本文主要是介绍【博士每天一篇文献-综述】Modularity in Deep Learning A Survey,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
阅读时间:2023-12-8
1 介绍
年份:2023
作者:孙浩哲,布朗克斯医疗卫生系统
会议: Science and Information Conference
引用量:4
论文主要探讨了深度学习中的模块化(modularity)概念,模块化具有易于理解、解释、扩展、模块组合性和重用等优点。论文探讨了数据、任务和模型模块化在深度学习中的表现,数据模块化指的是观察或创建不同目的的数据组;任务模块化指的是将任务分解为子任务;模型模块化意味着神经网络系统的架构可以分解为可识别的模块。
2 创新点
- 多维度综述:论文从数据、任务和模型三个维度对深度学习中的模块化进行了全面的综述,这种多角度的分析为理解模块化在深度学习中的作用提供了一个全面的视角。
- 模块化定义的讨论:论文对模块化这一概念进行了深入的探讨,并尝试提出一个通用的定义,这有助于统一不同研究者对模块化理解的差异。
- 模块化优势的具体化:详细描述了模块化在深度学习中的各种优势,如易于设计、提高解释性、促进知识迁移和重用、改善泛化和样本效率等,这些优势的具体阐述为模块化的应用提供了明确的指导。
- 模块化原则的实例分析:论文不仅讨论了模块化的理论基础,还结合具体的深度学习子领域,如计算机视觉和自然语言处理,展示了模块化原则的实际应用案例。
- 模块化与深度学习模型的结合:论文探讨了如何将模块化原则与现有的深度学习模型结合,包括对典型模块的分析和模块组合方式的讨论,这有助于推动深度学习模型的创新和发展。
- 模块化在不同学习场景下的应用:论文讨论了模块化在少样本学习、多任务学习、持续学习等不同学习场景下的应用,这有助于理解模块化在解决实际问题中的潜力。
3 相关研究
3.1 思维导图

3.2 数据模块化
数据模块化分为原生数据模块化(intrinsic data modularity)和人为的数据模块化(imposed data modularity)
原生的数据模块化指的是数据集中自然存在的、未经人为引入的模块划分。这种模块化通常是数据固有特性的反映,可能源自数据的生成过程或其内在的结构。例如,在一个图像数据集中,不同的类别可以自然形成模块,因为属于同一类别的图像在特征空间中倾向于彼此接近。固有模块化可以由数据集中的类别标签隐含地定义,它反映了数据样本之间的语义关系,即样本的相似性或差异性。此外,数据集中的固有模块化还可以通过其他元数据特征来识别,如时间、地点、性别等。代表的数据集有ImageNet、Omniglot、OmniPrint、Meta-Album、NORB、Moons Dataset、VQA v2.0、 SpeakingFaces 。
人为的数据模块化是指由人为引入的数据集划分。这种模块化是基于特定目的或为了实现特定的学习目标而人为创建的。例如,在训练深度学习模型时,实践者可能会将整个训练数据集划分为多个小批量(mini-batches),每个小批量作为一个模块进行处理。这种划分有助于减少反向传播过程中的内存需求,使得训练大型深度学习模型成为可能。此外,强加的模块化还可以包括数据增强、特征划分、课程学习中的非均匀小批量采样等,这些都是为了更好地训练学习机器而人为设计的策略。
3.3 任务模块化
子任务分解可以分为两种模式:并行分解和顺序分解。
(1)并行分解
将一个任务分解成可以同时并行处理的子任务。比如,
- 同质分解:当子任务彼此相似时,这种分解被称为同质的。例如,将多类分类问题分解为多个较小的分类问题。
- 参数掩码:使用参数掩码来识别对个别类别负责的参数子集。
- 树状结构:将神经网络分解为树状结构,处理不同子集的类别,确保不同类别的特征不会在网络的后层中共享。
- 模块化二元分类器:将多类分类模型分解为可重用、可替换和可组合的二元分类器模块。
(2)顺序分解
将任务分解为需要按特定顺序依次执行的子任务。 比如,
- 强化学习中的应用:在强化学习中,复杂任务可以分解为一系列子任务或步骤,代理需要按顺序学习完成这些步骤。
- 学习效率:如果学习发生在分解阶段的粒度上,而不是整个任务,强化学习代理将更有效地学习。
- 信用分配:任务的分解允许独立地进行信用分配,失败可以追溯到具体的问题阶段,而不影响其他阶段。
- 实际应用:顺序子任务分解广泛应用于实际应用中,如光学字符识别(OCR)和自然语言处理(NLP)。
- 多语言识别:面对多语言识别任务时,可以分解为脚本识别和特定脚本的识别两个阶段。
- 文本识别:文本识别任务通常包括解耦的文本检测(定位文本的边界框)和文本识别(识别边界框中的文本)两个子任务。
- NLP流程:传统的自然语言处理流程包括句子分割、词标记化、词性标注、词形还原、过滤停用词和依存句法分析等子任务。
3.4 模型模块化
3.4.1 优点
- 设计和实现的便利性:模型模块化允许神经网络由重复的层或块模式组成,简化了模型架构的描述和实现。
- Kolmogorov复杂性:模块化设计减少了模型架构描述的长度,提高了描述的简洁性。
- 硬件和软件优化:标准化的神经网络构建块(如全连接层和卷积层)促进了为快速计算优化的硬件和软件生态系统的发展。
- 专家知识整合:模块化有助于将专家知识整合到模型设计中,提升模型性能。
- 可解释性:模块化允许为每个神经网络模块分配特定子任务,增强了模型的可解释性。
- 选择性模块评估:提供了对不同样本或任务间关系洞察的能力,有助于条件计算的背景下理解模型行为。
- 重用和知识转移:模块化促进了跨任务的模块重用,例如通过微调大型预训练模型来适应下游任务。
- 细粒度重用:研究者关注于更细粒度的模块重用,假设任务共享底层模式,并保留可重用模块的清单。
- 组合泛化:模块化有助于实现组合泛化,即系统地重新组合已知元素以映射新输入到正确输出。
- 知识保留:模块化有助于知识保留,使得知识更新和故障排除更加有针对性。
- 减少梯度干扰和灾难性遗忘:模块化有助于减轻不同任务间的梯度干扰和灾难性遗忘问题。
- 模型扩展:模块化模型可以通过增加或减少模块数量来扩展或缩小模型容量,适应不同大小的数据集。
- 计算成本与模型大小解耦:基于稀疏激活的模块化方法允许增加模型容量而不增加计算成本,因为每次前向传递只评估模型的一小部分。
- 超大型模型示例:如Switch Transformer,展示了通过模块化可以构建具有数万亿参数的超大型模型。
3.4.2 非序列数据模块化
全连接层、卷积层、局部连接层 (类似于卷积层,但移除了参数共享的约束)、低秩局部连接层 (Low-rank locally connected layers)、 群卷积层 (Group convolutional layers)、深度可分离卷积层 (Depthwise separable convolutional layers)、构建块 (多个层组合成一个更高层次的模块,例如ResNet、Inception、ResNeXt和Wide ResNet中的构建块)、Inception模块、 ResNet块。
3.4.3 序列数据模块化
递归神经网络(RNN)、门控循环单元 (GRU)、长短期记忆网络 (LSTM)、自注意力层、多头自注意力、Transformer 块、视觉变换器 (Vision transformers)。
3.5 模块化的组合
3.5.1 静态模块组合
静态组合指模块组合的结构对所有输入样本或任务都是固定不变的。 比如顺序连接、集成组合 (并行方式组织)、Dropout、树形结构组合 (结合了顺序和并行组合,形成树状结构)、有向无环图 (DAG)、合作组合 (每个模块作为独立的神经网络,具有特定功能,与集成组合不同,合作组合中的模块通常是异构的)。
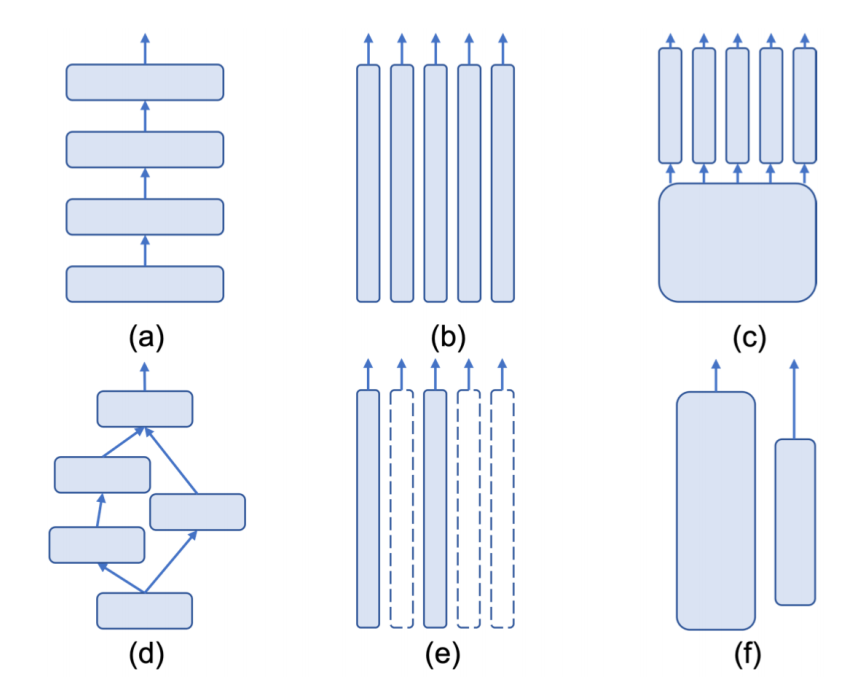
(a) 顺序连接 (b) 集成 © 树形结构组合 (d) 一般有向无环图 (e) 条件组合(f) 合作组合
3.5.2 条件模块组合
条件组合指的是根据每个特定的输入动态地(条件性地、稀疏地或选择性地)激活或使用组合模块。
比如条件计算 (根据输入样本或任务的条件,选择性地激活模块)、专家混合 (由多个独立的神经网络组成,每个模块学习处理整体任务的一个子任务,MoE)、模块崩溃 (训练过程中可能出现的问题,其中一个小模块被频繁选择,导致其他模块被忽视)、批量大小缩小 (条件激活的模块可能会导致处理的批量大小减少,影响硬件效率)、堆叠MoE (Stacked MoE)、层次MoE (Hierarchical MoE)、网络移植(通过直接移植对应新能力的模块来为通用网络添加新能力) 。
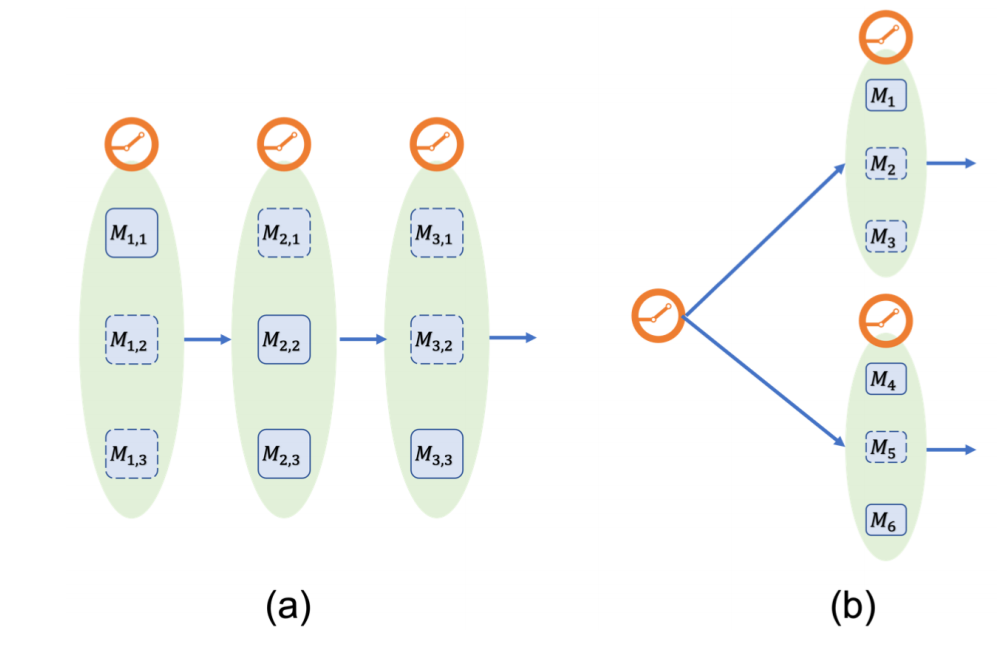
(a) 堆叠MoE (b) 分层MoE
3.6 其他模块化
- 图论中的模块化: 在图论中,模块化是一个用于社区检测的度量,衡量社区内部连接的密度与社区间连接的密度之比。
- 参数聚类: 受到图论中模块化度量的启发,研究了神经网络训练过程中参数聚类模式的出现。
- 结构模块化与功能专业化: 通过三个启发式度量定义了结构模块化,并直观地理解为子网络能够独立完成子任务的程度。
- 结构与功能模块化的关系: 通过设计场景研究了结构模块化(通过模块间稀疏连接强制实现)是否导致模块的功能专业化。
- 超网络的模块化: 将模块化用于描述超网络学习每个输入实例不同函数的能力。
- 解耦表示的模块化: 解耦表示旨在逆转数据生成过程,将数据的潜在因素恢复到学习到的表示中,其中模块化表示是解耦表示的一个理想属性。
6 思考
作者也在结论中说到,在深度学习中模块化这个概念本身没有一个明确的定义,所以作者将深度学习中所有可以称为模块化概念的方法、模型和结构都列举了出来,并说明了这些结构的优点和特性。启发性较低。
这篇关于【博士每天一篇文献-综述】Modularity in Deep Learning A Survey的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








