本文主要是介绍计算机毕业设计hadoop+spark+hive舆情分析系统 微博数据分析可视化大屏 微博情感分析 微博爬虫 微博大数据 微博推荐系统 微博预测系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本 科 毕 业 论 文
论文题目:基于Hadoop的热点舆情数据分析与可视化
| 姓名: | 金泓羽 | 学号: | 20200804050115 | ||
| 导师: | 关英 | 职称: |
| ||
| 专业: | 数据科学与大数据技术 | 提交日期: | 2024 年 月 日 | ||
独创性声明
本人呈交的学位论文,是在导师的指导下,独立进行研究工作所取得的成果,所有数据、图片资料真实可靠。尽我所知,除文中已经注明引用的内容外,本学位论文的研究成果不包含他人享有著作权的内容。对本论文所涉及的研究工作做出贡献的其他个人和集体,均已在文中以明确的方式标明。本学位论文的知识产权归属于培养单位。
本人签名:金泓羽 日期:
Hadoop-based hot public opinion data analysis and visualization
作 者 姓 名: 金泓羽
专 业: 数据科学与大数据技术
学 号: 20200804050115
指 导 教 师: 关英
完 成 日 期:
兰 州 城 市 学 院
Lanzhou City University
Abstract
With the popularity of social media and the rapid development of Internet technology, hot public opinion events occur frequently. For the government, enterprises and the public, it has become an important task to timely understand and analyze hot public opinion and grasp the trend of public opinion. However, the traditional data processing and analysis methods are powerless in the face of massive and real-time public opinion data, and cannot meet the needs of timely, accurate and comprehensive analysis. Therefore, this study uses Hadoop, Hive and other technologies to conduct a comprehensive analysis of hot public opinion by taking microblog data as an example.
Aiming at the crawling problem of microblog data, this system uses Selenium to realize the automatic crawling of data and store the data into MySQL database. It can efficiently crawl a large number of microblog data, including title, popularity, time, author, province, forwarding, hot search and other information.
For massive data preprocessing, the system uses mapreduce for data preprocessing. The data in MySQL is divided, sorted, merged, reduced and other operations are distributed to achieve fast and efficient data preprocessing. Then, to facilitate data analysis and visualization, convert the preprocessed data into.csv files and upload them to the HDFS file system. Then use Hive to create libraries and tables and import.CSV data sets.
Faced with the problem of analysis and visualization of microblog data, the system uses Hive for data analysis, and can quickly aggregate and screen microblog data. Import the analysis results into MySQL database using sqoop, and use Flask and Echarts to visually visualize the data, such as drawing pie charts, scatter charts, bar charts, maps, etc., for easy analysis and decision making.
To sum up, the system realizes automatic crawling of microblog data, efficient pre-processing of massive data, distributed uploading of data, and rapid analysis and visualization of data through the above steps. This research can provide data support for relevant enterprises such as airlines, so as to optimize and make decisions on flight routes.
Key Words:Hadoop; Public sentiment; Hive; Sqoop; visualization
目 录
摘 要
Abstract
1.绪论
1.1研究背景及意义
2.相关平台与技术介绍
2.1 Hadoop 集群
2.2 MySQL
2.3 Hive
2.4 Selenium
2.5 ECharts
3系统实现过程
4.平台搭建与部署
4.1 MySQL 部署
4.2Xshell部署
4.3Hadoop部署
4.4Hive部署
5.数据的流转过程与处理
5.1舆情数据分析的意义
5.2数据的爬取过程
5.2.1爬取评论数据(标题、链接)
5.2.2爬取热搜数据
5.2.3爬取文章数据(用户姓名、内容,转发评论点赞数)
5.3数据预处理
5.4数据上传Hive
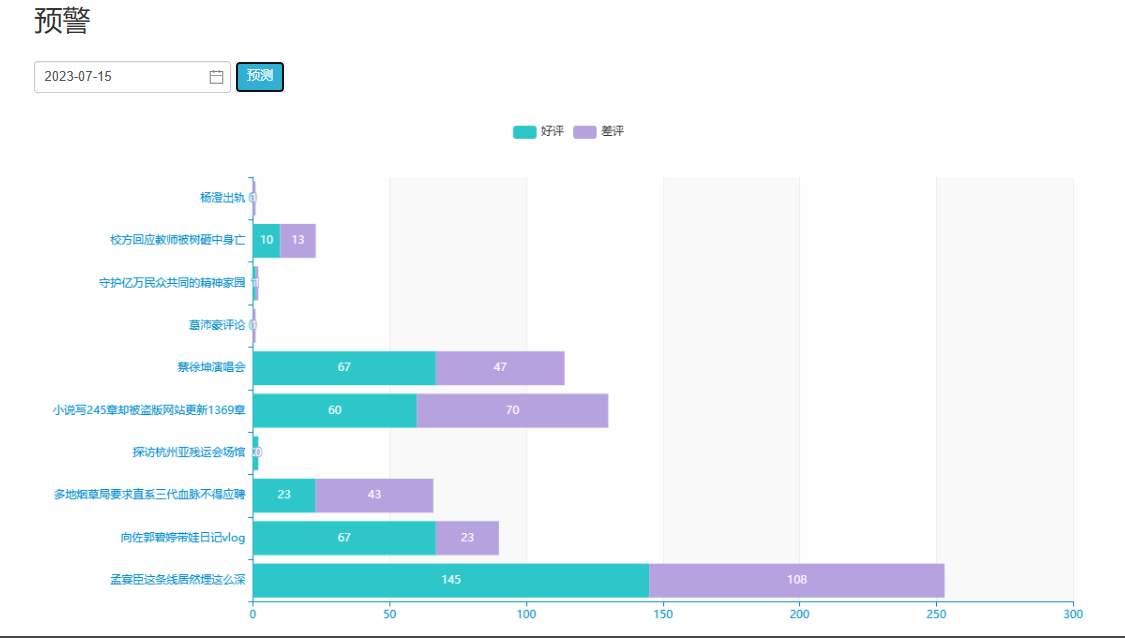
5.5数据可视化
6.结论和展望
6.1研究总结和贡献
6.2局限性和改进方向
6.3未来的发展和应用展望
参考文献
致 谢
s
1.绪论
1.1研究背景及意义
随着互联网应用越来越广泛,人们在网络上产生的数据量呈现爆发式增长。海量数据的日益增加,传统的数据管理系统和人工处理模式已经不能满足越来越复杂的数据。特别是云计算、分布式系统、虚拟化等新技术的出现,为大数据的存储、处理和分析提 供了更加高效、安全和灵活的方法和手段。此外,社交网络、移动设备、物联网等新兴 技术的快速发展也加速了大数据时代的到来。这些技术不仅让我们能够更加方便地获取、存储和传输数据,也让我们能够更好地理解和利用数据,从而为个人、企业、政府和社会带来更多的价值。同时,大数据也成为推动数字经济、人工智能等产业发展的重要动力。
在当今社会,随着互联网和社交媒体的普及,热点舆情事件频繁发生,其影响力和波及范围不断扩大。这些舆情数据包含了大量的公众意见、情感倾向、事件发展脉络等信息,对于政府、企业和公众都具有极高的价值。通过对这些数据进行深入挖掘和分析,可以洞察社会动态,预测趋势,为决策提供有力支持。
大数据技术的快速发展为热点舆情的研究提供了新的机遇。特别是Hadoop和Hive等大数据处理工具,以其强大的数据处理能力和高效的查询分析功能,为热点舆情的分析提供了强大的技术支持。
Hadoop作为一个分布式计算框架,可以实现对海量舆情数据的分布式处理,有效应对数据规模的不断增长。通过MapReduce算法,Hadoop可以对数据进行并行计算,提高处理效率。而Hive则作为一个基于Hadoop的数据仓库工具,提供了类似于SQL的查询接口,使得用户可以方便地对舆情数据进行查询和分析。
基于Hadoop和Hive的热点舆情分析,可以帮助政府、企业和公众更好地了解舆情事件的来龙去脉,把握公众意见和情感倾向,为决策提供参考。具体来说,可以通过分析舆情数据,进行以下方面的探索:
(1)舆情事件监测与预警。
通过对社交媒体、新闻网站等渠道的舆情数据进行实时监测,可以及时发现潜在的热点事件,为政府和企业提供预警和应对建议。
(2)公众意见与情感分析
通过对舆情数据中的文本信息进行挖掘和分析,可以了解公众对于某个事件或政策的看法和情感倾向,为政府和企业提供决策依据。
(3)舆情趋势预测与分析
通过对历史舆情数据的分析和建模,可以预测未来舆情的发展趋势和可能的走向,为政府和企业提供前瞻性分析和战略规划。
综上所述,基于Hadoop和Hive的热点舆情分析可以为政府、企业和公众提供更加全面、准确和实时的数据分析支持,帮助各方更好地了解社会动态,预测趋势,为决策提供有力支持。随着大数据技术的不断发展和完善,相信未来大数据在热点舆情研究中的应用将会更加广泛和深入。
2.相关平台与技术介绍
2.1 Hadoop 集群
Hadoop 是一个开源的分布式计算框架,它主要用于处理大规模数据集的分布式存 储和处理。hadoop 由多个节点组成,必须有一个主节点(也称为“NameNode”)和多个 从节点(也称为“DataNode”)。主节点管理整个 Hadoop 集群的文件系统和数据存储,从节点则负责存储数据和执行计算任务。Hadoop 集群的工作原理如下:
数据存储:在 Hadoop 集群中,数据通常分为多个块,并存储在从节点的本地磁盘 上。主节点负责跟踪文件系统中所有数据块的位置。
数据处理:Hadoop使用“MapReduce”编程模型来处理数据。
MapReduce是 Hadoop的核心组件之一,它是一种基于分布式计算的编程模型和处 理框架,用于处理大规模数据集。MapReduc可以自动并行处理和处理数据,同时将数据划分为小块,使其可以在 Hadoop集群中的多个节点上进行处理。MapReduce编程 模型的核心思想是将数据分解成多个独立的块,每个块在不同的计算节点上进行处理, 并将结果合并到最终结果中。MapReduce主要包括两个阶段:映射(Map)和归约(Reduce)。映射阶段(Map):在这个阶段中,MapReduce 将输入数据分成多个块,并将这些块分 配给不同的计算节点,每个计算节点执行相同的计算操作。每个计算节点将输入块处理 成中间键值对(Key-Value Pairs),其中 Key是映射函数计算的结果,Value是输入数据 中的一个记录。每个键值对被写入到中间结果集合中。归约阶段(Reduce):在这个阶段中,MapReduce 将相同的键值对合并,以生成最终结果。Reduce函数将中间结果 集合中的每个 Key 作为输入,对其进行处理,并输出最终结果集合。MapReduce具有以下优点:可扩展性:MapReduce能够自动分配和处理大量数据,而无需人工干预高效性:MapReduce能够并行处理多个数据块,并将结果组合成一个最终结果集。可靠性:MapReduce可以处理节点故障,并将任务重新分配到其他节点上。总之,MapReduce 是一种强大的分布式计算框架,可以处理大规模数据集,并具有可扩展性、高效性和可靠性等优点。它被广泛应用于大数据处理、数据挖掘、机器学习等领域。
集群管理:Hadoop集群有多个组件,包括主节点和从节点之间的通信和资源管理。 Hadoop还可以通过 Hadoop YARN(Yet Another Resource Negotiator)实现多种应用程序的资源调度和管理。
Hadoop集群的优点:
(1)可扩展性:Hadoop集群可以通过添加更多从节点来增加其存储和处理能力。
(2)高可用性:由于数据和计算任务都是在多个节点上分布式存储和处理,因此即 使一个节点失败,整个集群也不会停止工作。
(3)低成本:Hadoop可以在低成本的硬件上运行,因为它可以在多个节点上分布式 基于 Hadoop 与 Hive的航班线路数据分析及可视化存储和处理数据。
(4)处理大数据:Hadoop集群可以处理大规模数据集,包括结构化和非结构化数据。
总之,Hadoop集群是一个强大的分布式计算框架,可以处理大规模数据集,并具 有高可用性,可扩展性和低成本的优点。
2.2 MySQL
MySQL是一种流行的开源关系型数据库管理系统(RDBMS),最初由瑞典 MySQLAB公司开发并推广,现在属于 Oracle 公司旗下产品。MySQL 是一种跨平台的数据库系统。MySQL 是一种跨平台的数据库系统,可以在多种操作系统上运行,如 Linux、Windows、Mac等。
MySQL 的主要功能包括:
(1)数据库管理:MySQL 可以创建、修改、删除和管理多个数据库,并支持多种数据库对象类型,如表、视图、存储过程、触发器等。
(2)数据存储:MySQL 可以将数据存储在多个数据表中,并支持多种数据类型,如整数、浮点数、日期、字符串等。
(3)数据查询:MySQL 支持 SQL 语言,可以执行复杂的数据查询操作,如查询多表数据、使用聚合函数、联合查询、子查询等。
(4)数据备份和恢复:MySQL 提供了多种备份和恢复工具,如 MySQLdump、MySQLhotcopy 等,可以帮助用户备份和恢复数据,以保证数据的安全性和可靠性。
(5)数据安全:MySQL 提供了多种安全性措施,如用户权限管理、SSL 加密、访问控制等,可以保护用户数据免受恶意攻击和非法访问。
(6)扩展性:MySQL 支持多种存储引擎,如 InnoDB、MyISAM 等,用户可以根据需要选择不同的存储引擎来满足不同的需求。
(7)性能优化:MySQL 提供了多种性能优化工具和技术,如索引、查询优化、缓存、分区等,可以提高数据库的性能和响应速度。
2.3 Hive
Hive 是一个基于 Hadoop 的数据仓库工具,它提供了一种将结构化数据映射为数据库表的方式,并支持使用类 SQL 查询语言进行查询。Hive 的主要目标是将复杂的数据分析转化为简单的数据查询操作,使得大数据分析更加容易。
Hive 的架构基于 Hadoop,它使用 Hadoop 的 HDFS 作为数据存储,使用 MapReduce作为计算框架。Hive 将结构化数据映射为表格,类似于传统的关系型数据库,但是与传统数据库不同的是,Hive 的表格可以存储在 HDFS 中,可以支持 PB 级别的数据规模。
Hive 的表格结构由列和分区组成。列定义表格中的数据类型和名称,分区定义表格中数据的划分方式。Hive 支持多种数据类型,包括基本数据类型(如 int、string、boolean等)、复杂数据类型(如数组、结构体、映射等)和自定义数据类型(可以通过 UDF 定义)。
Hive 提供了类 SQL 查询语言(HiveQL)进行查询,这使得用户可以使用熟悉的查询语言来查询数据。HiveQL 支持 SELECT、FROM、WHERE、GROUP BY、ORDER BY 等关键字,可以进行数据过滤、聚合、排序等操作。HiveQL 还支持多种内置函数,如字符串函数、日期函数、数学函数等,这些函数可以帮助用户更加方便地进行数据处理。
除了HiveQL 之外,Hive 还支持自定义函数(UDF)和自定义聚合函数(UDAF)。用户可以编写自己的 UDF 和 UDAF,并将它们添加到 Hive中,以便在查询中使用。这些自定义函数可以扩展 Hive的功能,使得用户可以处理更加复杂的数据。
Hive 还支持数据导入和导出,用户可以将数据从其他数据源(如关系型数据库、文本文件、HBase 等)导入到Hive 中,也可以将数据从Hive 中导出到其他数据源中。Hive支持多种数据格式,包括文本、CSV、JSON、ORC 等,用户可以根据需要选择合适的数据格式进行数据存储和查询。
Hive的优点是它易于使用和学习,使用 HiveQL可以快速编写复杂的查询语句。Hive支持扩展性,用户可以编写自己的UDF和UDAF来扩展Hive的功能。Hive还支持高可靠性和容错性,它可以在集群中自动处理故障,并进行数据备份和恢复。
2.4 Selenium
Selenium爬虫技术是一种基于Selenium库的自动化爬虫技术。Selenium最初是一个用于Web应用程序测试的工具,后来被广泛应用于爬虫领域,主要用于解决一些传统爬虫技术无法处理的问题,如JavaScript渲染、动态加载数据等。
Selenium爬虫的工作原理是通过模拟浏览器行为来与目标网站进行交互。它使用浏览器驱动程序(如ChromeDriver、GeckoDriver等)来控制浏览器,并完全模拟用户的操作,如点击、输入、滚动等。在爬虫过程中,Selenium会加载并渲染完整的网页,包括由JavaScript动态生成的内容,从而获取到更完整的网页信息。
Selenium爬虫的优点包括:
支持JavaScript渲染:Selenium可以执行JavaScript代码,从而获取到由JavaScript动态生成的内容,解决了传统爬虫无法处理JavaScript渲染的问题。
可视化操作:Selenium爬虫的操作过程可以观察到,类似于用户在手动操作浏览器,这对于调试和观察爬虫行为非常有帮助。
支持多种浏览器:Selenium支持多种主流浏览器,如Chrome、Firefox、Edge等,可以灵活选择适合的浏览器进行爬虫操作。
然而,Selenium爬虫也存在一些缺点:
爬取数据效率较低:由于Selenium需要模拟浏览器行为,因此相对于传统爬虫技术,其爬取数据的效率较低。环境部署繁琐:Selenium爬虫需要安装浏览器驱动程序,并配置相应的环境,相对于传统爬虫技术来说,部署过程较为繁琐。
总的来说,Selenium爬虫技术适用于需要处理JavaScript渲染、动态加载数据等复杂情况的爬虫任务。它提供了一种可视化、灵活且强大的爬虫解决方案,但也需要考虑其效率和部署方面的限制。
2.5 ECharts
ECharts(Enterprise Charts)是一个开源的、基于JavaScript的数据可视化图表库,由百度团队开发并维护。它提供了丰富的图表类型,如折线图、柱状图、散点图、饼图、K线图等,以及多种交互组件,如标题、图例、数据区域、时间轴等。ECharts的图表可以通过数据驱动,实现动态数据的可视化,同时支持图表之间的联动和混搭展现。
ECharts具有以下几个特点:
丰富的图表类型:ECharts提供了多种类型的图表,可以满足不同领域的数据可视化需求。无论是用于展示统计数据的折线图、柱状图,还是用于展示地理数据的地图、热力图,ECharts都能提供合适的图表类型。
交互性强:ECharts支持多种交互操作,如缩放、平移、数据区域选择等,用户可以通过交互操作来深入探索数据,获取更多的信息。
高度个性化定制:ECharts允许用户对图表的各个元素进行个性化定制,包括颜色、字体、边框等,以满足用户的审美需求。
数据驱动:ECharts由数据驱动,数据的改变会驱动图表展现的改变。这使得动态数据的实现变得简单而高效。
移动端优化:ECharts对移动端进行了优化,提供了小体积的图表库,并提供了按需打包的能力,以减小移动端应用的体积。
ECharts被广泛应用于数据可视化领域,如数据分析、商业智能、金融、医疗等。通过ECharts,用户可以将复杂的数据转化为直观、易理解的图表,从而更好地分析和利用数据。








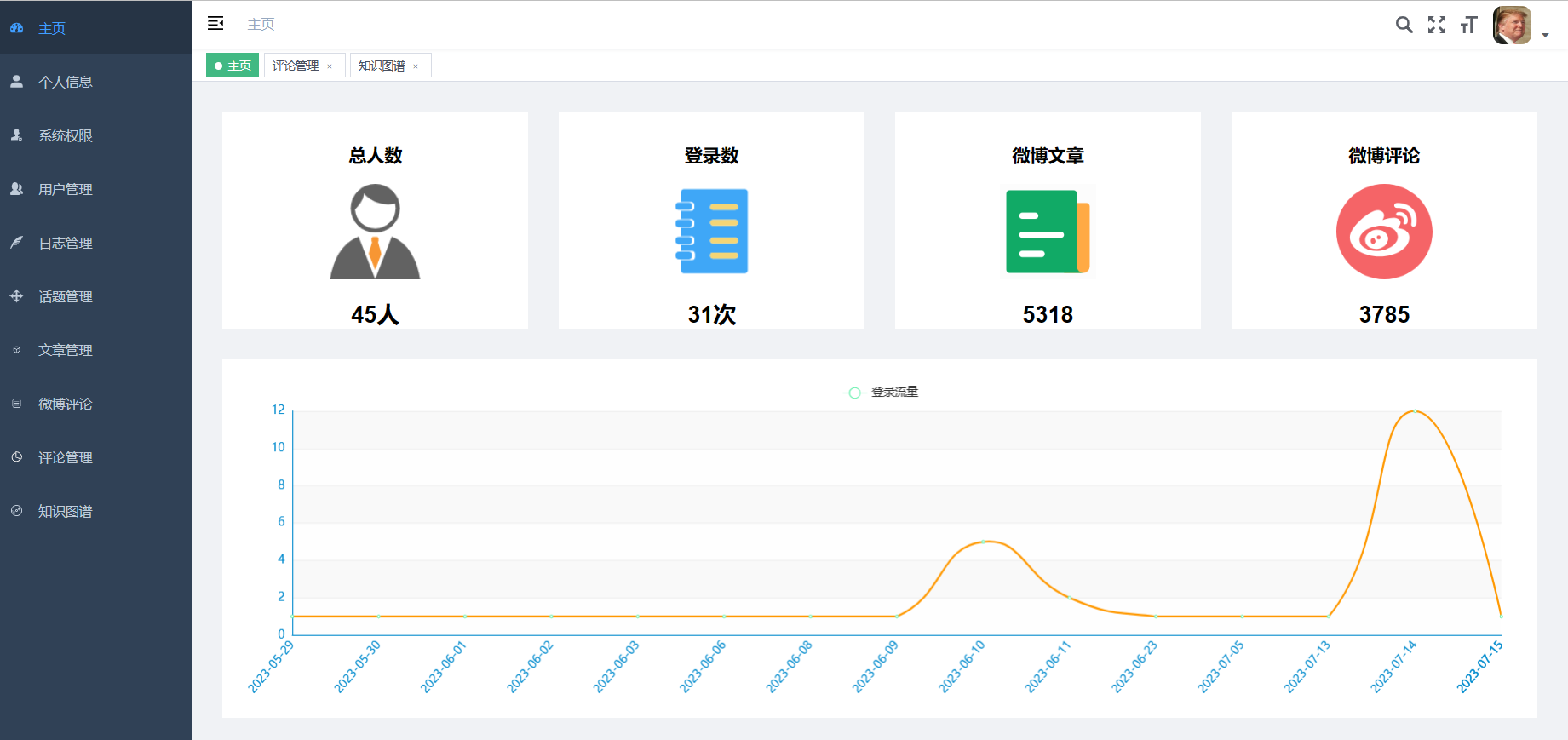
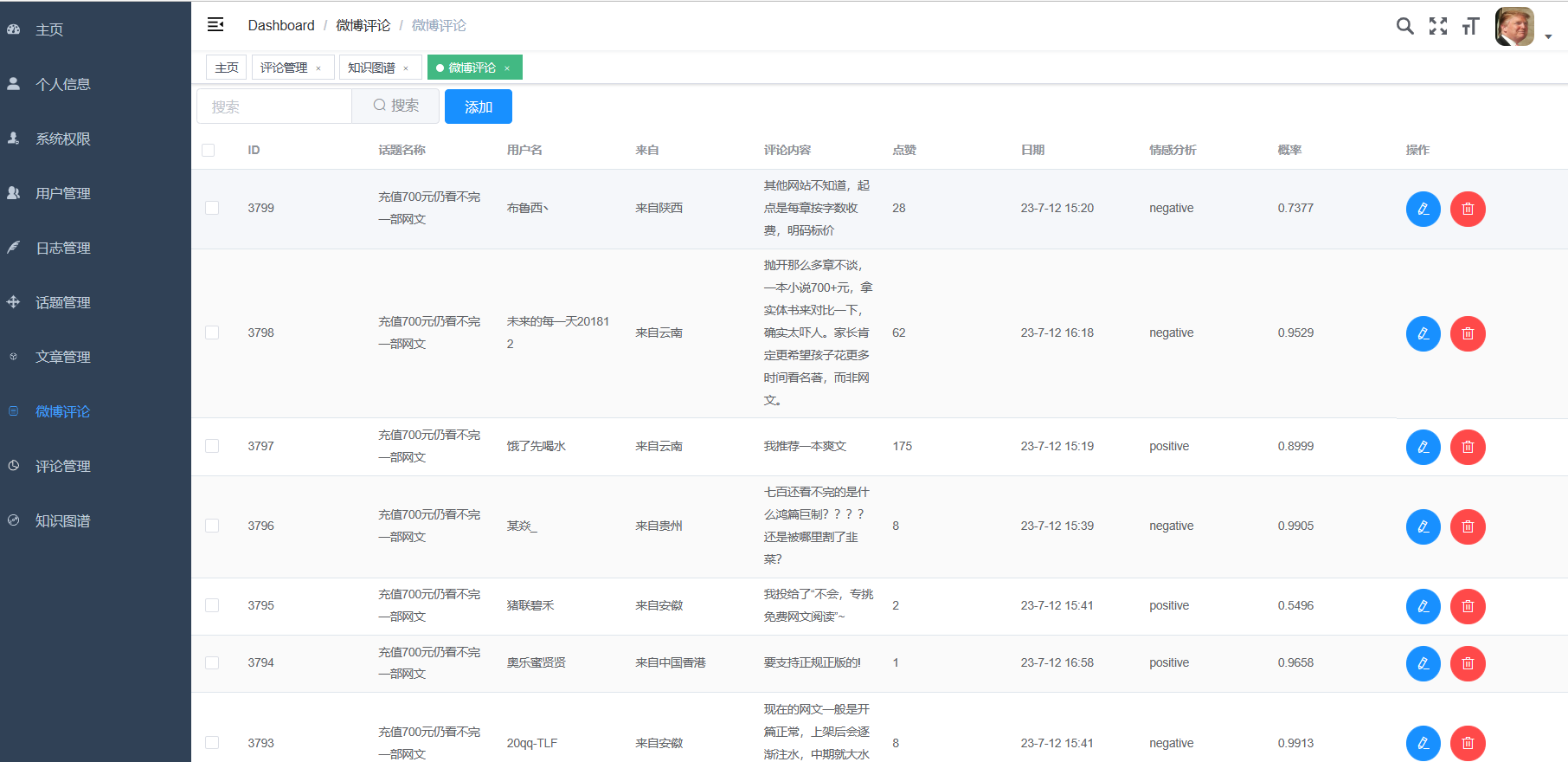
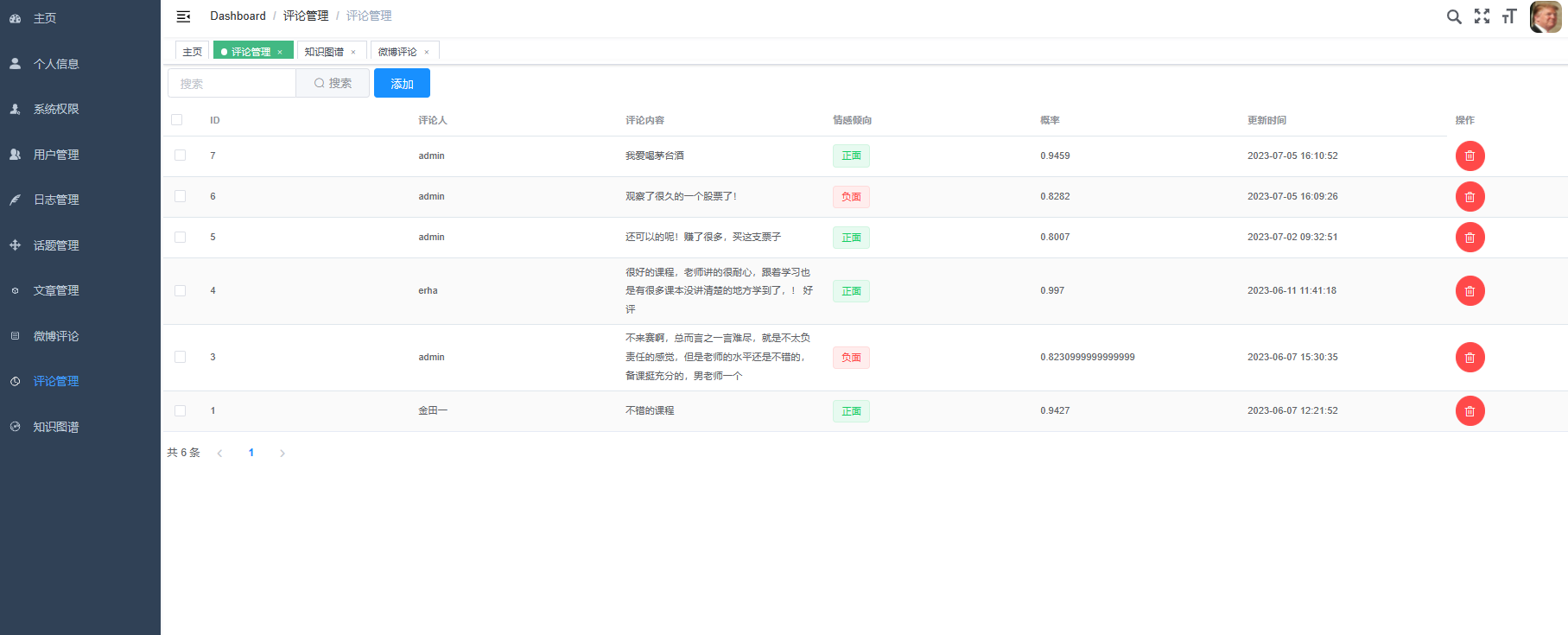
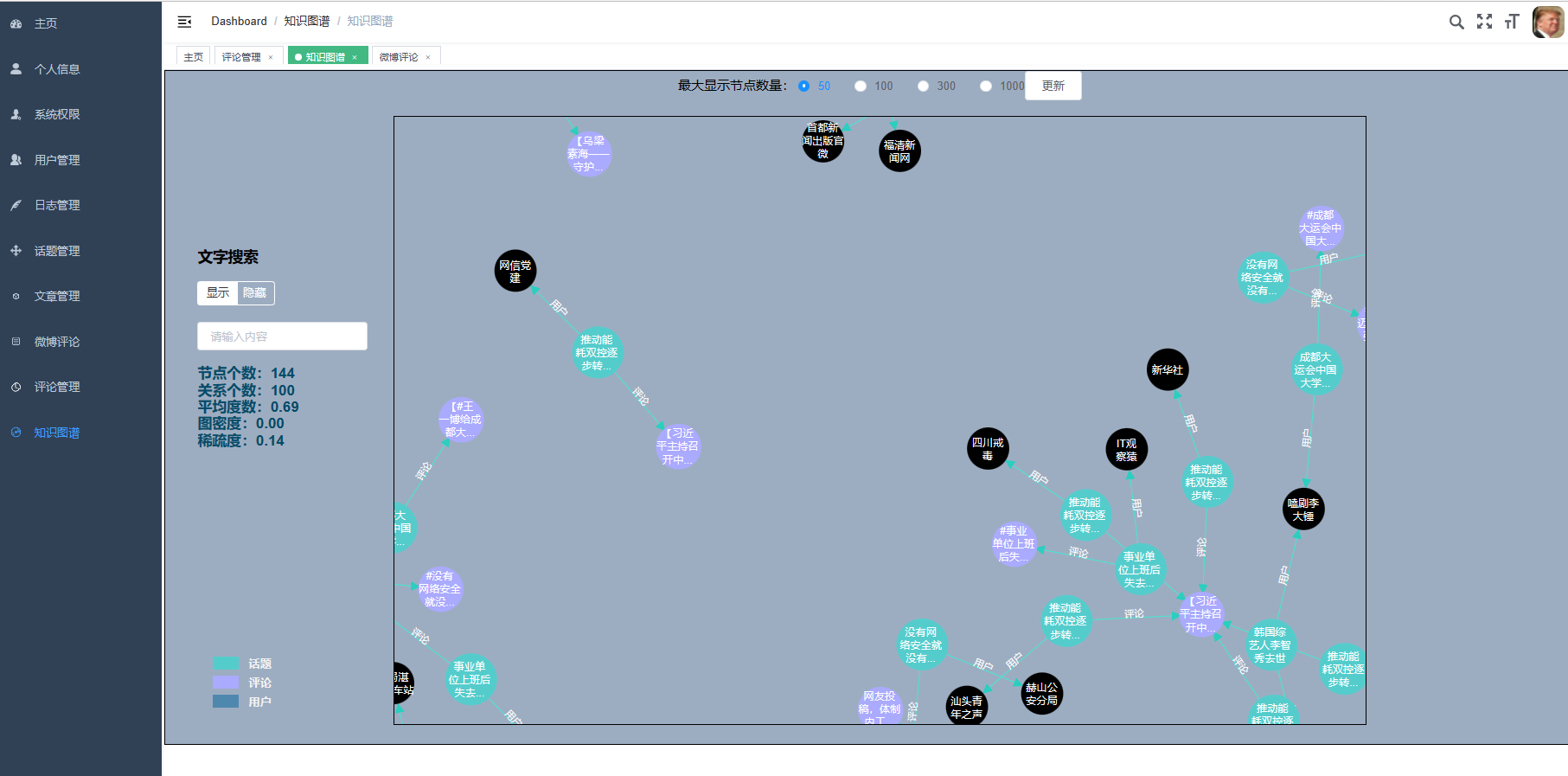
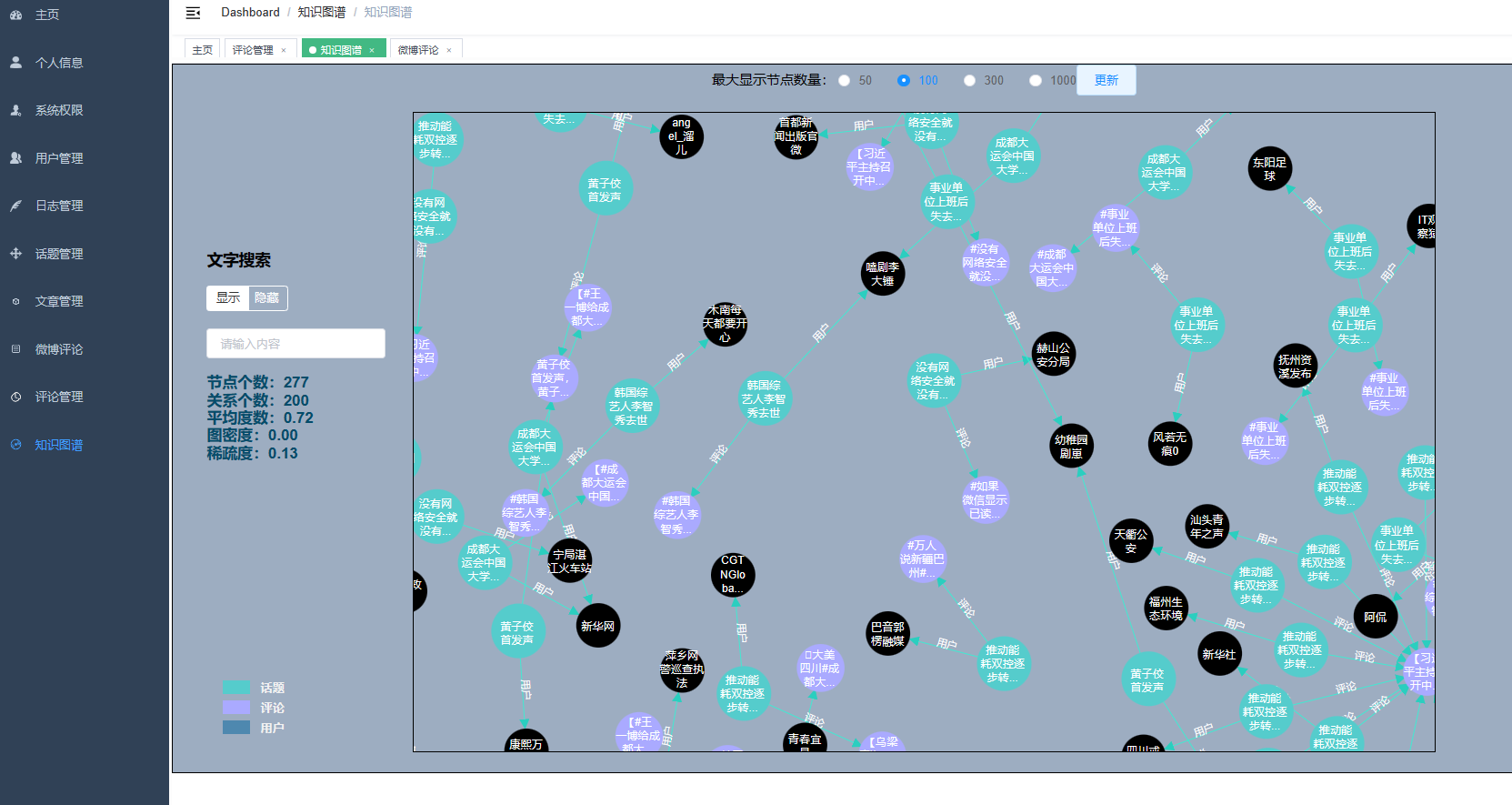
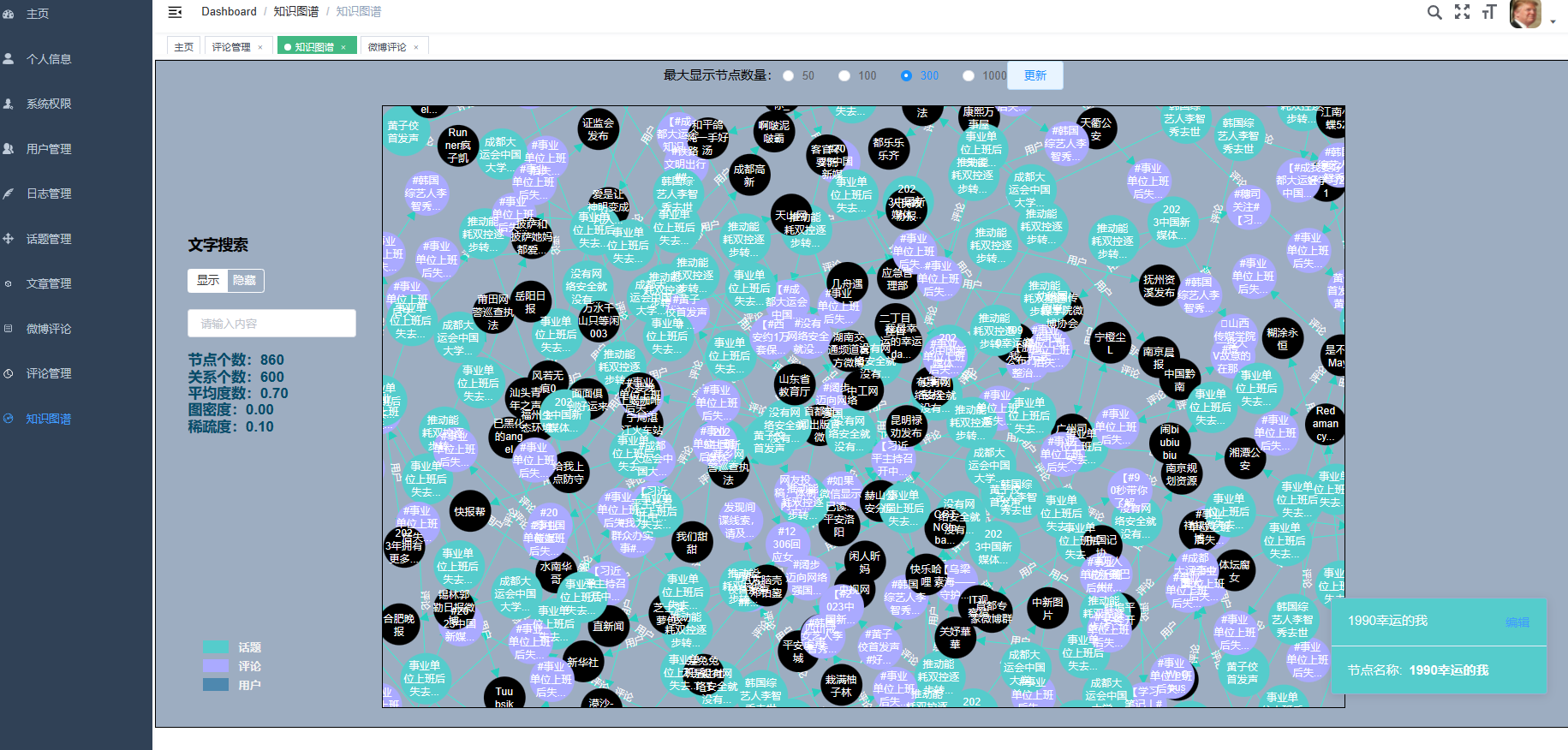







核心算法代码分享如下:
# coding=utf-8
from bs4 import BeautifulSoup
import requests
import sys
import random
import pymysql
links = []
datas = []
hea = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.118 Safari/537.36'
}
urls =["xxxx", #国内
]
# 打开数据库连接
db = pymysql.connect(host='127.0.0.1', user='root', password='123456', port=3396, db='news_recommendation_system')
# 使用cursor()方法获取操作游标
cursor = db.cursor()def main():#reload(sys)#sys.setdefaultencoding("utf-8")#baseurl = 'xxxx' # 要爬取的网页链接baseurl = 'xxxx' # 要爬取的网页链接# deleteDate()# 1.爬取主网页获取各个链接getLink(baseurl)# 2.根据链接爬取内部信息并且保存数据到数据库getInformationAndSave()# 3.关闭数据库db.close()def getInformationAndSave():for link in links:data = []url = "https://www.chinanews.com" + link[1]cur_html = requests.get(url, headers=hea)cur_html.encoding = "utf8"soup = BeautifulSoup(cur_html.text, 'html.parser')# 获取时间title = soup.find('h1')title = title.text.strip()# 获取时间和来源tr = soup.find('div', class_='left-t').text.split()time = tr[0] + tr[1]recourse = tr[2]# 获取内容cont = soup.find('div', class_="left_zw")content = cont.text.strip()print(link[0] + "---" + title + "---" + time + "---" + recourse + "---" + url)saveDate(title,content,time,recourse,url)def deleteDate():sql = "DELETE FROM news "try:# 执行SQL语句cursor.execute(sql)# 提交修改db.commit()except:# 发生错误时回滚db.rollback()def saveDate(title,content,time,recourse,url):try:cursor.execute("INSERT INTO news(news_title, news_content, type_id, news_creatTime, news_recourse,news_link) VALUES ('%s', '%s', '%s', '%s', '%s' ,'%s')" % \(title, content, random.randint(1,8), time, recourse,url))db.commit()print("执行成功")except:db.rollback()print("执行失败")def getLink(baseurl):html = requests.get(baseurl, headers=hea)html.encoding = 'utf8'soup = BeautifulSoup(html.text, 'html.parser')for item in soup.select('div.content_list > ul > li'):# 对不符合的数据进行清洗if (item.a == None):continuedata = []type = item.div.text[1:3] # 类型link = item.div.next_sibling.next_sibling.a['href']data.append(type)data.append(link)links.append(data)if __name__ == '__main__':main()
这篇关于计算机毕业设计hadoop+spark+hive舆情分析系统 微博数据分析可视化大屏 微博情感分析 微博爬虫 微博大数据 微博推荐系统 微博预测系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







