本文主要是介绍LLM中完全消除矩阵乘法,效果惊人!10亿参数在FPGA上运行功耗接近大脑!!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一直以来,矩阵乘法(MatMul)在神经网络操作中占据主导地位,主要因为GPU针对MatMul进行了优化。
老黄一举揭秘三代GPU!打破摩尔定律,打造AI帝国,量产Blackwell解决ChatGPT全球耗电难题
这种优化使得AlexNet在ILSVRC2012挑战赛中脱颖而出,成为深度学习崛起的历史性标志。
GPT-4o深夜发布!Plus免费可用!![]() https://www.zhihu.com/pin/1773645611381747712
https://www.zhihu.com/pin/1773645611381747712
没体验过OpenAI最新版GPT-4o?快戳最详细升级教程,几分钟搞定:
升级ChatGPT-4o Turbo步骤![]() https://www.zhihu.com/pin/1768399982598909952
https://www.zhihu.com/pin/1768399982598909952

论文地址:https://arxiv.org/pdf/2406.02528
项目地址:https://github.com/ridgerchu/matmulfreellm
值得注意的是,AlexNet利用GPU提高了训练速度,超越了CPU的能力,使深度学习仿佛赢得了「硬件彩票」。
尽管MatMul在深度学习中很流行,但它占据了计算开销的主要部分,尤其是在训练和推理阶段消耗了大部分执行时间和内存访问。
研究者已经开始使用其他更简单的操作替代MatMul,主要有两种策略:
1. 使用初等运算代替MatMul,例如在卷积神经网络(CNN)中,用有符号加法代替乘法;
2. 使用二值或三值化量化,将MatMul值在累加之前翻转或清零。例如,脉冲神经网络(SNN)使用二值激活,而二值化网络(BNN)使用量化权重。

在语言建模方面,BitNet等技术表明量化的可扩展性,但这种方式仍然保留了昂贵的矩阵-矩阵相乘(MMM)的自注意力机制。
尽管研究者尝试了多种方法,但MatMul操作在GPU上仍然是资源密集型的。
由于MatMul占据了LLM整体计算成本,且随着LLM向更大的嵌入维度和上下文长度扩展,这种成本只会增加。
这引发了一个问题:是否有可能完全从LLM中消除MatMul操作?

在这项工作中,加州大学圣克鲁兹分校等机构的研究者证明了MatMul操作可以完全从LLM中消除,同时在十亿参数规模下保持强大的性能。
实验表明,该研究提出的MatMul-free模型达到了与最先进的Transformer相当的性能,后者在推理期间需要更多的内存,规模至少为2.7B参数。
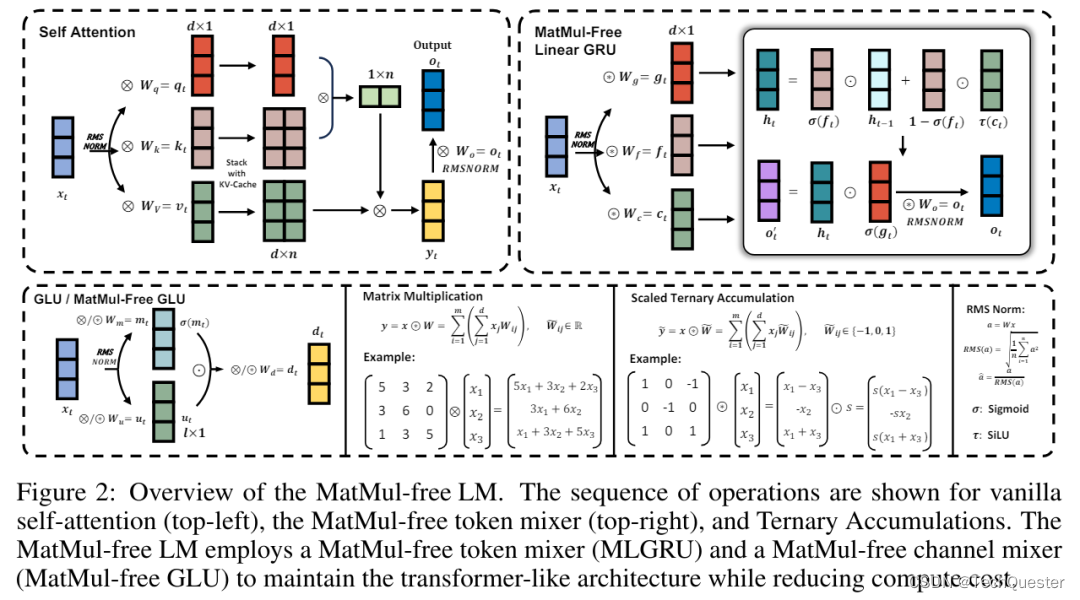
此外,论文还研究了扩展定律,发现随着模型规模的增加,MatMul-free模型与全精度Transformer之间的性能差距逐渐缩小。
研究者还提供了一种高效的GPU模型实现方式,在训练期间相比未优化的基线模型减少了多达61%的内存使用。通过在推理时利用优化的内核,模型内存消耗可以比未优化的模型减少超过10倍。
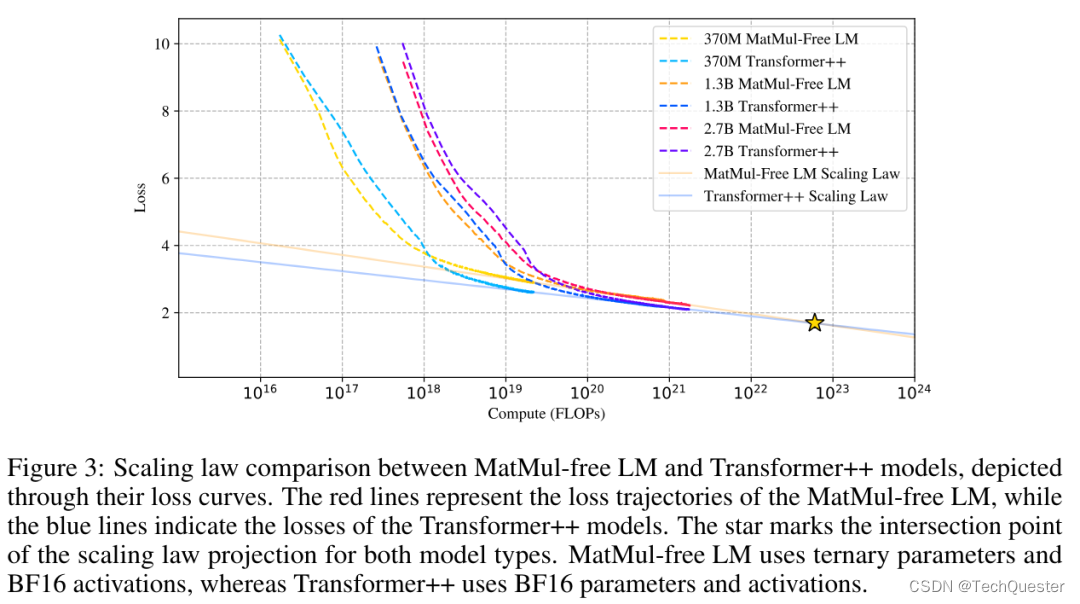
最后,研究者在FPGA上构建了一个自定义硬件解决方案,以13W的功耗处理了十亿参数规模的模型,超出了人类可读的吞吐量,使LLM更接近大脑般的效率。
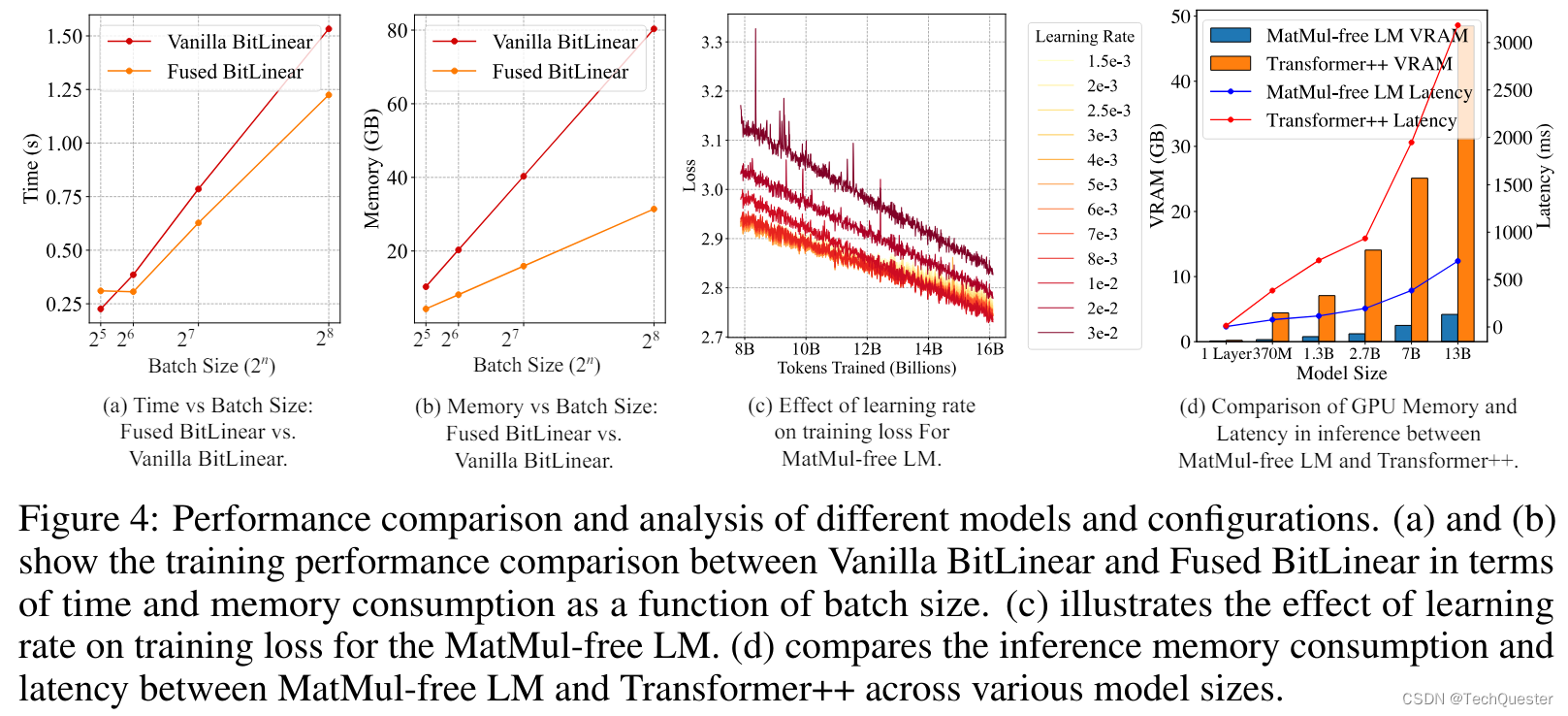
研究人员根据训练时间和内存使用情况评估了他们提出的融合型 BitLinear 和传统型 BitLinear 实现.
实验表明,他们的融合操作器在更大的批量大小下,能够带来更快的训练速度,并减少内存消耗。
当批量大小为 2 的 8 次方时,1.3B 参数模型的训练速度从每次迭代 1.52 秒提高到 1.21 秒,比 Vanilla 实现快了 25.6%。
推荐阅读:
如何免费使用GPT-4o?如何升级GPT...
更强大Mamba-2正式发布啦!!!
黎曼猜想取得重大进展!!
这篇关于LLM中完全消除矩阵乘法,效果惊人!10亿参数在FPGA上运行功耗接近大脑!!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







