日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件
http://flume.apache.org/FlumeUserGuide.html
Flume官网入门指南:
1:Flume的概述和介绍:
(1):Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
(2):Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到HDFS、hbase、hive、kafka等众多外部存储系统中
(3):一般的采集需求,通过对flume的简单配置即可实现
(4):Flume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以适用于大部分的日常数据采集场景
2:Flume的运行机制:
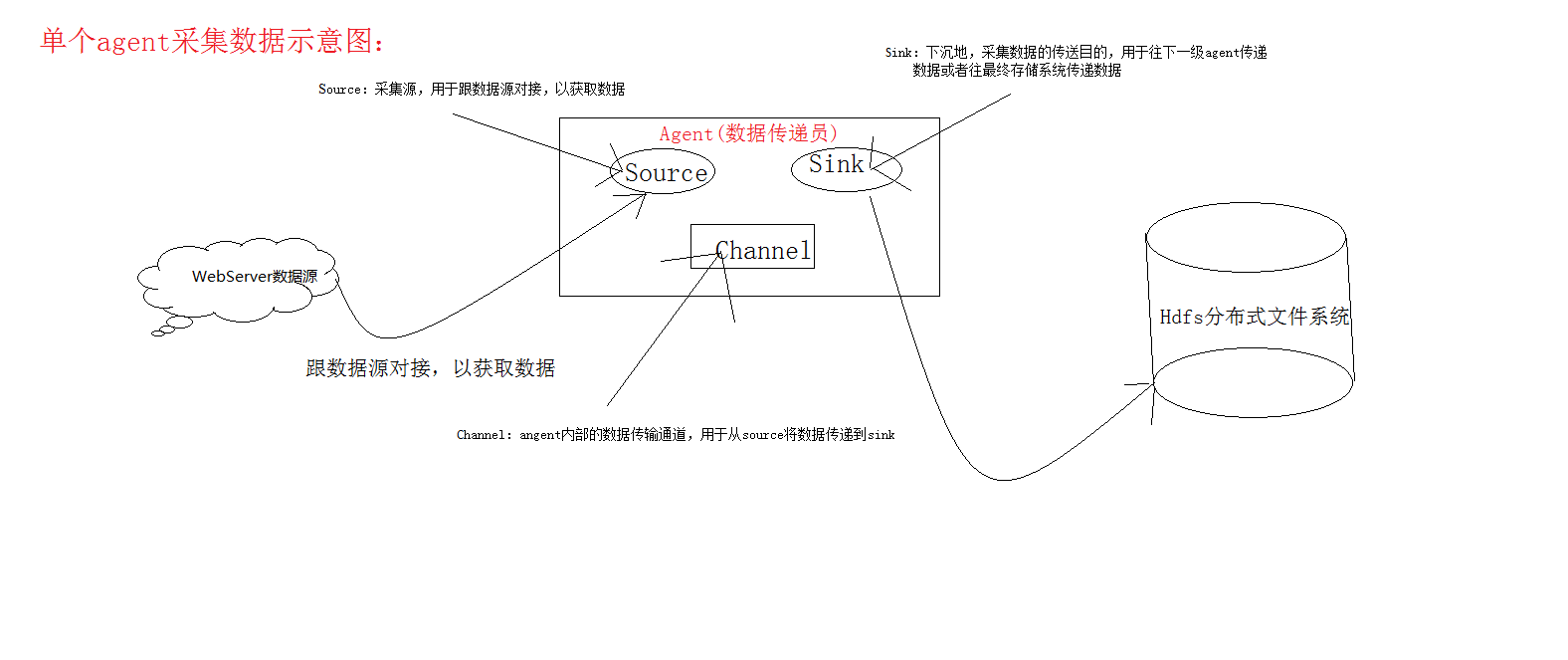
(1):Flume分布式系统中最核心的角色是agent,flume采集系统就是由一个个agent所连接起来形成。
(2):每一个agent相当于一个数据传递员,内部有三个组件:
a):Source:采集源,用于跟数据源对接,以获取数据。主要作用是接受客户端发送的数据,并将数据发送到channel中,source和channel之间的关系是多对多的关系,不过一般情况下使用一个source对应多个channel。通过名称区分不同的source。flume常用的source有:Avro Source,Thrift Source,Exec Source,Kafka Source,Netcat Source。
b):Sink:下沉地,采集数据的传送目的,用于往下一级agent传递数据或者往最终存储系统传递数据。主要作用就是定义数据写出方式,一般情况下sink从channel中获取数据,然后将数据写出到file,hdfs或者网络上。channel和sink之间的关系是一对多的关系,通过不同的名称来区分sink。Flume常用的sink有:hdfs sink,hive sink,file sink.hbase sink,avro sink,thrift sink,logger sink等等。
c):Channel:angent内部的数据传输通道,用于从source将数据传递到sink。主要作用是提供一个数据传输通道,提供数据传输和数据存储等功能。source将数据放到channel中,sink从channel中拿数据。通过不同的命令来区分channel。Flume常用的channel有:memory channel,jdbc channel,kafka channel,file channel等等。注意:Source 到 Channel 到 Sink之间传递数据的形式是Event事件;Event事件是一个数据流单元。
下面介绍单个Agent的fulme数据采集示意图:
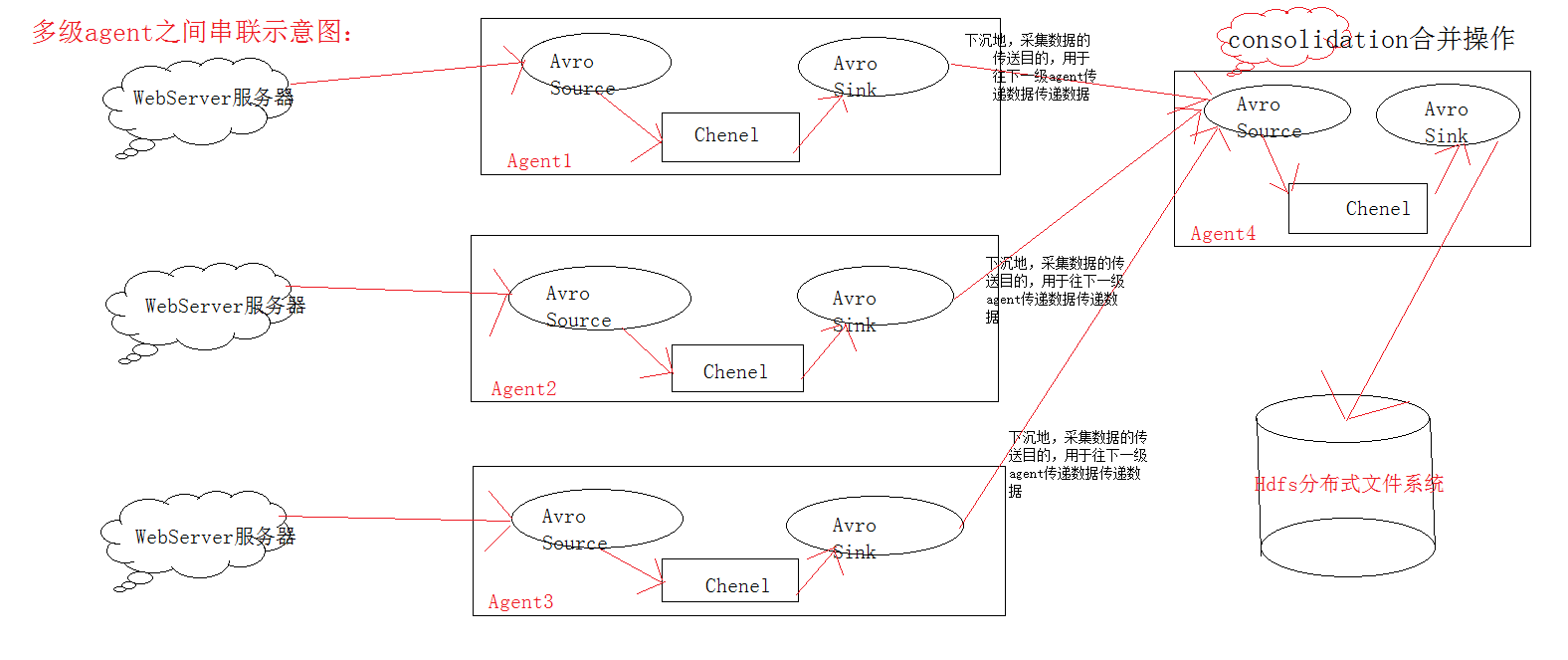
多级agent之间串联示意图:
3:Flume的安装部署:
(1)、Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境:
a):上传安装包到数据源所在节点上,上传过程省略。
b):然后解压 tar -zxvf apache-flume-1.6.0-bin.tar.gz;[root@master package]# tar -zxvf apache-flume-1.6.0-bin.tar.gz -C /home/hadoop/
c):然后进入flume的目录,修改conf下的flume-env.sh,在里面配置JAVA_HOME;(由于conf目录下面是 flume-env.sh.template,所以我复制一个flume-env.sh,然后进行修改JAVA_HOME)[root@master conf]# cp flume-env.sh.template flume-env.sh
[root@master conf]# vim flume-env.sh
然后将#注释去掉,加上自己的JAVA_HOME:export JAVA_HOME=/home/hadoop/jdk1.7.0_65
(2)、根据数据采集的需求配置采集方案,描述在配置文件中(文件名可任意自定义);
(3)、指定采集方案配置文件,在相应的节点上启动flume agent;(4)、可以先用一个最简单的例子来测试一下程序环境是否正常(在flume的conf目录下新建一个文件);
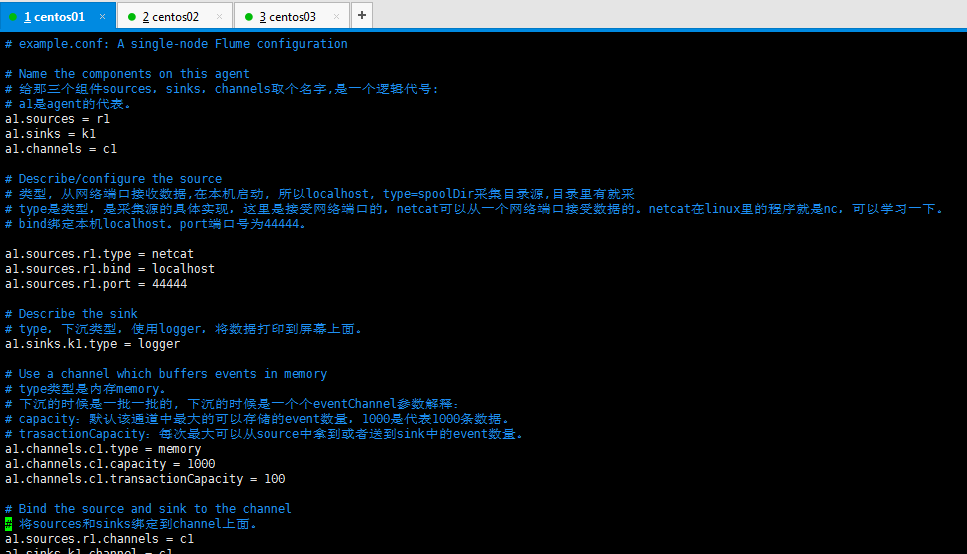
4:部署安装好,可以开始配置采集方案(这里是一个简单的采集方案配置的使用,从网络端口接收数据,然后下沉到logger), 然后需要配置一个文件,这个采集配置文件名称,netcat-logger.conf,采集配置文件netcat-logger.conf的内容如下所示:
1 # example.conf: A single-node Flume configuration 2 3 # Name the components on this agent 4 #定义这个agent中各组件的名字,给那三个组件sources,sinks,channels取个名字,是一个逻辑代号: 5 #a1是agent的代表。 6 a1.sources = r1 7 a1.sinks = k1 8 a1.channels = c1 9 10 # Describe/configure the source 描述和配置source组件:r1 11 #类型, 从网络端口接收数据,在本机启动, 所以localhost, type=spoolDir采集目录源,目录里有就采 12 #type是类型,是采集源的具体实现,这里是接受网络端口的,netcat可以从一个网络端口接受数据的。netcat在linux里的程序就是nc,可以学习一下。 13 #bind绑定本机localhost。port端口号为44444。 14 15 a1.sources.r1.type = netcat 16 a1.sources.r1.bind = localhost 17 a1.sources.r1.port = 44444 18 19 # Describe the sink 描述和配置sink组件:k1 20 #type,下沉类型,使用logger,将数据打印到屏幕上面。 21 a1.sinks.k1.type = logger 22 23 # Use a channel which buffers events in memory 描述和配置channel组件,此处使用是内存缓存的方式 24 #type类型是内存memory。 25 #下沉的时候是一批一批的, 下沉的时候是一个个eventChannel参数解释: 26 #capacity:默认该通道中最大的可以存储的event数量,1000是代表1000条数据。 27 #trasactionCapacity:每次最大可以从source中拿到或者送到sink中的event数量。 28 a1.channels.c1.type = memory 29 a1.channels.c1.capacity = 1000 30 a1.channels.c1.transactionCapacity = 100 31 32 # Bind the source and sink to the channel 描述和配置source channel sink之间的连接关系 33 #将sources和sinks绑定到channel上面。 34 a1.sources.r1.channels = c1 35 a1.sinks.k1.channel = c1
下面在flume的conf目录下面编辑这个文件netcat-logger.conf:
[root@master conf]# vim netcat-logger.conf
启动agent去采集数据,然后可以进行启动了,启动命令如下所示:
bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
-c conf 指定flume自身的配置文件所在目录
-f conf/netcat-logger.con 指定我们所描述的采集方案
-n a1 指定我们这个agent的名字
1 启动命令: 2 #告诉flum启动一个agent。 3 #--conf conf指定配置参数,。 4 #conf/netcat-logger.conf指定采集方案的那个文件(自命名)。 5 #--name a1:agent的名字,即agent的名字为a1。 6 #-Dflume.root.logger=INFO,console给log4j传递的参数。 7 $ bin/flume-ng agent --conf conf --conf-file conf/netcat-logger.conf --name a1 -Dflume.root.logger=INFO,console
演示如下所示:
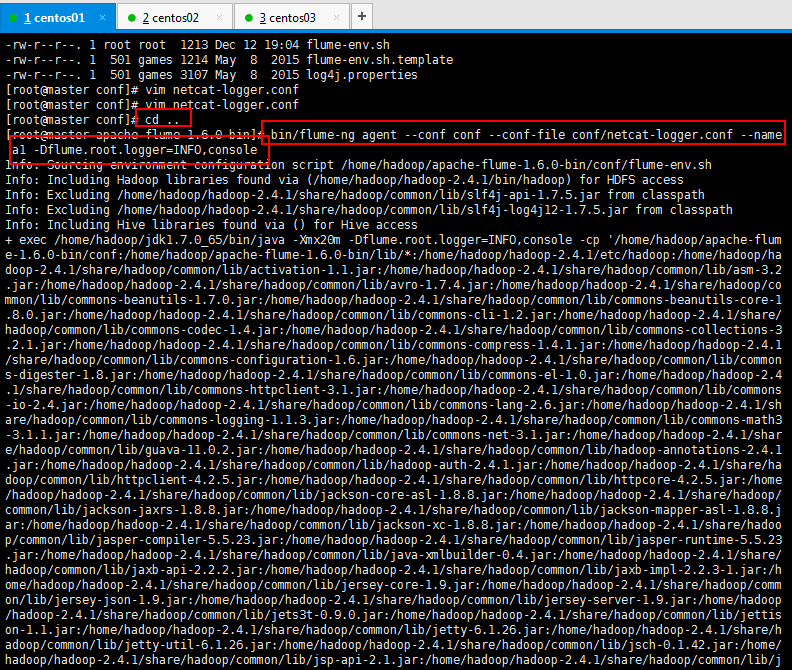
启动的信息如下所示,可以启动到前台,也可以启动到后台:
1 [root@master apache-flume-1.6.0-bin]# bin/flume-ng agent --conf conf --conf-file conf/netcat-logger.conf --name a1 -Dflume.root.logger=INFO,console 2 Info: Sourcing environment configuration script /home/hadoop/apache-flume-1.6.0-bin/conf/flume-env.sh 3 Info: Including Hadoop libraries found via (/home/hadoop/hadoop-2.4.1/bin/hadoop) for HDFS access 4 Info: Excluding /home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/slf4j-api-1.7.5.jar from classpath 5 Info: Excluding /home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/slf4j-log4j12-1.7.5.jar from classpath 6 Info: Including Hive libraries found via () for Hive access 7 + exec /home/hadoop/jdk1.7.0_65/bin/java -Xmx20m -Dflume.root.logger=INFO,console -cp '/home/hadoop/apache-flume-1.6.0-bin/conf:/home/hadoop/apache-flume-1.6.0-bin/lib/*:/home/hadoop/hadoop-2.4.1/etc/hadoop:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/activation-1.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/asm-3.2.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/avro-1.7.4.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/commons-cli-1.2.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/commons-codec-1.4.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/commons-collections-3.2.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/commons-compress-1.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/commons-configuration-1.6.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/commons-digester-1.8.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/commons-el-1.0.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/commons-httpclient-3.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/commons-io-2.4.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/commons-lang-2.6.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/commons-logging-1.1.3.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/commons-math3-3.1.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/commons-net-3.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/guava-11.0.2.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/hadoop-annotations-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/hadoop-auth-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/httpclient-4.2.5.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/httpcore-4.2.5.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/jackson-core-asl-1.8.8.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/jackson-jaxrs-1.8.8.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/jackson-mapper-asl-1.8.8.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/jackson-xc-1.8.8.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/jasper-compiler-5.5.23.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/jasper-runtime-5.5.23.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/jersey-core-1.9.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/jersey-json-1.9.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/jersey-server-1.9.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/jets3t-0.9.0.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/jettison-1.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/jetty-6.1.26.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/jetty-util-6.1.26.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/jsch-0.1.42.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/jsp-api-2.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/jsr305-1.3.9.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/junit-4.8.2.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/log4j-1.2.17.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/mockito-all-1.8.5.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/netty-3.6.2.Final.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/paranamer-2.3.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/servlet-api-2.5.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/stax-api-1.0-2.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/xmlenc-0.52.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/xz-1.0.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib/zookeeper-3.4.5.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/hadoop-common-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/hadoop-common-2.4.1-tests.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/hadoop-nfs-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/common/jdiff:/home/hadoop/hadoop-2.4.1/share/hadoop/common/lib:/home/hadoop/hadoop-2.4.1/share/hadoop/common/sources:/home/hadoop/hadoop-2.4.1/share/hadoop/common/templates:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/asm-3.2.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/commons-el-1.0.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/commons-io-2.4.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/guava-11.0.2.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/jackson-core-asl-1.8.8.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/jackson-mapper-asl-1.8.8.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/jasper-runtime-5.5.23.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/jsp-api-2.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/jsr305-1.3.9.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/hadoop-hdfs-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/hadoop-hdfs-2.4.1-tests.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/hadoop-hdfs-nfs-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/jdiff:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/lib:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/sources:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/templates:/home/hadoop/hadoop-2.4.1/share/hadoop/hdfs/webapps:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/activation-1.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/aopalliance-1.0.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/asm-3.2.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/commons-cli-1.2.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/commons-codec-1.4.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/commons-collections-3.2.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/commons-httpclient-3.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/commons-io-2.4.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/commons-lang-2.6.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/guava-11.0.2.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/guice-3.0.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/jackson-core-asl-1.8.8.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/jackson-jaxrs-1.8.8.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/jackson-mapper-asl-1.8.8.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/jackson-xc-1.8.8.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/javax.inject-1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/jersey-client-1.9.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/jersey-core-1.9.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/jersey-json-1.9.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/jersey-server-1.9.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/jettison-1.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/jetty-6.1.26.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/jline-0.9.94.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/jsr305-1.3.9.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/log4j-1.2.17.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/servlet-api-2.5.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/xz-1.0.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib/zookeeper-3.4.5.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/hadoop-yarn-api-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/hadoop-yarn-client-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/hadoop-yarn-common-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/hadoop-yarn-server-common-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/hadoop-yarn-server-tests-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/lib:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/sources:/home/hadoop/hadoop-2.4.1/share/hadoop/yarn/test:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/asm-3.2.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/guice-3.0.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/hadoop-annotations-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/hamcrest-core-1.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/jackson-core-asl-1.8.8.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.8.8.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/javax.inject-1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/junit-4.10.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib/xz-1.0.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.4.1-tests.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.1.jar:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/lib-examples:/home/hadoop/hadoop-2.4.1/share/hadoop/mapreduce/sources:/home/hadoop/hadoop-2.4.1/contrib/capacity-scheduler/*.jar:/lib/*' -Djava.library.path=:/home/hadoop/hadoop-2.4.1/lib/native org.apache.flume.node.Application --conf-file conf/netcat-logger.conf --name a1 8 2017-12-12 19:59:37,108 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider.start(PollingPropertiesFileConfigurationProvider.java:61)] Configuration provider starting 9 2017-12-12 19:59:37,130 (conf-file-poller-0) [INFO - org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:133)] Reloading configuration file:conf/netcat-logger.conf 10 2017-12-12 19:59:37,142 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:931)] Added sinks: k1 Agent: a1 11 2017-12-12 19:59:37,143 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1017)] Processing:k1 12 2017-12-12 19:59:37,143 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration$AgentConfiguration.addProperty(FlumeConfiguration.java:1017)] Processing:k1 13 2017-12-12 19:59:37,157 (conf-file-poller-0) [INFO - org.apache.flume.conf.FlumeConfiguration.validateConfiguration(FlumeConfiguration.java:141)] Post-validation flume configuration contains configuration for agents: [a1] 14 2017-12-12 19:59:37,158 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:145)] Creating channels 15 2017-12-12 19:59:37,166 (conf-file-poller-0) [INFO - org.apache.flume.channel.DefaultChannelFactory.create(DefaultChannelFactory.java:42)] Creating instance of channel c1 type memory 16 2017-12-12 19:59:37,172 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.loadChannels(AbstractConfigurationProvider.java:200)] Created channel c1 17 2017-12-12 19:59:37,174 (conf-file-poller-0) [INFO - org.apache.flume.source.DefaultSourceFactory.create(DefaultSourceFactory.java:41)] Creating instance of source r1, type netcat 18 2017-12-12 19:59:37,189 (conf-file-poller-0) [INFO - org.apache.flume.sink.DefaultSinkFactory.create(DefaultSinkFactory.java:42)] Creating instance of sink: k1, type: logger 19 2017-12-12 19:59:37,192 (conf-file-poller-0) [INFO - org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:114)] Channel c1 connected to [r1, k1] 20 2017-12-12 19:59:37,200 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:138)] Starting new configuration:{ sourceRunners:{r1=EventDrivenSourceRunner: { source:org.apache.flume.source.NetcatSource{name:r1,state:IDLE} }} sinkRunners:{k1=SinkRunner: { policy:org.apache.flume.sink.DefaultSinkProcessor@1ce79b8 counterGroup:{ name:null counters:{} } }} channels:{c1=org.apache.flume.channel.MemoryChannel{name: c1}} } 21 2017-12-12 19:59:37,210 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:145)] Starting Channel c1 22 2017-12-12 19:59:37,371 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.register(MonitoredCounterGroup.java:120)] Monitored counter group for type: CHANNEL, name: c1: Successfully registered new MBean. 23 2017-12-12 19:59:37,372 (lifecycleSupervisor-1-0) [INFO - org.apache.flume.instrumentation.MonitoredCounterGroup.start(MonitoredCounterGroup.java:96)] Component type: CHANNEL, name: c1 started 24 2017-12-12 19:59:37,376 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:173)] Starting Sink k1 25 2017-12-12 19:59:37,376 (conf-file-poller-0) [INFO - org.apache.flume.node.Application.startAllComponents(Application.java:184)] Starting Source r1 26 2017-12-12 19:59:37,377 (lifecycleSupervisor-1-3) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:150)] Source starting 27 2017-12-12 19:59:37,513 (lifecycleSupervisor-1-3) [INFO - org.apache.flume.source.NetcatSource.start(NetcatSource.java:164)] Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
然后可以向这个端口发送数据,就打印出来了,因为这里输出是在console的:
相当于产生数据的源:[root@master hadoop]# telnet localhost 44444
[root@master hadoop]# telnet localhost 44444
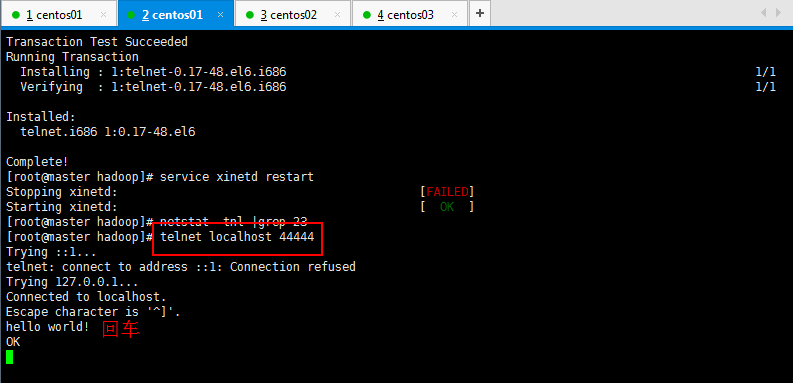
bash: telnet: command not found我的机器没有安装telnet ,所以先安装一下telnet ,如下所示:
第一步:检测telnet-server的rpm包是否安装 ???
[root@localhost ~]# rpm -qa telnet-server
若无输入内容,则表示没有安装。出于安全考虑telnet-server.rpm是默认没有安装的,而telnet的客户端是标配。即下面的软件是默认安装的。第二步:若未安装,则安装telnet-server:
[root@localhost ~]#yum install telnet-server
第三步:3、检测telnet的rpm包是否安装 ???
[root@localhost ~]# rpm -qa telnet
telnet-0.17-47.el6_3.1.x86_64第四步:若未安装,则安装telnet:
[root@localhost ~]# yum install telnet
第五步:重新启动xinetd守护进程???
由于telnet服务也是由xinetd守护的,所以安装完telnet-server,要启动telnet服务就必须重新启动xinetd
[root@locahost ~]#service xinetd restart完成以上步骤以后可以开始你的命令,如我的:
[root@master hadoop]# telnet localhost 44444
Trying ::1...
telnet: connect to address ::1: Connection refused
Trying 127.0.0.1...
Connected to localhost.
Escape character is '^]'.
解决完上面的错误以后就可以开始测试telnet数据源发送和flume的接受:
测试,先要往agent采集监听的端口上发送数据,让agent有数据可采集,随便在一个能跟agent节点联网的机器上:telnet localhost 44444
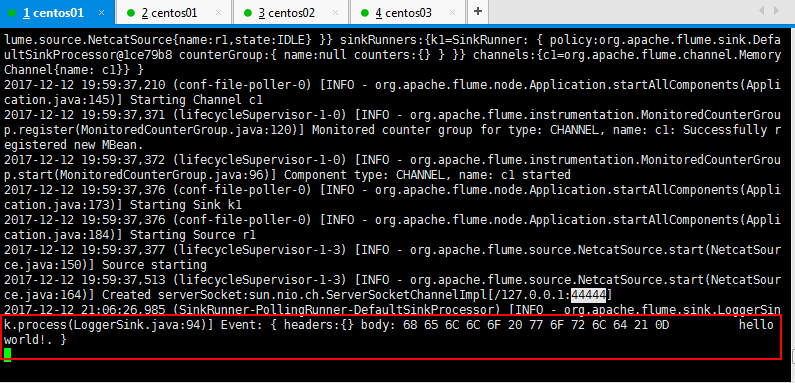
然后可以看到flume已经接受到了数据:
如何退出telnet呢???
首先按ctrl+]退出到telnet > ,然后输入telnet> quit即可退出,记住,quit后面不要加;
5:flume监视文件夹案例:
1 监视文件夹 2 3 4 第一步: 5 首先 在flume的conf的目录下创建文件名称为:vim spool-logger.conf的文件。 6 将下面的内容复制到这个文件里面。 7 8 # Name the components on this agent 9 a1.sources = r1 10 a1.sinks = k1 11 a1.channels = c1 12 13 # Describe/configure the source 14 #监听目录,spoolDir指定目录, fileHeader要不要给文件夹前坠名 15 a1.sources.r1.type = spooldir 16 a1.sources.r1.spoolDir = /home/hadoop/flumespool 17 a1.sources.r1.fileHeader = true 18 19 # Describe the sink 20 a1.sinks.k1.type = logger 21 22 # Use a channel which buffers events in memory 23 a1.channels.c1.type = memory 24 a1.channels.c1.capacity = 1000 25 a1.channels.c1.transactionCapacity = 100 26 27 # Bind the source and sink to the channel 28 a1.sources.r1.channels = c1 29 a1.sinks.k1.channel = c1 30 31 第二步:根据a1.sources.r1.spoolDir = /home/hadoop/flumespool配置的文件路径,创建相应的目录。必须先创建对应的目录,不然报错。java.lang.IllegalStateException: Directory does not exist: /home/hadoop/flumespool 32 [root@master conf]# mkdir /home/hadoop/flumespool 33 34 第三步:启动命令: 35 bin/flume-ng agent -c ./conf -f ./conf/spool-logger.conf -n a1 -Dflume.root.logger=INFO,console 36[root@master apache-flume-1.6.0-bin]# bin/flume-ng agent --conf conf --conf-file conf/spool-logger.conf --name a1 -Dflume.root.logger=INFO,console 37 第四步:测试: 38 往/home/hadoop/flumeSpool放文件(mv ././xxxFile /home/hadoop/flumeSpool),但是不要在里面生成文件。
6:采集目录到HDFS案例:
(1)采集需求:某服务器的某特定目录下,会不断产生新的文件,每当有新文件出现,就需要把文件采集到HDFS中去
(2)根据需求,首先定义以下3大要素
a):采集源,即source——监控文件目录 : spooldir
b):下沉目标,即sink——HDFS文件系统 : hdfs sink
c):source和sink之间的传递通道——channel,可用file channel 也可以用内存channel
(3):Channel参数解释:capacity:默认该通道中最大的可以存储的event数量;
trasactionCapacity:每次最大可以从source中拿到或者送到sink中的event数量;
keep-alive:event添加到通道中或者移出的允许时间;
配置文件编写:
1 #定义三大组件的名称 2 agent1.sources = source1 3 agent1.sinks = sink1 4 agent1.channels = channel1 5 6 # 配置source组件 7 agent1.sources.source1.type = spooldir 8 agent1.sources.source1.spoolDir = /home/hadoop/logs/ 9 agent1.sources.source1.fileHeader = false 10 11 #配置拦截器 12 agent1.sources.source1.interceptors = i1 13 agent1.sources.source1.interceptors.i1.type = host 14 agent1.sources.source1.interceptors.i1.hostHeader = hostname 15 16 # 配置sink组件 17 agent1.sinks.sink1.type = hdfs 18 agent1.sinks.sink1.hdfs.path =hdfs://master:9000/weblog/flume-collection/%y-%m-%d/%H-%M 19 agent1.sinks.sink1.hdfs.filePrefix = access_log 20 agent1.sinks.sink1.hdfs.maxOpenFiles = 5000 21 agent1.sinks.sink1.hdfs.batchSize= 100 22 agent1.sinks.sink1.hdfs.fileType = DataStream 23 agent1.sinks.sink1.hdfs.writeFormat =Text 24 agent1.sinks.sink1.hdfs.rollSize = 102400 25 agent1.sinks.sink1.hdfs.rollCount = 1000000 26 agent1.sinks.sink1.hdfs.rollInterval = 60 27 #agent1.sinks.sink1.hdfs.round = true 28 #agent1.sinks.sink1.hdfs.roundValue = 10 29 #agent1.sinks.sink1.hdfs.roundUnit = minute 30 agent1.sinks.sink1.hdfs.useLocalTimeStamp = true 31 # Use a channel which buffers events in memory 32 agent1.channels.channel1.type = memory 33 agent1.channels.channel1.keep-alive = 120 34 agent1.channels.channel1.capacity = 500000 35 agent1.channels.channel1.transactionCapacity = 600 36 37 # Bind the source and sink to the channel 38 agent1.sources.source1.channels = channel1 39 agent1.sinks.sink1.channel = channel1
7:采集文件到HDFS案例:
(1):采集需求:比如业务系统使用log4j生成的日志,日志内容不断增加,需要把追加到日志文件中的数据实时采集到hdfs
(2):根据需求,首先定义以下3大要素
采集源,即source——监控文件内容更新 : exec ‘tail -F file’
下沉目标,即sink——HDFS文件系统 : hdfs sink
Source和sink之间的传递通道——channel,可用file channel 也可以用 内存channel
配置文件编写:
1 agent1.sources = source1 2 agent1.sinks = sink1 3 agent1.channels = channel1 4 5 # Describe/configure tail -F source1 6 agent1.sources.source1.type = exec 7 agent1.sources.source1.command = tail -F /home/hadoop/logs/access_log 8 agent1.sources.source1.channels = channel1 9 10 #configure host for source 11 agent1.sources.source1.interceptors = i1 12 agent1.sources.source1.interceptors.i1.type = host 13 agent1.sources.source1.interceptors.i1.hostHeader = hostname 14 15 # Describe sink1 16 agent1.sinks.sink1.type = hdfs 17 #a1.sinks.k1.channel = c1 18 agent1.sinks.sink1.hdfs.path =hdfs://master:9000/weblog/flume-collection/%y-%m-%d/%H-%M 19 agent1.sinks.sink1.hdfs.filePrefix = access_log 20 agent1.sinks.sink1.hdfs.maxOpenFiles = 5000 21 agent1.sinks.sink1.hdfs.batchSize= 100 22 agent1.sinks.sink1.hdfs.fileType = DataStream 23 agent1.sinks.sink1.hdfs.writeFormat =Text 24 agent1.sinks.sink1.hdfs.rollSize = 102400 25 agent1.sinks.sink1.hdfs.rollCount = 1000000 26 agent1.sinks.sink1.hdfs.rollInterval = 60 27 agent1.sinks.sink1.hdfs.round = true 28 agent1.sinks.sink1.hdfs.roundValue = 10 29 agent1.sinks.sink1.hdfs.roundUnit = minute 30 agent1.sinks.sink1.hdfs.useLocalTimeStamp = true 31 32 # Use a channel which buffers events in memory 33 agent1.channels.channel1.type = memory 34 agent1.channels.channel1.keep-alive = 120 35 agent1.channels.channel1.capacity = 500000 36 agent1.channels.channel1.transactionCapacity = 600 37 38 # Bind the source and sink to the channel 39 agent1.sources.source1.channels = channel1 40 agent1.sinks.sink1.channel = channel1
待续......








