本文主要是介绍用于认知负荷评估的集成时空深度聚类(ISTDC),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Integrated Spatio-Temporal Deep Clustering (ISTDC) for cognitive workload assessment
摘要:
本文提出了一种新型的集成时空深度聚类(ISTDC)模型,用于评估认知负荷。该模型首先利用深度表示学习(DRL)将高维EEG数据转换到低维特征空间,然后应用变分贝叶斯高斯混合模型(VBGMM)进行聚类分析。ISTDC模型通过四个算法实现,包括时间-空间变分自编码器(VAE)和多模态集成,有效地从EEG信号中提取时间与空间的潜在特征。在i-back任务中,所提出的模型在0-back与2-back任务对比中达到了98.0%的最大平均聚类准确率,相较于现有方法有显著提升。此外,多模态方法在工作量评估方面优于单模态模型。
引言:
引言部分定义了认知负荷作为一个多维构造,并讨论了使用主观或生理测量方法来评估操作者的工作量水平。由于基于生理信号的客观测量至关重要,EEG作为最有效的生理测量手段被广泛用于认知应用。然而,传统的基于EEG的特征(如功率谱密度PSD或事件相关电位ERP)并不总能在认知负荷估计中取得满意结果。因此,本文提出了一种新的深度学习方法,通过深度表示学习将EEG数据转换到更易于聚类的低维特征空间。
文章贡献
- 提出了一个新颖的ISTDC框架,该框架由四个算法组成,后接深度聚类方法,有效利用结合的时间和空间深度潜在特征来分类工作量水平。
- 在0-back与2-back任务对比中,所提出的模型达到了最高的分类准确率,并且与基于单模态VAE的聚类方法相比,分别提高了15.8%和13.7%的性能。
- 通过不同种类的比较研究,证明了所提出模型在所有比较中的效率有显著提高。
这些贡献展示了ISTDC模型在认知负荷评估方面的潜力,特别是在提高聚类准确性和多模态数据处理方面。

算法框架
-
时间-空间特征提取:
利用变分自编码器(VAE)来提取EEG信号的时间和空间特征。时间特征通过长短期记忆网络(LSTM)模型提取,而空间特征则通过卷积神经网络(CNN)模型提取。
-
深度表示学习(DRL):
通过DRL技术,将高维EEG数据映射到低维特征空间,以便于后续的聚类分析。
-
特征融合:
将提取的时间和空间特征进行融合,形成一个综合的特征向量,这个向量包含了原始EEG信号的多维度信息。
-
变分贝叶斯高斯混合模型(VBGMM):
使用VBGMM作为聚类算法,对融合后的特征向量进行聚类分析,以识别不同的认知负荷水平。
方法部分
介绍了Integrated Spatio-Temporal Deep Clustering (ISTDC)模型的构建和实现方式,包括数据集的选择、实验设计、深度学习模型的架构和认知负荷估计的聚类方法。以下是方法部分的主要内容概述:
-
数据集和实验分析:
使用了一个包含26名受试者(9名男性和17名女性)的公开可访问EEG数据集。
数据集记录了30个EEG电极的信号,采样率为1000 Hz,并进行了1-40 Hz的带通滤波处理。
应用独立成分分析(ICA)去除眼动和心电等伪迹。 -
集成时空变分自编码器(IST-VAE)模型:
介绍了深度表示学习方法(DRL),用于将高维输入数据映射到低维嵌入特征空间。
利用变分自编码器(VAE)来克服自动编码器(AE)的过拟合问题,通过正则化潜在变量。
描述了用于构建IST-VAE模型的四个算法,包括编码过程、时间VAE、空间VAE和多模态集成。 -
认知负荷估计使用变分贝叶斯高斯混合模型(VBGMM):
详细描述了VBGMM聚类方法,这是一种基于变分推断算法的方法,用于在保留贝叶斯方法优势的同时确定近似后验分布。
讨论了VBGMM的两个关键参数:先验类型(狄利克雷过程或狄利克雷分布)和权重浓度先验,后者基于先验类型确定每个组件的权重分布。 -
实验设计:
描述了i-back任务的实验设计,包括0-back、2-back和3-back任务,以及实验中每个任务的执行流程和持续时间。
-
模型训练和优化:
讨论了模型训练过程中使用的不同优化器和学习率,以及如何使用随机搜索方法来调整超参数。
-
模型评估:
介绍了用于评估VBGMM聚类性能的三个指标:无监督聚类准确率(Acc)、归一化互信息(NMI)和Rand指数(RI)。
-
计算复杂性分析:
对模型的计算复杂性进行了讨论,包括LSTM和CNN模型的时间复杂度,以及VBGMM聚类算法的复杂度。
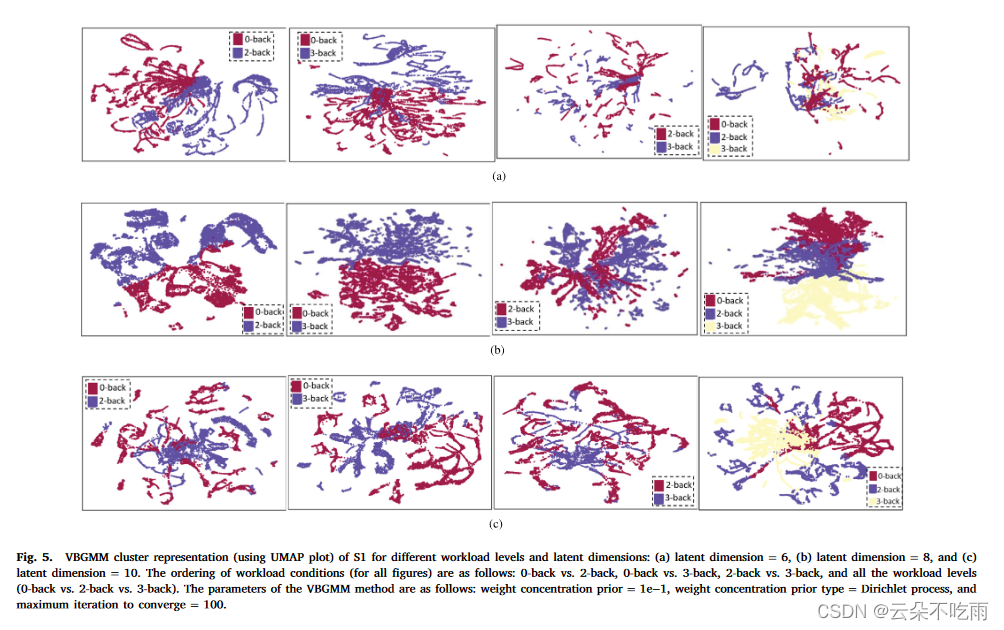
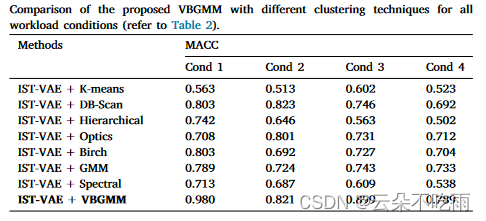
结论
本文提出了一种创新的Integrated Spatio-Temporal Deep Clustering (ISTDC)框架,通过融合电生理信号的时空特征,并应用变分贝叶斯高斯混合模型(VBGMM)进行聚类分析,有效提升了认知负荷评估的准确性。实验结果表明,该模型在0-back与2-back任务对比中实现了98.0%的高平均聚类准确率,并在个别受试者上达到了99.2%的准确率。此外,模型在不同数据集上展现出良好的泛化能力,相较于传统方法和其他深度学习模型,显示出显著的性能优势。未来的工作将探索集成更多生理信号,如近红外光谱(NIRS),以进一步提高模型的评估性能。
应用点
聚类在图像语义分割中的应用是将图像的每个像素或区域根据其特征自动划分到不同的类别中,从而实现对图像结构的理解和描述。通过使用不同的聚类算法,如K-means、谱聚类或基于密度的DBSCAN,可以从原始像素值或通过深度学习模型提取的高级特征中学习数据的内在结构。这些算法将图像的像素分组,以便每个组内的像素在视觉上或在特征空间中是相似的,而组与组之间则有明显的差异。聚类结果可以用于生成更加精细和准确的分割,尤其是在处理复杂场景或缺少大量标注数据的情况中。此外,聚类技术可以与监督学习方法结合使用,形成半监督学习框架,以提高分割精度并减少对大量标注数据的依赖。最终,聚类在图像语义分割中的应用有助于自动化和改善计算机视觉系统在场景理解、对象识别和自动驾驶等领域的性能。
聚类在语义语义分割中的应用
-
特征提取:
首先,需要从图像中提取有用的特征。这些特征可以是像素级的颜色、纹理、位置信息,或者是通过深度学习模型(如卷积神经网络CNN)提取的高级特征。
-
无监督学习:
聚类是一种无监督学习方法,可以在没有标签指导的情况下对数据进行分组。在图像语义分割中,可以将图像的每个像素或小区域视为数据点,并应用聚类算法来识别图像中不同的区域或对象。
-
选择聚类算法:
根据任务的具体需求选择合适的聚类算法,如K-means、谱聚类、层次聚类、基于密度的聚类(如DBSCAN)或变分贝叶斯聚类等。
-
应用聚类算法:
将聚类算法应用于提取的特征上,以将图像分割成多个区域或对象。每个聚类代表图像中的一个语义上一致的区域。
-
后处理:
聚类结果可能需要后处理步骤来优化分割效果,例如通过形态学操作来消除小的、孤立的区域,或通过条件随机场(CRF)来细化边界。
-
评估:
使用像素准确率、交并比(IoU)、平均精度等指标来评估聚类结果的质量。
-
集成学习:
在某些情况下,可以结合多个聚类模型的输出,通过集成学习方法来提高分割的准确性和鲁棒性。
-
半监督学习:
如果有少量的标注数据可用,可以结合无监督聚类和监督学习,使用半监督方法来提高分割性能。
-
多尺度聚类:
在不同尺度上应用聚类算法,可以帮助识别不同大小的对象,提高分割的准确性。
-
多模态特征融合:
如果有多种类型的数据可用(例如,彩色图像、深度图像、红外图像),可以融合这些数据的特征来进行更准确的聚类和分割。
这篇关于用于认知负荷评估的集成时空深度聚类(ISTDC)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





