本文主要是介绍人工蜂群算法求解货位优化问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
人工蜂群算法求解货位优化问题
【标签】 ABC TSP Matlab
data:2018-10-19 author:怡宝2号
【总起】利用人工蜂群算法(Artificial Bee Colony Algorithm, 简称ABC算法)求解TSP问题,语言:matlab
1. 算法简介
人工蜂群算法(Artificial Bee Colony Algorithm, 简称ABC算法)是一个由蜂群行为启发的算法,在2005年由Karaboga小组为优化代数问题而提出。其主要是为了解决多变量函数优化问题。
2. 算法原理
标准的ABC算法通过模拟实际蜜蜂的采蜜机制将人工蜂群分为3类: 采蜜蜂、观察蜂和侦察蜂。整个蜂群的目标是寻找花蜜量最大的蜜源。在标准的ABC算法中,采蜜蜂利用先前的蜜源信息寻找新的蜜源并与观察蜂分享蜜源信息;观察蜂在蜂房中等待并依据采蜜蜂分享的信息寻找新的蜜源;侦查蜂的任务是寻找一个新的有价值的蜜源,它们在蜂房附近随机地寻找蜜源。所以算法总体分为3个部分。
假设问题的解空间是D维的,采蜜蜂与观察蜂的个数都是S,采蜜蜂的个数或观察蜂的个数与蜜源的数量相等。则标准的ABC算法将优化问题的求解过程看成是在D维搜索空间中进行搜索。每个蜜源的位置代表问题的一个可能解,蜜源的花蜜量对应于相应的解的适应度。一个采蜜蜂与一个蜜源是相对应的。与第i个蜜源相对应的采蜜蜂依据如下公式寻找新的蜜源:
其中,i=1,2,···,S,表示蜜源、采蜜蜂、观察蜂的个数,D=1,2,···,D,表示优化变量的个数。Φid为[-1,1]之间的随机数,k≠i。
将新生成的可能解{Xi1’,Xi2’,···,XiD’}与原来的解{Xi1,Xi2,···,XiD}做比较,采用贪婪选择策略保留较好的解。
对每个采蜜蜂按上式对每个采蜜蜂计算一个概率。观察蜂以上面计算的概率接受采蜜蜂,并利用采蜜蜂更新的公式进行更新,再进行贪婪选择。
当所有的采蜜蜂和观察蜂都搜索完整个搜索空间时,如果一个蜜源的适应值在给定的步骤内(定义为控制参数“limit”) 没有被提高, 则丢弃该蜜源,而与该蜜源相对应的采蜜蜂变成侦查蜂,侦查蜂通过已下公式搜索新的可能解。
其中,r是[0,1]的随机数,xmin和xmax是第d个变量空间的下界和上界。
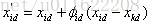
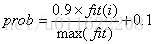
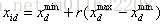
3. 模型
3.1 模型假设
根据已知条件,可作出以下假设:
(1)立体货架模型被定义为一个标准的长方体的点集合(x,y,z),以理想模型进行考虑,并将(0,0,0)作为出口坐标;
(2)商品有销售记录;
(3)堆垛机按直线运行;
(4)只考虑商品出库;
(5)堆垛机取货时间不计,只考虑堆垛机的运行速度;
(6)每个巷道只有一个堆垛机;
(7)货物体积完全相同,质量不同;
(8)货架长宽高均为1m,货物体积均为1m3。
3.2 符号规定

货位优化的多目标数学模型是建立以出库效率作为主要目标,货架稳定性作为次要目标的基础上。如下所示:

4. 总结
- 人工蜂群算法主要分:采蜜、观察、侦察三个阶段;
- 整个原理和遗传算法的原理很类似,采蜜蜂就相当于初始化父代chrom,观察蜂相当于轮盘赌选择之后的子代,侦察蜂就是在limit次中没能找到更优秀的解时,舍弃该解,再随机初始化。
5. 程序和结果
% Author: 怡宝2号 博士猿工作室
% 淘宝链接: https://shop437222340.taobao.com/index.htm?spm=2013.1.w5002-16262391244.6.733e1fb4LF2f58% Use: 基于人工蜂群算法的三维货位优化/基于坐标点的编码方式
% 输入变量(可修改量): TurnOver:每个货物的周转率
% Weight:每个货物的重量
% runtime:运行的次数
% numgoods:货物的个数
%
% 输出: res:最优结果记录
% Remark: 本人qq:778961303,如有疑问请咨询clc;clear all;close all;format compact% 参数初始化
[parameter] = initialtwo();% 画出初始货位位置
initialDraw(parameter);% 所有空货位的集合
[CHROM] = TotalGoods(parameter.X, parameter.Y, parameter.Z);for r = 1:parameter.runtime% 随机生成初始种群for i=1:parameter.foodnumbertemp = randperm(parameter.totaltray);Foods(i,:) = temp;end% 计算目标函数和种群适应度[ Fitness, fitval] = calculatefitness(Foods, parameter, CHROM);% 初始化搜索次数,用于和Limit比较trial=zeros(1,parameter.foodnumber);%找出适应度函数值的最小值BestInd=find(Fitness==min(Fitness));BestInd=BestInd(end); %避免有两个相同的位置,只取其一GlobalMin=Fitness(BestInd);GlobalParams=Foods(BestInd,:);%迭代开始iter=1; %初始化迭代次数while((iter <= parameter.maxCycle))%% 采蜜蜂for i=1:parameter.foodnumber%计算新蜜源的适应度函数值[FitnessSol, ~]=calculatefitness(Sol, parameter, CHROM);%使用贪婪准则,寻找最优蜜源if (FitnessSol<Fitness(i)) %若找到更好的蜜源,搜索次数清零Foods(i,:)=Sol;Fitness(i)=FitnessSol;trial(i)=0;elsetrial(i)=trial(i)+1; %不能找到更优解超过设定的Limit次,则该蜂成为侦察蜂/重新初始化endend%计算采蜜蜂被选出的概率prob=(0.9.*Fitness./max(Fitness))+0.1;%% 观察蜂i=1; %要跟随的采蜜蜂t=0; %标记观察蜂while(t<parameter.foodnumber)if (rand<prob(i)) %按概率选择要跟随的采蜜蜂t=t+1;%计算新蜜源的适应度函数值[FitnessSol, ~]=calculatefitness(Sol, parameter, CHROM);%使用贪婪准则,保留优秀的蜜蜂if (FitnessSol<Fitness(i)) %若找到更好的蜜源,搜索次数清零Foods(i,:)=Sol;Fitness(i)=FitnessSol;trial(i)=0;elsetrial(i)=trial(i)+1; %超过设定的Limit次,则该蜂成为侦察蜂//重新初始化endendi=i+1; %要跟随的下一个采蜜蜂if (i==(parameter.foodnumber)+1)i=1;endend% 记录最优解ind=find(Fitness==min(Fitness));ind=ind(end);if (Fitness(ind)<GlobalMin)GlobalMin=Fitness(ind);GlobalParams=Foods(ind,:);end%% 侦查蜂ind=find(trial==max(trial));ind=ind(end);if (trial(ind) > parameter.Limit) %若搜索次数超过极限值,则进行随机搜索产生新解end%%记录每代的最优解trace(iter) = GlobalMin; % 最小值bestABC(iter,:) = GlobalParams; % 最优参数iter=iter+1;endres{r}.min = GlobalMin;res{r}.trace = trace;res{r}.param = GlobalParams;disp(['第',num2str(r),'次运行得到的参数为:',num2str(GlobalParams(1:parameter.numgoods) ),',此参数对应的目标函数最小值为:',num2str(GlobalMin)])endminnumber = res{1}.min;
index = 1;
for i=2:parameter.runtimeif minnumber > res{i}.minminnumber = res{i}.min;index = iendend
%% 画出迭代图
figure(2);
plot(res{index}.trace,'b');
xlabel('迭代次数');
ylabel('目标值');%% 画出优化后的货位分配情况图
%解码染色体
result = res{index}.param(1:parameter.numgoods);
p = [];
for i=1:length(result)p = [p CHROM(result(i),:)];coordinate(i,:) = CHROM(result(i),:);
end
% disp(['优化前目标函数为:',num2str(max(trace))]);
disp(['优化后目标函数为:',num2str(res{index}.min)]);
disp(['优化后货物分配的货位为:',num2str(p)]);
coordinatefigure()
%%画出优化后的货位分配
finalDraw(coordinate, parameter);结果:

这篇关于人工蜂群算法求解货位优化问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







