapreduce.map.output.compress=true;
3)设置 mapreduce 中 map 输出数据的压缩方式
set mapreduce.map.output.compress.codec = org.apache.hadoop.io.compress.SnappyCodec;--设置Hive的最终输出压缩,也就是Reduce输出压缩
1)开启 hive 最终输出数据压缩功能
set hive.exec.compress.output=true;
2)开启 mapreduce 最终输出数据压缩
set mapreduce.output.fileoutputformat.compress=true;
3)设置 mapreduce 最终数据输出压缩方式
set mapreduce.output.fileoutputformat.compress.codec =org.apache.hadoop.io.compress.SnappyCodec;
4)设置 mapreduce 最终数据输出压缩为块压缩 还可以指定RECORD
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
9.2 存储格式
表数据存储方式有两种
一个行存储 一个列存储
行存储:
- 优点: 以整条记录为单位查询效率更高,插入和更新效率高
- 缺点: 无法跳过不必要的列, 压缩比例偏低,使用时消耗的内存和cpu资源比较多
列存储
- 优点: 查询数据时,可以跳过不必要的列,按照指定列查询效率高,压缩比例高,资源消耗少
- 缺点: 插入和更新效率较低, 不适合小数据量扫描
| name | age | gender |
|---|---|---|
| 小明 | 18 | 男 |
| 小芳 | 20 | 女 |
| 小丽 | 19 | 男 |
行式存储
小明 18 男 小芳 20 女 小丽 19 男
列式存储
小明 小芳 小丽 18 20 19 男 女 男
在实际开发中hive数仓更喜欢使用列式存储,因为hdfs不支持随机修改,我们也很少进行insert into插入, 更多的是进行数据的查询,且列式存储的时候可以跳过不必要的列,查询范围有所减少,对于服务器资源的消耗降低了,查询和使用的效率提高了
Hive支持的存储数的格式主要有:
- TEXTFILE(行式存储)
- SEQUENCEFILE(行式存储)
- ORC(列式存储)(推荐使用的存储方式,支持事务操作)
- PARQUET(列式存储)
默认的存储格式是 TEXTFILE(行式存储)
列存储的数据会转为二进制存储,所以文件打开后乱码
我们创建表的时候默认是STORED AS TEXTFILE 格式存储的
如果我们想要修改存储的格式可以在创建表的时候,设置存储格式。
比如:我想指定存储格式为ORC(orc 存储文件默认采用ZLIB 压缩。比 snappy 压缩的小),压缩格式snappy
stored as指定orc(列存储)存储方式 tblproperties(“orc.compress”=“SNAPPY”) 指定压缩方式
create table tb_visit_new(id int,name string,url string
) -- stored as指定orc(列存储)存储方式 tblproperties("orc.compress"="SNAPPY") 指定压缩方式stored as orc tblproperties("orc.compress"="SNAPPY");insert into tb_visit_new select * from tb_visit;select * from tb_visit_new;
10. Hive指令
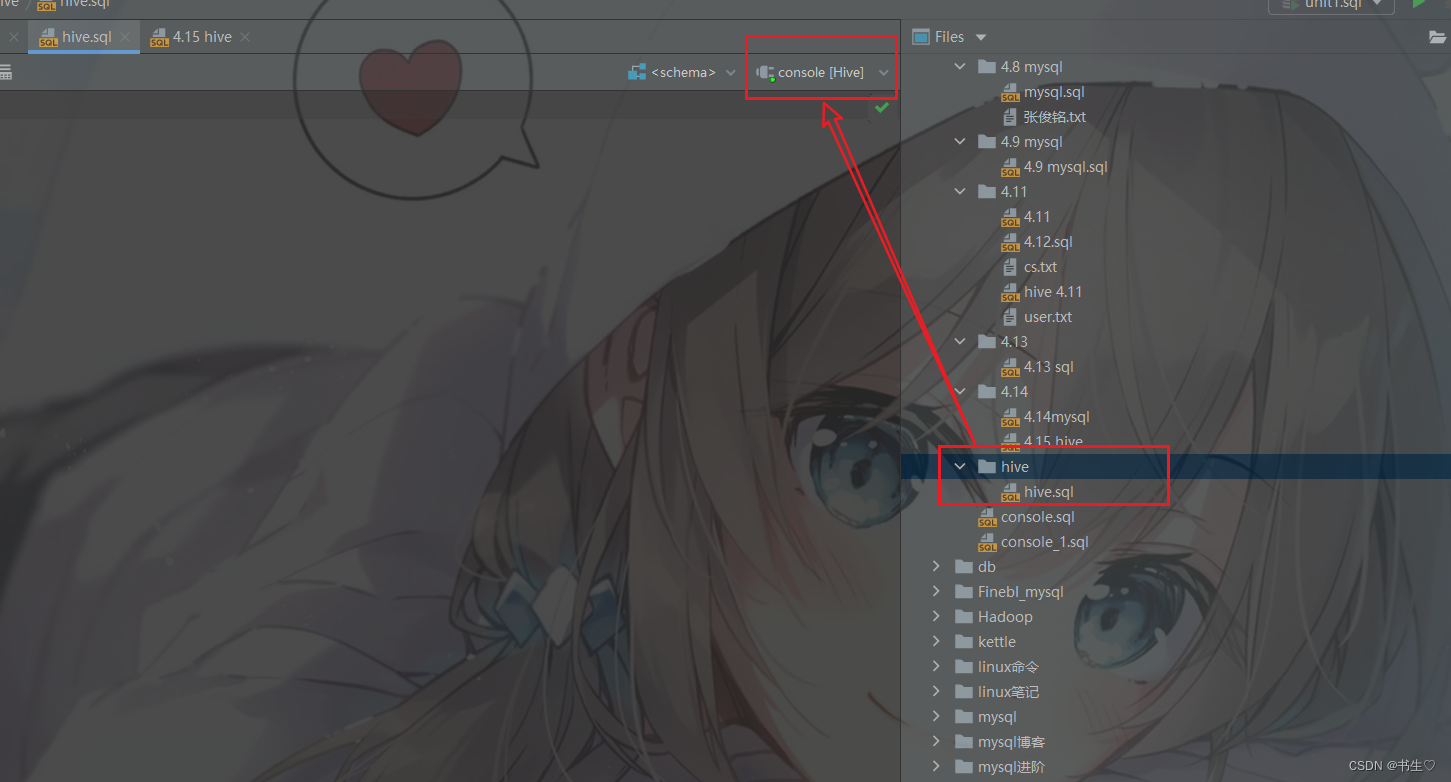
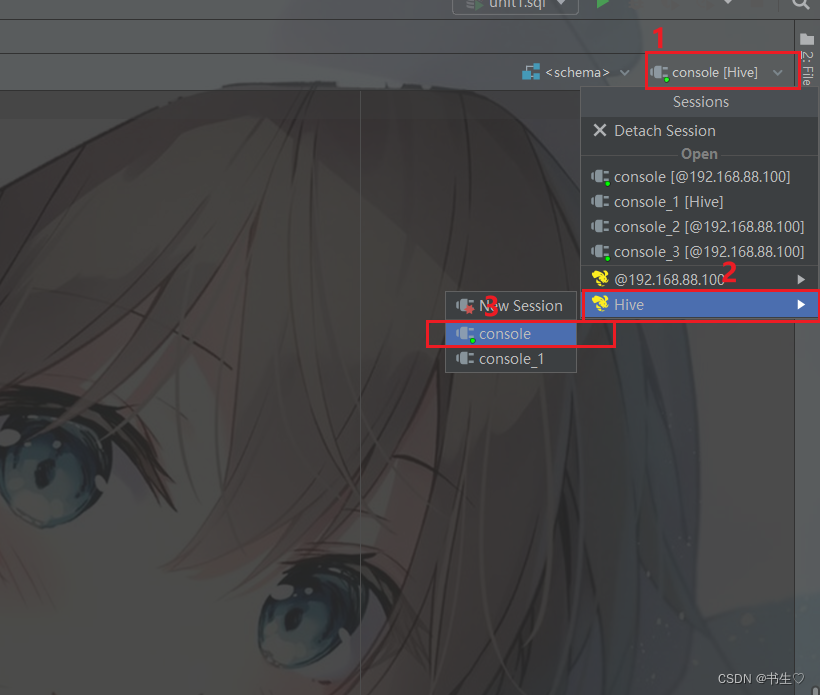
使用hive的shell指令,进行hive操作
1 点击右边的文件,创建一个文件夹,右键创建一个sql文件
2. 在右上角选择hive类型的
这样我们的hive语句就可以编写啦
- 我们在hive页面编写代码
- 将文件上传到服务器下
使用hive -f 执行sql文件,每次产生新数据后不需要重写sql语句,只需要执行sql文件
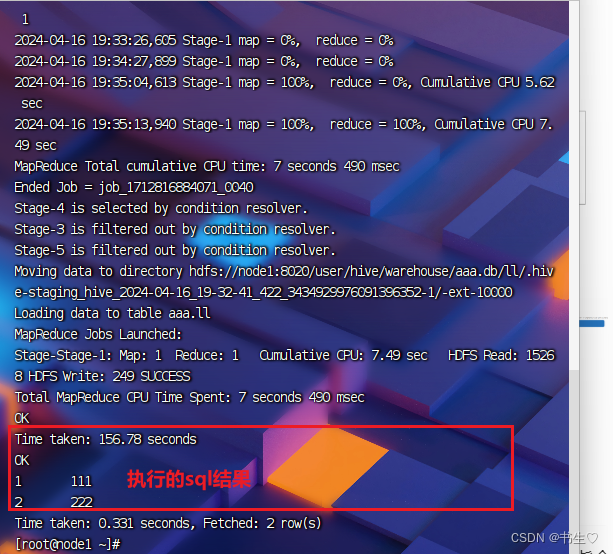
这篇关于【Hive下篇: 一篇文章带你了解表的静态分区,动态分区! 分桶!Hive sql的内置函数!复杂数据类型!hive的简单查询语句!】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



